一、集成学习
1.集成学习的含义
集成学习是将多个基学习器进行组合,来实现比单一学习器显著优越的学习性能
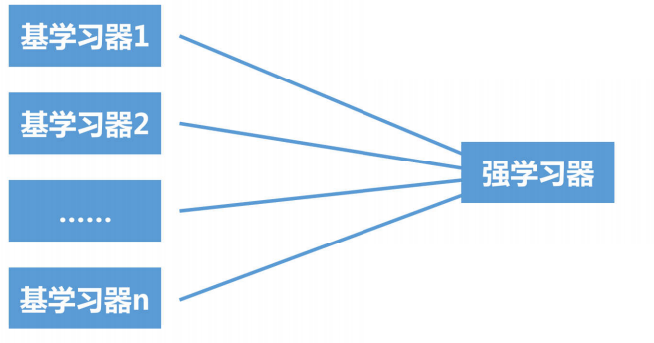
2.集成学习的代表:
bagging方法:典型的是随机森林
boosting方法:典型的是Xgboost
stacking方法:堆叠模型
XGBoost和随机森林的对比
相同点:
两者都是由多棵树组成,最终的结果都是由多棵树一起决定。
在使用CART树时,两者可以是分类树或者回归树。
不同点:
组成随机森林的树可以并行生成,而XGBoost是串行生成。
随机森林的结果是多数表决表决的,而XGBoost则是多棵树累加之和。
随机森林对异常值不敏感,而XGBoost对异常值比较敏感。
随机森林是减少模型的方差,而XGBoost是减少模型的偏差。
随机森林不需要进行特征归一化,而XGBoost则需要进行特征归一化。
XGBoost在训练之前,预先对数据进行了排序,然后保存为blockblock结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个blockblock结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
总之,XGBoost和随机森林各具特色,需要根据具体的数据特征和需求选择
3.集成学习的应用:
分类问题集成
回归问题集成
特征选取集成
二、随机森林
1.随机森林的概念
随机森林(Random Forest)是一种集成学习(Ensemble Learning) 算法,由多个决策树(Decision Tree)集成而成。它通过** bootstrap 抽样和特征随机选择**两种随机性机制,综合多棵决策树的预测结果,最终输出更稳定、更准确的预测结论。
其核心思想是"三个臭皮匠顶个诸葛亮"------单棵决策树容易过拟合(对训练数据拟合过好,泛化能力差),而多棵决策树通过合理组合可以降低方差、提升模型的泛化能力。
2.随机森林的特点
数据采集随机
特征选取随机
森林
基分类器为决策树
3.为什么要使用随机森林
随机森林的优势
随机森林是一种集成学习方法,通过组合多个决策树来提高预测准确性和稳定性。其核心优势包括:
高准确性
通过聚合多个决策树的预测结果,随机森林能够减少过拟合风险,提高泛化能力。在大多数分类和回归任务中,其表现优于单一决策树。
处理高维数据
随机森林能够自动处理大量特征,无需手动特征选择。通过随机选择特征子集进行训练,模型对噪声和冗余特征的鲁棒性较强。
抗过拟合能力
通过自助采样(Bootstrap)和特征随机选择,每棵树的训练数据与特征均不同,降低了模型过拟合的风险。
适用场景
非线性数据
随机森林能够捕捉复杂的非线性关系,适用于数据中存在交互作用或非线性的场景,如生物信息学、金融预测等。
缺失值处理
模型对缺失值不敏感,可通过其他特征的信息进行补偿,适合实际应用中数据不完整的情况。
并行化训练
每棵决策树的训练相互独立,支持并行计算,显著提升大规模数据集的训练效率。
实际应用示例
分类任务
在医疗诊断中,随机森林可用于预测疾病类别,如基于患者体征数据区分良性或恶性肿瘤。
回归任务
在房价预测中,模型能够整合位置、面积、年代等多维特征,输出连续型预测值。
特征重要性分析
随机森林可计算特征对预测的贡献度,辅助业务决策。例如在营销中识别影响用户购买的关键因素。
4.随机森林的生成步骤
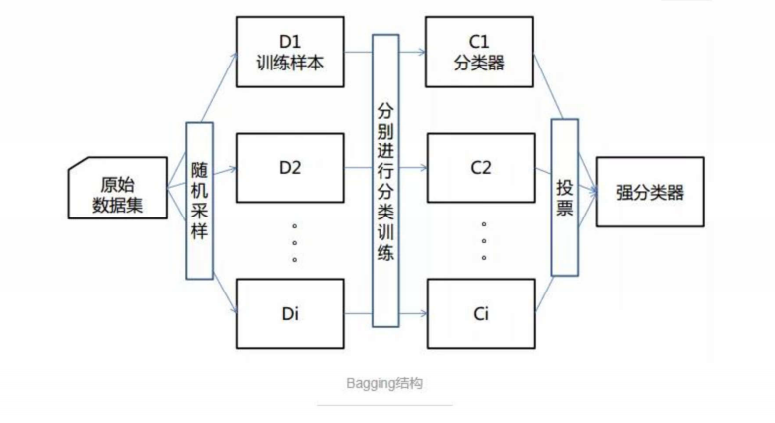
5.随机森林的优点
具有极高的准确率
随机性的引入,使得随机森林的抗噪声能力很强
随机性的引入,使得随机森林不容易过拟合
能够处理很高维度的数据,不用做特征选择
容易实现并行化计算
6.随机森林的缺点
当随机森林中的决策树个数很多时,训练时需要的空间和时间会较大
随机森林模型还有很多不好解释的地方,有点算个黑盒模型
三、实际案例
python
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(
n_estimators=100,#决策树的个数
max_features=0.8,#80%的特征,每个决策树学习到的特征数量
random_state=0
)
rf.fit(xtrain, ytrain)
#预测训练集结果
train_predicted = rf.predict(xtrain)#自测
"""
训练集结果
"""
from sklearn import metrics
#绘制混淆矩阵
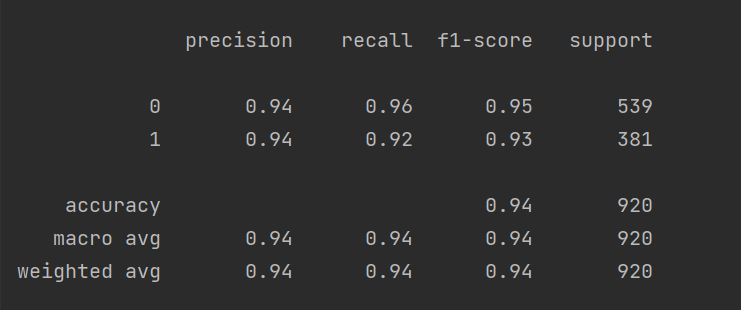
print(metrics.classification_report(ytrain, train_predicted,digits=9))#分类结果。
#可视化混淆矩阵
cm_plot(ytrain, train_predicted).show() #训练数据集再次做测试的结果
"""
测试集结果
"""
#预测测试集结果
test_predicted = rf.predict(xtest)#测试数据集
#绘制混淆矩阵
print(metrics.classification_report(ytest, test_predicted))
#可视化混淆矩阵
cm_plot(ytest, test_predicted).show()
"""
绘制特征重要程度排名
"""
import matplotlib.pyplot as plt
# from pylab import mpl
importances = rf.feature_importances_#这个属性保存了模型中特征的重要性
im = pd.DataFrame(importances,columns=["importances"])
clos = df.columns
clos_1 = clos.values
clos_2 = clos_1.tolist()
clos = clos_2[0:-1]
im['clos'] = clos
# 在Pandas中sort_values可以帮助我们对DataFrame或Series中的值进行排序。使用方法:
# DataFrame.sort_values(by='column_name', ascending=True/False, inplace=True/False)
# 参数解释:
# by:要排序的列名。可以是一个字符串(对单列进行排序)或一个列表(对多列进行排序)。默认情况下,按照升序排序。
# ascending:布尔值,表示是否按照升序排序。默认为True,表示按照升序排序;如果为False,则按照降序排序。
# inplace:布尔值,表示是否在原地修改数据。如果为True,则在原地修改数据;如果为False,则返回一个新的排序后的DataFrame。
im = im.sort_values(by=['importances'], ascending=False)[:10]
#设置中文字体
# mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei']
# mpl.rcParams['axes.unicode_minus'] = False
index = range(len(im))
plt.yticks(index, im.clos)#用于获取或设置y轴的刻度位置和标签。
plt.barh(index, im['importances'])#用于创建水平条形图。
plt.show()运行结果:
四、随机森林API文档
class sklearn.ensemble.RandomForestClassifier (n_estimators='warn' , criterion='gini' , max_depth=None , min_samples_split=2 , min_samples_leaf=1 , min_weight_fraction_leaf=0.0 , max_features='auto' , max_leaf_nodes=None , min_impurity_decrease=0.0 , min_impurity_split=None , bootstrap=True , oob_score=False , n_jobs=None , random_state=None , verbose=0 , warm_start=False , class_weight=None )
随机森林重要的一些参数:
1.n_estimators : (随机森林 独有 )
随机森林中决策树的个数。
在0.20版本中默认是10个决策树;
在0.22版本中默认是100个决策树;
2. criterion : ( 同决策树****)****
节点分割依据,默认为基尼系数。
可选【entropy:信息增益】
3.max_depth :( 同决策树****)**** 【重要】
default=(None)设置决策树的最大深度,默认为None。
【(1)数据少或者特征少的时候,可以不用管这个参数,按照默认的不限制生长即可
(2)如果数据比较多特征也比较多的情况下,可以限制这个参数,范围在10~100之间比较好】
4.min_samples_split : (同决策树)【重要】
这个值限制了子树继续划分的条件,如果某节点的样本数少于设定值,则不会再继续分裂。默认是2.如果样本量不大,不需要管这个值。如果样本量数量级非常大,则建议增大这个值。
5.min_samples_leaf :( 同决策树****)**** 【重要】
这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。 默认是1,可以输入最少的样本数的整数,或者最少样本数占样本总数的百分比。如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
【叶是决策树的末端节点。 较小的叶子使模型更容易捕捉训练数据中的噪声。 一般来说,我更偏向于将最小叶子节点数目设置为大于50。在你自己的情况中,你应该尽量尝试多种叶子大小种类,以找到最优的那个。】
【比如,设定为50,此时,上一个节点(100个样本)进行分裂,分裂为两个节点,其中一个节点的样本数小于50个,那么这两个节点都会被剪枝】
6.min_weight_fraction_leaf : (同决策树)
这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝。 默认是0,就是不考虑权重问题。一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。【一般不需要注意】
7.max_features : (随机森林独有)【重要】
随机森林允许单个决策树使用特征的最大数量。选择最适属性时划分的特征不能超过此值。
当为整数时,即最大特征数;当为小数时,训练集特征数*小数;
if "auto", then max_features=sqrt(n_features).
If "sqrt", then max_features=sqrt(n_features).
If "log2", then max_features=log2(n_features).
If None, then max_features=n_features.
【增加max_features一般能提高模型的性能,因为在每个节点上,我们有更多的选择可以考虑。 然而,这未必完全是对的,因为它降低了单个树的多样性,而这正是随机森林独特的优点。 但是,可以肯定,你通过增加max_features会降低算法的速度。 因此,你需要适当的平衡和选择最佳max_features。】
8.max_leaf_nodes :(同决策树)
通过限制最大叶子节点数,可以防止过拟合,默认是"None",即不限制最大的叶子节点数。如果加了限制,算法会建立在最大叶子节点数内最优的决策树。如果特征不多,可以不考虑这个值,但是如果特征分成多的话,可以加以限制,具体的值可以通过交叉验证得到。
【比如,一颗决策树,如果不加限制的话,可以分裂100个叶子节点,如果设置此参数等于50,那么最多可以分裂50个叶子节点】
9.min_impurity_split: (同决策树)
这个值限制了决策树的增长,如果某节点的不纯度(基于基尼系数,均方差)小于这个阈值,则该节点不再生成子节点。即为叶子节点 。一般不推荐改动默认值1e-7。
10. bootstrap =True(随机森林独有)
是否有放回的采样,按默认,有放回采样
11. n_jobs=1:
并行job个数。这个在是bagging训练过程中有重要作用,可以并行从而提高性能。1=不并行;
n:n个并行;
-1:CPU有多少core,就启动多少job。