基于 TensorFlow+CNN 的水果图像识别系统设计与实现
文章目录
- [基于 TensorFlow+CNN 的水果图像识别系统设计与实现](#基于 TensorFlow+CNN 的水果图像识别系统设计与实现)
-
- 摘要
- [一、 项目背景与技术栈](#一、 项目背景与技术栈)
- [二、 数据集准备与增强策略](#二、 数据集准备与增强策略)
- [三、 CNN 模型架构设计](#三、 CNN 模型架构设计)
- [四、 训练结果与可视化评估](#四、 训练结果与可视化评估)
-
- [1. 准确率与损失曲线 (Accuracy & Loss)](#1. 准确率与损失曲线 (Accuracy & Loss))
- [2. 混淆矩阵 (Confusion Matrix) 分析](#2. 混淆矩阵 (Confusion Matrix) 分析)
- [3. 预测结果抽样](#3. 预测结果抽样)
- [五、 Flask Web 端部署 (工程化落地)](#五、 Flask Web 端部署 (工程化落地))
- [六、 总结](#六、 总结)
摘要
本文详细介绍如何基于 TensorFlow 2.x 深度学习框架,从零构建一个卷积神经网络(CNN)模型,实现对苹果、香蕉、葡萄、橙子、梨五种常见水果的精准识别。文章将深入解析数据增强策略、CNN 网络架构设计、训练过程可视化(准确率/损失曲线),并重点通过混淆矩阵(Confusion Matrix)对模型性能进行深度评估,最后基于 Flask + AJAX 实现 Web 端的无刷新可视化部署。
一、 项目背景与技术栈
图像分类是计算机视觉的基础任务。本项目旨在解决小样本下的多分类问题,并将算法落地为可交互的 Web 系统。技术架构如下:
- 深度学习框架:TensorFlow / Keras
- 开发语言:Python 3.9
- 数据处理:Numpy, Pandas, PIL
- 可视化分析:Matplotlib, Seaborn (热力图绘制)
- Web 部署:Flask (后端), HTML5/JavaScript (前端 AJAX 交互)
二、 数据集准备与增强策略
为了防止 CNN 模型在有限数据集上出现过拟合(Overfitting),我们在训练阶段引入了在线数据增强(Online Data Augmentation)。
利用 Keras 的 ImageDataGenerator,在内存中实时生成经过变换的图像数据,使模型学习到更强的泛化特征。
核心代码实现
python
# 数据增强配置
train_datagen = ImageDataGenerator(
rescale=1./255, # 像素归一化
validation_split=0.3, # 划分 30% 为验证集
rotation_range=30, # 随机旋转 ±30度
width_shift_range=0.2, # 水平位移
height_shift_range=0.2, # 垂直位移
shear_range=0.2, # 错切变换
zoom_range=0.2, # 随机缩放
horizontal_flip=True, # 水平翻转
fill_mode='nearest'
)
# 验证集仅做归一化,不进行增强
test_datagen = ImageDataGenerator(rescale=1./255, validation_split=0.3)三、 CNN 模型架构设计
本项目采用自定义的 Sequential 模型,包含 4 个卷积块和全连接分类层。相比于简单的 MLP,CNN 通过卷积核(Kernel)提取图像的空间特征(如边缘、纹理、形状),并通过池化层(Pooling)降低维度。
网络结构详解
- 特征提取层 :
- Conv2D:使用 3x3 卷积核,激活函数为 ReLU。卷积核数量逐层递增(32 -> 64 -> 128 -> 128),以提取从低级纹理到高级语义的特征。
- MaxPooling2D:2x2 池化,压缩特征图大小,减少计算量并保留主要特征。
- 分类层 :
- Flatten:将多维特征图展平为一维向量。
- Dense (512):全连接层,整合特征。
- Dropout (0.5):随机丢弃 50% 的神经元,强制网络不依赖单一路径,显著抑制过拟合。
- Dense (5) :输出层,使用
softmax激活函数输出 5 个类别的概率分布。
模型代码
python
model = Sequential([
# Block 1
Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)),
MaxPooling2D(2, 2),
# Block 2
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
# Block 3
Conv2D(128, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
# Block 4
Conv2D(128, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Flatten(),
Dense(512, activation='relu'),
Dropout(0.5), # 关键正则化手段
Dense(5, activation='softmax')
])
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])四、 训练结果与可视化评估
模型训练设置为 30 个 Epoch,配合 EarlyStopping 早停机制。训练完成后,我们从三个维度对模型进行评估。
1. 准确率与损失曲线 (Accuracy & Loss)
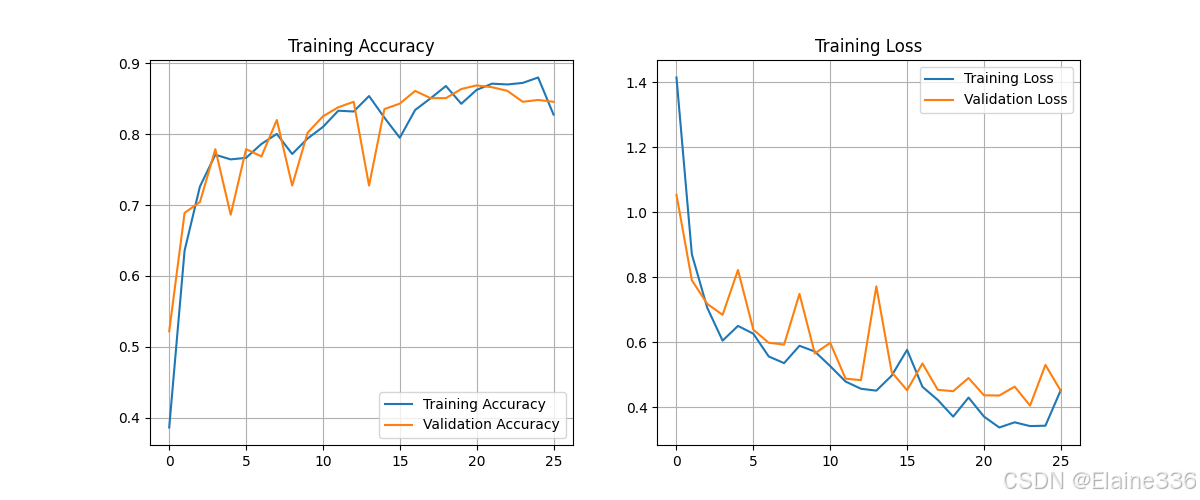
- 分析:若训练集准确率持续上升而验证集准确率下降,则提示过拟合。本模型曲线拟合紧密,说明数据增强和 Dropout 策略生效,模型具有良好的泛化能力。
2. 混淆矩阵 (Confusion Matrix) 分析
为了深入探究模型在特定类别上的表现,我们绘制了混淆矩阵热力图。
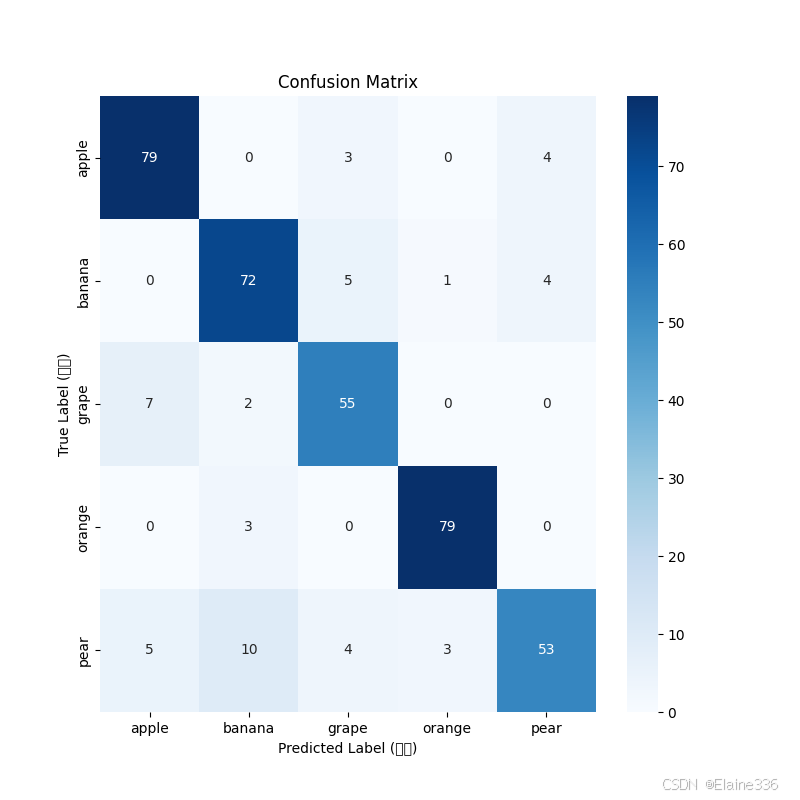
- 总体表现 :
- Apple 和 Orange 的对角线数值均为 79,说明这两类特征显著,模型识别非常精准。
- 误判/难点分析 :
- 主要混淆项(Pear vs Banana) :
- 数据 :矩阵显示,有 10 张 Pear (梨) 的图片被误判为 Banana (香蕉),是所有误判中数量最多的。
- 原因:梨和香蕉在某些角度下(如长条状的香梨)形状相似,且颜色(黄/绿)高度重叠,导致模型在提取纹理特征时出现偏差。
- 次要混淆项(Grape vs Apple) :
- 数据 :有 7 张 Grape (葡萄) 被误判为 Apple。
- 原因:两者轮廓均为圆形,若图片分辨率较低或背景复杂,模型容易混淆两者的轮廓特征。
- 主要混淆项(Pear vs Banana) :
- 优化思路 :
- 针对"梨"这一类召回率较低的问题,建议后续引入 Hard Sample Mining(困难样本挖掘) ,即在训练集中增加更多形态各异的梨的图片,或使用 MobileNetV2 进行迁移学习以提取更细腻的特征。
3. 预测结果抽样
随机抽取验证集中的 9 张图片进行推理并可视化,标题颜色为绿色表示预测正确,红色表示预测错误。

五、 Flask Web 端部署 (工程化落地)
为了将模型能力产品化,我们使用 Flask 构建了后端服务,并设计了专业仪表盘风格的前端界面。
1. 后端实现 (app.py)
采用全局模型预加载策略,避免每次请求重复加载模型导致的延迟,实现毫秒级响应。
python
from flask import Flask, render_template, request
import os
from predict import predict_fruit, load_trained_model
app = Flask(__name__)
# 全局加载模型,常驻内存
MODEL_PATH = './fruit_classifier_model.h5'
global_model = load_trained_model(MODEL_PATH)
@app.route('/', methods=['POST'])
def upload_file():
if request.method == 'POST':
file = request.files['file']
# 保存并推理
file_path = os.path.join('uploads', file.filename)
file.save(file_path)
# 使用预加载的模型进行预测
result = predict_fruit(file_path, model=global_model)
# 将结果渲染到隐藏字段,供前端 AJAX 读取
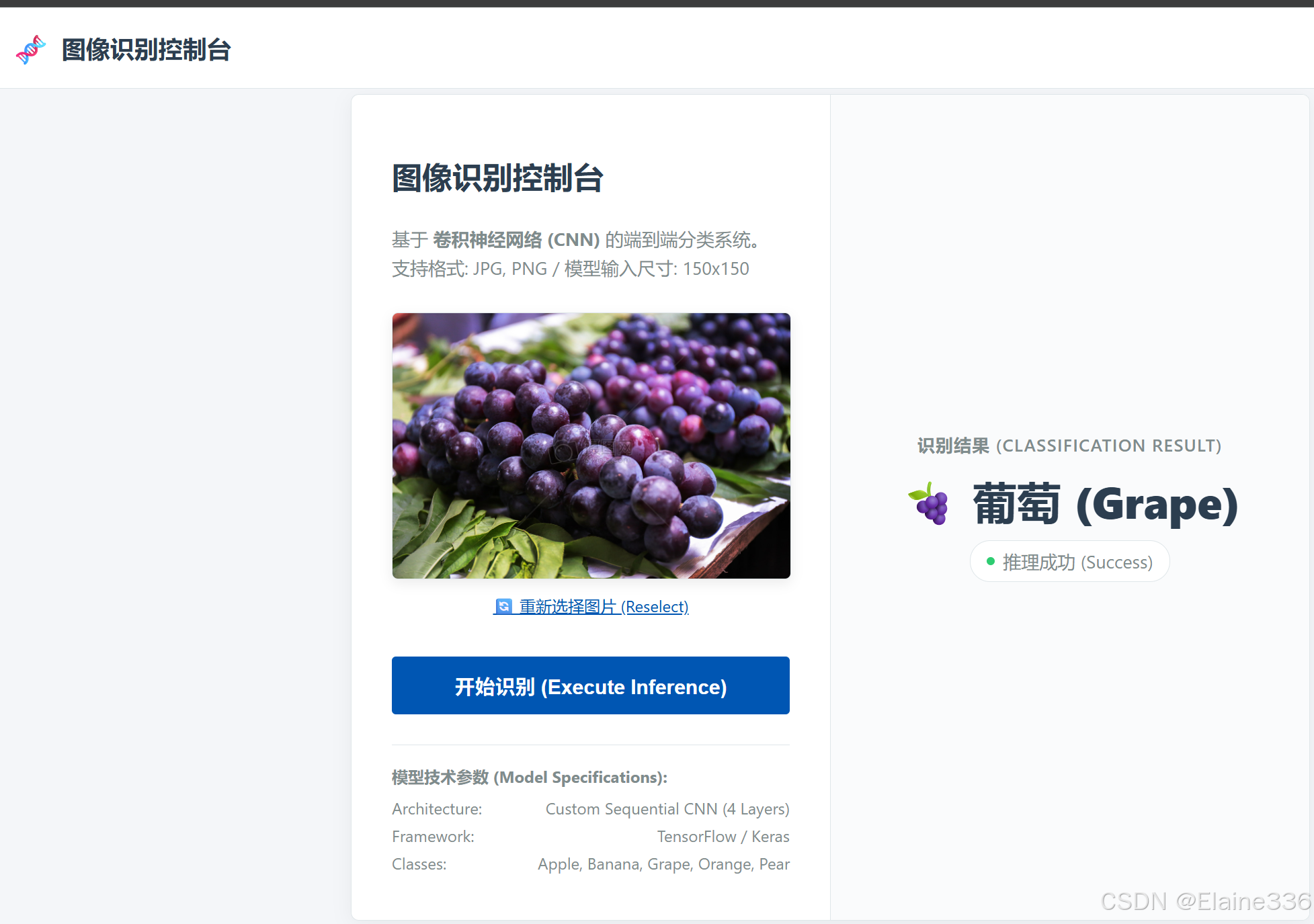
return render_template('index.html', result=result)2. 前端展示 (AJAX 无刷新交互)
前端放弃了传统的表单跳转,采用 Fetch API (AJAX) 接管提交事件。界面采用左右分栏的控制台布局,支持:
- 拖拽上传与即时预览。
- 无刷新识别:点击识别后,页面不刷新,图片不消失,结果动态显示。
- 自动汉化 :将模型返回的英文标签(如
apple)自动映射为中文+Emoji(如🍎 红苹果)。
六、 总结
本文构建了一个端到端的深度学习图像分类项目。通过自定义 CNN 架构、数据增强策略以及可视化的评估手段(特别是混淆矩阵),我们不仅训练了一个高准确率的分类器,更掌握了模型调优的核心方法。
在工程落地方面,通过引入 AJAX 异步交互 和 全局模型加载,显著提升了用户体验,使其不仅是一个算法 Demo,更具备了实际应用产品的雏形。