博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅
2、大数据、计算机专业选题(Python/Java/大数据/深度学习/机器学习)(建议收藏)✅
1、项目介绍
该图书数据分析平台以Python+Django为核心技术架构,整合requests爬虫、MySQL数据库与Echarts可视化工具,聚焦当当图书网数据的采集、清洗、分析与可视化呈现,构建了功能完善的图书数据处理与展示体系。
核心功能模块分工明确、协同联动:数据采集模块通过requests爬虫定向抓取当当网各类图书信息,经清洗去重后存储至MySQL数据库,支持后台配置爬虫参数与任务管理;图书展示模块提供分类图书列表与详情展示,清晰呈现书籍基础信息,方便用户快速浏览查询;数据分析模块围绕图书核心维度展开深度挖掘,涵盖不同类型图书的价格区间数量占比、出版社分布占比等关键指标;可视化呈现模块依托Echarts实现数据可视化大屏展示,以柱状图、饼图等直观形式呈现分析结果,让数据趋势一目了然;后台管理模块支持图书数据、爬虫任务及系统配置的全面管控,保障数据准确性与系统稳定运行。
各模块形成"采集-存储-分析-展示-管理"的完整闭环,既为用户提供了直观的图书数据洞察工具,也为管理者提供了高效的系统运营支持,实现了图书数据价值的最大化挖掘。
技术栈:
Python语言、Django框架、MySQL数据库、requests爬虫、当当图书网、爬虫+清洗+数据分析+Echarts可视化
图书数据分析大屏+爬虫+清洗+可视化 、
python图书数据分析大屏+爬虫+清洗+可视化 当当网 书籍数据分析
2、项目界面
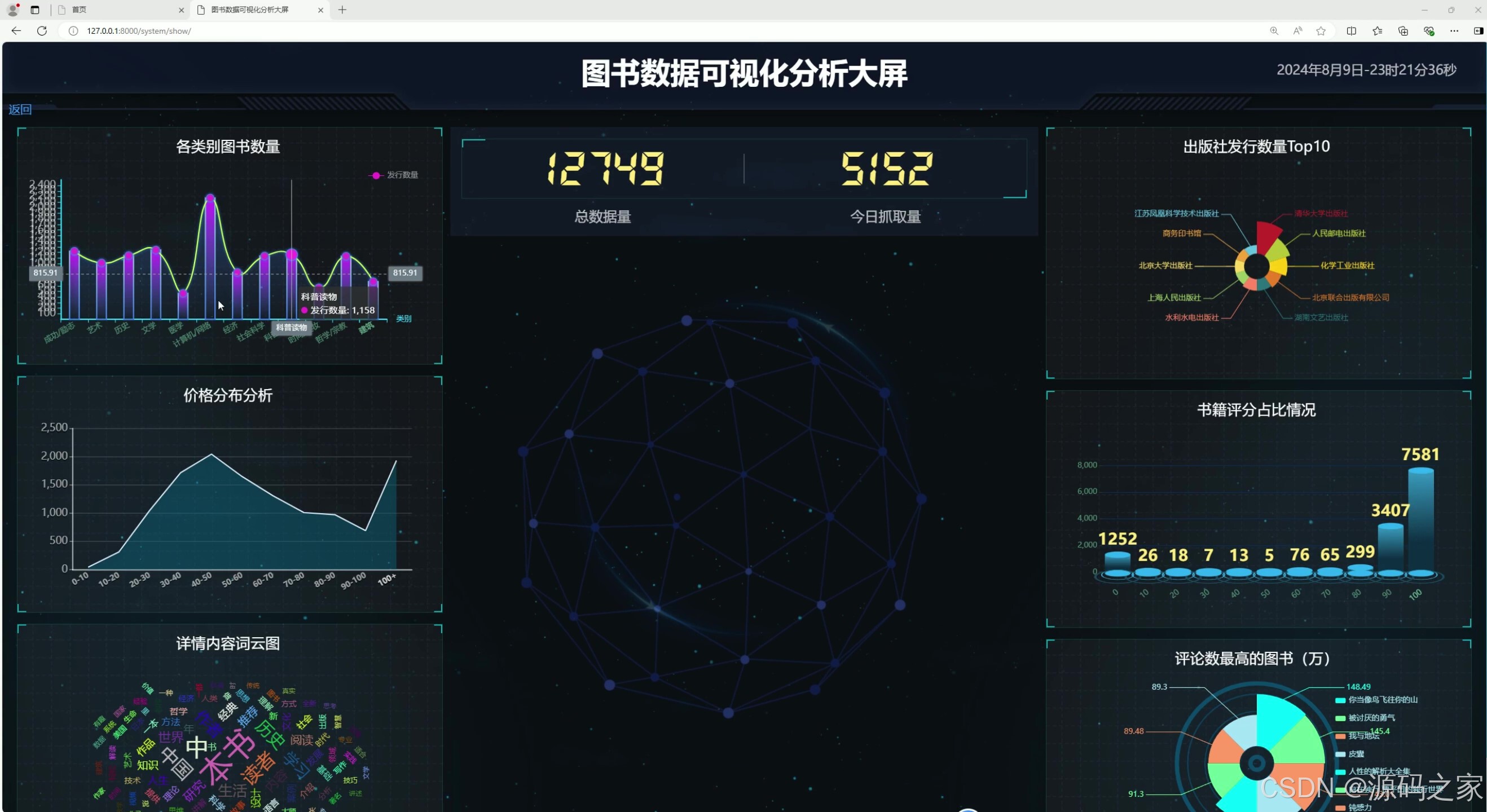
(1)数据可视化分析大屏
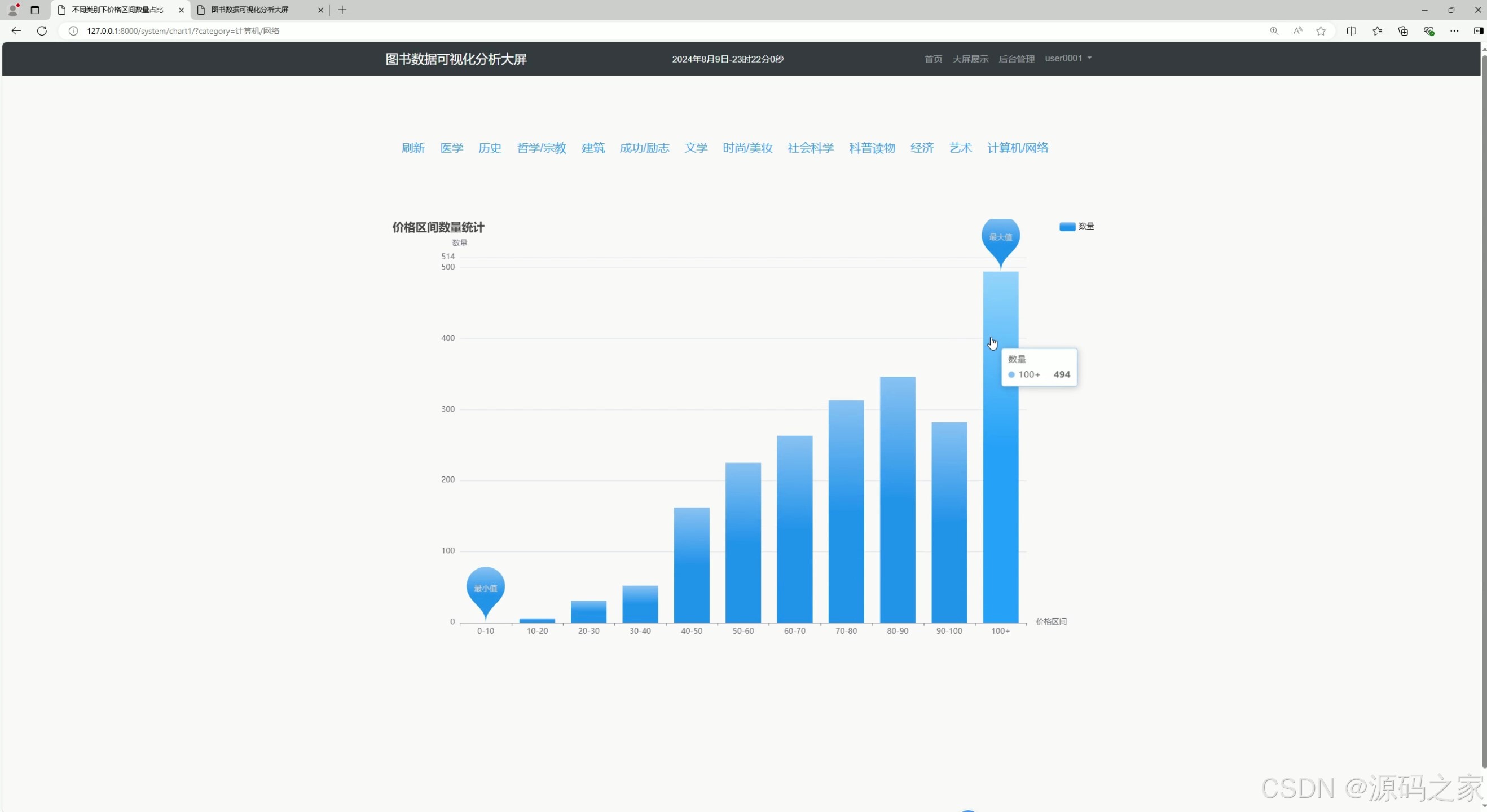
(2)不同类型下价格区间数量占比分析
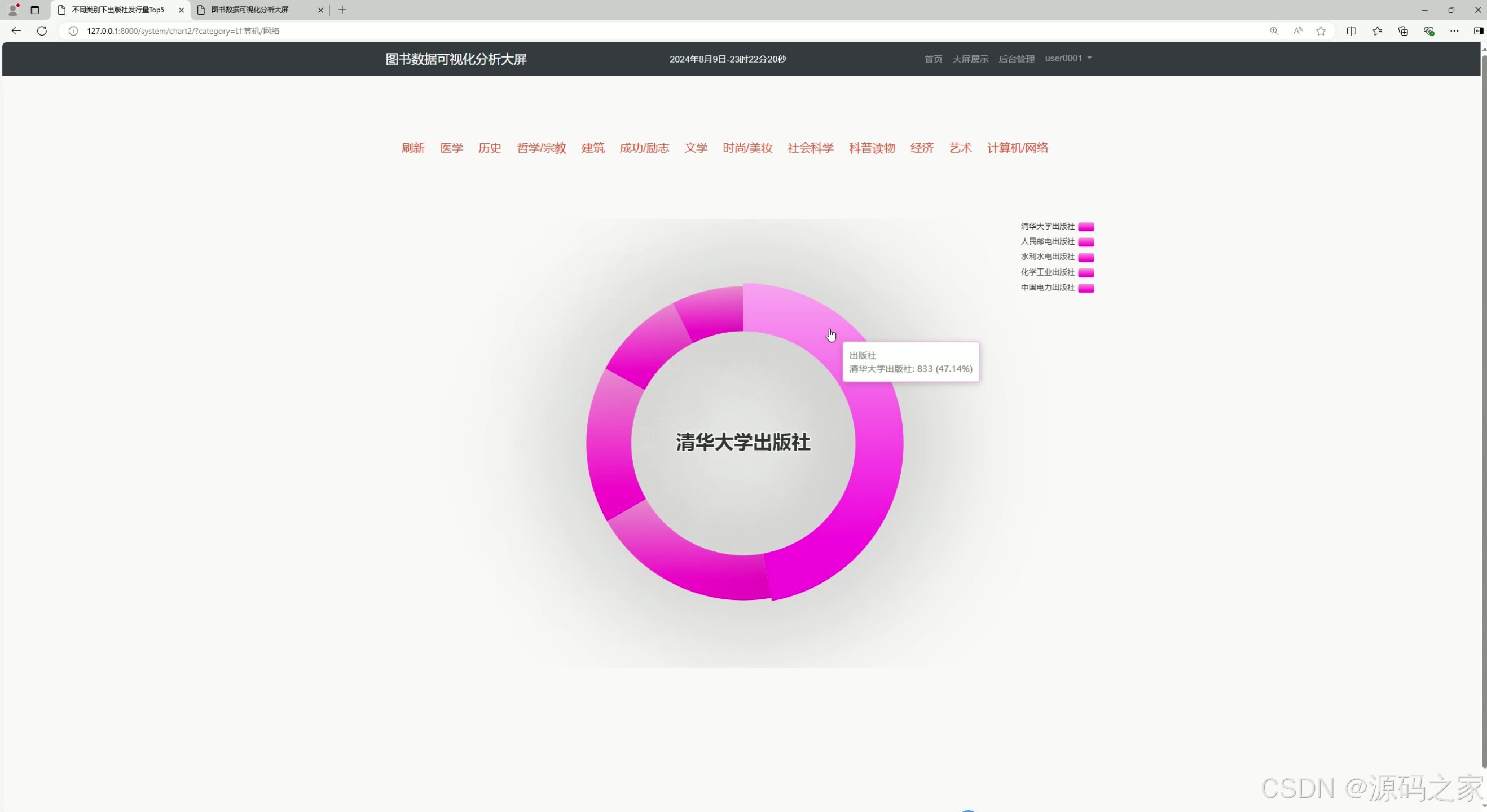
(3)不同类型下出版社数量分析占比
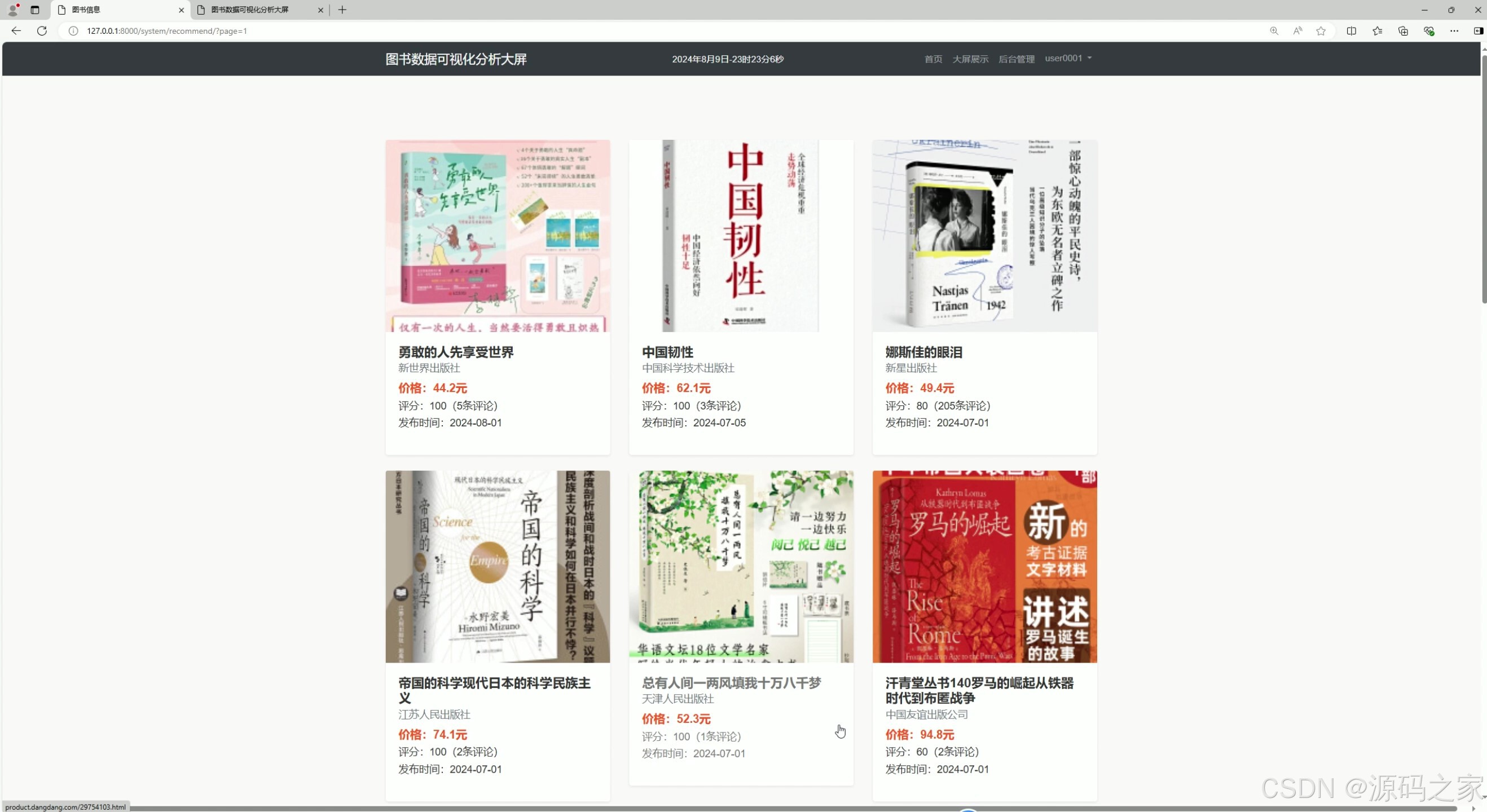
(4)图书信息、图书列表
(5)后台数据管理
(7)功能模块菜单
(8)数据采集爬取
3、项目说明
该图书数据分析平台以Python+Django为核心技术架构,整合requests爬虫、MySQL数据库与Echarts可视化工具,聚焦当当图书网数据的采集、清洗、分析与可视化呈现,构建了功能完善的图书数据处理与展示体系。
核心功能模块分工明确、协同联动:数据采集模块通过requests爬虫定向抓取当当网各类图书信息,经清洗去重后存储至MySQL数据库,支持后台配置爬虫参数与任务管理;图书展示模块提供分类图书列表与详情展示,清晰呈现书籍基础信息,方便用户快速浏览查询;数据分析模块围绕图书核心维度展开深度挖掘,涵盖不同类型图书的价格区间数量占比、出版社分布占比等关键指标;可视化呈现模块依托Echarts实现数据可视化大屏展示,以柱状图、饼图等直观形式呈现分析结果,让数据趋势一目了然;后台管理模块支持图书数据、爬虫任务及系统配置的全面管控,保障数据准确性与系统稳定运行。
各模块形成"采集-存储-分析-展示-管理"的完整闭环,既为用户提供了直观的图书数据洞察工具,也为管理者提供了高效的系统运营支持,实现了图书数据价值的最大化挖掘。
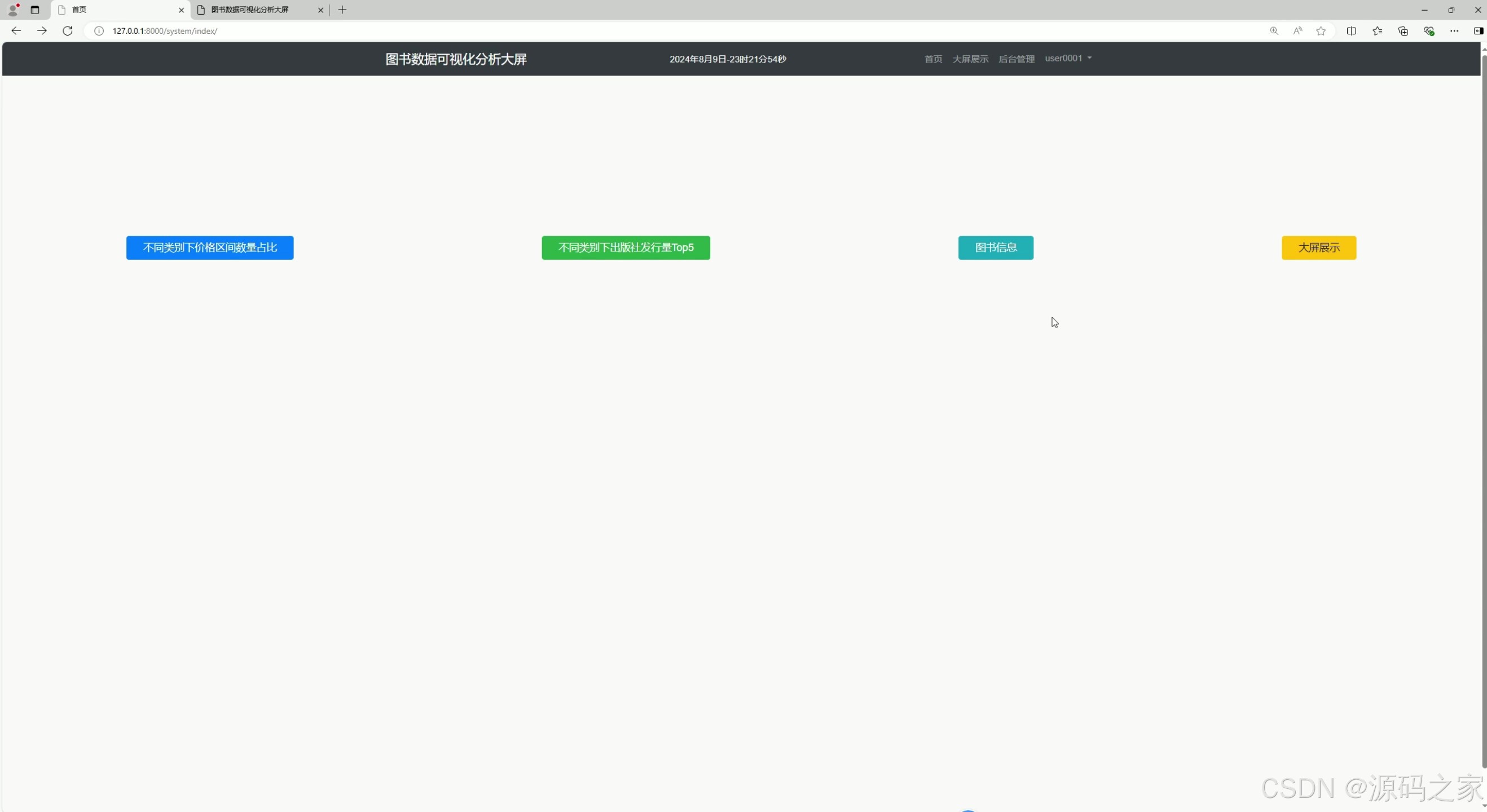
1. 数据可视化分析大屏
功能描述 :
这是项目的主界面,通过 Echarts 可视化工具将图书数据以图表形式展示,包括价格分布、出版社占比、图书类型等关键信息。用户可以直观地了解图书市场的整体情况。
实现方式:
- 使用 Python 的 Django 框架搭建后端服务,从 MySQL 数据库中获取数据。
- 前端通过 Echarts 绘制图表,将数据以直观的可视化形式展示。
- 数据实时更新,用户可以通过筛选条件(如图书类型、价格区间)动态调整图表内容。
2. 不同类型下价格区间数量占比分析
功能描述 :
该模块分析不同图书类型(如小说、科技、教育等)在各个价格区间内的数量占比,帮助用户了解不同类型图书的定价分布。
实现方式:
- 从数据库中提取图书价格和类型数据。
- 使用 Python 的数据分析库(如 Pandas)对数据进行清洗和分类。
- 通过 Echarts 绘制饼图或柱状图,展示不同价格区间内的图书数量占比。
3. 不同类型下出版社数量分析占比
功能描述 :
分析不同图书类型中各出版社的图书数量占比,帮助用户了解哪些出版社在特定领域更具影响力。
实现方式:
- 从数据库中提取图书类型和出版社信息。
- 使用 Pandas 对数据进行分组和统计。
- 使用 Echarts 绘制饼图或柱状图,展示各出版社在不同类型的图书市场中的占比情况。
4. 图书信息、图书列表
功能描述 :
展示图书的详细信息列表,用户可以查看每本书的名称、作者、出版社、价格、评分等信息。
实现方式:
- 从数据库中查询图书信息,并通过 Django 模板渲染到前端页面。
- 提供搜索和筛选功能,用户可以根据书名、作者、类型等条件快速查找图书。
- 使用分页技术优化用户体验,避免单页加载过多数据。
5. 后台数据管理
功能描述 :
管理员可以通过后台管理系统对图书数据进行增删改查操作,确保数据的准确性和完整性。
实现方式:
- 使用 Django 的 Admin 模块搭建后台管理系统。
- 定义图书数据模型(如 Book),并配置相应的管理界面。
- 提供数据导入和导出功能,方便管理员批量处理数据。
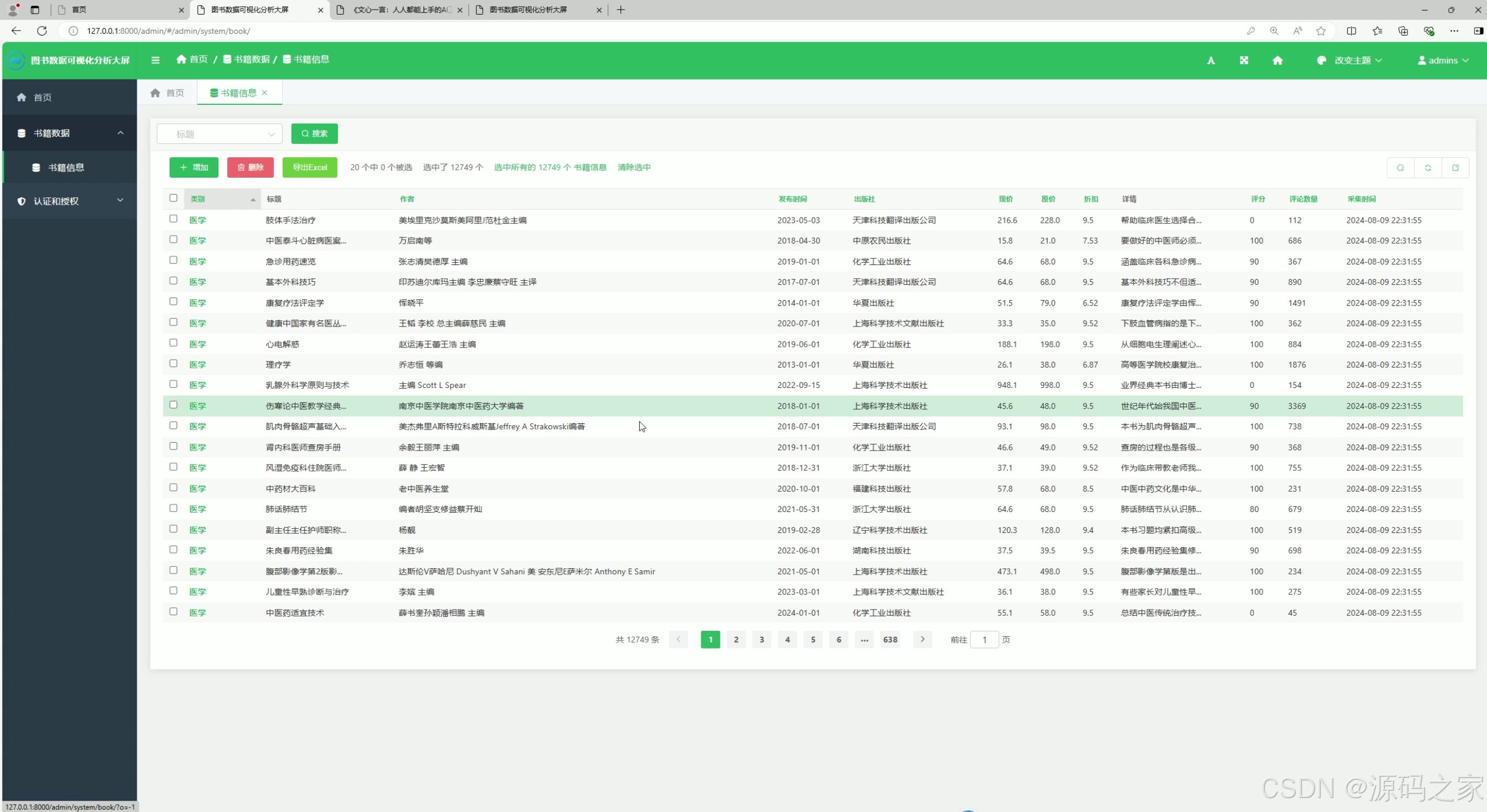
6. 功能模块菜单
功能描述 :
提供项目的导航菜单,方便用户快速切换到不同的功能模块,如数据可视化、图书列表、数据管理等。
实现方式:
- 使用前端框架(如 Bootstrap)设计导航栏。
- 通过路由功能实现模块之间的跳转。
- 根据用户权限动态显示菜单项,确保用户只能访问其有权限的功能模块。
7. 数据采集爬取
功能描述 :
通过爬虫技术从当当网等图书网站采集图书数据,并清洗后存储到 MySQL 数据库中,为后续的分析和可视化提供数据支持。
实现方式:
- 使用 Python 的
requests库和BeautifulSoup库编写爬虫脚本。 - 定期运行爬虫任务,获取最新的图书数据。
- 使用 Pandas 对采集的数据进行清洗和预处理,去除无效数据或重复记录。
- 将清洗后的数据存储到 MySQL 数据库中,供前端调用。
4、核心代码
python
import requests
from bs4 import BeautifulSoup
import time
def fun(find,type=None):
if find:
if type:
try:
return find[0].get(type).strip().replace('\t','').replace('\n','')
except:
return ""
return find[0].text.strip().replace('\t','').replace('\n','')
def getData(url,data,category):
response = requests.get(url=url,headers=headers)
soup = BeautifulSoup(response.text,'lxml')
li_list = soup.select('#search_nature_rg ul.bigimg li')
for li in li_list:
title = fun(li.select('a.pic'),'title').split('(')[0]
author = li.select('p.search_book_author span')[0].text.strip().replace('\t','').replace('\n','')
createTime = li.select('p.search_book_author span')[1].text.strip().replace('\t','').replace('\n','')
press = li.select('p.search_book_author span')[2].text.strip().replace('\t','').replace('\n','')
now_price = fun(li.select('p.price span.search_now_price'))
pre_price = fun(li.select('p.price span.search_pre_price'))
discount = fun(li.select('p.price span.search_discount'))
detail = fun(li.select('p.detail'))
star = fun(li.select('p.search_star_line span.search_star_black span'),'style')
comment_num = fun(li.select('p.search_star_line a.search_comment_num'))
img_url = fun(li.select('.pic img'),'data-original')
if img_url:
img_url = "http:" + img_url
book_url = fun(li.select('p.name a'),'href')
if book_url:
book_url = "http:" + book_url
addTime = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
data.append([category,title,author,createTime,press,now_price,pre_price,discount,detail,star,comment_num,img_url,book_url,addTime])
def writeData(data):
with open('./data.csv','w+',encoding='utf-8') as fp:
fp.write("\t".join(['category','title','author','createTime','press','now_price','pre_price','discount','detail','star','comment_num','img_url','book_url','addTime'])+'\n')
for item in data:
fp.write("\t".join([str(i) for i in item])+'\n')
if __name__ == '__main__':
base = 'http://category.dangdang.com/pg{}-cp01.{}.00.00.00.00.html'
data = []
# 这个设置爬取多少页
max_page = 2
category_code = {'成功/励志':'21','艺术':'07','历史':'36','文学':'05','医学':'56','计算机/网络':'54','经济':'25','社会科学':'30','科普读物':'52','时尚/美妆':'11','哲学/宗教':'28','建筑':'55'}
for category in category_code:
for page in range(max_page):
url = base.format(page+1,category_code[category])
try:
getData(url,data,category)
print('类别{}第{}页爬取成功!'.format(category,page+1))
time.sleep(1)
except:
print('类别{}第{}页爬取失败!'.format(category,page+1))
time.sleep(15)
writeData(data)🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式

🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看 👇🏻获取联系方式👇🏻