Qwen
Qwen3 Technical Report
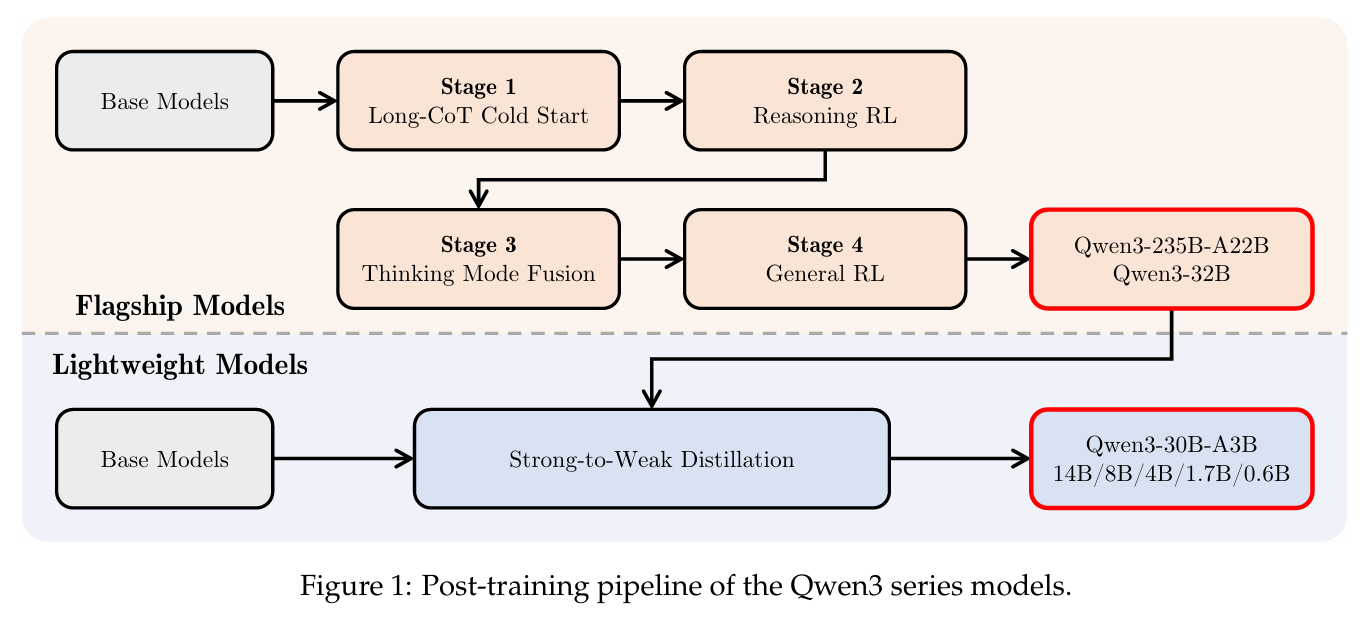
一、模型架构
1. 模型规模系列
Qwen3包含8个模型,分为两大类:
Dense(稠密)模型 - 6个:
MoE(专家混合)模型 - 2个:
2. 核心架构特点
所有Qwen3模型采用类似的基础架构,包括:
- Grouped Query Attention (GQA):通过在多个Query头之间共享Key/Value头来优化推理速度和内存使用
- SwiGLU激活函数
- Rotary Positional Embeddings (RoPE):旋转位置编码
- RMSNorm:预归一化
- QK-Norm:应用于所有模型的注意力机制以确保训练稳定性
- 移除了Qwen2中的QKV-bias
上下文长度:
- 小模型(0.6B/1.7B/4B):32K tokens
- 大模型(8B/14B/32B及MoE模型):128K tokens
3. MoE架构特色
Qwen3-MoE模型采用细粒度专家分割,共有128个专家,每个token激活8个专家。关键改进包括:
- 不使用共享专家(与Qwen2.5-MoE不同)
- 采用全局批次负载平衡损失来鼓励专家专业化
二、预训练(Pretraining)
1. 数据规模
训练数据达到约36万亿tokens,覆盖119种语言和方言,相比Qwen2.5从29种扩展到119种
数据来源包括:
- 高质量网页内容
- 使用Qwen2.5-VL从PDF文档中提取并精炼的文本
- 使用Qwen2.5-Math和Qwen2.5-Coder生成的数万亿合成数据
- STEM、编程、推理任务、书籍、多语言文本
2. 三阶段预训练策略
阶段1:通用阶段(S1)
- 使用超过30万亿tokens训练,序列长度4096
- 学习基础语言能力和通用世界知识
- 覆盖119种语言
阶段2:推理阶段(S2)
- 使用约5万亿高质量tokens,增加STEM、编码、推理和合成数据的比例
- 加速学习率衰减
- 提升推理能力
阶段3:长文本阶段
- 使用数千亿tokens训练,序列长度32768
- 75%的文本长度在16384-32768之间,25%在4096-16384之间
- 使用ABF技术将RoPE基频从10000提升到1000000
- 引入YARN和Dual Chunk Attention(DCA)实现4倍序列长度扩展
3. Scaling Law指导
通过三阶段预训练过程的全面scaling law研究,系统调优关键超参数(如学习率调度器和批次大小),为dense和MoE模型分别设置
三、后训练(Post-training)
Qwen3的核心创新在于统一框架下的双模式系统:
1. 四阶段训练流程
阶段1:长CoT冷启动(Long-CoT Cold Start)
- 构建包含数学、编程、逻辑推理和STEM问题的综合数据集
- 使用QwQ-32B生成N个候选响应
- 严格过滤:去除错误答案、重复内容、猜测、不一致等
- 目标是建立基础推理模式而不过度强调立即性能
阶段2:推理强化学习(Reasoning RL)
- 收集3995个查询-验证器对,使用GRPO算法
- 采用大批次和高rollout数
- 结合off-policy训练提高样本效率
- 旗舰模型Qwen3-235B-A22B的AIME'24分数从70.1提升到85.1(170个RL训练步骤)
阶段3:思维模式融合(Thinking Mode Fusion)
这是Qwen3的关键创新!
Chat模板设计:
Thinking模式:
<|im_start|>user
{query} /think<|im_end|>
<|im_start|>assistant
<think>
{思维内容}
</think>
{回答}<|im_end|>
Non-thinking模式:
<|im_start|>user
{query} /no_think<|im_end|>
<|im_start|>assistant
<think>
</think>
{回答}<|im_end|>- 使用/think和/no_think标志让用户动态切换模型思维过程
- 对于非思维模式样本,保留空的thinking块以确保内部格式一致性
- 默认为思维模式
思维预算机制(Thinking Budget):
- 当思维长度达到用户定义阈值时,手动停止思维并插入指令:"考虑到用户的时间限制,我必须直接基于当前思考给出解决方案。\n.\n\n"
- 这种能力不是显式训练的,而是作为思维模式融合的自然结果出现
阶段4:通用强化学习(General RL)
目标是广泛提升各种场景下的能力和稳定性,建立了覆盖20多个任务的复杂奖励系统:
核心能力:
- 指令遵循:准确解释内容、格式、长度要求
- 格式遵循:响应/think和/no_think标志,正确使用标签
- 偏好对齐:提升有用性、参与度和风格
- Agent能力:通过多轮交互训练工具调用
- 特殊场景:如RAG任务中减少幻觉
使用三种奖励类型:
- 基于规则的奖励
- 带参考答案的模型奖励
- 无参考答案的模型奖励(从人类偏好数据训练)
2. Strong-to-Weak蒸馏
这是优化轻量级模型的专门流程,包括5个dense模型和1个MoE模型
两阶段过程:
阶段1:Off-policy蒸馏
- 结合教师模型在/think和/no_think模式下的输出
- 帮助学生模型建立基础推理能力和模式切换能力
阶段2:On-policy蒸馏
- 学生模型生成on-policy序列,然后通过最小化与教师模型(Qwen3-32B或Qwen3-235B-A22B)的KL散度来微调
- 实验显示蒸馏比强化学习获得更好的即时性能(Pass@1)和探索能力(Pass@64),且仅需约1/10的GPU小时
三、关键创新总结
-
双模式统一框架:无需在不同模型(如GPT-4o和QwQ-32B)之间切换
-
思维预算控制:用户可以根据任务复杂度自适应分配计算资源,平衡延迟和性能
-
效率突破:Qwen3-MoE基础模型仅使用Qwen2.5 dense基础模型10%的激活参数就能达到相当性能
-
性能提升:Qwen3-1.7B/4B/8B/14B/32B-Base的性能分别相当于Qwen2.5-3B/7B/14B/32B/72B-Base
Qwen2.5-VL Technical Report
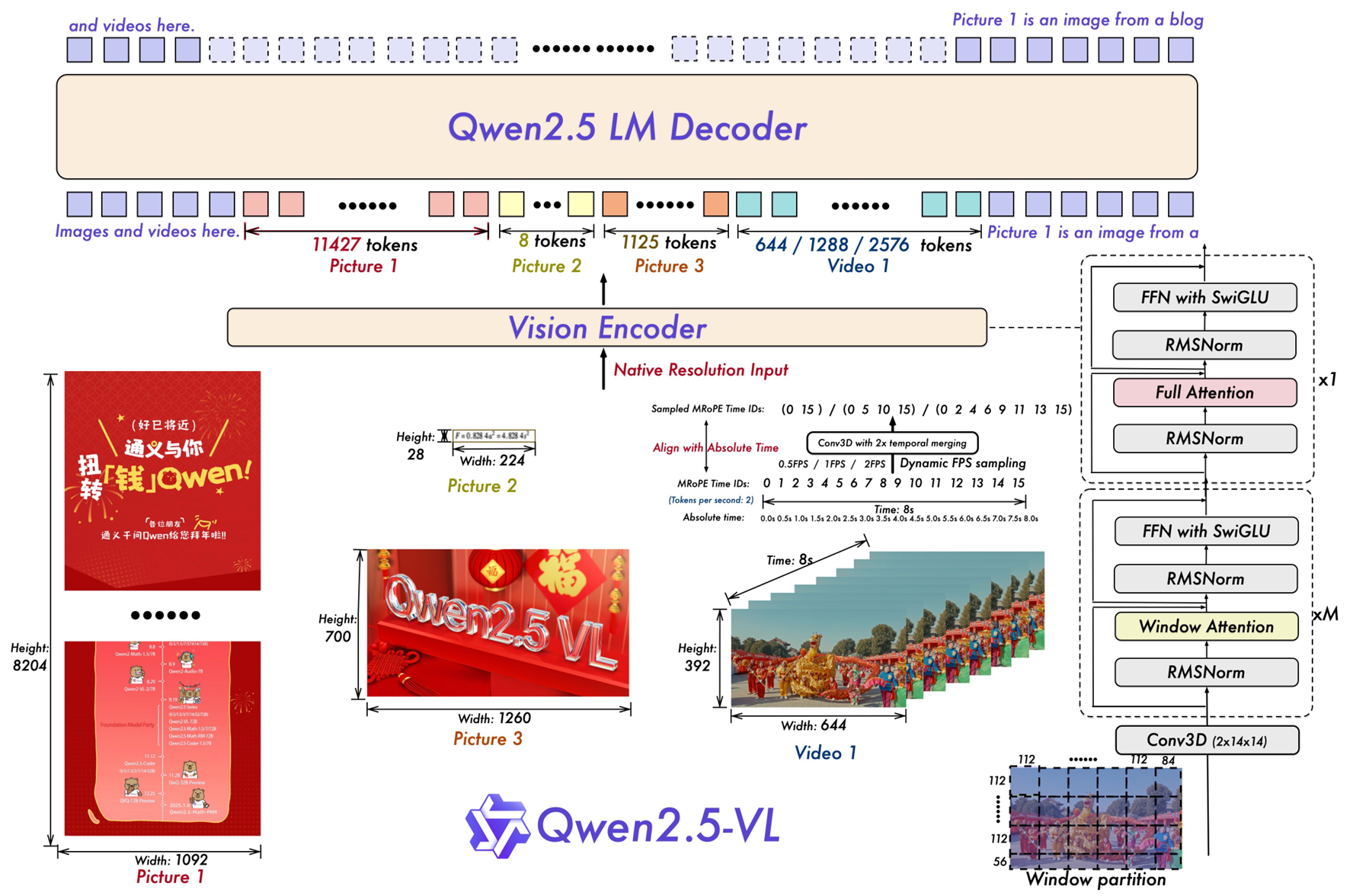
Qwen2.5-VL 架构与训练详解
一、模型架构
Qwen2.5-VL由三个核心组件组成:
1. 视觉编码器(Vision Encoder)
- 基础架构:重新设计的Vision Transformer (ViT)
- 创新设计 :
- 采用窗口注意力机制(Window Attention):大部分层使用窗口大小为112×112的局部注意力,仅4层使用全局注意力
- 支持原生动态分辨率:输入图像调整为28的倍数,以14×14的patch进行切分
- 使用2D-RoPE位置编码来捕捉空间关系
- 视频处理:将连续两帧分组,扩展到3D patch分割
- 架构细节 :
- Hidden Size: 1280
- 层数: 32层
- 激活函数: SwiGLU
- 归一化: RMSNorm
2. 视觉-语言融合器(Vision-Language Merger)
- 设计:基于MLP的简单高效方案
- 压缩策略:将相邻的4个patch特征分组,通过两层MLP投影到与LLM文本嵌入相同的维度
- 作用:在保持灵活性的同时减少计算成本
3. 大语言模型(LLM)
- 基础:基于Qwen2.5 LLM初始化
- 改进 :将1D RoPE升级为多模态RoPE对齐到绝对时间 (MRoPE Aligned to Absolute Time)
- 包含三个组件:时间、高度、宽度
- 关键创新:时间ID与视频的实际时间戳对齐,而非仅与帧数相关
4. 三种规模配置
| 模型 | LLM Hidden Size | LLM层数 | 训练Tokens |
|---|---|---|---|
| Qwen2.5-VL-3B | 2048 | 36 | 4.1T |
| Qwen2.5-VL-7B | 3584 | 28 | 4.1T |
| Qwen2.5-VL-72B | 8192 | 80 | 4.1T |
二、预训练(Pre-Training)
数据规模
从Qwen2-VL的1.2T tokens扩展到约4T tokens,数据包括:
- 图像标注、交错图文数据
- OCR数据、视觉知识
- 多模态学术问题
- 定位数据、文档解析数据
- 视频描述、视频定位
- Agent交互数据
三阶段训练策略
第一阶段:视觉预训练
- 训练对象:仅训练ViT
- 数据量:1.5T tokens
- 数据类型:图像标注、视觉知识、OCR、纯文本
- 序列长度:8192
- 目的:建立ViT与语言模型的对齐基础
第二阶段:多模态预训练
- 训练对象:ViT + LLM全部参数
- 数据量:2T tokens
- 数据类型:交错数据、VQA、视频、Grounding、Agent任务、纯文本
- 序列长度:8192
- 目的:增强复杂视觉信息处理能力
第三阶段:长上下文预训练
- 训练对象:ViT + LLM
- 数据量:0.6T tokens
- 数据类型:长视频、长Agent任务、长文档
- 序列长度:32768
- 目的:提升长序列推理能力
关键数据创新
-
交错图文数据:四级评分系统(文本质量、图文相关性、信息互补性、信息密度平衡)
-
绝对坐标Grounding数据:使用图像实际尺寸的坐标值,支持10,000+物体类别
-
文档全能解析数据:统一HTML格式表示文档(表格、图表、公式、乐谱、化学式等)
-
动态FPS视频数据:支持可变帧率,时间戳对齐到绝对时间
三、后训练(Post-Training)
监督微调(SFT)阶段
数据规模:约200万条数据
- 50%纯文本数据
- 50%多模态数据(图像-文本、视频-文本)
数据构成:
- 通用VQA、图像描述
- 数学问题、代码任务
- 文档&OCR、Grounding
- 视频分析、Agent交互
数据过滤流程:
第一阶段:领域分类
- 使用Qwen2-VL-Instag模型将QA对分为8个主域、30个子类别
第二阶段:定制化过滤
- 基于规则:去除重复模式、不完整响应、有害内容
- 基于模型:评估复杂度、正确性、完整性、清晰度、相关性
拒绝采样(Rejection Sampling):
- 针对数学、代码、领域VQA等需要复杂推理的任务
- 使用中间版本模型生成,仅保留与标准答案匹配的样本
- 增强思维链(CoT)推理能力
直接偏好优化(DPO)阶段
- 冻结参数:ViT参数保持冻结
- 数据类型:图像-文本和纯文本偏好数据
- 训练策略:每个样本仅处理一次,确保高效优化
- 目标:与人类偏好对齐
训练优化
动态数据打包:
- 根据LLM输入序列长度动态打包样本
- 确保各GPU计算负载一致
- 阶段1-2:序列长度8192
- 阶段3:序列长度32768
四、核心技术亮点
- 原生动态分辨率:直接使用图像实际尺寸,无需归一化坐标
- 绝对时间编码:MRoPE时间ID与视频时间戳对齐,理解事件节奏
- 窗口注意力:计算复杂度从O(n²)降至O(n)
- 动态FPS采样:适应不同帧率的视频内容
- 统一HTML文档格式:整合布局、文本、图表、插图
DeepSeek
DeepSeek-V2 架构与训练详解
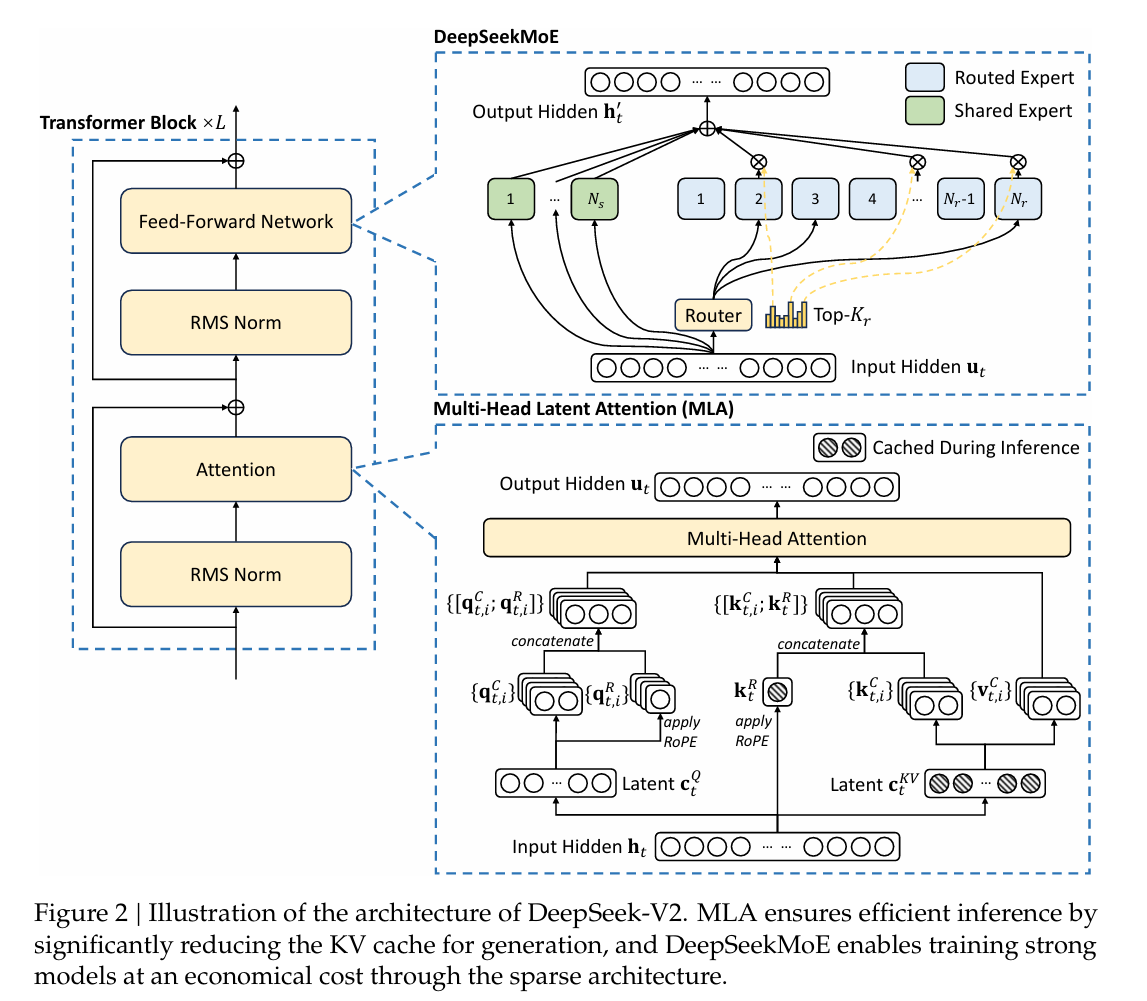
一、模型架构
DeepSeek-V2是一个创新的MoE(混合专家)大语言模型,具有以下核心特点:
基本配置
- 总参数: 236B
- 激活参数: 每个token激活21B参数
- 上下文长度: 128K tokens
- 层数: 60层
- 隐藏维度: 5120
1. Multi-head Latent Attention (MLA) - 高效推理的关键
MLA是DeepSeek-V2最重要的创新之一,通过低秩KV联合压缩大幅减少推理时的KV缓存:
核心机制:
-
KV联合压缩:
c_KV = W_DKV × h_t (压缩到潜在向量) k_C = W_UK × c_KV v_C = W_UV × c_KV- KV压缩维度 d_c = 512 (相比标准的 128×128=16384 大幅减少)
- 推理时只需缓存压缩后的潜在向量 c_KV
-
解耦的RoPE策略:
- 为避免RoPE与低秩压缩冲突,使用额外的多头查询 q_R 和共享键 k_R 来承载RoPE
- 维度 d_R_h = 64(每个头)
性能优势:
- 相比DeepSeek 67B,KV缓存减少93.3%
- 每个token的KV缓存仅为 (d_c + d_R_h)×l = (512 + 64)×60 ≈ 34.6K 元素
- 相当于GQA只有2.25个组,但性能优于标准MHA
2. DeepSeekMoE - 经济训练的核心
DeepSeekMoE采用细粒度专家分割 和共享专家隔离策略:
架构设计:
- 共享专家: 2个(所有token都会激活)
- 路由专家: 160个
- 激活专家数: 6个路由专家
- 专家中间维度: 1536
- 部署: 除第一层外,所有FFN都替换为MoE层
关键机制:
(1) 设备受限路由 (Device-Limited Routing)
- 将160个路由专家分布在8个设备上(D=8)
- 每个token最多路由到3个设备(M=3)
- 控制通信开销
(2) 三重负载均衡损失
总损失 = 专家级均衡损失 + 设备级均衡损失 + 通信均衡损失
L = α₁×L_ExpBal + α₂×L_DevBal + α₃×L_CommBal- α₁ = 0.003, α₂ = 0.05, α₃ = 0.02
(3) Token丢弃策略
- 训练时采用设备级token丢弃
- 每个设备的容量因子为1.0
- 确保约10%的训练序列永不丢弃token
3. 注意力机制对比
| 机制 | KV缓存/token | 性能 |
|---|---|---|
| MHA | 2n_h × d_h × l | 强 |
| GQA | 2n_g × d_h × l | 中等 |
| MQA | 2d_h × l | 弱 |
| MLA | (d_c + d_R_h) × l ≈ 4.5d_h × l | 更强 |
二、预训练 (Pre-Training)
数据构建
- 总量: 8.1T tokens
- 语言分布: 中文tokens比英文tokens多约12%
- 词表: 100K (Byte-level BPE)
- 序列长度: 4K
数据质量提升:
- 扩展数据量,优化清洗流程,恢复被误删的大量数据
- 增加中文数据比例
- 改进基于质量的过滤算法
- 过滤有争议内容以减少数据偏见
训练策略
优化器配置:
- AdamW优化器
- β₁ = 0.9, β₂ = 0.95
- weight_decay = 0.1
- 最大学习率 = 2.4×10⁻⁴
- 梯度裁剪范数 = 1.0
学习率调度:
- Warmup阶段: 前2K步线性增长到最大值
- 第一次衰减: 训练约60%的tokens后,学习率×0.316
- 第二次衰减: 训练约90%的tokens后,再次×0.316
批次大小调度:
- 前225B tokens: 从2304逐渐增加到9216
- 之后保持9216
并行策略:
- 16路零气泡流水线并行
- 8路专家并行
- ZeRO-1数据并行
- 无需张量并行(减少通信开销)
训练效率
- 在H800集群上训练
- 训练每T tokens仅需172.8K GPU小时
- 相比DeepSeek 67B(300.6K GPU小时),节省42.5%训练成本
长上下文扩展
- 使用YaRN方法将4K扩展到128K
- 参数设置: scale s=40, α=1, β=32
- 额外训练1000步,序列长度32K,批次大小576
- 在"Needle In A Haystack"测试中表现优异
三、后训练 (Post-Training)
监督微调 (SFT)
数据构成:
- 总量: 1.5M实例
- 帮助性数据: 1.2M
- 安全性数据: 0.3M
数据改进:
- 提高数据质量以减少幻觉
- 增强写作能力
- 优化指令遵循能力
训练配置:
- 训练2个epoch
- 学习率 = 5×10⁻⁶
- 使用ChatML格式
强化学习 (RL)
算法: Group Relative Policy Optimization (GRPO)
- 无需critic模型(通常与policy模型同等大小)
- 使用组得分估计基线
- 节省训练成本
目标函数:
J_GRPO = E[最小化(ratio × A_i, clip(ratio, 1-ε, 1+ε) × A_i)] - β×D_KL
其中 ratio = π_θ(o_i|q) / π_θ_old(o_i|q)两阶段训练策略:
(1) 推理对齐阶段
- 训练推理奖励模型 RM_reasoning
- 针对代码和数学任务
- 奖励: r_i = RM_reasoning(o_i)
(2) 人类偏好对齐阶段
-
多奖励框架:
r_i = c₁×RM_helpful(o_i) + c₂×RM_safety(o_i) + c₃×RM_rule(o_i) -
有用性RM、安全性RM、基于规则的RM
奖励模型训练:
- 使用DeepSeek-V2 Chat (SFT)初始化
- 代码偏好数据基于编译器反馈
- 数学偏好数据基于真实标签
- 采用point-wise或pair-wise损失
工程优化:
- 混合引擎:训练和推理采用不同并行策略
- 使用vLLM大批次推理加速
- 精心设计的CPU-GPU模型卸载/加载调度
四、性能亮点
训练效率
- 训练成本降低42.5%
- KV缓存减少93.3%
- 生成吞吐量提升5.76倍
推理效率
- 部署时使用FP8精度
- KV缓存量化到平均6 bits
- 单节点8×H800: 生成吞吐量>50K tokens/秒
- Prompt输入吞吐量>100K tokens/秒
模型性能
- MMLU: 78.5%
- GSM8K: 79.2%
- HumanEval: 48.8%
- 仅21B激活参数达到顶级开源模型性能
对话能力
- AlpacaEval 2.0: 38.9% (长度控制胜率)
- MT-Bench: 8.97
- AlignBench (中文): 7.91 (超越所有开源模型)
五、关键创新总结
- MLA: 通过低秩KV联合压缩实现高效推理,性能优于MHA但缓存仅为其7%
- DeepSeekMoE: 细粒度专家分割+共享专家隔离,实现经济训练
- 设备受限路由: 控制MoE通信开销
- 两阶段RL: 先推理对齐,后人类偏好对齐
- GRPO算法: 无需critic模型的高效RL训练
DeepSeek-V2证明了通过架构创新,可以在显著降低训练和推理成本的同时,达到甚至超越密集模型的性能。