运行一个大模型,确实就像运行一个庞大而精密的数字工厂:
芯片(硬件)是工厂的机器与动力源,而计算框架(软件)是整个工厂的流水线、控制系统和操作手册。两者深度融合,缺一不可。
我们可以将其理解为一个分层的技术栈,下图清晰地展示了从底层硬件到顶层应用的核心层次与协同关系:
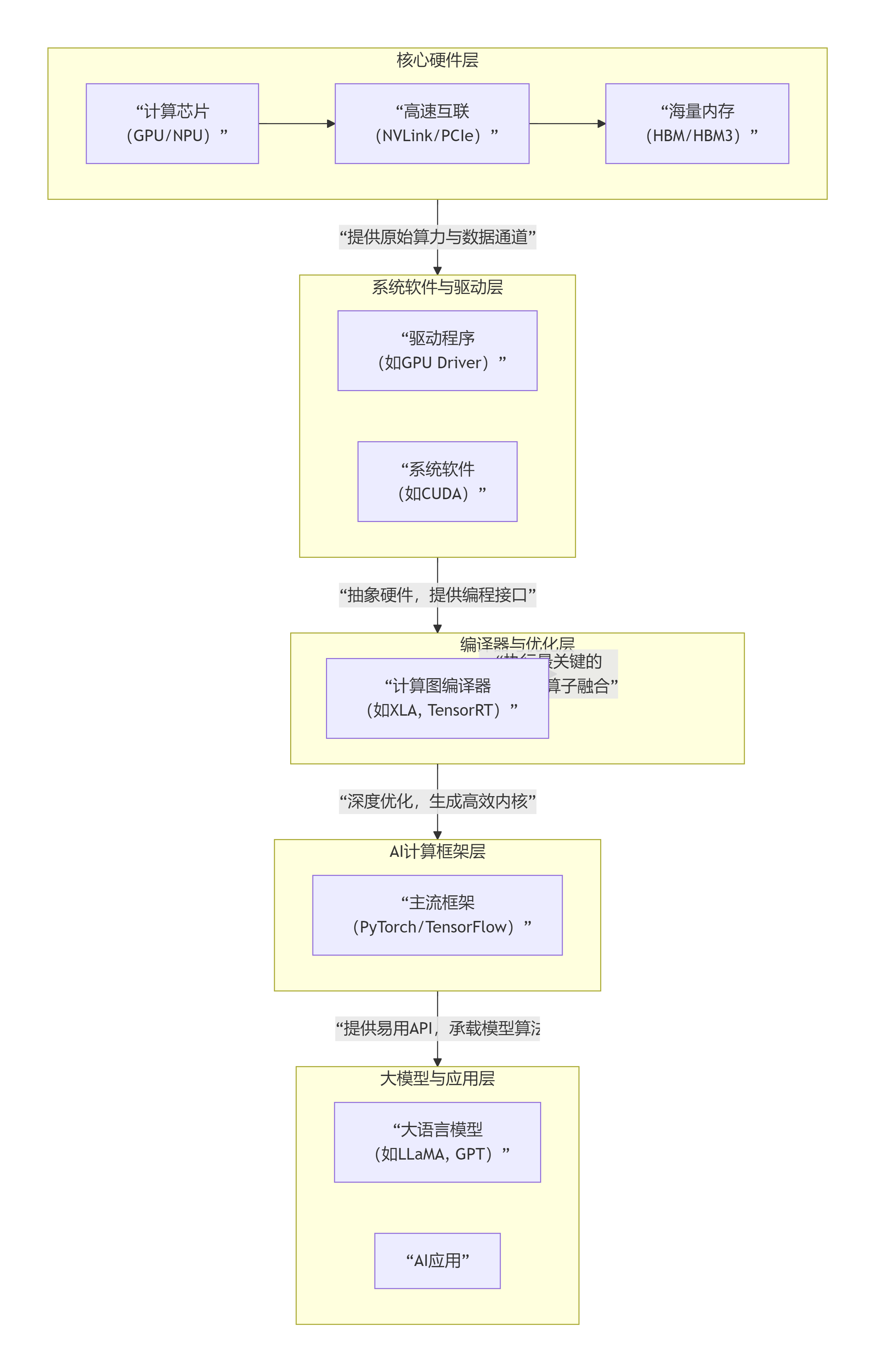
上图展示了一个典型的技术栈,其中最关键的协同发生在两个"粘合层":
-
框架与硬件的"翻译官":驱动和编译器
-
驱动程序:直接控制芯片,但框架不直接与它对话。
-
系统软件 :以英伟达的 CUDA 为例,它建立了一套从PyTorch等框架到GPU硬件的完整生态。框架调用
CUDA函数,CUDA再驱动GPU工作。对于其他芯片(如华为昇腾NPU),其对应的 CANN 也扮演相同角色。 -
计算图编译器 :这是性能关键 。框架将模型描述为一个计算图,编译器(如PyTorch的 TorchScript 、Google的 XLA 、英伟达的 TensorRT)会对整个图进行深度优化:包括将多个操作融合为一个更高效的内核、为特定芯片选择最佳算子实现、优化内存布局等。最终将高级模型"翻译"成在目标芯片上运行最高效的机器指令。
-
-
芯片为框架和模型提供的核心支撑
-
算力 :GPU/NPU提供的TFLOPS/TOPS指标,直接决定了训练和推理的速度。
-
显存容量与带宽 :大模型的参数动辄数百亿,需要被全部加载进芯片的高带宽内存 中。HBM的带宽直接决定了芯片"喂饱"自己计算核心的能力,带宽不足会成为瓶颈。
-
高速互联 :当单个芯片无法容纳整个模型时(如万亿参数模型),必须使用多卡并行。NVLink 、InfiniBand等超高速互联技术,决定了多卡之间交换数据(梯度、激活值)的效率,是实现大规模分布式训练的基础。
-
实际影响与选型启示
这种深度耦合带来了一个核心现实:选择芯片,往往就是选择其软件生态。
-
英伟达(NVIDIA) :凭借 CUDA + cuDNN + TensorRT 的全栈封闭生态,成为了行业事实标准。PyTorch/TensorFlow对其支持最成熟,新论文的代码默认在其上运行。选择它,意味着最少的兼容性烦恼和最丰富的社区资源。
-
其他芯片(AMD、华为、寒武纪等) :必须通过自己的软件栈去兼容主流框架(PyTorch/TensorFlow)。其成功与否,不取决于峰值算力,而取决于软件栈的兼容性、稳定性和性能表现。这需要巨大的软件投入。
未来趋势:协同设计与软硬一体
-
框架感知的芯片设计:芯片公司会深入研究主流框架和模型(如Transformer)的计算模式,在硬件中加入专用单元(如Transformer引擎)。
-
芯片感知的框架优化:框架和编译器会针对不同芯片的微架构进行深度优化,发挥其最大潜力。
-
统一编程接口的出现 :为了打破生态锁,OpenXLA 、MLIR 等开源编译器中间表示项目正在兴起,旨在让同一份模型代码能高效部署到任何硬件上,这是未来重要的演进方向。
总结来说,大模型的竞赛是"系统级"的竞赛。芯片提供"肌肉",计算框架提供"神经和骨骼"。只有两者深度协同、高效匹配,才能构建出支撑大模型智能的强健躯体。 在选择技术路线时,必须将芯片和框架作为一个整体来评估。