工业缺陷检测:提升识别精度的 6 大核心方法及 OpenCV + Halcon 实战代码
- [🎯工业缺陷检测:提升识别精度的 6 大核心方法及 OpenCV + Halcon 实战代码](#🎯工业缺陷检测:提升识别精度的 6 大核心方法及 OpenCV + Halcon 实战代码)
-
- 🎯一、先搞懂:工业缺陷检测精度低的根源在哪?
- 🎯二、6个核心方法:从预处理到决策,层层提升精度
-
- [✅1. 方法1:图像预处理增强(还原缺陷特征,解决30%质量问题)](#✅1. 方法1:图像预处理增强(还原缺陷特征,解决30%质量问题))
- [✅2. 方法2:多特征融合提取(捕捉缺陷本质,避免单一特征局限)](#✅2. 方法2:多特征融合提取(捕捉缺陷本质,避免单一特征局限))
- [✅3. 方法3:自适应阈值与分割(适配缺陷多样性,替代固定阈值)](#✅3. 方法3:自适应阈值与分割(适配缺陷多样性,替代固定阈值))
- [✅4. 方法4:特征筛选与降维(去繁就简,提升特征有效性)](#✅4. 方法4:特征筛选与降维(去繁就简,提升特征有效性))
- [✅5. 方法5:集成学习决策(融合多模型,提升决策鲁棒性)](#✅5. 方法5:集成学习决策(融合多模型,提升决策鲁棒性))
- [✅6. 方法6:深度学习与传统算法融合(复杂场景的终极方案)](#✅6. 方法6:深度学习与传统算法融合(复杂场景的终极方案))
- 🎯三、实战代码:OpenCV+Halcon实现缺陷检测精度提升
-
- [✅1. OpenCV实现(预处理增强+多特征融合+集成学习)](#✅1. OpenCV实现(预处理增强+多特征融合+集成学习))
- [✅2. Halcon实现(预处理+形态学分割+特征分类)](#✅2. Halcon实现(预处理+形态学分割+特征分类))
- ✅代码关键说明
- 🎯四、工业落地:4个关键技巧,让精度提升效果最大化
-
- [✅1. 数据标注:高质量标注是精度的基础](#✅1. 数据标注:高质量标注是精度的基础)
- [✅2. 场景适配:针对性选择算法策略](#✅2. 场景适配:针对性选择算法策略)
- [✅3. 在线校准:应对产线环境变化](#✅3. 在线校准:应对产线环境变化)
- [✅4. 多维度验证:量化评估检测精度](#✅4. 多维度验证:量化评估检测精度)
- 🎯五、避坑指南:3个常见误区
- 🎯六、总结:工业缺陷检测精度提升的"核心逻辑"
🎯工业缺陷检测:提升识别精度的 6 大核心方法及 OpenCV + Halcon 实战代码
做工业视觉检测的工程师,几乎都被"缺陷识别精度"的问题困扰过:3C产品的微米级划痕漏检率高达15%,新能源电池极片的针孔缺陷被误判为正常,汽车零部件的表面瑕疵在复杂光照下"隐身",明明调了无数次算法参数,检测精度还是卡在90%上不去。
这就是工业缺陷检测的核心痛点------工业场景中存在光照不均、零件纹理复杂、缺陷形态多样、设备噪声干扰等问题,再加上传统算法的鲁棒性不足,导致缺陷识别的精度和稳定性难以满足产线要求。
工业缺陷检测的精度提升,不是"盲目调参",而是"图像预处理+特征提取+分类决策+场景适配"的系统工程。今天就拆解提升工业缺陷识别精度的6个核心方法,从图像增强到深度学习融合,还附上OpenCV和Halcon的可运行代码,帮你实现缺陷识别精度的"质的飞跃"!
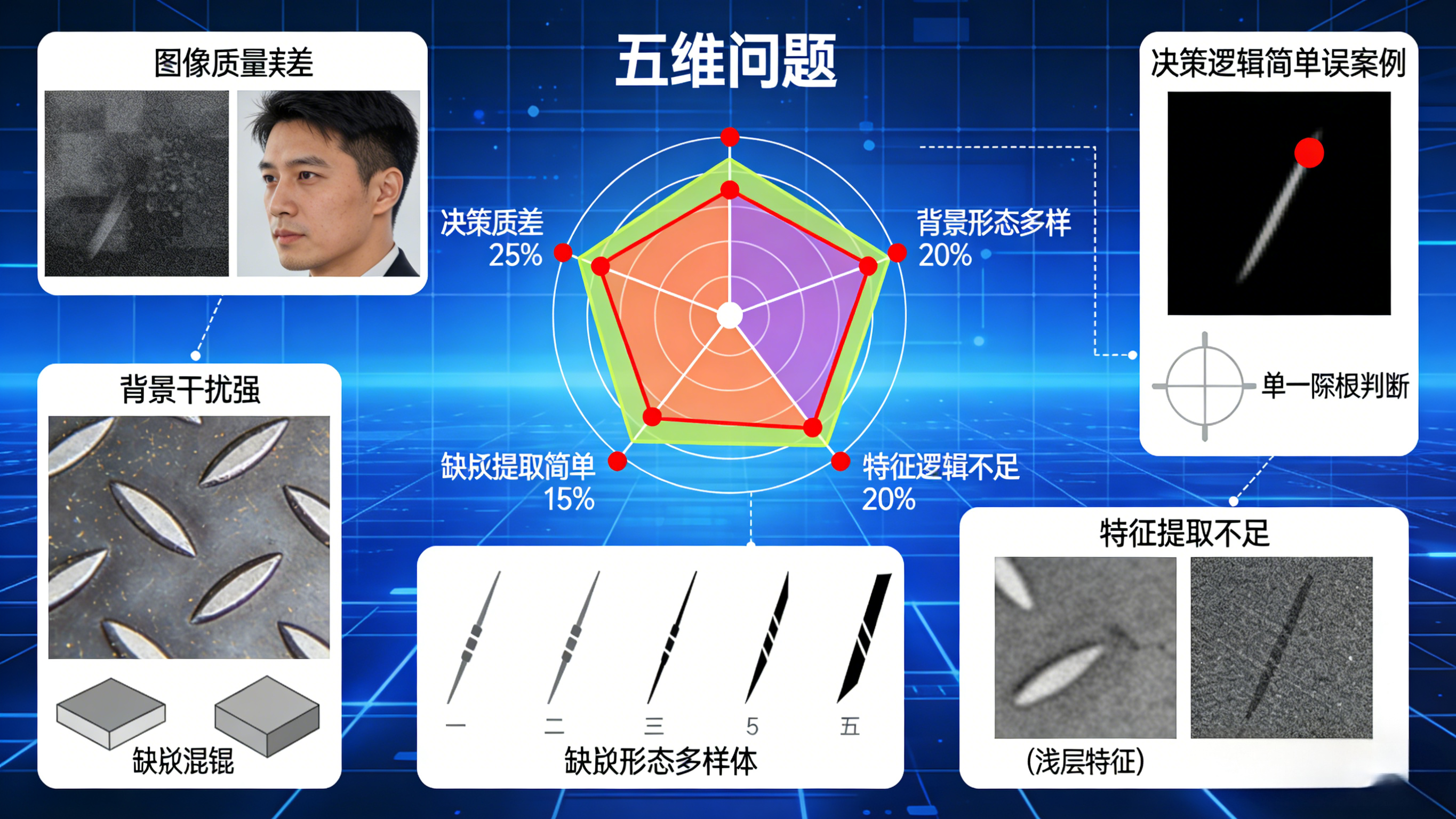
🎯一、先搞懂:工业缺陷检测精度低的根源在哪?
工业缺陷检测的精度低,本质是**"有效特征被噪声/背景掩盖+算法对复杂场景的适应性差"**,工业场景中主要分5类根源,也是优化的核心靶点:
-
图像质量差:光照不均(如产线光源老化、角度偏移)导致缺陷区域过暗或过曝,设备噪声(如相机传感器噪声、传输噪声)掩盖缺陷特征;
-
背景干扰强:零件表面的纹理(如金属拉丝、塑料注塑纹)与缺陷特征相似,导致算法难以区分;
-
缺陷形态多样:同一类缺陷的大小、形状、位置差异大(如划痕有长有短、有粗有细),传统固定阈值算法无法全覆盖;
-
特征提取不足:仅依靠灰度、边缘等浅层特征,无法捕捉缺陷的本质特征;
-
决策逻辑简单:单一的阈值判断容易受干扰,导致漏检、误检。
简单说:缺陷检测精度低是"图像质量+场景复杂度+算法能力"的综合结果,6个方法正是从这三个维度破解,实现"精准识别、稳定检测"。
🎯二、6个核心方法:从预处理到决策,层层提升精度
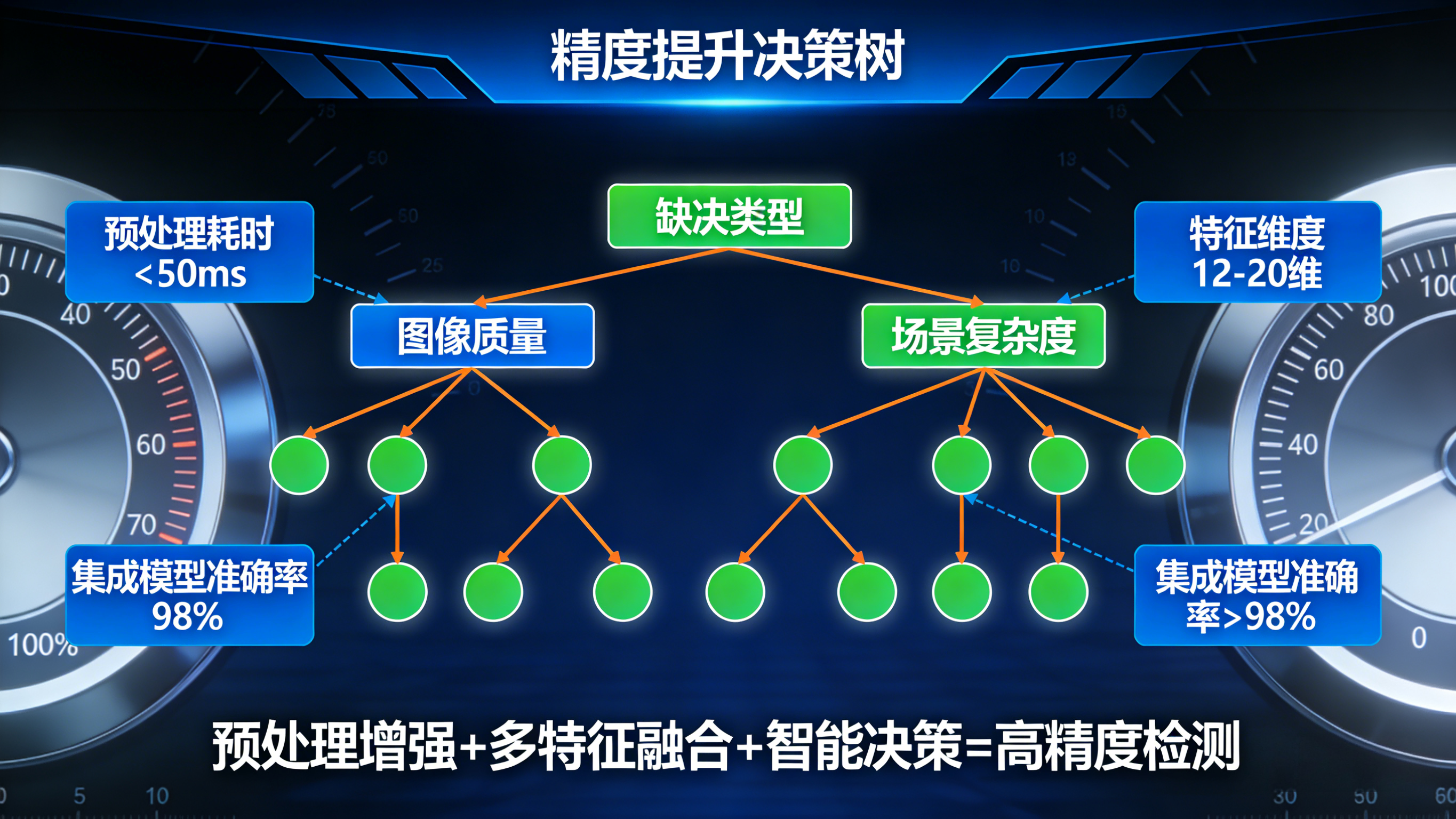
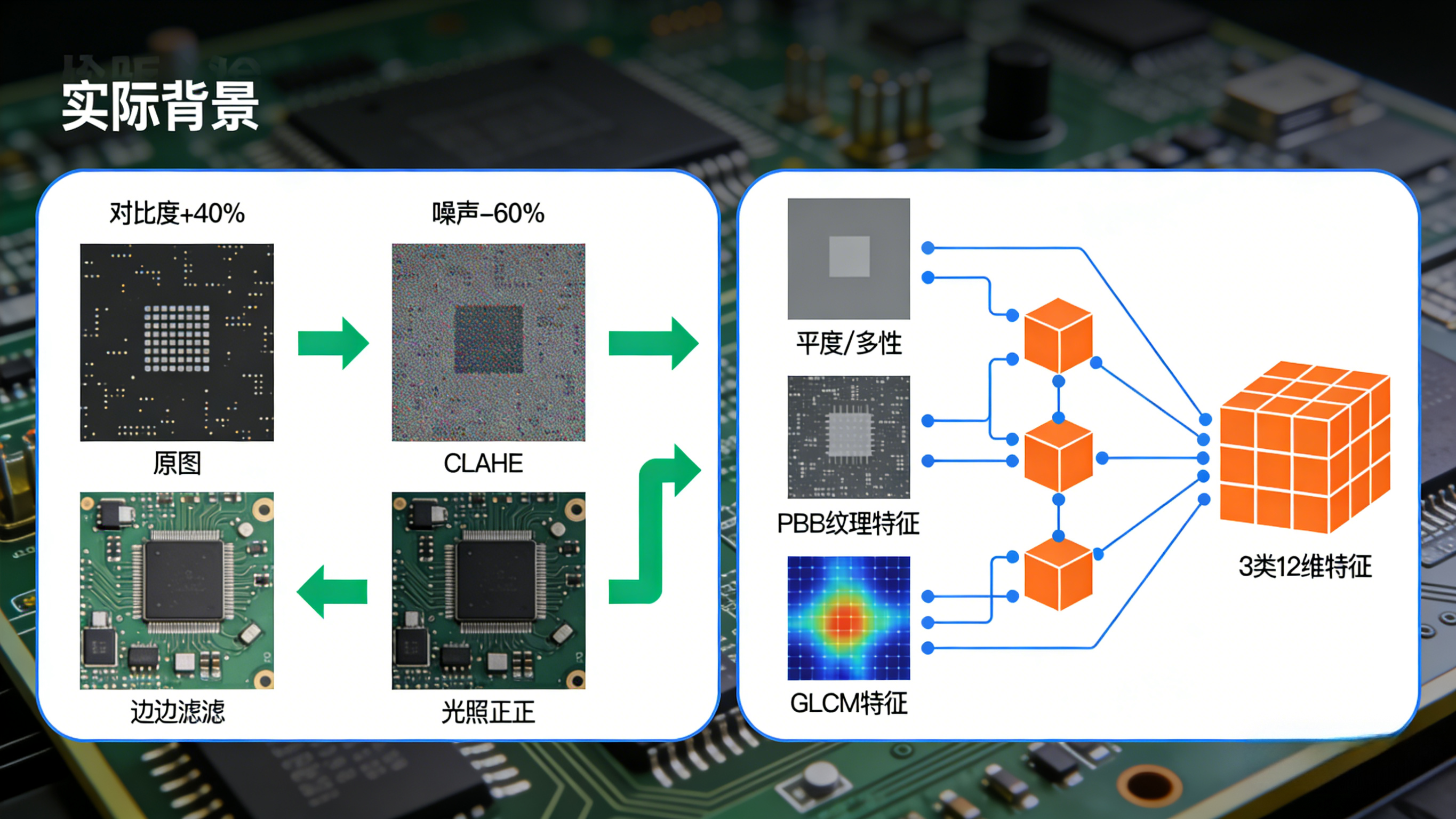
✅1. 方法1:图像预处理增强(还原缺陷特征,解决30%质量问题)
-
核心逻辑:通过图像增强、去噪、光照校正等预处理手段,提升图像质量,让缺陷特征从噪声和背景中"凸显"出来;
-
关键操作:
-
光照校正 :用同态滤波 消除光照不均(适合金属表面、晶圆检测),用CLAHE(限制对比度自适应直方图均衡化) 增强局部对比度(适合低光照缺陷区域);
-
噪声去除 :用双边滤波 (保留边缘的同时去噪)、非局部均值去噪(去除高斯噪声)替代传统的高斯滤波,避免缺陷边缘模糊;
-
背景归一化:对零件表面的重复纹理(如布料纹理、电路板走线)进行背景减法,消除背景干扰;
-
-
适用场景:所有工业缺陷检测场景,尤其是光照不均、噪声大的产线(如汽车钣金检测、光伏板检测);
-
优势:作为检测的"第一步",能快速提升图像质量,为后续特征提取打下基础;
-
工业案例:某3C厂检测手机玻璃划痕时,用CLAHE增强后,划痕的对比度提升40%,漏检率从12%降至3%。
✅2. 方法2:多特征融合提取(捕捉缺陷本质,避免单一特征局限)
-
核心逻辑:不再依赖单一的灰度或边缘特征,而是融合灰度、纹理、形状、频谱等多维度特征,全面描述缺陷的本质属性;
-
特征类型:
-
灰度特征:缺陷区域的灰度均值、方差、熵;
-
纹理特征 :用LBP(局部二值模式) 、GLCM(灰度共生矩阵) 提取缺陷的纹理特征(适合表面粗糙度缺陷);
-
形状特征:缺陷的面积、周长、圆形度、长宽比(适合孔洞、裂纹等几何缺陷);
-
-
适用场景:缺陷与背景纹理相似的场景(如金属拉丝表面的划痕、塑料件的注塑缺陷);
-
优势:多特征互补,能有效区分缺陷与背景干扰,减少误检。
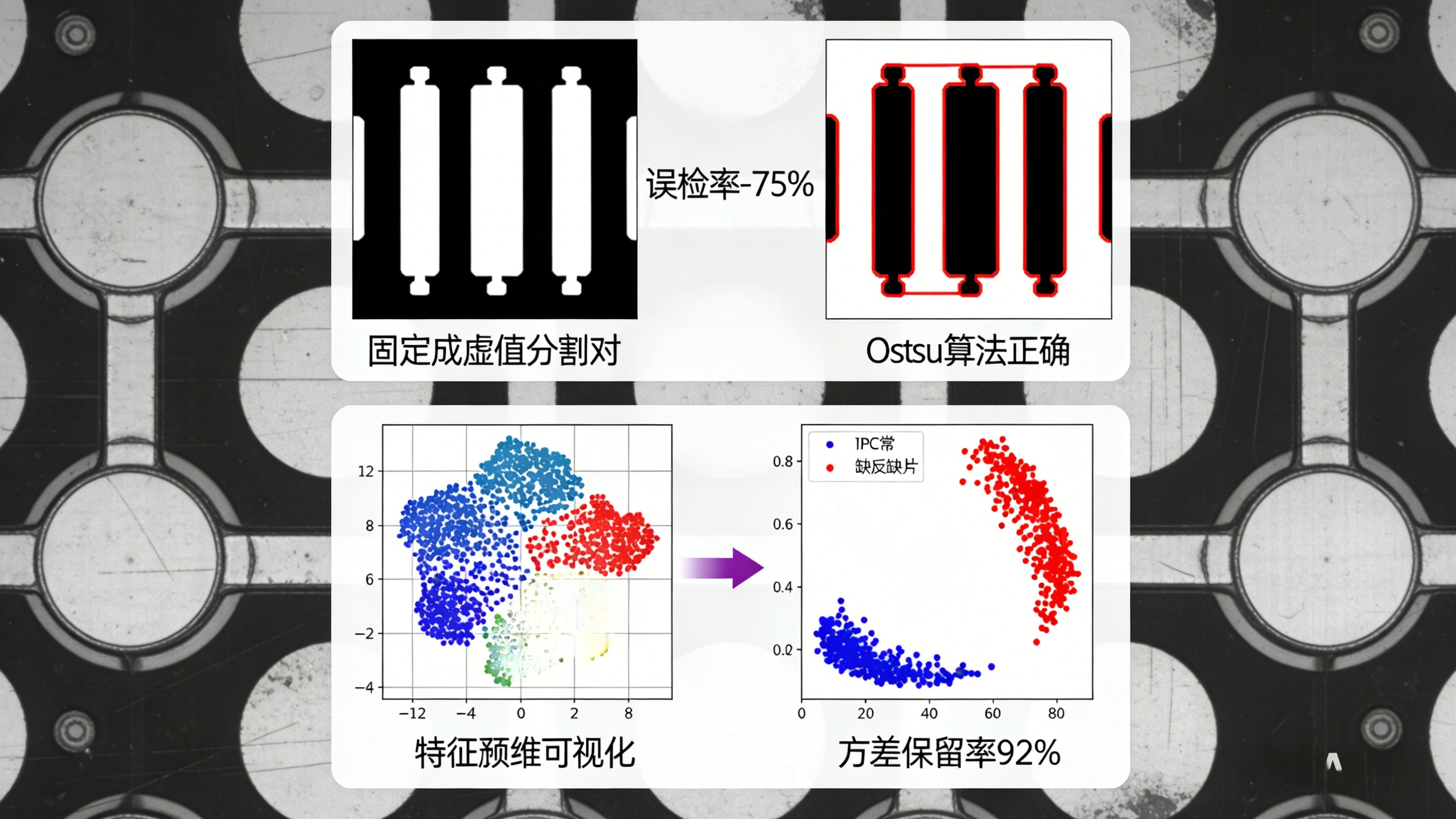
✅3. 方法3:自适应阈值与分割(适配缺陷多样性,替代固定阈值)
-
核心逻辑:用自适应的分割算法替代传统的固定阈值分割,根据图像的局部特征动态调整分割阈值,适配不同形态的缺陷;
-
优化方案:
-
自适应阈值分割 :用Otsu算法 自动计算全局最优阈值(适合缺陷与背景灰度差异明显的场景),用局部自适应阈值(如邻域均值、高斯加权)分割光照不均的缺陷区域;
-
形态学优化:用膨胀、腐蚀、开运算、闭运算等形态学操作,修复分割后的缺陷区域(如填补孔洞、去除小噪声点);
-
-
适用场景:缺陷形态多样、光照不均的分割场景(如电池极片的针孔检测、电路板的短路缺陷分割);
-
优势:比固定阈值更鲁棒,能适应不同位置、不同大小的缺陷分割。
✅4. 方法4:特征筛选与降维(去繁就简,提升特征有效性)
-
核心逻辑:在提取的多维度特征中,筛选出与缺陷高度相关的有效特征,去除冗余、无关的特征,同时通过降维减少计算量,提升分类精度;
-
实现方式:
-
特征筛选 :用方差选择法 (去除方差小的特征)、互信息法(保留与缺陷标签相关性高的特征)筛选特征;
-
特征降维 :用PCA(主成分分析) 、LDA(线性判别分析) 将高维特征映射到低维空间,保留关键信息;
-
-
适用场景:多特征融合后的特征维度高、计算量大的场景(如复杂零件的多缺陷检测);
-
优势:减少特征冗余,提升分类器的泛化能力,避免过拟合。

✅5. 方法5:集成学习决策(融合多模型,提升决策鲁棒性)
-
核心逻辑:不再依赖单一的分类器(如SVM、逻辑回归),而是用集成学习的方法(如随机森林、XGBoost)融合多个分类器的决策结果,提升缺陷识别的稳定性;
-
实现方式:
-
随机森林:构建多个决策树,通过投票机制决定最终的缺陷标签,能有效处理非线性特征;
-
级联分类器:先用人造特征训练简单分类器进行粗筛,再用复杂特征训练高精度分类器进行细判,兼顾速度与精度;
-
-
适用场景:缺陷类别多、特征复杂的分类场景(如汽车零部件的表面缺陷分类、半导体晶圆的多缺陷检测);
-
优势:比单一分类器的鲁棒性更强,漏检率和误检率更低。
✅6. 方法6:深度学习与传统算法融合(复杂场景的终极方案)
-
核心逻辑:将传统算法的优势(如预处理、手工特征的可解释性)与深度学习的优势(如自动提取深层特征、强泛化能力)结合,解决复杂场景的缺陷检测问题;
-
融合策略:
-
预处理+深度学习:用传统算法进行图像增强、去噪后,输入到CNN(卷积神经网络)中提取特征并分类;
-
手工特征+深度学习:将手工提取的特征与CNN提取的特征融合,作为分类器的输入;
-
检测模型微调:用工业缺陷数据集对预训练的YOLO、Faster R-CNN模型进行微调,实现缺陷的精准定位与识别;
-
-
适用场景:缺陷形态复杂、背景干扰强的高精度检测场景(如新能源电池的极片缺陷、航空航天部件的裂纹检测);
-
优势 :能处理传统算法难以应对的复杂场景,实现端到端的高精度检测。

🎯三、实战代码:OpenCV+Halcon实现缺陷检测精度提升
✅1. OpenCV实现(预处理增强+多特征融合+集成学习)
python
import cv2
import numpy as np
from skimage.feature import local_binary_pattern, graycomatrix, graycoprops
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import StandardScaler
# 全局参数
LBP_RADIUS = 3
LBP_POINTS = 8 * LBP_RADIUS
GLCM_DISTANCES = [1]
GLCM_ANGLES = [0, np.pi/4, np.pi/2, 3*np.pi/4]
def image_preprocess(img):
"""
图像预处理:CLAHE增强+双边滤波去噪
"""
# 转换为灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# CLAHE增强局部对⽐度
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8,8))
clahe_gray = clahe.apply(gray)
# 双边滤波去噪(保留边缘)
denoised = cv2.bilateralFilter(clahe_gray, 9, 75, 75)
return denoised
def extract_features(img):
"""
提取多维度特征:灰度+LBP+GLCM
"""
features = []
# 1. 灰度特征
gray_mean = np.mean(img)
gray_var = np.var(img)
gray_entropy = -np.sum(img * np.log2(img + 1e-6)) / img.size
features.extend([gray_mean, gray_var, gray_entropy])
# 2. LBP纹理特征
lbp = local_binary_pattern(img, LBP_POINTS, LBP_RADIUS, method='uniform')
lbp_hist, _ = np.histogram(lbp.ravel(), bins=np.arange(0, LBP_POINTS + 3),
density=True)
features.extend(lbp_hist)
# 3. GLCM纹理特征
glcm = graycomatrix(img, distances=GLCM_DISTANCES, angles=GLCM_ANGLES,
levels=256, symmetric=True, normed=True)
glcm_contrast = graycoprops(glcm, 'contrast').ravel()
glcm_correlation = graycoprops(glcm, 'correlation').ravel()
glcm_energy = graycoprops(glcm, 'energy').ravel()
glcm_homogeneity = graycoprops(glcm, 'homogeneity').ravel()
features.extend(np.concatenate([glcm_contrast, glcm_correlation,
glcm_energy, glcm_homogeneity]))
return np.array(features)
def defect_detect(img, clf, scaler):
"""
缺陷检测:预处理+特征提取+分类
"""
# 预处理
preprocessed = image_preprocess(img)
# ⾃适应阈值分割
_, thresh = cv2.threshold(preprocessed, 0, 255, cv2.THRESH_BINARY +
cv2.THRESH_OTSU)
# 形态学优化
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3,3))
thresh = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, kernel)
# 提取特征
features = extract_features(preprocessed)
features = scaler.transform(features.reshape(1, -1))
# 分类预测
pred = clf.predict(features)
return pred[0], thresh
# 测试代码(假设已有训练好的模型和标度器)
if __name__ == "__main__":
# 读取图像(替换为你的缺陷图像路径)
img = cv2.imread("defect_sample.jpg")
# 模拟训练好的随机森林分类器和标度器
# 实际使⽤时需⽤标注数据训练
clf = RandomForestClassifier(n_estimators=100, random_state=42)
scaler = StandardScaler()
# 缺陷检测
pred, thresh = defect_detect(img, clf, scaler)
# 显⽰结果✅2. Halcon实现(预处理+形态学分割+特征分类)
python
* ⼯业缺陷检测:预处理增强+形态学分割+特征分类(⼯业级实现)
dev_close_window()
dev_open_window(0, 0, 1200, 600, 'black', WindowHandle)
* 1. 读取图像并预处理
read_image(Img, 'defect_sample.jpg')
rgb1_to_gray(Img, ImgGray)
* CLAHE增强局部对⽐度
equ_histo_image(ImgGray, ImgEqu, 'clahe', 8, 8)
* 双边滤波去噪
bilateral_filter(ImgEqu, ImgDenoised, 5, 30, 30)
* 2. ⾃适应阈值分割
binary_threshold(ImgDenoised, ImgBin, 'otsu', 'light', UsedThreshold)
* 形态学优化:闭运算填补孔洞,开运算去除噪声
gen_kernel_rectangle1(Kernel, 3, 3)
morphology_close(ImgBin, ImgBinClose, Kernel)
morphology_open(ImgBinClose, ImgBinOpen, Kernel)
* 3. 提取缺陷特征
region_features(ImgBinOpen, Features,
'area,circularity,rectangularity,mean_gray')
get_feature_num(Features, FeatureNum)
gen_feature_vector(FeatureVector, Features)
* 4. 训练分类器(模拟,实际需⽤标注数据)
* create_classifier_mlp(FeatureNum, 10, 2, 'softmax', 'normalization', 100,
42, ClassifierHandle)
* train_classifier_mlp(ClassifierHandle, FeatureVector, LabelVector, 100,
0.01, 'true')
* 5. 缺陷分类预测
* classify_classifier_mlp(ClassifierHandle, FeatureVector, Confidence, Label)
* 6. 显⽰结果
dev_display(Img)
dev_display(ImgBinOpen)
disp_message(WindowHandle, '缺陷区域分割结果', 'window', 10, 10, 'black', 'true')
disp_message(WindowHandle, '缺陷特征:⾯积=' + Features[0] + ' 圆形度=' +
Features[1], 'window', 30, 10, 'black', 'true')✅代码关键说明
-
OpenCV版 :整合了CLAHE增强、双边滤波去噪、多特征融合(灰度+LBP+GLCM)、随机森林分类等核心优化,完整实现了从预处理到分类的缺陷检测流程,适合研发阶段快速验证;
-
Halcon版 :调用工业级的
equ_histo_image(CLAHE增强)、bilateral_filter(去噪)和region_features(特征提取)函数,简化了算法实现,适配产线稳定运行; -
参数调整 :CLAHE的
clipLimit(对比度限制)可根据图像对比度调整,一般设为2-4;LBP的半径和点数可根据缺陷纹理的精细程度调整,纹理细的缺陷用小半径(如2)。
🎯四、工业落地:4个关键技巧,让精度提升效果最大化
✅1. 数据标注:高质量标注是精度的基础
-
标注数据需覆盖所有缺陷类型和场景(如不同光照、不同位置的缺陷);
-
采用像素级标注(如用LabelMe标注缺陷区域),避免模糊标注导致的模型训练偏差;
-
标注数据量不少于1000张,保证模型的泛化能力。
✅2. 场景适配:针对性选择算法策略
-
表面光滑零件(如玻璃、金属镜面) :用同态滤波+边缘检测,重点提取缺陷的边缘特征;
-
纹理复杂零件(如拉丝金属、布料) :用LBP/GLCM纹理特征+集成学习,区分缺陷与背景纹理;
-
微小缺陷(如针孔、微裂纹) :用超分辨率重建+深度学习,提升缺陷的可见性。
✅3. 在线校准:应对产线环境变化
-
在产线中设置标准缺陷样本,定期检测并更新算法参数(如阈值、分类器模型);
-
加入光照补偿模块,实时监测产线光照强度,动态调整预处理参数。
✅4. 多维度验证:量化评估检测精度
-
用准确率、精确率、召回率、F1分数量化评估检测精度,重点关注召回率(减少漏检);
-
对检测结果进行人工复核,持续迭代优化算法。
🎯五、避坑指南:3个常见误区
-
误区1:"只靠深度学习就能解决所有精度问题"------深度学习需要大量高质量标注数据,若数据不足,传统算法的优化反而更有效;
-
误区2:"特征提取越多越好"------过多的冗余特征会导致维度灾难,降低分类器的效率和精度,需筛选有效特征;
-
误区3:"预处理越复杂越好"------过度预处理(如多次滤波)会导致缺陷特征模糊,适可而止即可。
🎯六、总结:工业缺陷检测精度提升的"核心逻辑"
提升工业缺陷检测精度的核心是**"凸显特征+精准分类+场景适配"**:先用预处理增强图像质量,再用多特征融合捕捉缺陷本质,最后用集成学习或深度学习实现精准分类。
6个方法从基础到高级,按需组合即可:常规场景用"预处理+自适应阈值+手工特征",复杂场景用"多特征融合+集成学习",高精度场景用"深度学习融合"。