论文名:"YOLOE: Real-Time Seeing Anything"
发布单位:清华大学
发布时间:2025.3
主要贡献:
-
**文本提示:**提出可重参数化区域 - 文本对齐(RepRTA)策略,通过轻量级辅助网络优化预训练文本嵌入,以零推理和迁移开销增强视觉 - 文本对齐。
-
**视觉提示:**设计语义激活视觉提示编码器(SAVPE),通过解耦的语义分支与激活分支,以最小复杂度提升视觉嵌入与准确性。
-
**对于无提示场景:**引入懒区域 - 提示对比(LRPC)策略,利用内置的大型词汇表和专用嵌入识别所有对象,避免对昂贵语言模型的依赖
结果:
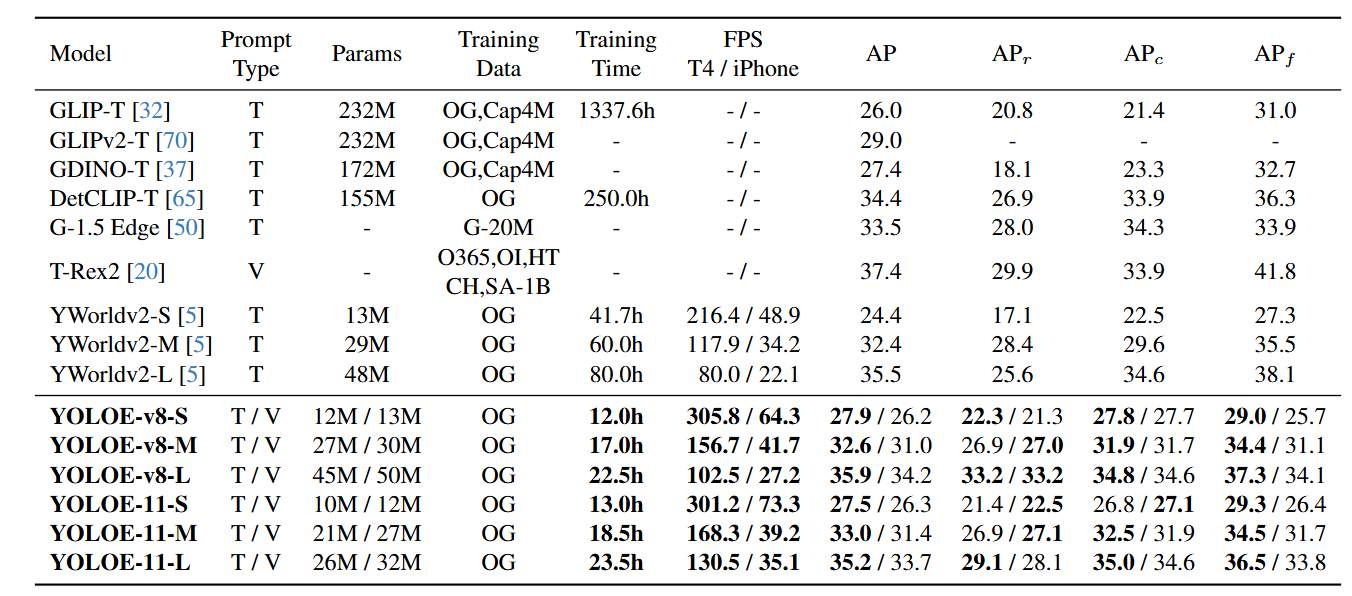
YOLOE 具有卓越的零样本性能、迁移能力和高效推理,同时训练成本低。在 LVIS 数据集上,YOLOE-v8-S 的训练成本比 YOLO-Worldv2-S 低 3 倍,推理速度提升 1.4 倍,平均精度(AP)高出 3.5。当迁移到 COCO 数据集时,YOLOE-v8-L 相比封闭集的 YOLOv8-L,在训练时间减少近 4 倍的情况下,边界框平均精度AP(Box)和掩码平均精度AP(Mask)分别提升 0.6 和 0.4
引言:
传统的方法依赖预定义物体类别,这样限制了实际开放场景中的灵活性。近年有很多工作都转向模型能够对开放提示进行泛化,这些方法要么针对单一提示类型(GLIP),或者多种提示类型使用统一的方式进行处理(DINO-X),除了 DINO-X 之外,很少有研究能在单一架构中实现跨多种开放提示机制的目标检测与分割。然而,DINO-X 需要大量的训练成本和显著的推理开销。文本提示方法在纳入大型词汇表时,由于跨模态融合的复杂性,通常会产生大量计算开销。视觉提示方法则因基于 Transformer 的设计或依赖额外的视觉编码器,往往不具备在边缘设备上的部署能力。
方法:
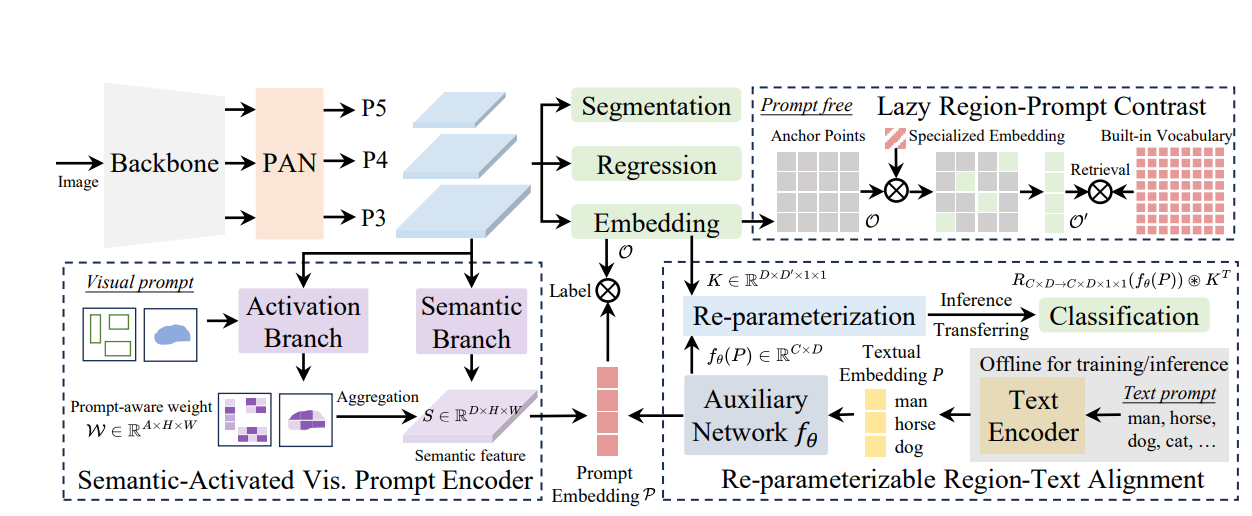
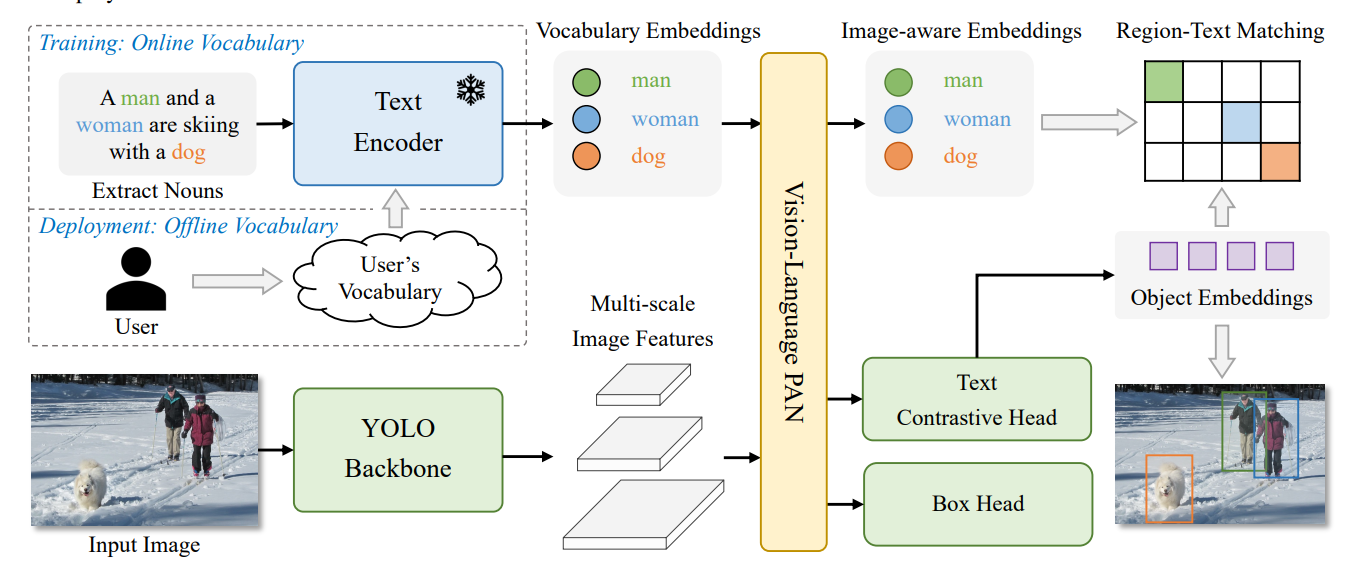
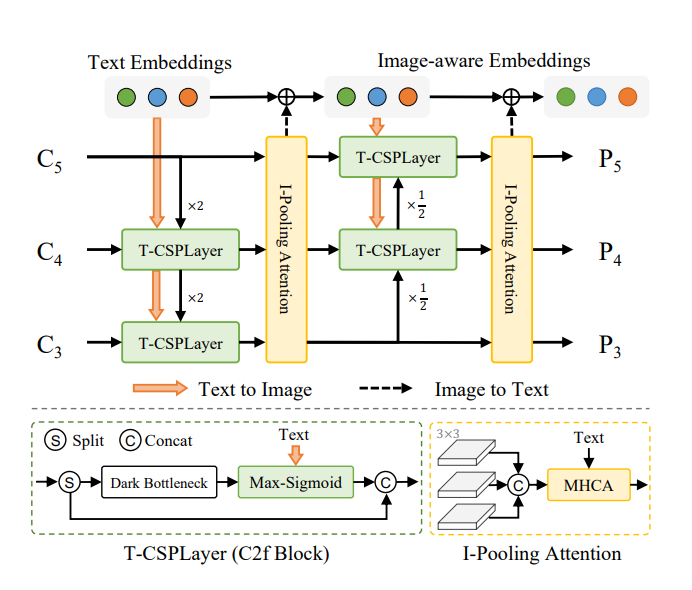
模型结构方面使用经典的模型结构包括主干网络、PAN颈部以及回归头(regression)、分割头(segmentation)、对象嵌入头(Embedding),其中对象嵌入头使用YOLO系列分类头结构,在最后一个 1×1 卷积 层的输出通道数从封闭集场景下的类别数改为嵌入 维度:
对于封闭集而言(也就是我们现在常用的一个标签对应一个类别),它的输出通道为固定类别数,分类头会直接预测固定类别的概率,如使用Softmax。这样则无法处理应对这种开集检测。所以改为嵌入维度D(如256维)。
其中O(Object Embeddings):锚点的对象嵌入矩阵,形状为N×D,其中N为锚点总数(N=H×W,H/W为特征图尺寸),D为则为每个锚点的嵌入的特征向量。P(Prompt Embeddings):提示嵌入矩阵,形状为C×D,其中C为提示的数量,D为提示的嵌入维度。通过矩阵乘法获得最终的LabelN,C,表示第N个锚点与第C个提示的匹配分数。
文本提示:
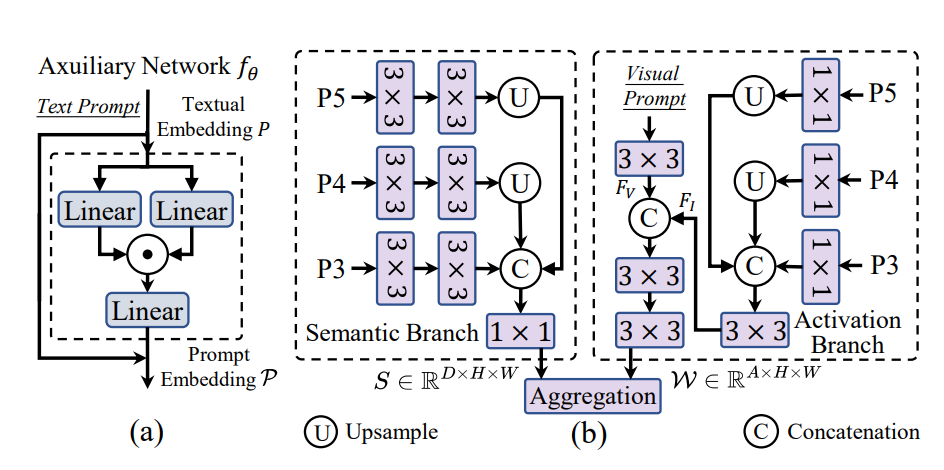
可重参数化区域 - 文本对齐(RepRTA)策略,该策略通过可重参数化的轻量级辅助网络在训练过程中优化预训练文本嵌入,首先对于输入的文本进行预处理,使用CLIP生成预训练的嵌入P,关键优化在于训练前预先计算并缓存所有训练数据中出现的文本嵌入,训练时直接加载缓存,移除CLIP(节省计算资源)
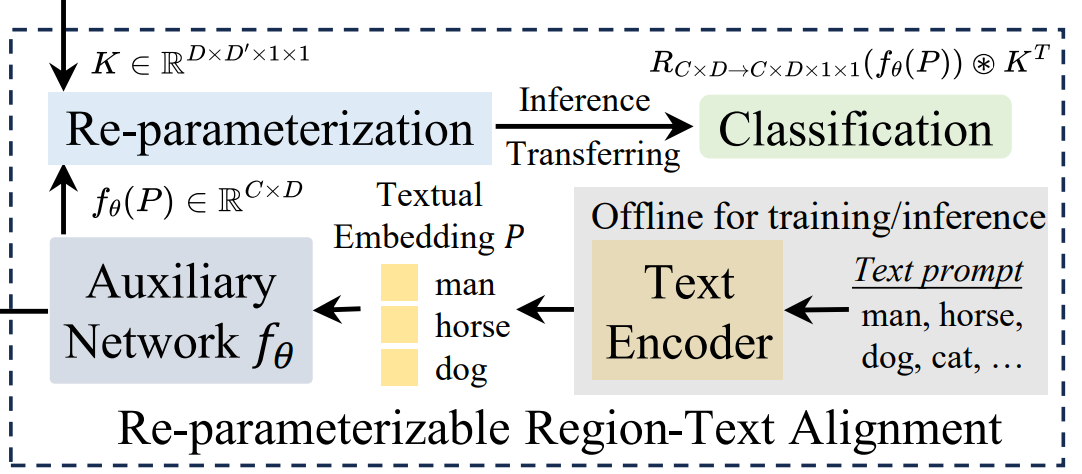
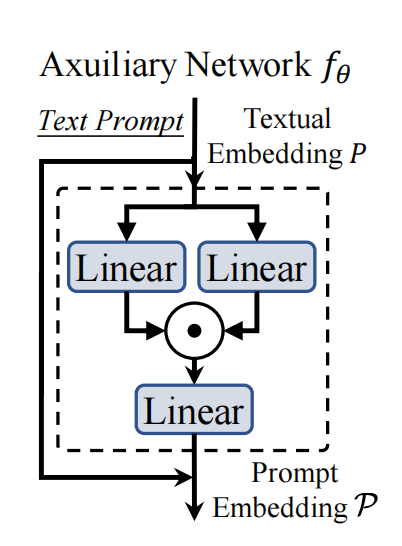
预训练生成的嵌入向量P,通过轻量级辅助网络生成最终的嵌入向量P,轻量级辅助网络由一个前馈网络块构成。
训练阶段使用辅助网络优化文本嵌入,推理阶段辅助网络输出的嵌入特征P(C×D)与最后一层卷积核K(D×D'×1×1)融合生成新的卷积核K',公式如下:
获得新卷积核后与输出特征I(D'×H×W)进行卷积操作即可获得最终的输出label,公式如下:
视觉提示:
语义视觉提示编码器(SAVPE),具有两个解耦的轻量级分支,(1)语义分支,(2)激活分支。
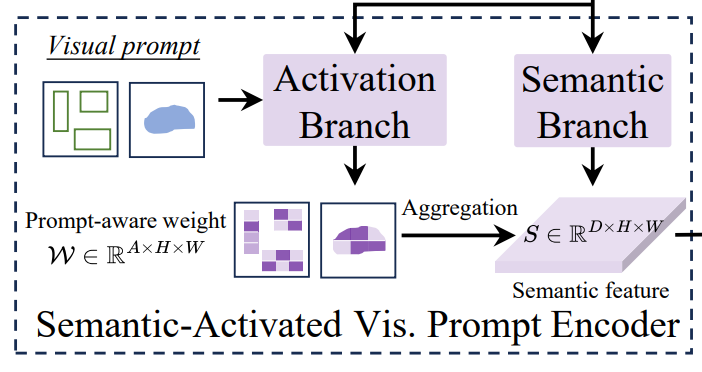
对于Semantic Branch(语义分支),使用来自特征金字塔的三层特征{P5,P4, P3},对每个尺度的特征分别使用两个3×3卷积进行处理(目的是通过卷积提取不同尺度的特征),最后对这些特征进行上采用并融合在一起,通过1×1卷积进行映射获得通用的语义特征S(D×H×W)。
对于Actication Branch(激活分支),将视觉提示化为一个掩码,在指定的目标区域值设为 1,其他区域设为 0,通过这种方式突出视觉提示所关注的区域,利用3×3卷积来提取提示特征Fv(A×H×W),同样激活分支也需要特征金字塔的三层特征,通过卷积与采样生成FI(A×H×W),将Fv与Fi拼接,也就是将视觉提示信息和图像本身特征结合,最终获得感知权重W(A×H×W),其中A为人为设定(论文默认16)。
获得语义特征S与感知权重W后,需要将两者进行融合,该融合使用通道分组来进行低维处理,将语义特征S的通道划分为A组,每组包含D/A个通道,第i组的通道共享来自感知权重W第i个通道的权重Wi:i+1。公式如下:
无提示:
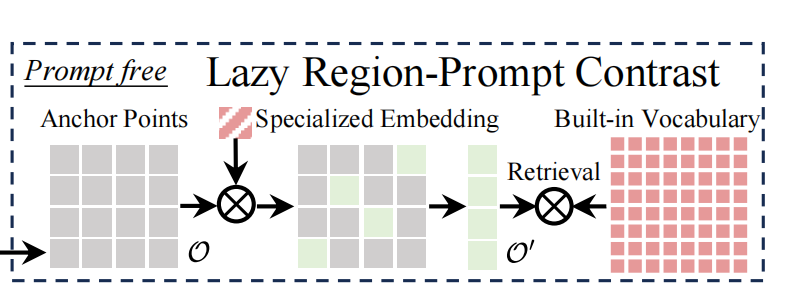
无提示则利用语言模型为密集检测到的物体生成类别。这将带来显著的计算开销,GenerateU中使用的拥有 2.5 亿参数的FlanT5-base,以及在 DINO-X中使用的 OPT-125M 等语言模型,远远无法满足高效性要求。YOLOE提出懒惰性区域提示对比策略(LRPC)。
-
专门提示嵌入训练:基于已经预训练好的 YOLOE 模型,引入了一种专门的提示嵌入。这个嵌入是经过特殊训练的,在训练过程中,把所有要识别的物体都当作一个类别来处理。让这个提示嵌入具备发现图像中所有物体的能力,它可以作为一个 "探测器",初步判断图像中哪些位置可能存在物体。
-
大型词汇表收集:收集了一个包含各种各样类别的大型词汇表。这个词汇表会作为模型内置的检索数据源,为后续识别物体的具体类别提供依据。
对于传统方法,直接把大型词汇表作为文本提示输入到模型中,在识别过程中,需要将大量的锚点的对象嵌入和词汇表中众多的文本嵌入进行对比。LRPC策略优化进行锚点筛选,采用专门的提示嵌入Ps,通过公式:
筛选出与物体对应的锚点集合,其中o代表所有锚点,计算每个锚点的对象嵌入与提示嵌入的相似度。设定一个超参数,只有大于阈值,对应的锚点才会被选入集合,这样排除大量不相关的锚点。之所以叫"惰性",就是因为避免了大量无关锚点,减少了计算成本。
对比YOLO-world:
实验
数据:
使用检测和定位数据集,包括 Objects365(V1)、GoldG(包含 GQA 和 Flickr30k ),其中不包含来自 COCO 的图像。使用的 SAM - 2.1 模型,借助检测和定位数据集中的真实边界框生成伪实例掩码,作为分割数据。在无提示任务中,使用相同的数据集,将所有对象标注为单一类别,以学习专门的提示嵌入。
在LVIS数据集上的Zero-shot评估结果: