作者:Pau Labarta Bajo
https://paulabartabajo.substack.com/p/fine-tuning-lfm2-350m-for-browser
今天要分享的是在 Liquid AI Discord 社区举办的一场60分钟实战课程的详细记录。
主题是什么?如何通过强化学习教会语言模型浏览网站并完成任务。
这篇文章将展示如何构建能够点击按钮、填写表单,甚至预订机票的浏览器智能体,它们通过试错学习而非完美示范来掌握这些技能。
文章会展示如何使用 GRPO、BrowserGym 和 LFM2-350M 构建完整的训练流程,从简单的"点击测试"任务开始逐步扩展。
所有代码都可以在 Liquid AI Cookbook 中找到:
代码仓库:https://github.com/Liquid4All/cookbook/tree/main/examples/browser-control
什么是浏览器控制?
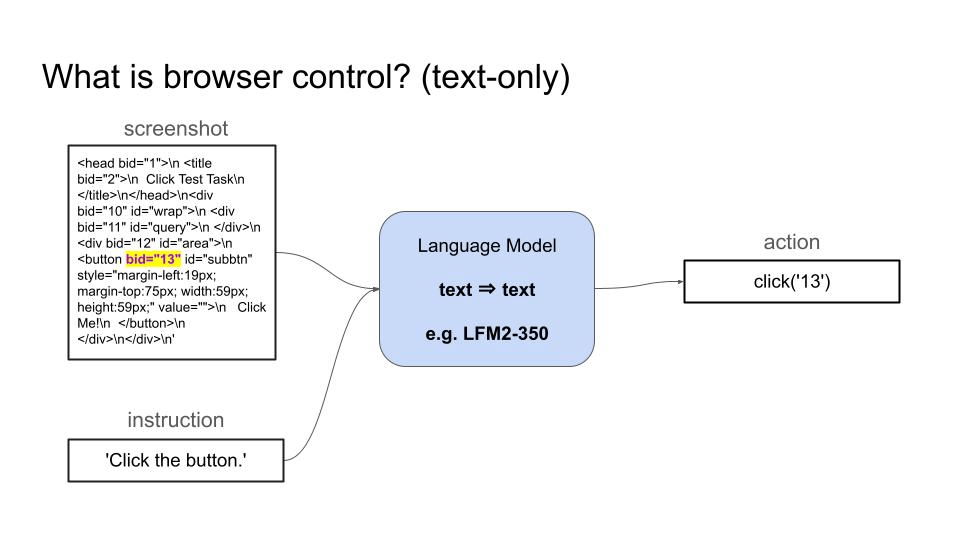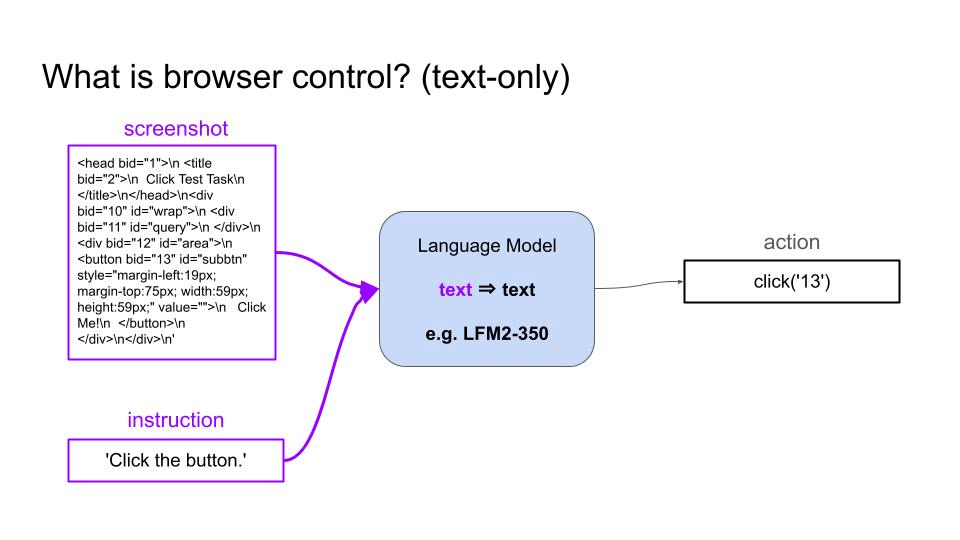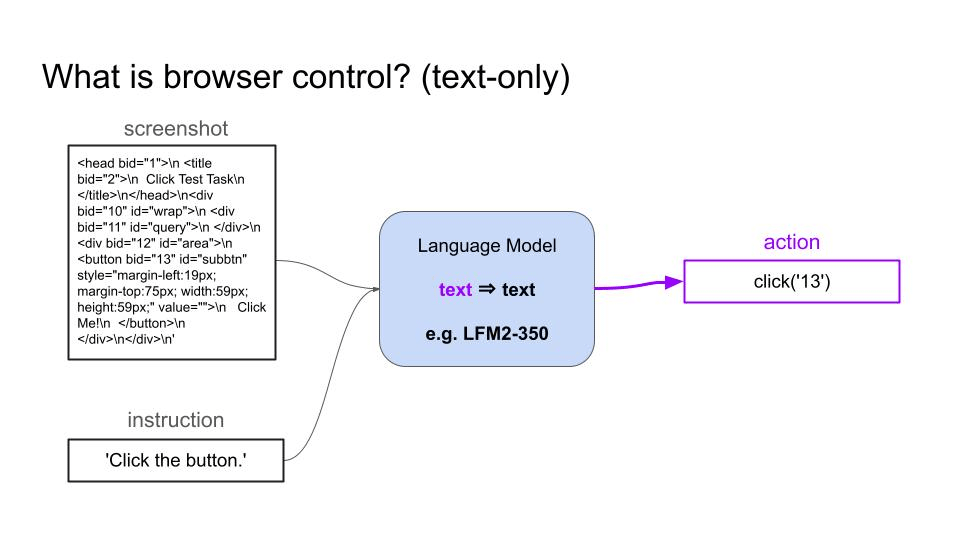
浏览器控制是指语言模型通过生成一系列动作(点击元素、输入文本、滚动页面)来浏览和操作网站,从而完成用户指定任务的能力,比如预订机票、填写表单或从网页提取信息。
具体来说:
- 视觉语言模型(VLM)可以接收截图和用户目标作为输入,然后生成一系列动作来实现目标。
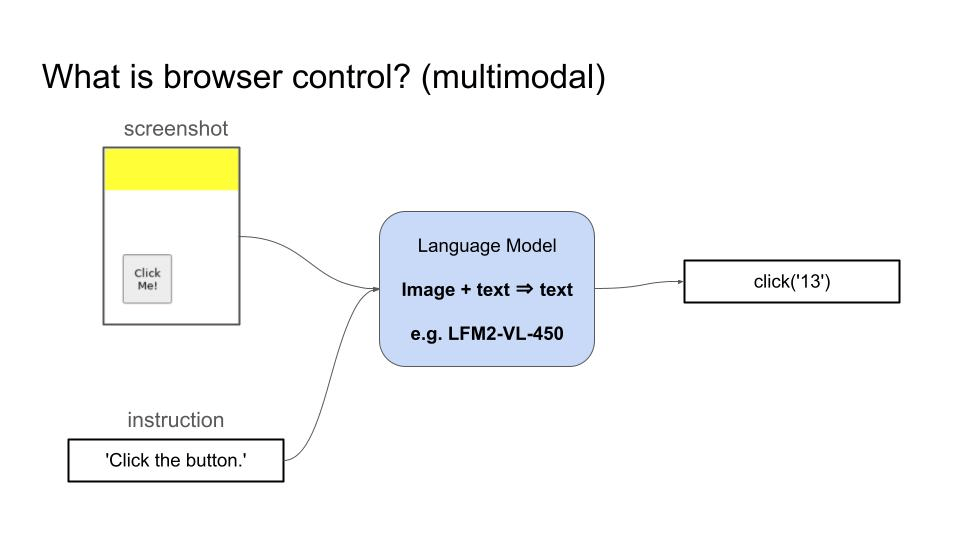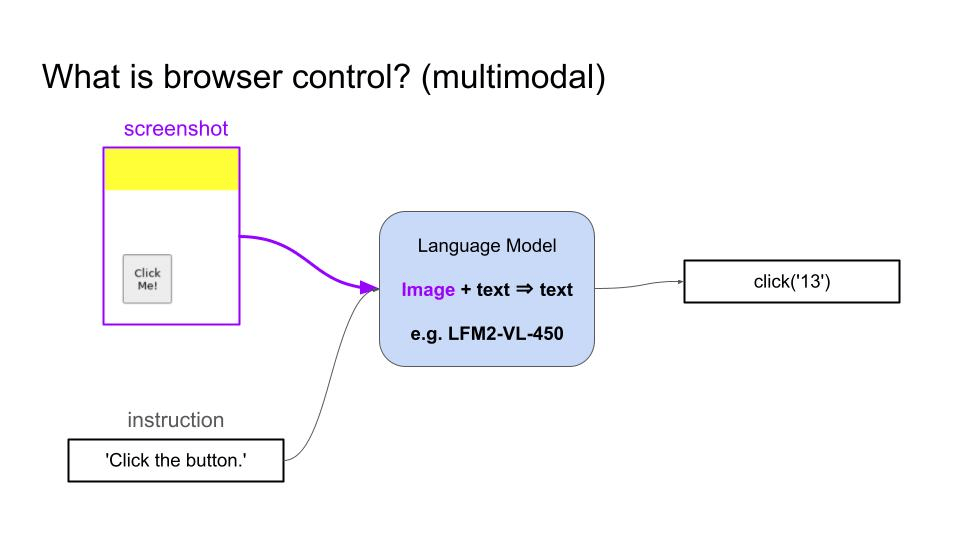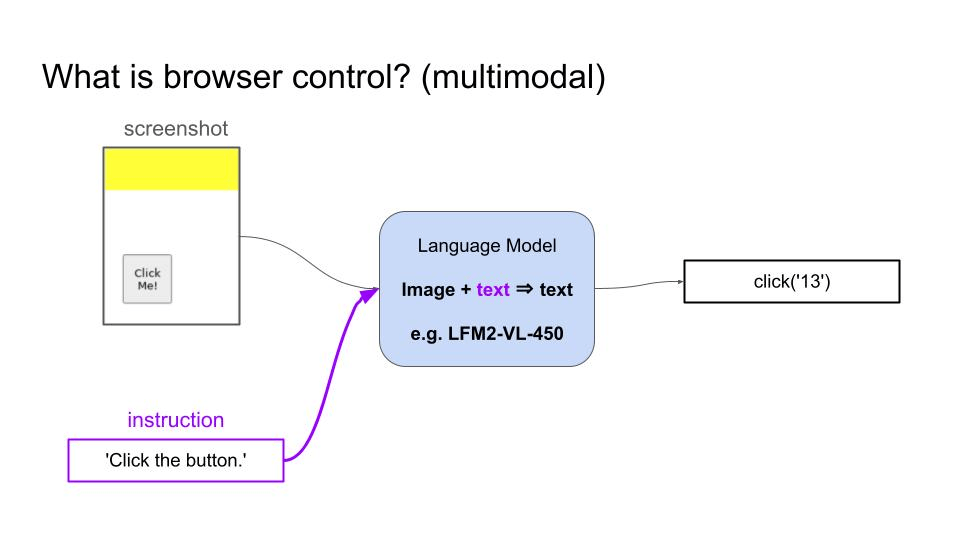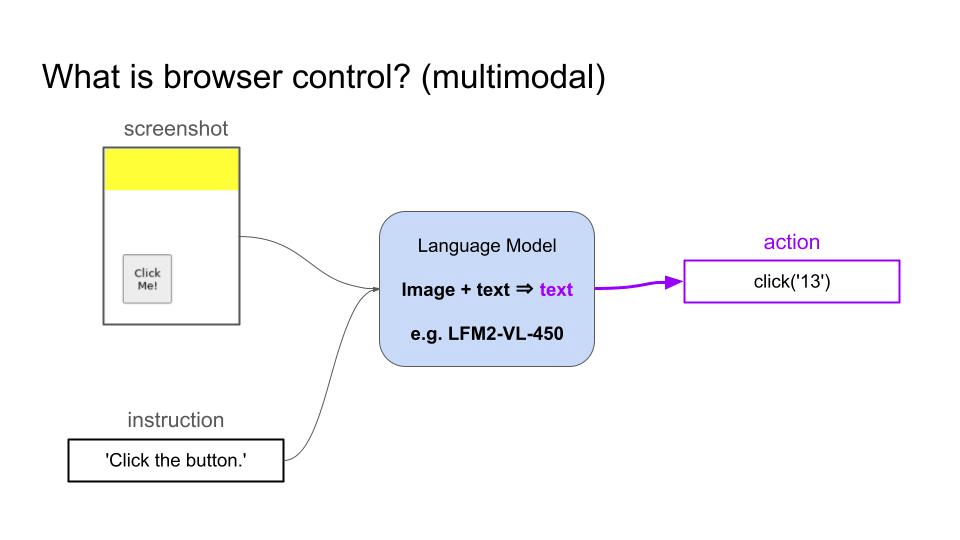
- 纯文本语言模型可以接收页面的 HTML 代码作为输入,用同样的方式进行操作。
现实应用场景
浏览器控制有很多实际应用,既有好的用途:
辅助无障碍访问:作为屏幕阅读器的伴侣,为视障用户在亚马逊或生鲜配送网站上导航复杂的结账流程、阅读产品描述并完成购买。
医疗预约管理:检查多个诊所网站的预约空位,预订与保险匹配的最早时段,并添加到日历中。
账单支付自动化:每月访问公用事业公司网站,核实金额,并从银行账户安排付款。
但就像任何强大的技术一样,也可能被滥用来制作有害软件,比如:
评论操纵:机器人创建虚假账户,在亚马逊、Yelp 或谷歌上发布欺诈性评论,人为提高产品评分或损害竞争对手。
理解这些系统如何训练和部署,对于最大化良性应用的价值、同时最小化恶意用例的影响至关重要。
为什么需要强化学习(RL)?
在浏览器控制中,完成同一个目标往往有多种有效方法。
关键在于,验证模型是否完成任务要比构建完整的(输入、输出)示范数据集来模仿要容易得多。
这就是为什么使用带有可验证奖励的强化学习比监督微调更适合解决这个问题。
举个例子
任务:"在2016年12月6日预订从 LAF 到阿拉斯加 Akuton 的最短单程航班"
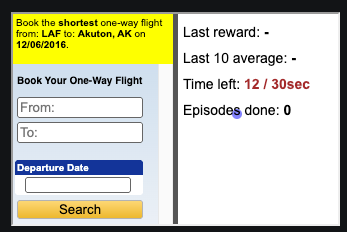
解决这个问题有很多可能的方法,从类似人类的正常路径(智能体填写"出发地"字段,然后是"目的地"字段,最后是日期),到智能体先错误输入 LAT,然后纠正并继续完成的情况。
为监督微调(SFT)获取所有这些情况的专家演示是不切实际的。相反,一个在每一步验证任务是否完成的强化学习环境可以提供稀疏反馈(即奖励),强化学习算法可以用它来迭代改进模型性能。
此外,通过强化学习,语言模型还能学会在出错时自我纠正。如果它们点击了错误的元素或导航到意外的页面,可以回溯并找到替代路径。仅在成功演示上训练的 SFT 模型在偏离预期轨迹时往往会卡住。
这就是为什么针对这个任务使用强化学习而不是 SFT。话虽如此,可以先用 SFT 预热模型,然后用强化学习提升性能。
强化学习训练框架的构建模块
强化学习的思路是迭代地让语言模型(即策略):
- 观察环境的状态(例如网站的 DOM 元素)
- 输出一个动作(即文本补全),并且
- 偶尔从环境获得正向奖励(即反馈)
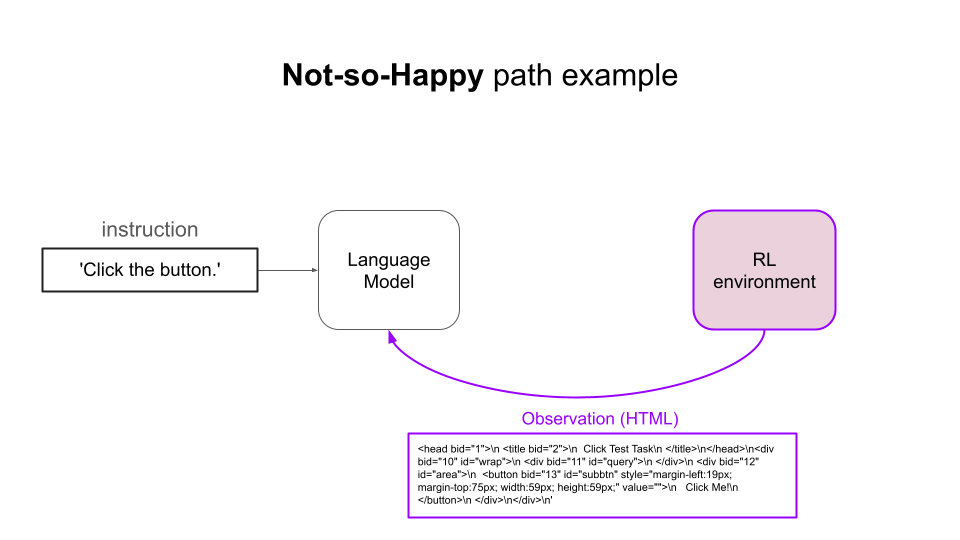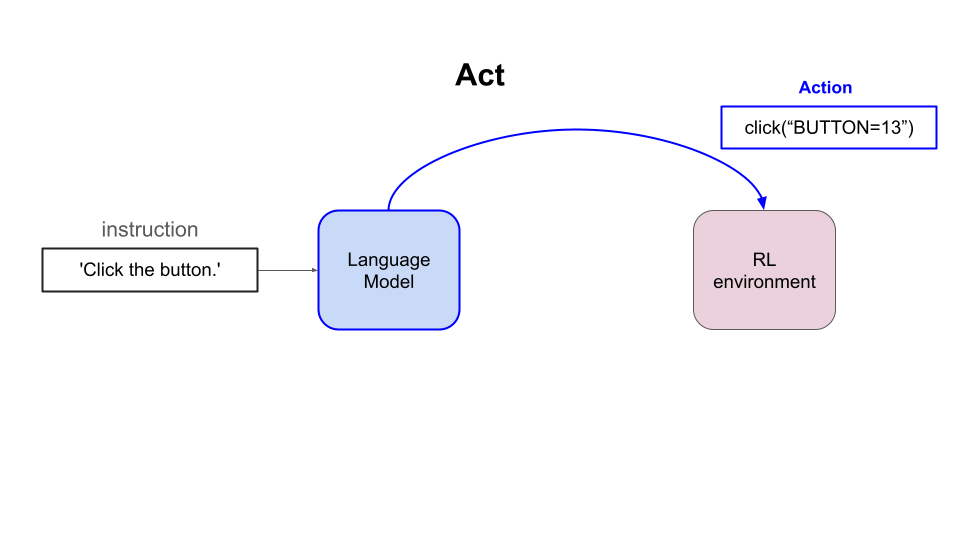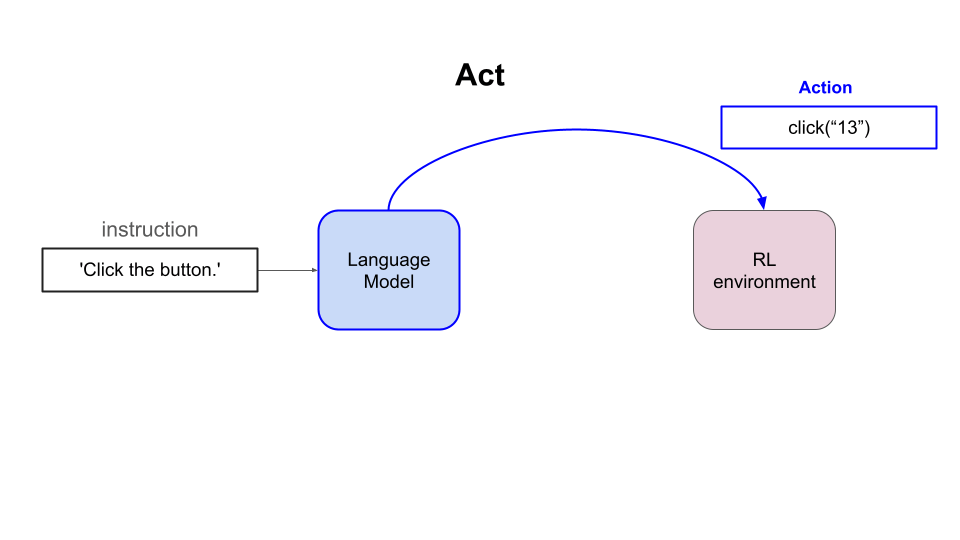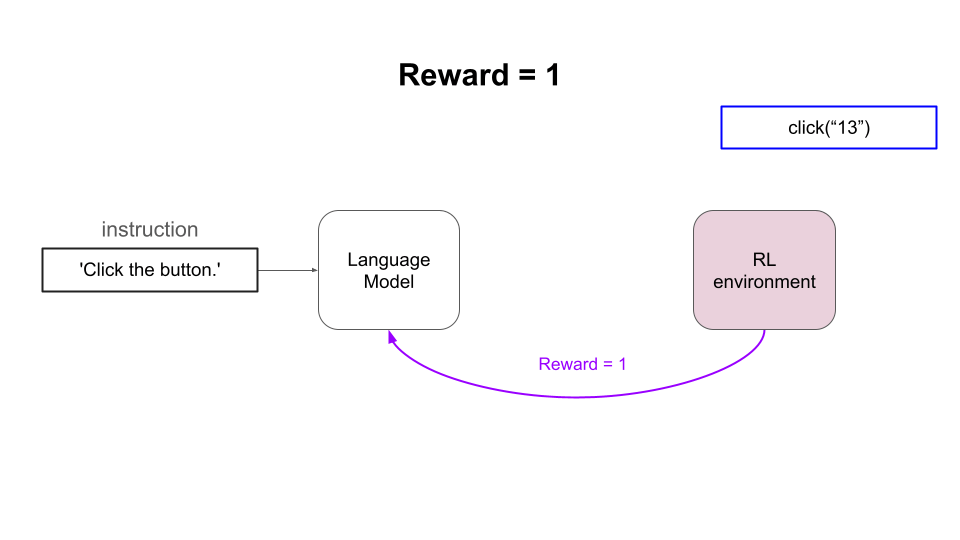
通过足够长时间地重复这个过程,并使用校准良好的强化学习算法,语言模型会在这个任务上越来越好。
浏览器控制任务的奖励可以通过 Playwright 等工具以编程方式计算。Playwright 是一个用于 Web 应用的端到端测试框架,可以:
- 从页面文档对象模型(DOM)中提取结构和内容
- 检查 URL 以验证智能体是否到达所需页面,或者
- 查询数据库以检查智能体是否正确修改了状态
1. 环境 → 通过 OpenEnv 使用 BrowserGym
OpenEnv 是一个开源库,它:
- 标准化了对大量强化学习环境的 Python 访问
- 简化了将强化学习环境部署为独立 Docker 容器的过程,可以在本地、Kubernetes 远程运行或作为 Hugging Face 空间运行
- 帮助 AI 研究人员生成和发布新的强化学习环境
OpenEnv 中的环境之一是 BrowserGym,这是一个包含不同浏览器自动化基准的开源集合:
- Mini World of Bits++(即 MiniWoB)
- WebArena
- VisualWebArena
- WorkArena
MiniWoB 是 BrowserGym 中最简单的基准,因为它包含的任务定义非常明确狭窄。这是强化学习冒险的绝佳起点。以下是这些任务的示例,完整列表可以在这里找到。
在这个项目中使用的是 MiniWoB 中一个简单任务,叫做 click-test,也就是学习点击按钮。

这个任务足够简单,可以展示整个训练流程,而不需要花太多时间训练模型。
读者可以从这个列表中选择另一个任务,投入一些 GPU 资源来达到良好的性能。
2. 强化学习算法 → GRPO
当语言模型与环境交互时,会收集一系列带有来自环境的稀疏奖励的轨迹(rollouts)。强化学习算法(例如 GRPO)使用这些稀疏奖励来调整语言模型参数,以增加获得更大奖励的机会。
以下是针对同一初始提示/任务的4条轨迹示例,模型在这些轨迹中:
- 在第一步解决任务
- 在第二步解决任务
- 在第三步解决任务
- 在4步之后没有解决任务(设置的最大轨迹长度)

GRPO 使用该组内的相对性能来确定应该强化哪些动作。
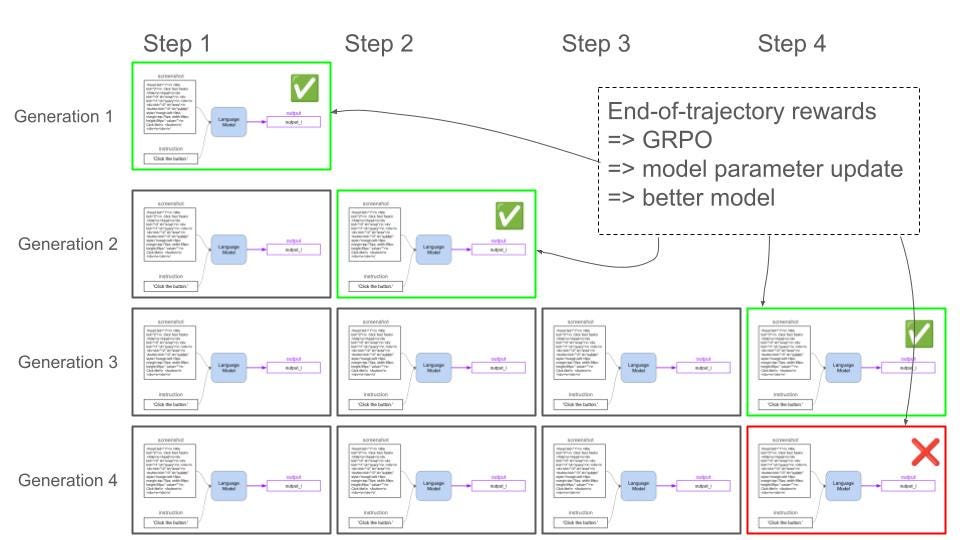
表现优于组内其他成员的响应获得正优势,而表现较差的则获得负优势。这种方法比以前的强化学习算法(如近端策略优化 PPO)更节省内存,因为它不需要为价值函数训练和存储第二个语言模型。
GRPO 已成为 AI 实验室和 AI 从业者使用强化学习训练/微调语言模型时最流行的算法之一。
3. 策略 → LFM2-350M
项目将使用 LFM2-350M,这是一个小而强大且快速的语言模型,具备以下能力:
- 知识(MMLU、GPQA)
- 指令遵循(IFEval、IFBench)
- 数学推理(GSM8K、MGSM),以及
- 多模态理解(MMMU)
为了加快训练速度,还会添加对 LoRA 适配器的支持,这样就不需要对整个模型进行微调。
架构设计
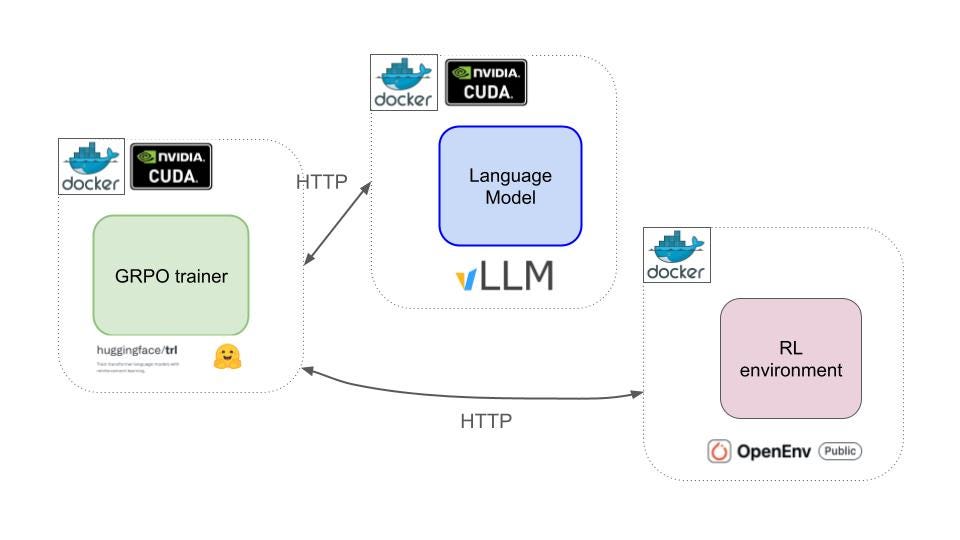
强化学习训练框架的3个组件是:
-
来自 trl 库的
GRPOTrainer,实现 GRPO 算法。它需要在 GPU 上运行,以便更新模型参数的反向传播足够快。 -
用于生成 LFM2-300M 轨迹的
vLLM服务器。它需要在 GPU 上运行以并行化轨迹的生成。 -
带有
BrowserGym环境的 Docker 容器,作为 Hugging Face 空间运行。也可以在本地或 Kubernetes 基础设施上运行。这个可以在 CPU 上运行。
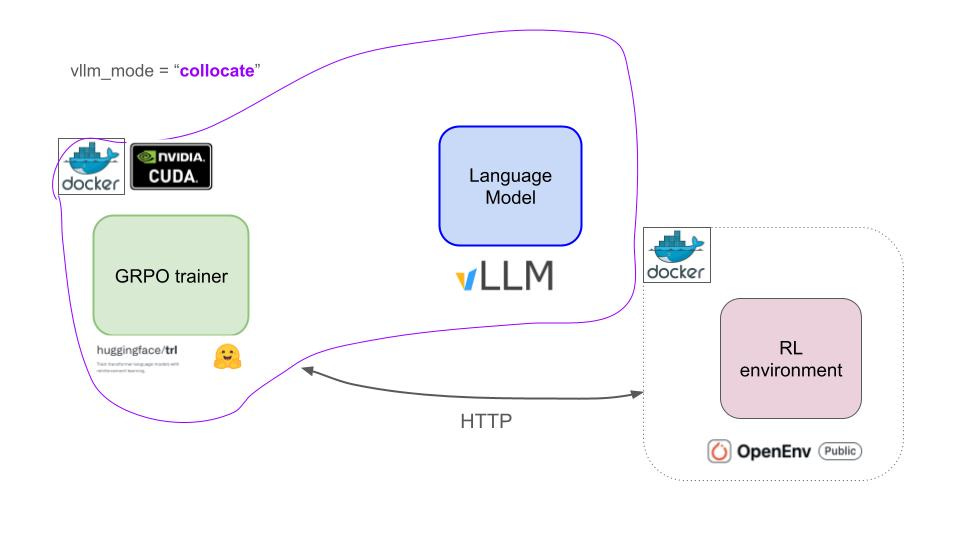
为了简化操作,会在同一个 GPU 上同时运行 GRPOTrainer 和 vLLM。
项目使用 Modal 作为无服务器 GPU 基础设施。Modal 对于不想过多担心基础设施而更愿意按使用量付费的 AI 工程师来说是一个很好的选择。它通过基于 Python 的简单配置提供按需 GPU 访问,可以轻松扩展训练工作负载,而无需管理集群或处理复杂的 DevOps 设置。
实验结果
完整微调
第一个实验是对 LFM2-350M 进行完整微调:
make run config=lfm2_350m.yamlclick-test 任务比较简单,模型从一开始就能在不到10次尝试内解决它。
最终检查点已上传到 HF:
使用 LoRA 进行参数高效微调
使用 LoRA 可以用更少的计算资源和时间达到完整微调的效果。
make run config=lfm2_350m_lora.yaml尝试的任务虽然简单,但准备的代码和基础设施已经可以应对更具挑战性的环境。