1.下载 WORD 数据集
WORD 官方仓库在这里:https://github.com/HiLab-git/WORD
建议BaiduPan 下载。password for BaiduPan isABOD, and the WORD dataset unzip password is word@uest
2. 创建 conda 环境
java
conda create -n nnunetv2 python=3.10 -y
conda activate nnunetv2踩雷,NumPy 版本是 nnUNetv2容易踩坑的点。记得卸载numpy,然后换成numpy1.26.4
一句话解决(最稳)
java
pip uninstall -y numpy
pip install "numpy==1.26.4"2.1 安装 PyTorch
请各位根据自己的cuda版本安装pytorch。因为我的cuda版本是12.1,所以我安装:
java
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121验证 GPU 可用:
java
python -c "import torch; print('torch:', torch.__version__); print('cuda:', torch.cuda.is_available())"安装 nnUNetv2
java
pip install nnunetv23.配置 nnUNetv2 三个路径环境变量(关键)
nnUNet 需要 3 个环境变量:nnUNet_raw / nnUNet_preprocessed / nnUNet_results。官方文档明确要求这样设置。
以你实际路径为例(这里用的是 /workspace/nnUnetv2/):
python
mkdir -p /workspace/nnUnetv2/nnUNet_raw
mkdir -p /workspace/nnUnetv2/nnUNet_preprocessed
mkdir -p /workspace/nnUnetv2/nnUNet_results
export nnUNet_raw="/workspace/nnUnetv2/nnUNet_raw"
export nnUNet_preprocessed="/workspace/nnUnetv2/nnUNet_preprocessed"
export nnUNet_results="/workspace/nnUnetv2/nnUNet_results"验证:
python
echo $nnUNet_raw
echo $nnUNet_preprocessed
echo $nnUNet_results4.准备 WORD 数据为 nnUNet 格式
nnUNet 的数据格式规范见官方 dataset_format.md:核心是 imagesTr/labelsTr/imagesTs + dataset.json,并且图像文件名必须带通道后缀 _0000(单模态也要)。
4.1目录命名:必须是 DatasetXXX_NAME
nnUNetv2 要求 raw 数据集目录形如:nnUNet_raw/Dataset500_WORD/
python
/workspace/nnUnetv2/nnUNet_raw/Dataset500_WORD/
├── dataset.json
├── imagesTr
│ ├── case_0001_0000.nii.gz
│ ├── case_0002_0000.nii.gz
│ └── ...
├── labelsTr
│ ├── case_0001.nii.gz
│ ├── case_0002.nii.gz
│ └── ...
└── imagesTs
├── case_0101_0000.nii.gz
└── ...4.2 统一给 imagesTr/imagesTs 加 _0000 后缀(单模态必做)
在数据集目录下执行:
python
cd "$nnUNet_raw/Dataset500_WORD" || exit 1
# imagesTr:只给尚未带 _0000 的加后缀
for f in imagesTr/*.nii.gz; do
b=$(basename "$f")
[[ "$b" == *"_0000.nii.gz" ]] && continue
base="${b%.nii.gz}"
mv "$f" "imagesTr/${base}_0000.nii.gz"
done
# imagesTs:如果存在则同理
if ls imagesTs/*.nii.gz 1> /dev/null 2>&1; then
for f in imagesTs/*.nii.gz; do
b=$(basename "$f")
[[ "$b" == *"_0000.nii.gz" ]] && continue
base="${b%.nii.gz}"
mv "$f" "imagesTs/${base}_0000.nii.gz"
done
fi4.3 修改dataset.json
将旧的/workspace/nnUnetv2/nnUNet_raw/Dataset500_WORD/dataset.json全部替换为:
python
{
"name": "WORD",
"channel_names": {
"0": "CT"
},
"labels": {
"background": 0,
"liver": 1,
"spleen": 2,
"left_kidney": 3,
"right_kidney": 4,
"stomach": 5,
"gallbladder": 6,
"esophagus": 7,
"pancreas": 8,
"duodenum": 9,
"colon": 10,
"intestine": 11,
"adrenal": 12,
"rectum": 13,
"bladder": 14,
"Head_of_femur_L": 15,
"Head_of_femur_R": 16
},
"numTraining": 100,
"file_ending": ".nii.gz"
}5. 预处理(计划生成处理后图片)
执行 nnUNetv2_plan_and_preprocess -d 500 --verify_dataset_integrity
完成后你会在 nnUNet_preprocessed/Dataset500_WORD/ 看到诸如:
6. 训练(两种写法)
6.1 快速跑通(fold=all)
java
nnUNetv2_train 500 3d_fullres all --npz6.2 标准 5-fold(更规范,推理时默认可集成)
java
for f in 0 1 2 3 4; do
nnUNetv2_train 500 3d_fullres $f --npz
done7 推理生成预测图(使用 checkpoint_best.pth)
python
CUDA_VISIBLE_DEVICES=1 nnUNetv2_predict \
-i "$nnUNet_raw/Dataset500_WORD/imagesTs" \
-o "/workspace/nnUnetv2/WORD_pred_3d_fullres_best" # 没有这个文件夹会自动创建\
-d 500 \
-c 3d_fullres \
-f all \
-chk "/workspace/nnUnetv2/nnUNet_results/Dataset500_WORD/nnUNetTrainer__nnUNetPlans__3d_fullres/fold_all/checkpoint_best.pth"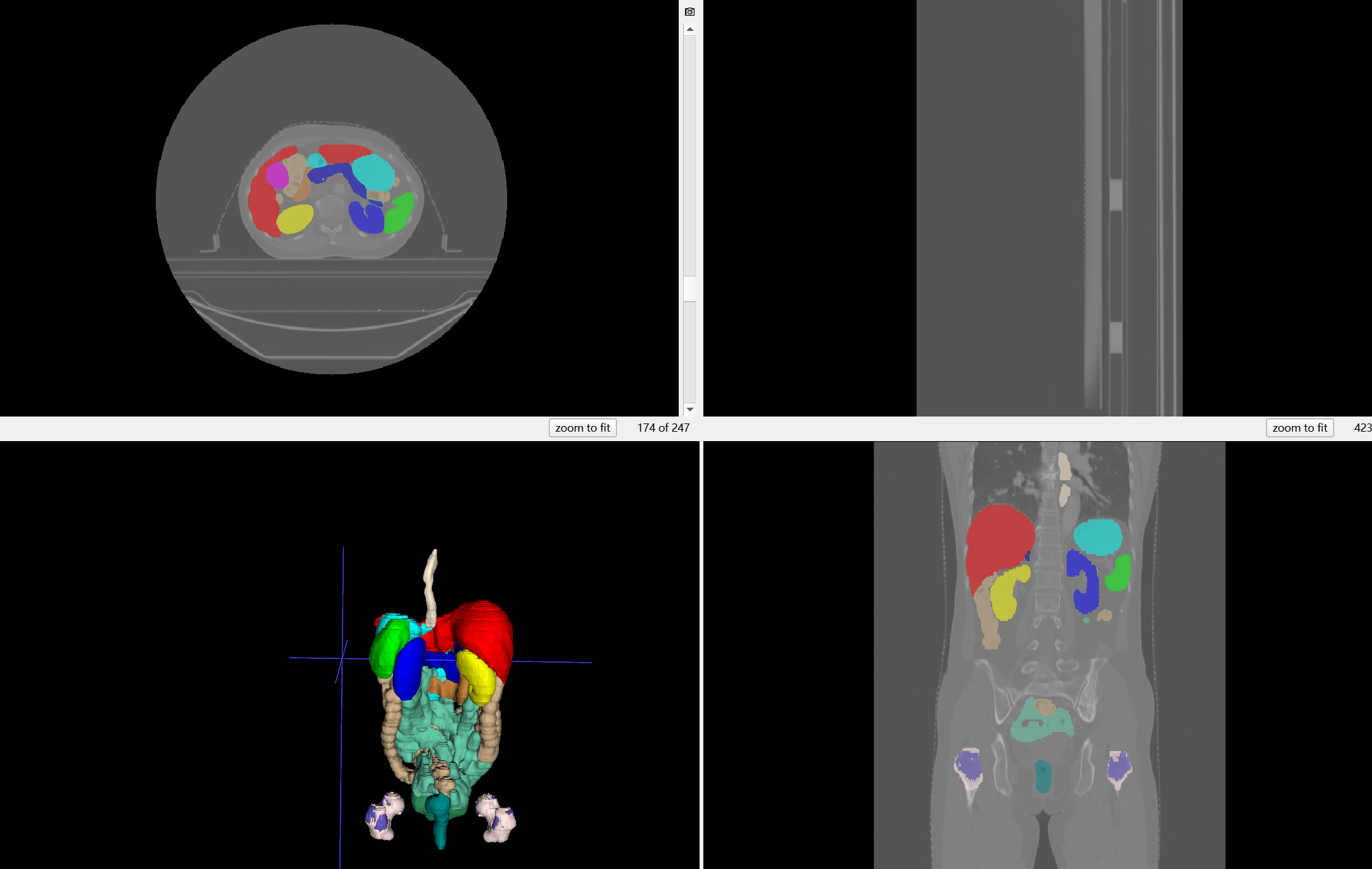
友情提示:我处理好的数据在这里下载:通过网盘分享的文件:nnUNet_preprocessed.zip
链接: https://pan.baidu.com/s/1mCoFwj4w7ZvyR5KMgOX40w?pwd=uaj8 提取码: uaj8
--来自百度网盘超级会员v9的分享
将处理好的数据文件夹直接替换成/path/to/your/dir/nnUNet_preprocessed