文章目录
- 1、基本介绍
- 2、池化层计算
- [3、Padding(填充)- 用得少](#3、Padding(填充)- 用得少)
- 4、Stride(步长)
- 5、多通道池化计算
- [6、池化层 - API](#6、池化层 - API)
- 7、代码:特征图后加池化层
1、基本介绍
一、"池化"这个名字是怎么来的?
🌊 字面意思:像"水池"一样汇聚
- "池" = pool (英文原名就是 pooling)
- 想象一个网格状的水池,每个小格子代表输入的一个局部区域。
- "池化"就是把每个小格子里的水(数值)汇聚(aggregate) 起来,变成一滴更浓缩的水(输出值)。
✅ 所以,"池化" = 局部区域的信息聚合,就像把多个像素"汇入一个池子",提炼出最有代表性的信息。
二、池化层是干什么的?(技术原理)
🎯 核心目的:
- 降维(Downsampling):减小特征图的空间尺寸(H, W),降低计算量。
- 增强平移不变性(Translation Invariance):即使目标在图像中轻微移动,池化后的结果变化不大。
- 防止过拟合:丢弃部分细节,保留主要结构。
三、最常见的池化操作
- 最大池化(Max Pooling)
- 在每个滑动窗口内,取最大值作为输出。
- 保留最显著的特征(如最强的边缘响应)。
python
import torch
import torch.nn as nn
x = torch.tensor([[[[1, 2, 3, 4],
[5, 6, 7, 8],
[9,10,11,12],
[13,14,15,16]]]], dtype=torch.float32) # (1,1,4,4)
max_pool = nn.MaxPool2d(kernel_size=2, stride=2)
out = max_pool(x)
print(out)
# 输出:
# tensor([[[[ 6., 8.],
# [14., 16.]]]])- 平均池化(Average Pooling)
- 在窗口内取平均值。
- 更平滑,适合去噪或保留整体趋势。
python
avg_pool = nn.AvgPool2d(kernel_size=2, stride=2)
out = avg_pool(x)
print(out)
# 输出:
# tensor([[[[ 3.5, 5.5],
# [11.5, 13.5]]]])四、池化层的关键参数(以 nn.MaxPool2d 为例)
python
nn.MaxPool2d(
kernel_size=2, # 池化窗口大小(如2×2)
stride=None, # 步长,默认等于 kernel_size(即不重叠)
padding=0, # 输入填充(较少用)
dilation=1, # 空洞池化(几乎不用)
ceil_mode=False # 是否向上取整输出尺寸
)🔍 注意:池化层没有可学习参数!它是一个固定的、确定性的操作。
五、为什么叫"池化"而不是"下采样"?
- "下采样(Downsampling)"是功能描述(尺寸变小了)。
- "池化(Pooling)"是操作方式描述(在一个"池子"里聚合信息)。
- 英文中 "to pool" 有"汇集资源"的意思,非常贴切!
💬 类比:
卷积 = 用滤镜扫描图像提取特征
池化 = 把扫描结果"压缩打包",只留精华
六、池化 vs 卷积降维
| 方法 | 是否有参数 | 是否可学习 | 主要作用 |
|---|---|---|---|
| 卷积(stride>1) | 有 | 是 | 提取特征 + 降维 |
| 池化 | 无 | 否 | 仅降维 + 增强鲁棒性 |
📌 现代网络(如 ResNet)有时会用 stride=2 的卷积 替代池化,因为可学习的降维可能更优。但池化仍广泛用于简单、高效的架构中(如 LeNet、早期 CNN)。
七、形象比喻 🌟
想象你在看一幅马赛克壁画:
- 原始图像:由成千上万个彩色小瓷砖组成。
- 卷积层:用不同颜色的"探测器"找出哪些区域有红色火焰、蓝色海水......
- 池化层 :你后退几步,每 2×2 块瓷砖只记住最亮的那一块(最大池化)------这样你看到的仍是主要图案,但细节少了,画面也变小了。
这就是"池化":站在更高处,抓住重点,忽略琐碎。
✅ 总结
| 问题 | 回答 |
|---|---|
| 名字来源? | 来自英文 "pooling"(汇聚),像把数据"汇入池子"再提炼 |
| 作用是什么? | 降维、增强平移不变性、防过拟合 |
| 有参数吗? | ❌ 没有!是固定操作 |
| 常用类型? | 最大池化(主流)、平均池化 |
| 必须用吗? | 不必须,但传统 CNN 中非常常见 |
2、池化层计算
-
最大池化(Max Pooling) :通过池化窗口进行最大池化,取窗口中的最大值作为输出

-
平均池化(Avg Pooling) :取窗口内的所有值的均值作为输出
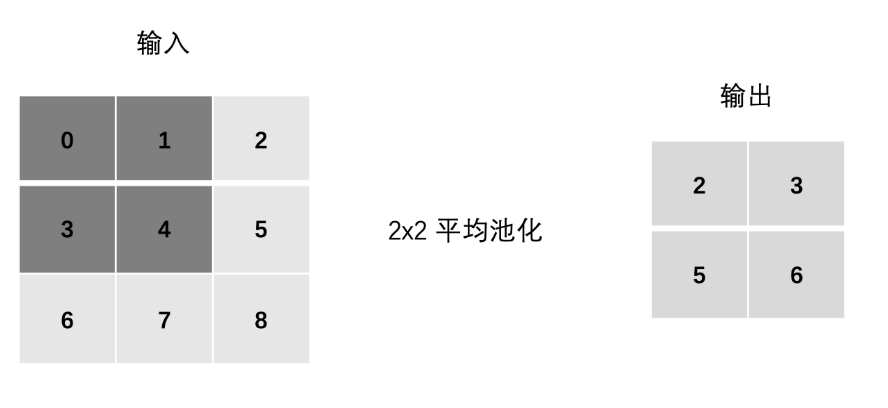
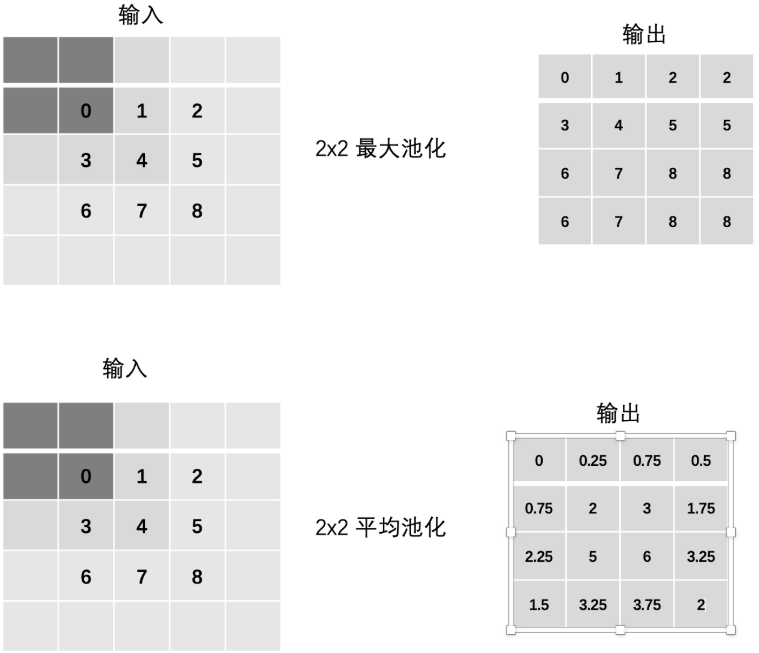
3、Padding(填充)- 用得少
用得少,本来目的就是降维,再填充就又回去了
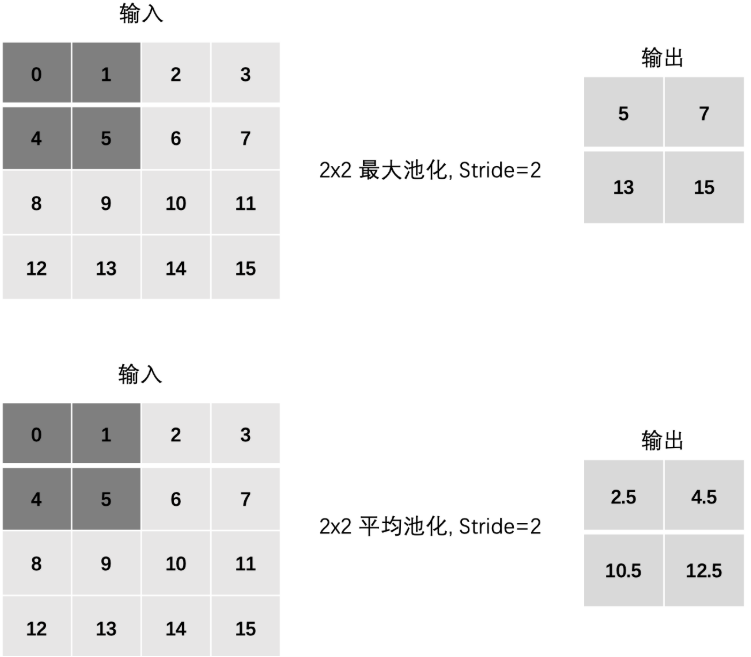
4、Stride(步长)
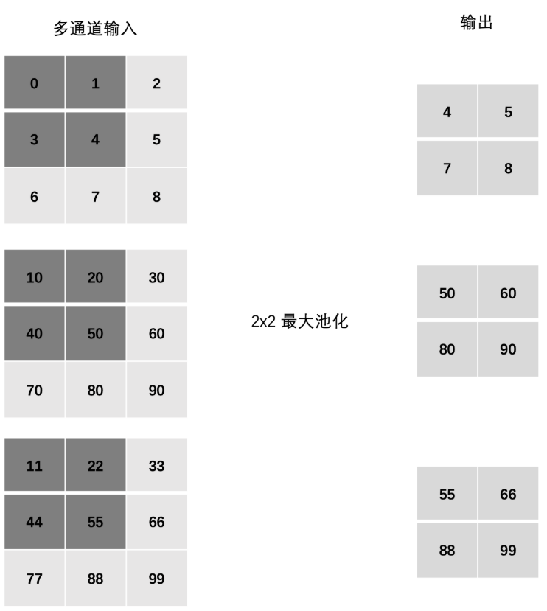
5、多通道池化计算
在处理多通道输入数据时,池化层对每个输入通道分别池化,而不是像卷积层那样将各个通道的输入相加。这意味着池化层的输出和输入的通道数是相等。
池化只在宽高维度上池化 ,在通道上是不发生池化(池化前后,多少个通道还是多少个通道)
6、池化层 - API
🧩 一、池化层的作用(简要回顾)
- 降维(Downsampling):减小特征图空间尺寸(H, W 或 L / D,H,W),降低计算量。
- 增强平移不变性:目标轻微移动时,池化结果变化不大。
- 保留显著特征 (MaxPool)或 平滑响应(AvgPool)。
- 无学习参数:纯确定性操作,不可训练。
📚 二、PyTorch 池化层 API 总览
| 维度 | 最大池化 | 平均池化 |
|---|---|---|
| 一维 | nn.MaxPool1d |
nn.AvgPool1d |
| 二维 | nn.MaxPool2d |
nn.AvgPool2d |
| 三维 | nn.MaxPool3d |
nn.AvgPool3d |
✅ 所有池化层都继承自
torch.nn.Module,用法一致。
🔍 三、以 nn.MaxPool2d 为例详解(最常用)
📥 构造函数
python
torch.nn.MaxPool2d(
kernel_size, # 必填:池化窗口大小
stride=None, # 步长,默认 = kernel_size
padding=0, # 输入边界补零(慎用)
dilation=1, # 空洞(MaxPool2d 实际不支持 >1)
ceil_mode=False # 是否向上取整输出尺寸
)📐 输入张量形状
(N, C, H_in, W_in)N: batch sizeC: 通道数(每个通道独立池化)H_in,W_in: 高、宽
📤 输出张量形状
(N, C, H_out, W_out)其中:
H out = ⌊ H in + 2 × padding − kernel_size stride ⌋ + 1 H_{\text{out}} = \left\lfloor \frac{H_{\text{in}} + 2 \times \text{padding} - \text{kernel\_size}}{\text{stride}} \right\rfloor + 1 Hout=⌊strideHin+2×padding−kernel_size⌋+1
若 ceil_mode=True,则使用 ceil() 向上取整。
✅ 通道数 C 保持不变!
⚙️ 四、参数详解(适用于所有 Pooling 层)
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
kernel_size |
int / tuple | --- | 池化窗口大小 • 2 → (2,2) • (2,3) → 高2宽3 |
stride |
int / tuple | = kernel_size |
滑动步长 • stride=1 → 重叠池化 • stride=2 → 非重叠(常用) |
padding |
int / tuple | 0 |
输入四周补零 ⚠️ MaxPool 补零可能引入虚假 0 值,慎用! |
dilation |
int | 1 |
元素间距(空洞) ❌ MaxPool2d/AvgPool2d 不支持 dilation > 1 |
ceil_mode |
bool | False |
若为 True,输出尺寸向上取整 避免因整除丢掉边缘信息 |
🖼️ 五、输入 → 输出 示例
✅ 示例 1:标准 MaxPool2d
python
import torch
import torch.nn as nn
x = torch.randn(1, 3, 4, 4) # (N=1, C=3, H=4, W=4)
pool = nn.MaxPool2d(kernel_size=2, stride=2)
y = pool(x)
print(y.shape) # torch.Size([1, 3, 2, 2])✅ 示例 2:使用 ceil_mode
python
x = torch.randn(1, 1, 5, 5)
pool1 = nn.MaxPool2d(2, stride=2, ceil_mode=False) # → (1,1,2,2)
pool2 = nn.MaxPool2d(2, stride=2, ceil_mode=True) # → (1,1,3,3)✅ 示例 3:全局平均池化(常用于分类头)
python
gap = nn.AdaptiveAvgPool2d((1, 1)) # 自适应输出 1×1
x = torch.randn(1, 512, 7, 7)
out = gap(x) # (1, 512, 1, 1)⚠️ 六、关键注意事项(避坑指南)
- 通道独立处理
- 池化在每个通道内单独进行,不会跨通道融合信息(与卷积不同)。
- 输出通道数 = 输入通道数。
padding在 MaxPool 中风险高
- 补零后,窗口可能包含 0,导致最大值被错误抑制。
- 一般只在特殊结构(如全卷积网络)中使用。
dilation几乎无效
- PyTorch 的
MaxPool2d和AvgPool2d不支持dilation > 1(会报错或忽略)。 - 如需空洞感受野,请用 空洞卷积(
dilated convolution)。
ceil_mode=True可防止信息丢失
- 当
(H_in - kernel) % stride != 0时,最后一行/列会被丢弃。 - 设
ceil_mode=True可通过虚拟 padding 保留它。
- MaxPool vs AvgPool 使用场景
| 类型 | 特点 | 适用场景 |
|---|---|---|
MaxPool |
保留最强响应 | 边缘、纹理、显著特征提取(主流) |
AvgPool |
平滑、去噪 | 全局信息聚合、分类前压缩(如 GAP) |
- 现代 CNN 趋势:用卷积代替池化
- ResNet、EfficientNet 等常使用
stride=2的卷积 替代池化,因为:- 可学习的降维更灵活
- 保留更多信息
- 但池化仍广泛用于简单、高效模型(如 LeNet、小型 CNN)。
📏 七、1D / 3D 池化对比
| 类型 | 输入形状 | 输出形状 | 典型应用 |
|---|---|---|---|
MaxPool1d |
(N, C, L) |
(N, C, L_out) |
语音信号、时间序列、文本嵌入 |
MaxPool3d |
(N, C, D, H, W) |
(N, C, D_out, H_out, W_out) |
视频(帧+高+宽)、医学 CT/MRI 体数据 |
参数含义完全一致,只是维度扩展。
✅ 八、总结速查表
| 项目 | 说明 |
|---|---|
| 是否有可学习参数? | ❌ 无(weight / bias 不存在) |
| 通道数是否变化? | ❌ 保持不变 |
| 作用维度? | 仅空间维度(L / H,W / D,H,W) |
| 最常用配置? | kernel_size=2, stride=2 |
| 典型位置? | 卷积 + ReLU 之后 |
| 可视化效果? | MaxPool 后特征更稀疏、边缘更突出 |
| 替代方案? | Conv2d(..., stride=2) |
💡 九、推荐实践代码模板
python
# 标准 CNN 块(含池化)
block = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2) # 尺寸减半
)
x = torch.randn(1, 3, 32, 32)
out = block(x)
print(out.shape) # torch.Size([1, 64, 16, 16])7、代码:特征图后加池化层
python
import torch
import torch.nn as nn
torch.manual_seed(66)
# 假设已经得到特征图
x = torch.randn(size=(1, 3, 2, 4)) # (N=1, C=3, H=2, W=4)
print(f'x.shape = {x.shape}') # torch.Size([1, 3, 4, 4])
# print(x)
# tensor([[[[ 0.2142, -0.1434, -0.2636, 1.2033],
# [ 1.0941, 0.7960, 0.0044, -1.5482]],
#
# [[-0.3422, 0.8648, 0.2224, -1.1033],
# [ 1.1821, 1.4265, -0.3477, -0.5355]],
#
# [[-1.0420, 1.3591, 0.0154, 1.3389],
# [ 0.5368, 1.6555, 0.7570, 0.1617]]]])
pool = nn.MaxPool2d(kernel_size=(2, 2), stride=1, padding=0)
output = pool(x)
print(f'output.shape = {output.shape}') # torch.Size([1, 3, 2, 4])
print(output)
# tensor([[[[1.0941, 0.7960, 1.2033]],
#
# [[1.4265, 1.4265, 0.2224]],
#
# [[1.6555, 1.6555, 1.3389]]]])