文章目录
- Elasticsearch(ES)详细介绍
-
- 一、核心特性
-
- [1. 分布式架构(高可用+可扩展)](#1. 分布式架构(高可用+可扩展))
- [2. 全文检索能力(Lucene内核)](#2. 全文检索能力(Lucene内核))
- [3. 实时性](#3. 实时性)
- [4. 多数据类型支持](#4. 多数据类型支持)
- [5. RESTful API & 多语言客户端](#5. RESTful API & 多语言客户端)
- [6. 弹性扩展与容错](#6. 弹性扩展与容错)
- 二、核心概念
-
- [1. 集群(Cluster)](#1. 集群(Cluster))
- [2. 节点(Node)](#2. 节点(Node))
- [3. 索引(Index)](#3. 索引(Index))
- [4. 文档(Document)](#4. 文档(Document))
- [5. 映射(Mapping)](#5. 映射(Mapping))
- [6. 分片(Shard)& 副本(Replica)](#6. 分片(Shard)& 副本(Replica))
- [7. 倒排索引(Inverted Index)](#7. 倒排索引(Inverted Index))
- 三、核心工作流程
-
- [1. 数据写入流程](#1. 数据写入流程)
- [2. 数据检索流程](#2. 数据检索流程)
- 四、典型应用场景
-
- [1. 全文检索](#1. 全文检索)
- [2. 日志/监控分析](#2. 日志/监控分析)
- [3. 数据分析与可视化](#3. 数据分析与可视化)
- [4. 安全与风控](#4. 安全与风控)
- [五、ELK/Elastic Stack 生态](#五、ELK/Elastic Stack 生态)
- 六、版本与选型
- 七、优缺点
- 总结
- 架构
Elasticsearch(ES)详细介绍
Elasticsearch(简称ES)是一款基于Lucene 构建的分布式、RESTful风格的开源搜索与数据分析引擎,由Elastic(原Elasticsearch BV)公司开发维护,核心定位是实时、高可用、可扩展地处理海量结构化/非结构化数据的搜索、分析与存储需求。
它广泛应用于日志分析、全文检索、监控告警、业务数据分析、搜索引擎搭建等场景(如维基百科、Netflix、阿里云日志服务均基于ES构建核心能力)。
一、核心特性
1. 分布式架构(高可用+可扩展)
ES的核心设计是分布式,无需额外配置即可实现节点集群化,核心优势:
- 水平扩展:通过增加节点(Node)线性提升存储、搜索、分析能力,支持PB级数据;
- 分片(Shard)机制:索引数据被拆分为多个分片(Primary Shard),分片可分布在不同节点,每个分片是独立的Lucene索引;
- 副本(Replica)机制:主分片的冗余副本,既提升读取性能(负载均衡),又实现故障自动恢复(主分片故障时副本升级为主分片);
- 集群自动发现:节点自动感知集群拓扑变化,支持跨机房部署,保障高可用。
2. 全文检索能力(Lucene内核)
基于Lucene的倒排索引(Inverted Index),提供强大的全文检索能力:
- 分词支持:内置多语言分词器(中文支持IK、jieba等扩展分词器),支持自定义分词规则;
- 模糊搜索:支持前缀匹配、通配符、正则、拼写纠错(Fuzzy Query);
- 相关性排序:基于TF-IDF、BM25(ES7+默认)算法计算文档与查询的相关性,支持自定义排序规则;
- 高亮显示:检索结果可高亮匹配的关键词,提升用户体验。
3. 实时性
- 近实时(NRT):数据写入后秒级可被检索(默认1秒刷新间隔),兼顾写入性能与检索实时性;
- 实时分析:支持聚合(Aggregation)操作,实时对海量数据做统计、分组、计算(如统计某时段日志的错误数、按地区分组统计订单量)。
4. 多数据类型支持
ES不仅支持文本,还兼容多种结构化/非结构化数据:
- 结构化:数字、日期、布尔、地理坐标(Geo-point)、IP地址;
- 半结构化:JSON、XML、CSV;
- 非结构化:文本、二进制(需结合插件)。
5. RESTful API & 多语言客户端
- 原生提供HTTP RESTful API,支持CRUD、检索、集群管理等所有操作;
- 官方提供Java、Python、Go、JavaScript、PHP等多语言客户端,降低开发成本;
- 支持SQL查询(ES SQL),可通过SQL语法操作ES数据,降低学习成本。
6. 弹性扩展与容错
- 自动负载均衡:检索请求自动分发到可用分片,避免单点压力;
- 故障自愈:节点宕机后,集群自动重新分配分片,无需人工干预;
- 冷热数据分离:支持将不常用的"冷数据"迁移到低成本存储节点,优化资源利用率。
二、核心概念
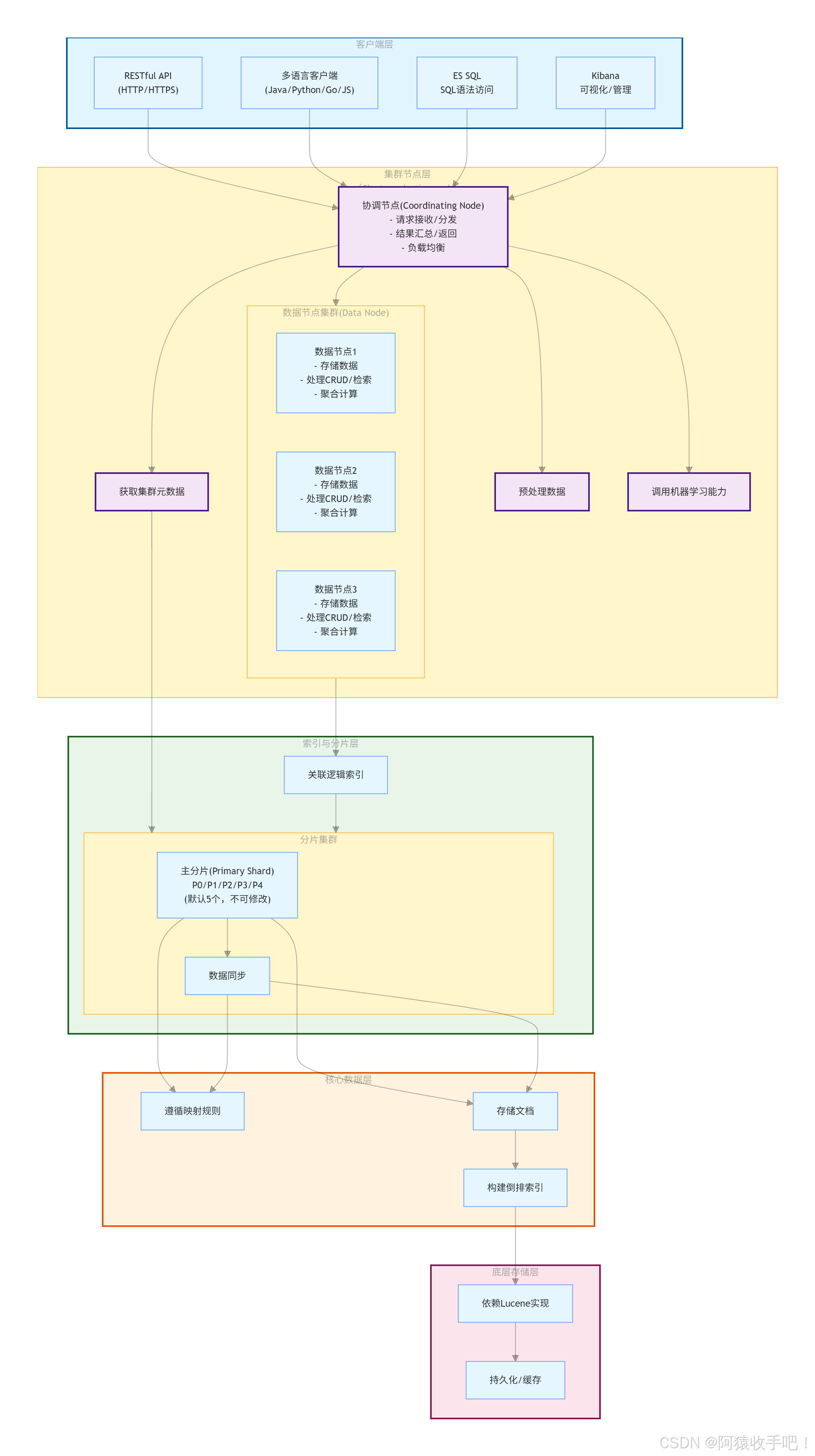
1. 集群(Cluster)
由一个或多个节点组成的集合,共享同一集群名称(默认elasticsearch),协同处理数据和请求。集群中有一个主节点(Master Node),负责管理集群元数据(如索引、分片配置),主节点故障时自动选举新主节点。
2. 节点(Node)
运行ES进程的单个服务器,按角色可分为:
- 主节点(Master):管理集群状态,不处理数据请求(建议专用);
- 数据节点(Data):存储数据、处理CRUD和检索请求;
- 协调节点(Coordinating):接收客户端请求,分发到数据节点,汇总结果返回(默认所有节点都是协调节点);
- ** ingest 节点**:数据写入前的预处理(如过滤、转换、富化);
- 机器学习节点:运行ES的机器学习功能(如异常检测)。
3. 索引(Index)
- 逻辑概念:类似关系型数据库的"数据库",是一组具有相似结构的文档的集合(如"用户日志索引""商品索引");
- 物理概念:索引由多个分片(Shard)组成,分片是ES的最小存储/检索单元。
- 命名规则:小写、无特殊字符,建议语义化(如
user_logs_2026)。
4. 文档(Document)
ES中最小的数据单元,类似关系型数据库的"行",以JSON格式存储。每个文档有唯一ID(手动指定或自动生成),属于某个索引。
示例文档:
json
{
"id": 1001,
"title": "Elasticsearch入门教程",
"content": "ES是分布式搜索引擎,基于Lucene构建",
"create_time": "2026-01-04",
"tags": ["搜索", "分布式", "Elasticsearch"]
}5. 映射(Mapping)
类似关系型数据库的"表结构",定义文档的字段名、字段类型(如text、keyword、integer、date)、分词器、是否索引等属性。
- 动态映射:ES默认自动识别字段类型(如数字→integer,文本→text),适合快速上手;
- 显式映射:手动定义Mapping,精准控制字段行为(如text字段用于全文检索,keyword字段用于精确匹配/聚合)。
示例Mapping:
json
{
"mappings": {
"properties": {
"title": { "type": "text", "analyzer": "ik_max_word" }, // 中文分词
"content": { "type": "text", "analyzer": "ik_smart" },
"create_time": { "type": "date", "format": "yyyy-MM-dd" },
"tags": { "type": "keyword" } // 精确匹配,支持聚合
}
}
}6. 分片(Shard)& 副本(Replica)
- 主分片(Primary Shard):数据的原始分片,索引创建时指定数量(默认5),一旦创建不可修改;
- 副本分片(Replica Shard):主分片的冗余副本,可动态调整数量(默认1),提升读取性能和容错性。
示例:索引goods配置5个主分片、1个副本,则集群中该索引共10个分片(5主+5副)。
7. 倒排索引(Inverted Index)
ES实现快速全文检索的核心机制:
- 正排索引:文档ID → 文档内容(如ID1 → "ES是分布式搜索引擎");
- 倒排索引:关键词 → 包含该关键词的文档ID列表(如"分布式" → ID1, ID3, ID5)。
倒排索引在数据写入时构建,检索时直接匹配关键词,无需遍历所有文档。
三、核心工作流程
1. 数据写入流程
- 客户端向协调节点发送写入请求;
- 协调节点根据文档ID/路由规则(默认
_routing字段,无则用文档ID哈希)计算目标主分片; - 协调节点将请求转发到主分片所在节点;
- 主分片写入数据,同步到所有副本分片;
- 所有副本确认写入完成后,主分片返回成功给协调节点,再由协调节点返回给客户端;
- ES默认每隔1秒将内存中的数据刷新(Refresh)到文件系统缓存,使其可被检索;每隔30分钟(或达到阈值)执行刷盘(Flush),将数据持久化到磁盘。
2. 数据检索流程
- 客户端向协调节点发送检索请求;
- 协调节点将请求广播到所有相关分片(主分片/副本分片均可);
- 各分片执行检索,返回Top N结果给协调节点;
- 协调节点汇总所有分片结果,重新排序后返回最终结果给客户端。
四、典型应用场景
1. 全文检索
- 电商商品搜索(如按名称、描述检索商品,支持模糊匹配、相关性排序);
- 文档/知识库检索(如企业内部文档、在线文档平台的全文搜索);
- 网站站内搜索(如博客、论坛的内容检索)。
2. 日志/监控分析
- 日志集中收集与分析(ELK/EFK栈:Elasticsearch + Logstash/Fluentd + Kibana);
- 系统监控告警(如服务器CPU/内存、接口响应时间的实时监控,异常触发告警);
- 应用性能监控(APM):追踪应用调用链路、分析性能瓶颈。
3. 数据分析与可视化
- 业务数据聚合分析(如按地区/时间统计订单量、用户活跃度);
- 实时报表生成(结合Kibana制作可视化仪表盘);
- 地理空间分析(如基于Geo-point的外卖配送范围、物流轨迹分析)。
4. 安全与风控
- 日志审计(如用户操作日志、系统访问日志的检索与分析);
- 异常检测(如基于机器学习的登录异常、交易异常识别);
- 舆情分析(抓取互联网文本,分析关键词、情感倾向)。
五、ELK/Elastic Stack 生态
ES通常与Elastic生态的其他组件配合使用,形成完整的解决方案:
- Kibana:ES的可视化与管理工具,支持检索、仪表盘、报表、集群监控;
- Logstash:数据采集与预处理工具,支持从多源采集数据(文件、数据库、消息队列),清洗/转换后写入ES;
- Beats:轻量级数据采集器(如Filebeat采集日志、Metricbeat采集监控指标、Packetbeat采集网络数据),替代Logstash的轻量场景;
- Elastic Agent:统一的采集代理,整合Beats和Logstash的能力,简化部署。
六、版本与选型
- 主流版本 :
- ES 7.x:稳定版,无官方维护但企业广泛使用(移除Type概念,默认单索引单Type);
- ES 8.x:最新稳定版,新增安全特性(默认开启HTTPS/身份验证)、向量搜索、性能优化,推荐新项目使用;
- 注意事项 :
- 避免跨大版本升级(如6.x→8.x),建议分步升级;
- 生产环境建议使用官方推荐的JDK版本(ES 8.x推荐JDK 17);
- 云服务商(阿里云、AWS)提供托管ES服务(如阿里云Elasticsearch),降低运维成本。
七、优缺点
优点
- 分布式架构天然支持高可用、高扩展,适配海量数据;
- 全文检索性能优异,实时性强(秒级);
- 生态完善,配套工具(Kibana/Logstash)降低使用成本;
- 灵活性高,支持动态映射、自定义分词、聚合分析;
- 多语言支持,RESTful API易于集成。
缺点
- 学习成本较高(需理解分片、映射、分词、聚合等核心概念);
- 资源消耗较大(内存、CPU、磁盘),生产环境需合理规划节点配置;
- 深度定制化(如自定义评分、复杂聚合)需掌握Lucene底层原理;
- 数据一致性为最终一致性,不适合强事务场景(如金融核心交易)。
总结
Elasticsearch是目前最主流的分布式搜索与分析引擎,核心优势是分布式、实时、高性能,覆盖检索、存储、分析全场景。它不仅是"搜索引擎",更是一站式的大数据处理平台,适合从中小企业到大型企业的各类数据检索与分析需求。使用时需结合业务场景合理设计索引、分片、映射,配合Elastic Stack生态可快速落地解决方案。
架构