1 单选题(每题 2 分,共 30 分)
第1题 对如下定义的循环单链表,横线处填写( )。
cpp
// 循环单链表的结点
struct Node {
int data; // 数据域
Node* next; // 指针域
Node(int d) : data(d), next(nullptr) {}
};
// 创建一个只有一个结点的循环单链表
Node* createList(int value) {
Node* head = new Node(value);
head->next = head;
return head;
}
// 在循环单链表尾部插入新结点
void insertTail(Node* head, int value) {
Node* p = head;
while (p->next != head) {
p = p->next;
}
Node* node = new Node(value);
node->next = head;
p->next = node;
}
// 遍历并输出循环单链表
void printList(Node* head) {
if (head == nullptr) return;
Node* p = head;
_______________________ //在此处填入代码
cout << endl;
}A.
cpp
while (p != nullptr){
cout << p->data << " ";
p = p->next;
}B.
cpp
while (p->next != nullptr){
cout << p->data << " ";
p = p->next;
}C.
cpp
do {
cout << p->data << " ";
p = p->next;
} while (p != head);D.
cpp
for(; p; p=p->next){
cout << p->data << " ";
}解析:答案C。遍历并输出循环单链表,应该使用循环,故排除A、B,由于是循环链表,总存在p->next,需要用条件判断并终止。因为从head开始,如p->next==head表示已循环一周并可以终止。故选C。
第2题 区块链技术是比特币的基础。在区块链中,每个区块指向前一个区块,构成链式列表,新区块只能接在链尾,不允许在中间插入或删除。下面代码实现插入区块添加函数,则横线处填写( )。
cpp
//区块(节点)
struct Block {
int index; // 区块编号(高度)
string data; // 区块里保存的数据
Block* prev; // 指向前一个区块
Block(int idx, const string& d, Block* p) : index(idx), data(d), prev(p) {}
};
// 区块链
struct Blockchain {
Block* tail;
// 初始化
void init() {
tail = new Block(0, "Genesis Block", nullptr);
}
// 插入新区块
void addBlock(const string& data) {
_______________________ //在此处填入代码
}
// 释放内存
void clear() {
Block* cur = tail;
while (cur != nullptr) {
Block* p = cur->prev;
delete cur;
cur = p;
}
tail = nullptr;
}
};A.
cpp
Block* newBlock = new Block(tail->index + 1, data, tail);
tail = newBlock->prev;B.
cpp
Block* newBlock = new Block(tail->index + 1, data, tail);
tail = newBlock;C.
cpp
Block* newBlock = new Block(tail->index + 1, data, tail->prev);
tail = newBlock;D.
cpp
Block* newBlock = new Block(tail->index + 1, data, tail->prev);
tail = newBlock->prev;解析:答案B。定义一个新块,块号是原尾部块号+1,tail是原尾部,tail->prev是原尾部的前驱。新定义块的前驱是原尾部,tail应更新为当前节点,成为新的尾部。故选B。
第3题 下面关于单链表和双链表的描述中,正确的是( )。
cpp
struct DNode {
int data;
DNode* prev;
DNode* next;
};
// 在双链表中删除指定节点
void deleteNode(DNode* node) {
if (node->prev) {
node->prev->next = node->next;
}
if (node->next) {
node->next->prev = node->prev;
}
delete node;
}
struct SNode {
int data;
SNode* next;
};
// 在单链表中删除指定节点
void deleteSNode(SNode* head, SNode* node) {
SNode* prev = head;
while (prev->next != node) {
prev = prev->next;
}
prev->next = node->next;
delete node;
}A. 双链表删除指定节点是𝑂(1),单链表是𝑂(1)
B. 双链表删除指定节点是𝑂(𝑛),单链表是𝑂(1)
C. 双链表删除指定节点是𝑂(1),单链表是𝑂(𝑛)
D. 双链表删除指定节点是𝑂(𝑛),单链表是𝑂(𝑛)
解析:答案C。题目所给程序中,在双链表中删除指定节点函数中无循环,所以𝑂(1);在单链表中删除指定节点函数中有一个循环,所以𝑂(𝑛),所以C正确。故选C。
第4题 假设我们有两个数𝑎=38和𝑏=14,它们对模𝑚同余,即𝑎≡𝑏(mod 𝑚)。以下哪个值不可能是𝑚?
A. 3 B. 4 C. 6 D. 9
解析:答案D。当𝑚=3,𝑎 % 𝑚 =2, 𝑏 % 𝑚 = 2,A正确;当𝑚=4,𝑎 % 𝑚 =2, 𝑏 % 𝑚 = 2,B正确;当𝑚=6,𝑎 % 𝑚 =2, 𝑏 % 𝑚 = 2,C正确;当𝑚=9,𝑎 % 𝑚 =2, 𝑏 % 𝑚 = 5,D错误。故选D。
第5题 下面代码实现了欧几里得算法。下面有关说法,错误的是( )。
cpp
int gcd1(int a, int b) {
return b == 0 ? a : gcd1(b, a % b);
}
int gcd2(int a, int b) {
while (b != 0) {
int temp = b;
b = a % b;
a = temp;
}
return a;
}A. gcd1() 实现为递归方式。
B. gcd2() 实现为迭代方式。
C. 当 𝑎 较大时, gcd1() 实现会多次调用自身,需要较多额外的辅助空间。
D. 当 𝑎 较大时, gcd1() 的实现比 gcd2() 执行效率更高。
解析:答案D。gcd1()为递归函数,算法用递归方式实现,A正确;gcd2()为普通函数,算法用循环(迭代)实现,B正确;递归要使用递归栈,需要较多额外的辅助空间(栈空间),C正确;循环(迭代)的效率要高于递归(至少省了入栈、出栈所消耗的时间),D错误。故选D。
第6题 唯一分解定理描述的内容是( )。
A. 任何正整数都可以表示为两个素数的和。
B. 任何大于1的合数都可以唯一分解为有限个质数的乘积。
C. 两个正整数的最大公约数总是等于它们的最小公倍数除以它们的乘积。
D. 所有素数都是奇数。
解析:答案B。唯一分解定理(也称为算术基本定理)指出,任何一个大于1的正整数都可以唯一地表示为有限个素数的乘积(不计素因数的排列顺序)。例如,12可以分解为2²×3¹,且这种分解是唯一的。任何正整数都可以表示为两个素数的和:这是哥德巴赫猜想的内容,A错误。任何大于1的合数都可以唯一分解为有限个质数的乘积:这是唯一分解定理的准确描述,B正确。两个正整数的最大公约数总是等于它们的最小公倍数除以它们的乘积:这是错误的,最大公约数和最小公倍数的关系是gcd(a,b)×lcm(a,b)=a×b,C错误。所有素数都是奇数:这是错误的,2是唯一的偶数素数,D错误。故选B。
第7题 下述代码实现素数表的线性筛法,筛选出所有小于等于𝑛的素数,则横线上应填的代码是( )。
cpp
vector<int> linear_sieve(int n) {
vector<bool> is_prime(n +1, true);
vector<int> primes;
is_prime[0] = is_prime[1] = 0; //0和1两个数特殊处理
for (int i = 2; i <= n; ++i) {
if (is_prime[i]) {
primes.push_back(i);
}
________________________________ { // 在此处填入代码
is_prime[ i * primes[j] ] = 0;
if (i % primes[j] == 0)
break;
}
}
return primes;
}A. for (int j = 0; j < primes.size() && i * primesj <= n; j++)
B. for(int j = sqrt(n); j <= n && i * primesj <= n; j++)
C. for (int j = 1; j <= sqrt(n); j++)
D. for(int j = 1; j < n && i * primesj <= n; j++)
解析:答案A。A. 外层循环遍历 i(2 到 n),内层循环遍历已知素数 primesj。i * primesj 计算合数位置,标记 is_primei \* primes\[j] = 0。if (i % primesj == 0) 优化:若 i 能被 primesj 整除,后续合数重复标记(跳出内层循环),所以是线性时间复杂度𝑂(𝑛),每个合数仅被最小质因数标记一次。内层循环条件 i * primesj <= n 确保索引有效。j < primes.size() 避免越界(primes 仅存储素数),所以A正确。B. j = sqrt(n) 起始值错误,j <= n会越界(primes 仅当前存储的素数≤n)。C. j = 1 起始值错误:primes0 为 2,i * primes0 会重复标记(如 4 = 2 * 2)。D. j < n 终止值错误:primes中的素数是逐步增加的,素数数远小于n。故选A。
第8题 下列关于排序的说法,正确的是( )。
A. 快速排序是稳定排序 B. 归并排序通常是稳定的
C. 插入排序是不稳定排序 D. 冒泡排序不是原地排序
解析:答案B。快速排序是不稳定排序,A错误。归并排序通常是稳定的,B正确。插入排序是稳定排序,C错误。冒泡排序是原地排序,D错误。故选B。
第9题 下面代码实现了归并排序。下述关于归并排序的说法中,不正确的是( )。
cpp
void merge(vector<int>& arr, vector<int>& temp, int l, int mid, int r) {
int i = l, j = mid + 1, k = l;
while (i <= mid && j <= r) {
if (arr[i] <= arr[j]) temp[k++] = arr[i++];
else temp[k++] = arr[j++];
}
while (i <= mid) temp[k++] = arr[i++];
while (j <= r) temp[k++] = arr[j++];
for (int p = l; p <= r; p++) arr[p] = temp[p];
}
void mergeSort(vector<int>& arr, vector<int>& temp, int l, int r) {
if (l >= r) return;
int mid = l + (r - l) / 2;
mergeSort(arr, temp, l, mid);
mergeSort(arr, temp, mid + 1, r);
merge(arr, temp, l, mid, r);
}A. 归并排序的平均复杂度是𝑂(𝑛 log 𝑛)。
B. 归并排序需要𝑂(𝑛)的额外空间。
C. 归并排序在最坏情况的时间复杂度是𝑂(𝑛²)。
D. 归并排序适合大规模数据。
解析:答案C。归并排序的时间复杂度在所有情况下(最坏、最好、平均)均为𝑂(𝑛 log 𝑛)。其分治策略确保了每次递归将问题规模减半,合并操作的时间复杂度为𝑂(𝑛),因此整体复杂度为𝑂(𝑛 log 𝑛)。代码实现中的 mergeSort 函数通过递归将数组分成两半,merge 函数负责合并有序子数组,符合归并排序的核心逻辑。所以C错误。故选C。
第10题 下述C++代码实现了快速排序算法,最坏情况的时间复杂度是( )。
cpp
int partition(vector<int>& arr, int low, int high) {
int i = low, j = high;
int pivot = arr[low]; // 以首元素为基准
while (i < j) {
while (i < j && arr[j] >= pivot) j--;
while (i < j && arr[i] <= pivot) i++;
if (i < j) swap(arr[i], arr[j]);
}
swap(arr[i], arr[low]);
return i;
}
void quickSort(vector<int>& arr, int low, int high) {
if (low >= high) return;
int p = partition(arr, low, high);
quickSort(arr, low, p - 1);
quickSort(arr, p + 1, high);
}A. 𝑂(𝑛) B. 𝑂(log 𝑛) C. 𝑂(𝑛²) D. 𝑂(𝑛 log 𝑛)
解析:答案C。快速排序最坏情况时间复杂度分析:基准选择 :代码中以数组首元素为基准(pivot = arrlow),在最坏情况下(如数组已有序),每次分区只能将问题规模缩小1(如1,2,3,4分区后变成1和2,3,4)。分区效率 :最坏分区导致递归树高度为n-1,即𝑇(𝑛) = 𝑇(𝑛-1) + 𝑇(0) + 𝑂(𝑛),简化为𝑇(𝑛-1) + 𝑂(𝑛)。时间复杂度推导 :递归树的总工作量为𝑂(𝑛)+ 𝑂(𝑛-1)+ ... + 𝑂(1) = 𝑂(𝑛²)。所以快速排序最坏情况时间复杂度为𝑂(𝑛²)。故选C。
第11题 下面代码尝试在有序数组中查找第一个大于等于 x 的元素位置。如果没有大于等于 x 的元素,返回 arr.size() 。以下说法正确的是( )。
cpp
int lower_bound(vector<int>& arr, int x) {
int l = 0, r = arr.size();
while(l < r) {
int mid = l + (r - l) / 2;
if(arr[mid] >= x) r = mid;
else l = mid + 1;
}
return l;
}A. 上述代码逻辑正确
B. 上述代码逻辑错误,while 循环条件应该用 l <= r
C. 上述代码逻辑错误,mid 计算错误
D. 上述代码逻辑错误,边界条件不对
解析:答案A。代码逻辑正确,使用二分查找高效定位第一个大于等于 x 的元素。
边界处理:当 arr 为空时,l 和 r 均为 0,循环不执行,返回 l = 0(符合预期)。当所有元素小于 x 时,l 最终会等于 arr.size()(返回值正确)。当所有元素大于等于 x 时,l 最终会等于 0(返回值正确),A正确。如while 循环条件改为l <= r,当 l == r 时,表示搜索区间只剩下一个元素。此时若继续执行 l = mid + 1,会导致 l 越界(超出数组范围),从而无法正确返回结果,B错误。mid = l + (r - l) / 2 是标准二分查找的 mid 计算方式,避免溢出(l + r 可能溢出),无逻辑错误,C错误。当 arr 为空时,l 和 r 均为 0,循环不执行,返回 l = 0(符合预期)。当所有元素小于 x 时,l 最终会等于 arr.size()(返回值正确)。当所有元素大于等于 x 时,l 最终会等于 0(返回值正确),所以代码逻辑本身边界条件处理正确,D错误。故选A。
第12题 小杨要把一根长度为 L 的木头切成 K 段,使得每段长度小于等于 x 。已知每切一刀只能把一段木头分成两段,他用二分法找到满足条件的最小 x ( x 为正整数),则横线处应填写( )。
// 判断:在不超过 K 次切割内,是否能让每段长度 <= x
cpp
bool check(int L, int K, int x) {
int cuts = (L - 1) / x;
return cuts <= K;
}
// 二分查找最小可行的 x
int binary_cut(int L, int K) {
int l = 1, r = L;
while (l < r) {
int mid = l + (r - l) / 2;
________________________________ // 在此处填入代码
}
return l;
}
int main() {
int L = 10; // 木头长度
int K = 2; // 最多切 K 刀
cout << binary_cut(L, K) << endl;
return 0;
}A.
cpp
if (check(L, K, mid))
r = mid;
else
l = mid + 1;B.
cpp
if (check(L, K, mid))
r = mid+1;
else
l = mid + 1;C.
cpp
if (check(L, K, mid))
r = mid + 1;
else
l = mid - 1;D.
cpp
if (check(L, K, mid))
r = mid + 1;
else
l = mid;解析:答案A。check(L, K, mid) 判断 mid 是否满足条件(切割次数 <= K)。若满足,r = mid 缩小右边界(保留 mid 位置)。若不满足,l = mid + 1 缩小左边界(排除 mid 位置)。循环终止时,l 指向最小可行的 x。二分查找标准实现,确保 l 始终指向可行解。边界处理正确:l < r 避免越界,l 最终为最小可行值或 L,所以A正确。若 check(L, K, mid) 为真,r = mid + 1 会跳过可行解(mid)。若为假,l = mid + 1 正确,但可能错过最小值,B错误。若 check(L, K, mid) 为真,r = mid + 1 会跳过可行解(mid)。若为假,l = mid - 1 可能导致 l 越界(l < 1),C错误。若 check(L, K, mid) 为真,r = mid + 1 会跳过可行解(mid)。若为假,l = mid 会陷入死循环(l 不变),D错误。故选A。
第13题 下面给出了阶乘计算的两种方式。以下说法正确的是( )。
cpp
int factorial1(int n) {
if (n <= 1) return 1;
return n * factorial1(n - 1);
}
int factorial2(int n) {
int acc = 1;
while (n > 1) {
acc = n * acc;
n = n - 1;
}
return acc;
}A. 上面两种实现方式的时间复杂度相同,都为𝑂(𝑛)
B. 上面两种实现方式的空间复杂度相同,都为𝑂(𝑛)
C. 上面两种实现方式的空间复杂度相同,都为𝑂(1)
D. 函数 factorial1() 的时间复杂度为𝑂(2ⁿ),函数 factorial2() 的时间复杂度为𝑂(𝑛)
解析:答案A。factorial1()用递归方法,调用𝑛次,所以时间复杂度为𝑂(𝑛),第调用一次需要保存栈数据,空间复杂度为𝑂(𝑛)。Factorial2()用迭代方法,循环𝑛次,所以时间复杂度为𝑂(𝑛),只使用了循环变量n和结果变量acc,空间复杂度为𝑂(1)。所以A正确,B错误,C错误,D错误。故选A。
第14题 给定有𝑛个任务,每个任务有截止时间和利润,每个任务耗时 1 个时间单位、必须在截止时间前完成,且每个时间槽最多做 1 个任务。为了在规定时间内获得最大利润,可以采用贪心策略,即按利润从高到低排序,尽量安排,则横线处应填写( )。
cpp
struct Task {
int deadline; //截止时间
int profit; //利润
};
void sortByProfit(vector<Task>& tasks) {
sort(tasks.begin(), tasks.end(),
[](const Task& a, const Task& b) {
return a.profit > b.profit;
});
}
int maxProfit(vector<Task>& tasks) {
sortByProfit(tasks);
int maxTime = 0;
for (auto& t : tasks) {
maxTime = max(maxTime, t.deadline);
}
vector<bool> slot(maxTime + 1, false);
int totalProfit = 0;
for (auto& task : tasks) {
for (int t = task.deadline; t >= 1; t--) {
if (!slot[t]) {
_______________________ //在此处填入代码
break;
}
}
}
return totalProfit;
}A.
cpp
slot[t] = true;
totalProfit += task.profit;B.
cpp
slot[t] = false;
totalProfit += task.profit;C.
cpp
slot[t] = true;
totalProfit = task.profit;D.
cpp
slot[t] = false;
totalProfit = task.profit;解析:答案A。slott = true; 标记时间槽 t 已被占用。totalProfit += task.profit; 累加当前任务利润。按利润排序后,优先安排高利润任务。从截止时间 t 向前查找空闲时间槽(贪心策略)。
找到空闲槽后标记并累加利润,确保最大利润,A正确。slott = false; 错误标记时间槽未被占用(应标记为 true)。totalProfit += task.profit; 正确累加利润。时间槽被重复占用(未标记 true),导致冲突,B错误。slott = true; 正确标记时间槽。totalProfit = task.profit; 错误重置总利润(应累加)。忽略之前任务利润,仅是当前任务利润,(总利润错误),C错误。slott = false; 错误标记时间槽未被占用(应标记为 true)。totalProfit = task.profit; 错误重置总利润(应累加)。时间槽被重复占用(未标记 true),导致冲突,总利润只有当前任务利润。故选A。.
第15题 下面代码实现了对两个数组表示的正整数的高精度加法(数组低位在前),则横线上应填写( )。
cpp
vector<int> add(vector<int> a, vector<int> b) {
vector<int> c;
int carry = 0;
for (int i = 0; i < a.size() || i < b.size(); i++) {
if (i < a.size()) carry += a[i];
if (i < b.size()) carry += b[i];
_______________________ //在此处填入代码
}
if (carry) c.push_back(carry);
return c;
}A.
cpp
c.push_back(carry / 10);
carry %= 10;B.
cpp
c.push_back(carry % 10);
carry /= 10;C.
cpp
c.push_back(carry % 10);D.
cpp
c.push_back(carry);
carry /= 10;解析:答案B。当前位如大于9,则产生进行,所以当前位的值应该是carry %10,进位为carry / 10。所以B正确。故选B。.
2 判断题(每题 2 分,共 20 分)
第1题 数组和链表都是线性表。链表的优点是插入删除不需要移动元素,并且能随机查找。
解析:答案╳(错误)。数组和链表都是线性表。链表的优点是插入删除不需要移动元素,数组能随机查找,链表查找只能从头开始一个一个找,时间复杂度为𝑂(𝑛)。故错误。.
第2题 假设函数 gcd() 函数能正确求两个正整数的最大公约数,则下面的 lcm(a, b) 函数能正确找到两个正整 数 a 和 b 的最小公倍数。
cpp
int lcm(int a, int b) {
return a / gcd(a, b) * b;
}解析:答案√(正确)。因为gcd(a, b) * lcm(a, b) = a * b,所以lcm(a, b) = a / gcd(a, b) * b。故正确。.
第3题 在单链表中,已知指针 p 指向要删除的结点(非尾结点),想在𝑂(1)删除 p ,可行做法是用 p->next 覆盖 p 的值与 next ,然后删除 p->next 。
解析:答案√(正确)。用 p->next 覆盖 p 的值与 next,相当于将p变成p->next,删除 p->next后相当于删除了p(p已成为p->next)。故正确。.
第4题 在求解所有不大于 n 的素数时,线性筛法(欧拉筛)都应当优先于埃氏筛法使用,因为线性筛法的时间复杂度为𝑂(𝑛),低于埃氏筛法的𝑂(𝑛 log log 𝑛)。
解析:答案╳(错误)。理论上线性筛法优于埃氏筛法,但实际上,当𝑛≤10⁷时,埃氏筛法更快,当𝑛>10⁸时,线性筛法更快;当10⁷<𝑛≤10⁸时,两者性能接近,但埃氏筛法可能仍稍快或需实测确定。原因是:(1)缓存命中率差异: 埃氏筛法 :内层循环以固定步长跳跃访问内存(如质数p的倍数),内存访问模式被 CPU 预取器准确预测,缓存命中率高达 98%(n=10⁷ 时);线性筛法:需遍历质数表并计算 i * p,内存访问随机性强,缓存命中率仅 89%****。 (2)指令复杂度对比 :单元素操作平均指令数:埃氏筛法4.1条,线性筛法12.7条;埃氏筛法无分支跳转,线性筛法需维护质数表并执行高代价的取模运算(i % p)。故错误。
第5题 二分查找仅适用于有序数据。若输入数据无序,当仅进行一次查找时,为了使用二分而排序通常不划算。
解析:答案√(正确)。普通查找的时间复杂度为𝑂(𝑛),而最快的排序也需要𝑂(𝑛 log 𝑛),所以当仅进行一次查找时,为了使用二分而排序通常不划算。故正确。.
第6题 通过在数组的第一个、最中间和最后一个这3个数据中选择中间值作为枢轴(比较基准),快速排序算法可降低落入最坏情况的概率。
解析:答案√(正确)。这种方法的核心原理是:通常快速排序算法最坏情况通常发生在枢轴选择不当(如选择最小或最大元素)时,导致分割后的子数组严重不平衡。通过取三个位置元素的中位数作为枢轴,可以更好地近似整个数组的真实中位数,从而提高分割的平衡性。这减少了极端不平衡分割的可能性,使得算法在平均情况下更接近𝑂(𝑛 log 𝑛)的时间复杂度,可以有效降低算法落入最坏情况的时间复杂度(𝑂(𝑛²))的概率。故正确。
第7题 贪心算法在每一步都做出当前看来最优的局部选择,并且一旦做出选择就不再回溯;而分治算法将问题分解为若干子问题分别求解,再将子问题的解合并得到原问题的解。
解析:答案√(正确)。贪心算法的核心思想:贪心算法在每一步决策时,都选择当前状态下最优的局部选择(即"贪心选择"),并基于这种局部最优选择逐步构建问题的解。一旦做出选择,算法就不会回溯或修改之前的决策。分治算法 的核心思想:分治算法将原问题分解为若干个规模较小、相互独立且与原问题相似的子问题("分解"),递归地求解这些子问题("求解"),然后将子问题的解合并起来,形成原问题的解("合并")。故正确。
第8题 以下 fib 函数计算第n 项斐波那契数(fib(0)=0 , fib(1)=1),其时间复杂度为𝑂(𝑛)。
cpp
int fib(int n) {
if (n <= 1) return n;
return fib(n-1) + fib(n-2);
}解析:答案╳(错误)。此递归算法的时间复杂度为𝑂(2ⁿ),不是𝑂(𝑛)。故错误。
第9题 递归函数一定要有终止条件,否则可能会造成栈溢出。
解析:答案√(正确)。递归函数如果没有终止条件,会导致无限递归(相当于无限循环),最终引发栈溢出错误。故正确。.
第10题 使用贪心算法解决问题时,通过对每一步求局部最优解,最终一定能找到全局最优解。
解析:答案╳(错误)。使用贪心算法解决问题时,通过对每一步求局部最优解,不一定能找到全局最优解。故错误。
3 编程题(每题 25 分,共 50 分)
3.1 编程题 1
- 试题名称:数字移动
- 时间限制:1.0 s
- 内存限制:512.0 MB
3.1.1题目描述
小 A 有一个包含𝑁个正整数的序列𝐴={𝐴₁, 𝐴₂, ..., 𝐴},序列𝐴恰好包含
对不同的正整数。形式化地,对于任意1≤𝑖≤𝑁,存在唯一一个𝑗满足1≤𝑗≤𝑁, 𝑖≠𝑗, 𝐴ᵢ=𝐴ⱼ。
小A希望每对相同的数字在序列中相邻,为了实现这一目的,小A每次操作会选择任意𝑖(1≤𝑖≤𝑁),将当前序列的第𝑖个数字移动到任意位置,并花费对应数字的体力。
例如,假设序列𝐴{1, 2, 1, 3, 2, 3},小A可以选择𝑖=2,将𝐴₂=2移动到𝐴₃=1的后面,此时序列变为{1, 1, 2, 3, 2, 3},耗费2点体力。小A也可以选择𝑖=3,将𝐴₃=1移动到𝐴₂=2的前面,此时序列变为{1, 1, 2, 3, 2, 3},花费1点体力。
小A可以执行任意次操作,但他希望自己每次花费的体力尽可能小。小A希望你能帮他计算出一个最小的𝑥,使得他能够在每次花费的体力均不超过𝑥的情况下令每对相同的数字在序列中相邻。
3.1.2 输入格式
第一行一个正整数𝑁,代表序列长度,保证𝑁为偶数。
第二行包含𝑁个正整数𝐴₁, 𝐴₂, ..., 𝐴𝑁,代表序列𝐴。且对于任意1≤𝑖≤𝑁,存在唯一一个𝑗满足1≤𝑗≤𝑁, 𝑖≠𝑗, 𝐴ᵢ=𝐴ⱼ。
数据保证小A至少需要执行一次操作。
3.1.3 输出格式
输出一行,代表满足要求的𝑥的最小值。
3.1.4 样例
3.1.4.1 输入样例
cpp
6
1 2 1 3 2 33.1.4.2 输出样例
cpp
23.1.5 数据范围
对于40%的测试点,保证1≤𝑁, 𝐴ᵢ≤100。
对于所有测试点,保证1≤𝑁, 𝐴ᵢ≤10⁵。
3.1.6 编写程序
编程思路:
这是要从小的里面找最大值。使用分治求解。
按题目移动次数不限,每次花费的体力尽可能小,所以要移就移小的那个数,要找在移的小的数中最大的那个,这个数以下的数移动可使每对相同的数字在序列中相邻。
1 2 2 1、2 1 1 2移动小的数1,2 1 1 2 6 6 8 7 8 7移动1和7,7是其中最大的,即x=7。
方法一:
用check()检查序列中大于mid的元素是否都成对?如不成对,则从比mid大的元素再检查,如都成对,则当前答案(要找的x)取mid,再从比mid小的元素中检查。
参考程序代码如下:
cpp
#include <iostream>
using namespace std;
int a[100005], n, l, r, mid, ans, x; // 𝑁≤10⁵
bool check() { //
x = 0;
for (int i = 1; i <= n; i++) {
if (a[i] <= mid) continue; // 跳过不超过mid的a[i]不检查
if (!x) x = a[i]; // 如果x=0,则x=a[i],第1个值
else if (a[i] != x) return 0; // 如果成对,返回0
else x = 0; // 成对,则重置,继续找
}
return 1; // 大于mid的数都成对,返回1
}
int main() {
cin >> n;
for (int i = 1; i <= n; i++) {
cin >> a[i];
if (a[i] > r) r = a[i]; // 边求最大值作为二分右值
}
while (l <= r) { // 二分(分治)
mid = (l + r) / 2;
if (check()) { // 如果大于mid的数全部成对
ans = mid; // 当前要找的x就是mid
r = mid - 1; // 再从比mid小的数中去找
} else l = mid + 1; // 否则再从比mid大的数中去找
}
cout << ans;
return 0;
}方法二:
先将大于mid的元素存入b数组,然后检查是否都成对?如不成对,则从比mid大的元素再检查,如都成对,则当前答案(要找的x)取mid,再从比mid小的元素中检查。
参考程序代码如下:
cpp
#include <iostream>
using namespace std;
const int N = 100005; // 𝑁≤10⁵
int a[N], b[N], pos;
int main() {
int n, left=0, right, ans;
cin >> n;
for (int i = 0; i < n; i++) {
cin >> a[i];
if (a[i] > right) right = a[i]; // 边求最大值作为二分右值
}
while (left <= right) { // 二分(分治)
int mid = (left + right) / 2;
bool possible = true;
pos = 0;
for (int i = 0; i < n; i++) // 将>mid的数存入b,pos为计数
if (a[i] > mid) b[pos++] = a[i];
for (int i = 0; i < pos; i += 2) { // 检查pos个数
if (b[i] != b[i + 1]) { // 如不两两成对
possible = false; // possible为false
break;
} // 否则possible为true
}
if (possible) { // 如果大于mid的数全部成对
ans = mid; // mid是当前要找的x
right = mid - 1; // 再从比mid小的数中去找
} else left = mid + 1; // 否则再从比mid大的数中去找
}
cout << ans << endl;
return 0;
}3.2 编程题 2
- 试题名称:相等序列
- 时间限制:1.0 s
- 内存限制:512.0 MB
3.2.1题目描述
小A有一个包含𝑁个正整数的序列𝐴={𝐴₁, 𝐴₂, ..., 𝐴𝑁}。小A每次可以花费1个金币执行以下任意一种操作:
选择序列中一个正整数𝐴ᵢ(1≤𝑖≤𝑁),将𝐴ᵢ变为𝐴ᵢ×𝑃,𝑃为任意质数;
选择序列中一个正整数𝐴ᵢ(1≤𝑖≤𝑁),将𝐴ᵢ变为 ,𝑃为任意质数,要求𝐴ᵢ能整除𝑃。
小A想请你帮他计算出令序列中所有整数都相同,最少需要花费多少金币。
3.2.2 输入格式
第一行一个正整数𝑁,含义如题面所示。
第二行包含𝑁个正整数𝐴₁, 𝐴₂, ..., ,代表序列𝐴。
3.2.3 输出格式
输出一行,代表最少需要花费的金币数量。
3.2.4 样例
3.2.4.1 输入样例
cpp
5
10 6 35 105 423.2.4.2 输出样例
cpp
83.2.5 数据范围
对于60%的测试点,保证1≤𝑁, 𝐴ᵢ≤100。
对于所有测试点,保证1≤𝑁, 𝐴ᵢ≤10⁵。
3.2.6 编写程序
编程思路:
很明显是分解质因数的问题,例如这组测试数据{6, 20, 28, 210, 66},那么我们先分解出每个数的质因数如图1所示:
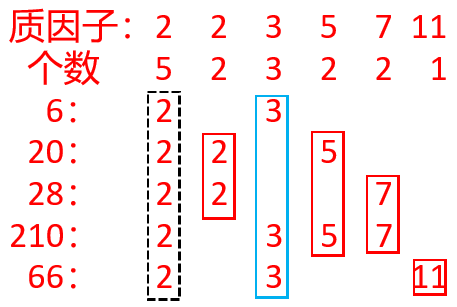
图1
这五个数的全部因子有2、2、3、5、7、11共六个,第1个质因子2五个数都有,不需要乘或除,第2个质因子2只有两个数有,少于总数的一半,除可以少操作,第3个质因子3三个数有,多于总数的一半,乘可以少操作,质因子5、7、11都少于总数的一半,除可以少操作,如刚好一半对一半,则乘、除都可以。所以最少操作(最少需要花费金币数)是min(N-某质因子个数,某质因子个数)的和。
本例最少操作=min(5-5,5)+min(5-2,2)+min(5-3,3)+min(5-2,2)+ min(5-2,2)+min(5-1,1)=9。
对样例:序列{10, 6, 35, 105, 42}如图2所示:
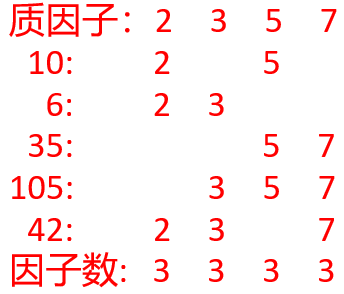
图2
所以最少操作=min(5-3,3)+min(5-3,3)+min(5-3,3)+min(5-3,3)=8。
方法一:
先用埃氏筛法求出2~10⁵的所有质数。在埃氏筛法的基础上稍作改变,标准埃氏筛法数组默认为true(默认都是质数),找到质数后将其倍数标记为false(不是质数)。本方法中数组默认为0,找到质数后将其倍数标记为1,如是质数记录是第几(非0)个质数。10⁵分解为质因子数,如全部以质数2分解,也只有16.6,不超过17位。所以定义aN18。
参考程序代码如下:
cpp
#include<iostream>
using namespace std;
const int N = 100005; // 𝑁≤10⁵
int n, x, a[N][18], m, cnt, p[N], b[N], ans;
int main() {
cin >> n;
for (int i = 2; i <= N; i++) { // 埃氏筛法求~10⁵+5的质数
if (!b[i]) {
p[++cnt] = i, b[i] = cnt; // 如i是质数,记录其序号
for (int j = i + i; j <= N; j += i)b[j] = 1; // 倍数标记为非质数
}
}
for (int i = 1; i <= n; i++) {
cin >> x;
for (int j = 1; p[j]*p[j] <= x; j++) { // 求x的质因子
for (int k = 1; k < 18 && x >= p[j]; k++) {
if (x % p[j]) break; // 质数p[j]不是质因子,则取下一个质数
x /= p[j]; // p[j]是质因子,从x中去除此因子,继续求质因子
a[j][k]++; // a的j行(表示第j个质数),第k个因子+1(计数)
}
}
if (x > 1)a[b[x]][1]++; // 如x>0,则x为质因子,对应质数编号第1个因子+1
}
for (int i = 1; i <= cnt; i++) { // 遍历所有质因子
for (int j = 1; a[i][j]; j++) // 对其质因子数求min((n-a[i][j])<a[i][j])
ans += (n - a[i][j])<a[i][j]?(n - a[i][j]):a[i][j];
}
cout << ans;
return 0;
}方法二:不记录质数位置,而是需求时刻遍历查找。参考程序代码如下:
cpp
#include <iostream>
using namespace std;
const int N = 100005;
int num[N][18], n, a[N];
int main(){
cin >> n;
for(int i=1;i<=n;i++){
cin >> a[i];
int x = a[i];
for(int i=2;i*i<=x;i++){
if(x%i==0){
int cnt=0;
while(x%i==0){
x/=i;
cnt++;
}
num[i][cnt]++;
}
}
if(x>1){
num[x][1]++;
}
}
int ans=0;
for(int i=2;i<100001;i++){
int pos = 0;
for(int j=0;j<18;j++){
pos += num[i][j];
}
num[i][0]=n-pos;
int p_pos=0;
pos = 0;
for(int j=0;j<18;j++){
pos += num[i][j];
if(pos*2>=n){
p_pos=j;
break;
}
}
for(int j=0;j<18;j++){
ans+=num[i][j]*abs(j-p_pos);
}
}
cout << ans;
}