一、主方法-应用起点
PreRowDataToOdsHive
除了spark环境准备外还要实现安装卸载激活的数据加载入库
loadRowToOds.loadInstall()
loadRowToOds.loadActivate()
loadRowToOds.loadUnInstall()
Scala
package com.dw.application
import com.dw.common.utils.{SparkEnv, SparkEnvUtil}
import com.dw.service.LoadRowToOds
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SparkSession
object PreRowDataToOdsHive extends SparkEnv {
/**
* 预处理HDFS上的ROW层下的用户行为数据文件
* 将处理后的数据加载到hive的ODS表中
*/
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.ERROR) //日志控制代码,要在线程创建之前设置
//环境准备
//val sc: SparkContext = getSparkContext()
//SparkEnvUtil.setSc(sc)
val spark: SparkSession = getSparkSession(master = "local[*]")
SparkEnvUtil.setSession(spark)
val loadRowToOds = new LoadRowToOds
//安装数据入库
println("#############安装数据入库#############")
loadRowToOds.loadInstall()
println("#############激活数据入库#############")
loadRowToOds.loadActivate()
println("#############卸载数据入库#############")
loadRowToOds.loadUnInstall()
//释放连接
//SparkEnvUtil.clearSc()
//sc.stop()
SparkEnvUtil.clearSession()
spark.stop()
}
}二、功能实现类LoadRowToOds
主要实现三个逻辑:安装、卸载、激活的数据加载入库
结合ods层的三个样例类将读取到的数据转换成DataSet,然后再写入hive表
Scala
package com.dw.service
import com.dw.common.utils.{ConfigUtil, SparkEnvUtil}
import com.dw.dao.{HdfsFileOpt, SparkReadHdfsFile}
import com.dw.entity.{OdsActivate, OdsInstall, OdsUninstall}
import com.dw.util.{DateUtils, StringUtils}
import org.apache.spark.sql.{Dataset, SparkSession}
import java.time.LocalDate
import java.time.format.DateTimeFormatter
class LoadRowToOds extends Serializable {
private val odsFilePath = ConfigUtil.getHdfsFilePath.getConfig("hdfs_file_path")
private val odsFilePrefix = ConfigUtil.getHdfsFilePath.getConfig("hdfs_file_Prefix")
private val odsHiveTableName = ConfigUtil.getHiveTableName.getConfig("ods")
private val spark: SparkSession = SparkEnvUtil.getSession
//private val sc: SparkContext = SparkEnvUtil.getSc
private val stringUtils = new StringUtils
private val hdfsFileOpt = new HdfsFileOpt
private val dateUtils = new DateUtils
import spark.implicits._
private val sparkReadHdfsFile = new SparkReadHdfsFile
/**
* 实现把安装的hadoop中的row层数据加载到对应的hive的ods表中
*/
def loadInstall(today: String = LocalDate.now().format(DateTimeFormatter.ofPattern("yyyyMMdd"))): Unit = {
val installPath = odsFilePath.getString("user_install_path") //ods文件所在的hadoop路径
val installPrefix = odsFilePrefix.getString("user_install_file_Prefix") //安装文件的前缀
val installTableName = odsHiveTableName.getString("ods_app_install") //安装的ods表名
//读取安装的文件路径+日期目录+前缀下的文件,加载成ds
val installDs: Dataset[String] = sparkReadHdfsFile.readFilesByPrefix(installPath + "/" + today, installPrefix)
if (!installDs.isEmpty) {
//获取到的文件名清单
val fileNameList = installDs.map(row => {
row.split("\\|")(4)
}).collect().distinct.toList
// 3. 修复分区元数据(可选,避免Hive看不到新增分区)
spark.conf.set("hive.exec.dynamic.partition", "true")
spark.conf.set("hive.exec.dynamic.partition.mode", "nonstrict")
//解析读取到的ds数据并加载到hive表中
installDs.map((rows: String) => {
val strings: Array[String] = rows.split("\\|")
OdsInstall(
device_id = strings(0),
app_id = strings(1),
install_channel_id = strings(2),
install_time = dateUtils.strToTimestamp(strings(3)),
file_name = strings(4),
dt = stringUtils.getFiveCharsAfterPrefix(strings(4), installPrefix, 8)
)
}).as[OdsInstall]
.write.mode("append")
.partitionBy("dt")
.format("hive")
.saveAsTable(installTableName)
//将已经加载到hive表中的文件移到bak目录下
hdfsFileOpt.bakFile(today, installPath, fileNameList, installPrefix)
}
}
/**
* 实现把安装的hadoop中的row层数据加载到对应的hive的ods表中
*/
def loadActivate(today: String = LocalDate.now().format(DateTimeFormatter.ofPattern("yyyyMMdd"))): Unit = {
val activatePath = odsFilePath.getString("user_activate_path") //ods文件所在的hadoop路径
val activatePrefix = odsFilePrefix.getString("user_activate_file_Prefix") //安装文件的前缀
val activateTableName = odsHiveTableName.getString("ods_app_activate") //安装的ods表名
println(activatePath,activatePrefix,activateTableName)
//读取激活的文件路径+日期目录+前缀下的文件,加载成ds
val activateDs: Dataset[String] = sparkReadHdfsFile.readFilesByPrefix(activatePath + "/" + today, activatePrefix)
if (!activateDs.isEmpty) {
//获取到的文件名清单
val fileNameList = activateDs.map(row => {
row.split("\\|")(3)
}).collect().distinct.toList
// 3. 修复分区元数据(可选,避免Hive看不到新增分区)
spark.conf.set("hive.exec.dynamic.partition", "true")
spark.conf.set("hive.exec.dynamic.partition.mode", "nonstrict")
//解析读取到的ds数据并加载到hive表中
activateDs.map((rows: String) => {
val strings: Array[String] = rows.split("\\|")
OdsActivate(
device_id = strings(0),
app_id = strings(1),
activate_time = dateUtils.strToTimestamp(strings(2)),
file_name = strings(3),
dt = stringUtils.getFiveCharsAfterPrefix(strings(3), activatePrefix, 8)
)
}).as[OdsActivate]
.write.mode("append")
.partitionBy("dt")
.format("hive")
.saveAsTable(activateTableName)
//将已经加载到hive表中的文件移到bak目录下
hdfsFileOpt.bakFile(today, activatePath, fileNameList, activatePrefix)
}
}
/**
* 实现把安装的hadoop中的row层数据加载到对应的hive的ods表中
*/
def loadUnInstall(today: String = LocalDate.now().format(DateTimeFormatter.ofPattern("yyyyMMdd"))): Unit = {
val unInstallPath = odsFilePath.getString("user_uninstall_path") //ods文件所在的hadoop路径
val unInstallPrefix = odsFilePrefix.getString("user_uninstall_file_Prefix") //安装文件的前缀
val unInstallTableName = odsHiveTableName.getString("ods_app_uninstall") //安装的ods表名
//读取卸载的文件路径+日期目录+前缀下的文件,加载成ds
val unInstallDs: Dataset[String] = sparkReadHdfsFile.readFilesByPrefix(unInstallPath + "/" + today, unInstallPrefix)
if (!unInstallDs.isEmpty) {
//获取到的文件名清单
val fileNameList = unInstallDs.map(row => {
row.split("\\|")(3)
}).collect().distinct.toList
// 3. 修复分区元数据(可选,避免Hive看不到新增分区)
spark.conf.set("hive.exec.dynamic.partition", "true")
spark.conf.set("hive.exec.dynamic.partition.mode", "nonstrict")
//解析读取到的ds数据并加载到hive表中
unInstallDs.map((rows: String) => {
val strings: Array[String] = rows.split("\\|")
OdsUninstall(
device_id = strings(0),
app_id = strings(1),
uninstall_time = dateUtils.strToTimestamp(strings(2)),
file_name = strings(3),
dt = stringUtils.getFiveCharsAfterPrefix(strings(3), unInstallPrefix, 8)
)
}).as[OdsUninstall]
.write.mode("append")
.partitionBy("dt")
.format("hive")
.saveAsTable(unInstallTableName)
//将已经加载到hive表中的文件移到bak目录下
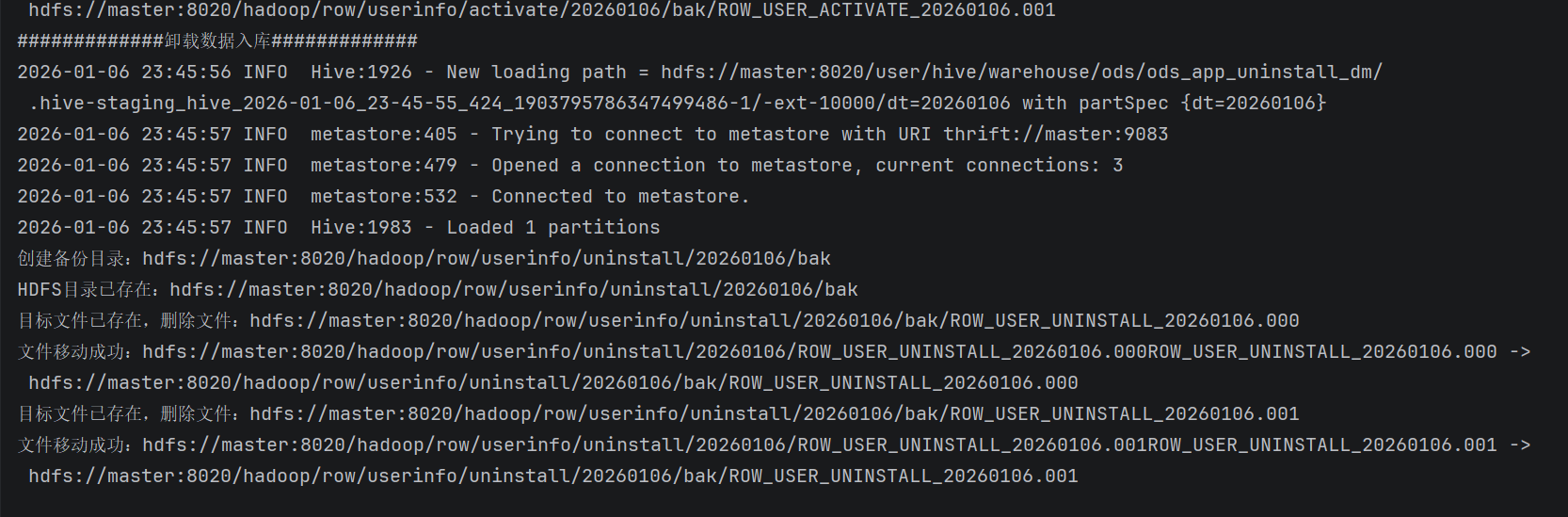
hdfsFileOpt.bakFile(today, unInstallPath, fileNameList, unInstallPrefix)
}
}
}三、公用类补充
1、HdfsFileOpt新增bakFile方法
Scala
/**
* 批量移动文件到指定日期的备份目录
*
* @param srcDir 源文件所在的HDFS目录(如:hdfs://master:8020/hadoop/row/userinfo/install/)
* @param fileNameList 需要备份的文件名列表(如:ROW_USER_INSTALL_20260106.000)
* @param fileNamePrefix 文件前缀(用于提取日期,如:ROW_USER_INSTALL_)
*/
def bakFile(today:String,srcDir: String, fileNameList: List[String], fileNamePrefix: String = ""): Unit = {
var fs: FileSystem = null
try {
// 初始化FileSystem(放在try块内,确保能关闭)
fs = FileSystem.get(new URI(hdfsUri), _conf, hdfsUser)
// 第一步:提取所有唯一日期,创建对应的备份目录
val uniqueDates = fileNameList
.map(fileName => stringUtils.getFiveCharsAfterPrefix(fileName, fileNamePrefix, 8))
.distinct
// 遍历日期创建备份目录(路径:srcDir/date/bak)
uniqueDates.foreach { date =>
val bakDirPath = s"$srcDir/$date/bak"
println(s"创建备份目录:$bakDirPath")
createHdfsDir(bakDirPath, "777")
}
// 第二步:遍历文件列表,逐个移动文件到对应备份目录
fileNameList.foreach { fileName =>
// 提取当前文件的日期
val date = stringUtils.getFiveCharsAfterPrefix(fileName, fileNamePrefix, 8)
// 构建源文件完整路径(srcDir + 文件名)
val srcFilePath = new Path(s"$srcDir/$date", fileName)
// 构建目标文件完整路径(srcDir/date/bak + 文件名)
val targetFilePath = new Path(s"$srcDir/$date/bak", fileName)
// 检查源文件是否存在
if (!fs.exists(srcFilePath)) {
println(s"源文件不存在:${srcFilePath.toString}")
}
// 检查目标文件是否已存在(避免rename异常)
if (fs.exists(targetFilePath)) {
println(s"目标文件已存在,删除文件:${targetFilePath.toString}")
fs.delete(targetFilePath, true) // true表示递归删除(这里是文件,递归无影响)
}
// 执行文件移动(HDFS的rename是原子操作,移动同集群文件性能极高)
val isMoveSuccess = fs.rename(srcFilePath, targetFilePath)
if (isMoveSuccess) {
println(s"文件移动成功:$srcFilePath$fileName -> ${targetFilePath.toString}")
} else {
throw new RuntimeException(s"$fileName 文件移动失败")
}
}
} catch {
case e: Exception =>
println(s"备份文件时发生异常:${e.getMessage}")
e.printStackTrace()
throw e // 抛出异常让上层处理,避免静默失败
} finally {
// 无论是否出错,都关闭FileSystem
if (fs != null) {
try {
fs.close()
} catch {
case e: IOException => println(s"关闭FileSystem失败:${e.getMessage}")
}
}
}
}2、增加Dao层的SparkReadHdfsFile类
用于读取hdfs上的文件
Scala
package com.dw.dao
import com.dw.common.utils.SparkEnvUtil
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.sql.{Dataset, SparkSession}
class SparkReadHdfsFile extends Serializable {
private val spark: SparkSession = SparkEnvUtil.getSession
//private val sc: SparkContext = SparkEnvUtil.getSc
import spark.implicits._
// HDFS文件系统实例
@transient private val hadoopConf: Configuration = spark.sparkContext.hadoopConfiguration
@transient private val fs: FileSystem = FileSystem.get(hadoopConf)
// 读取HDFS无结构文本文件(核心:先读为Dataset[String],后续结构化)
/**
* 读取HDFS目录下,以指定前缀开头的文件
*
* @param hdfsDir HDFS目标目录
* @param fileNamePrefix 文件名前缀(如"user_log_")默认为空
* @return 匹配文件的内容(Dataset[String])
*/
def readFilesByPrefix(hdfsDir: String, fileNamePrefix: String = ""): Dataset[String] = {
//校验目录合法性
val dirPath = new Path(hdfsDir)
if (!fs.exists(dirPath)) {
throw new RuntimeException(s"HDFS目录不存在或非法:$hdfsDir")
}
//列出目录下所有文件,过滤"前缀匹配"的文件
val matchedFiles: Array[String] = fs.listStatus(dirPath)
.filter(_.isFile) // 只处理文件(跳过子目录)
.map(_.getPath.getName) // 获取文件名
.filter(_.startsWith(fileNamePrefix)) // 前缀匹配
.map(fileName => s"$hdfsDir/$fileName") // 拼接完整HDFS路径
//校验匹配结果
if (matchedFiles.isEmpty) {
println(s"HDFS目录[$hdfsDir]下无匹配前缀[$fileNamePrefix]的文件!")
}
//读取匹配文件的内容
spark.read.textFile(matchedFiles: _*)
.filter(_.nonEmpty) // 过滤空行
}
// 关闭HDFS资源
def close(): Unit = {
if (fs != null) fs.close()
}
}3、增加字符工具类StringUtils
Scala
package com.dw.util
class StringUtils extends Serializable {
/**
* 去掉字符串特定前缀,截取后面的5位字符
* @param str 原始字符串
* @param prefix 要去除的前缀
* @return 去除前缀后截取的5位字符(不足5位返回剩余全部)
*/
def getFiveCharsAfterPrefix(str: String, prefix: String,number:Int): String = {
// 1. 校验字符串和前缀合法性
if (str == null || prefix == null || !str.startsWith(prefix)) {
throw new IllegalArgumentException(s"字符串[$str]不以前缀[$prefix]开头!")
}
// 2. 去掉前缀
val strWithoutPrefix = str.substring(prefix.length)
// 3. 截取后number位(不足number位返回全部)
strWithoutPrefix.take(number)
}
}4、更新日期工具类DateUtils的strToTimestamp方法
Scala
/**
* String转Timestamp
*
* @param timeStr 时间字符串
* @param format 时间格式(默认yyyy-MM-dd HH:mm:ss)
* @return 可选的Timestamp(避免空指针)
*/
def strToTimestamp(timeStr: String, format: String = DEFAULT_FORMAT): Timestamp = {
val formatter = DateTimeFormatter.ofPattern(format)
val localDateTime = LocalDateTime.parse(timeStr, formatter)
Timestamp.valueOf(localDateTime)
}四、遇到的问题
1、目录没有权限

我直接用最暴力的方法赋权,正式点的环境应该用到将用户添加到目标组
hdfs dfs -chmod 777 /user/hive/warehouse/ods/ods_app_activate_dm
其他报错同理
2、序列化问题
第一种核心问题是 Spark 任务序列化失败
根源是自己写的LoadRowToOds类没有实现Serializable接口,但在分布式计算的闭包中引用了该类的实例,导致 Spark 无法将其序列化并分发到 Executor 节点
解决方案是在类定义处添加extends Serializable,这是解决 Spark 序列化问题的通用方案
第二种是引用的类不支持序列化
从报错日志的核心信息 java.io.NotSerializableException: java.time.format.DateTimeFormatter 能明确:
DateUtils类中定义了DEFAULT_FORMATTER(DateTimeFormatter类型)作为成员变量;
LoadRowToOds类依赖DateUtils实例,而map算子闭包中隐式引用了这个DateUtils实例;
Spark 序列化闭包时,会尝试序列化所有引用的对象,但DateTimeFormatter无法序列化,最终导致任务失败。
解决方案:
将DateTimeFormatter定义为局部变量(推荐,最优雅)
在map算子内部重新创建DateTimeFormatter,避免引用类成员的不可序列化对象
Scala
// 核心修改:添加transient关键字,避免序列化@transient
privatevar _defaultFormatter: DateTimeFormatter = _要保证闭包中无任何不可序列化的类成员引用(包括DateUtils、stringUtils等工具类,若需引用需确保工具类要么实现序列化,要么仅引用其静态方法)
还有案例就是hadoop的fs成员变量无法序列化
SparkReadHdfsFile类定义了fs(FileSystem类型)成员变量,而FileSystem的实现类DistributedFileSystem是 Hadoop 的核心类,既不实现Serializable,也不能跨节点传输;
LoadRowToOds类持有SparkReadHdfsFile实例,且map/filter等算子闭包隐式引用了LoadRowToOds的this对象(包含SparkReadHdfsFile);
Spark 序列化闭包时,会递归序列化所有引用的对象,DistributedFileSystem无法序列化,导致任务失败
解决方案:重构SparkReadHdfsFile(推荐,一劳永逸)
修改SparkReadHdfsFile,将FileSystem和Configuration都标记为transient,并通过静态方法 + 懒加载在每个 Executor 节点重新创建,且不在类级别持有这些对象
以上解决方案来源于豆包,还需要加强对scala的闭包的理解,理论知识还需加强
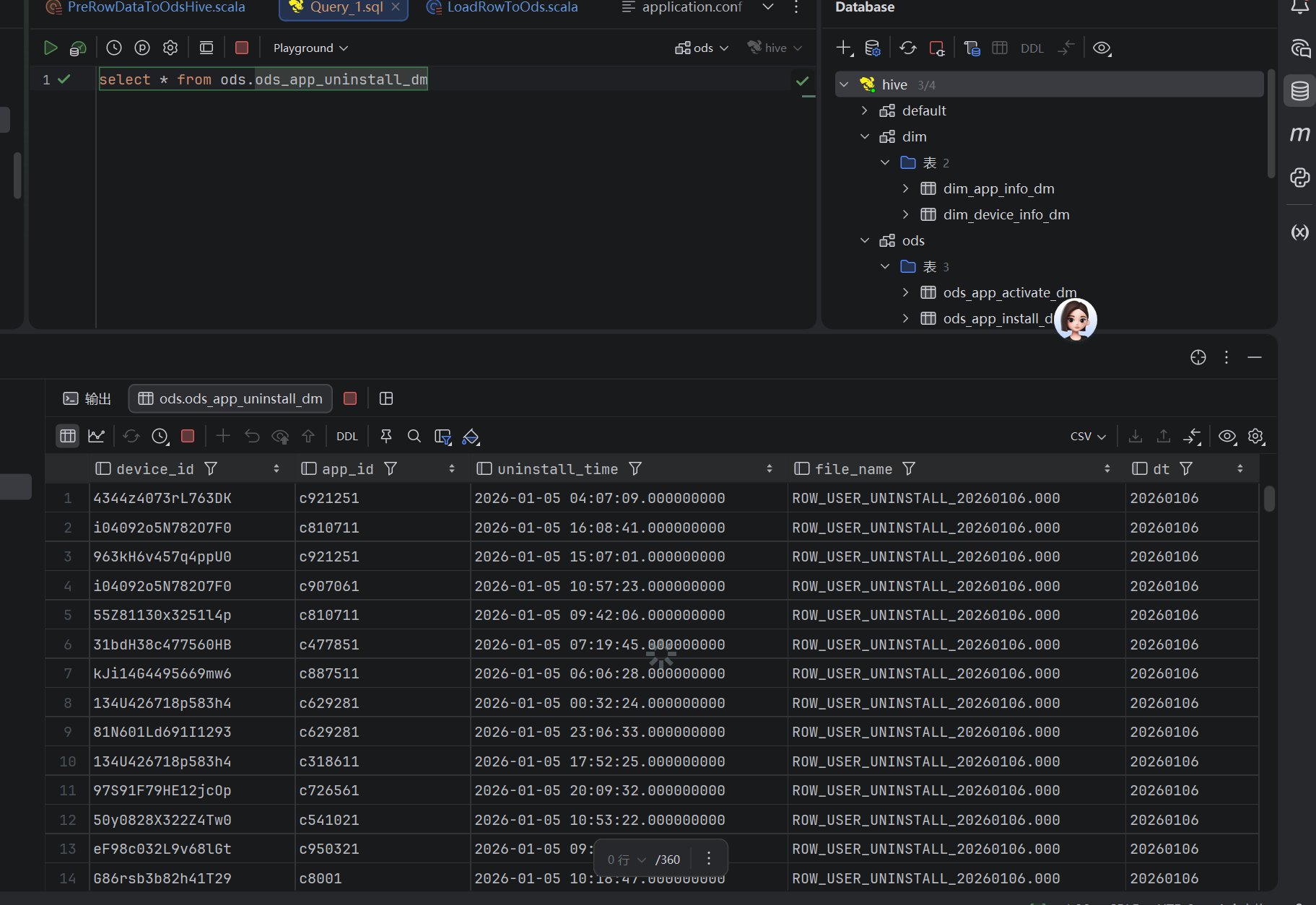
五、结果展示