切换到 GPU 模式
在使用 vLLM 时,确保模型运行在 GPU 上以获得最佳性能。以下是如何切换到 GPU 模式
完成后,vLLM 将在 GPU 上运行,从而显著提升推理速度。
从WORKSPACE进入到 vLLM 目录下
cd vLLM

那我们准备开始安装和配置 vLLM 啦!!!
1. 安装必要的依赖(已配置成功)
vllm官方文档:Engine Arguments --- vLLM:https://docs.vllm.ai/en/latest/models/engine_args.html
后续操作所需依赖已提前完成安装配置,无需重复安装即可直接使用!
pip install qwen-vl-utils transformers accelerate torchvision requests modelscope # vllm版本是0.6.3,之前使用0.6.2会报keyerror的错误,如果出现了这个错误,可以提高vllm的版本 pip install --upgrade vllm
以下是对这些模块的详细解释:
| 模块名 | 说明 |
|---|---|
qwen-vl-utils |
通常是和通义千问视觉语言模型(Qwen-VL)相关的工具集。Qwen-VL 是能够处理图像和文本输入的多模态大模型。qwen-vl-utils 模块可能包含了对 Qwen-VL 模型进行调用、数据预处理、结果后处理等功能的工具函数和类,可帮助开发者更便捷地使用该模型开展多模态任务,像图像描述生成、视觉问答等。 |
transformers |
由 Hugging Face 开发的一个强大的 Python 库,它为自然语言处理(NLP)领域提供了大量预训练的 Transformer 模型,例如 BERT、GPT - 2、XLNet 等。借助 transformers,你能够轻松加载这些预训练模型,对其进行微调以适应特定的任务,如文本分类、命名实体识别、机器翻译等。该库还提供了统一的接口,使得不同模型的使用方式具有一致性,极大地简化了 NLP 模型的开发流程。 |
accelerate |
Hugging Face 开发的库,其主要作用是帮助用户在多 GPU、TPU 等不同硬件环境下高效地运行和训练深度学习模型。它提供了一系列工具和方法,能够自动处理模型并行、数据并行等复杂的分布式训练配置,让开发者可以专注于模型的设计和训练逻辑,而无需深入了解底层的分布式训练细节。 |
vllm |
一个用于高效推理大语言模型的库。它采用了先进的技术,如 PagedAttention 算法,能显著提升大语言模型的推理速度,减少内存占用。在实际应用中,使用 vllm 可以更快速地获取大语言模型的输出结果,提高系统的响应性能。你提到使用 0.6.2 版本会报 KeyError 错误,升级到 0.6.3 版本可能会修复这个问题,这通常是因为新版本修复了旧版本存在的一些 bug。 |
torchvision |
PyTorch 的一个扩展库,主要用于计算机视觉任务。它包含了常用的数据集(如 MNIST、CIFAR - 10 等)、预训练的模型(如 ResNet、VGG 等)以及图像变换工具。torchvision 使得开发者可以方便地加载和处理图像数据,构建和训练计算机视觉模型,例如图像分类、目标检测、语义分割等。 |
requests |
一个简单易用的 HTTP 库,用于发送 HTTP 请求。在 Python 中,它是处理网络请求的首选库。借助 requests,你可以轻松地发送 GET、POST 等各种类型的 HTTP 请求,获取网页内容、与 API 进行交互等。它简化了网络请求的过程,提供了清晰的 API 接口,使得开发者能够更高效地进行网络编程。 |
modelscope |
阿里云推出的一个开源的模型即服务平台,它提供了一系列丰富的预训练模型,涵盖计算机视觉、自然语言处理、语音处理等众多领域。借助 modelscope,你可以轻松地使用这些预训练模型来完成各种任务,而无需从头开始训练模型。例如,利用它可以进行图像生成、文本生成、目标检测等任务。使用 modelscope 能显著节省开发时间和计算资源,并且可以方便地对模型进行评估和部署。 |
2. 下载相关模型
可以查看modlescope选择自己需要的模型,放在vLLM文件夹下的download_model.py文件中
这里已经下载了Qwen2.5-1.5B-Instruct模型和Qwen2.5-1.5B模型。在vLLM/Quwen文件夹中
python download_model.py
3. 使用原生进行推理
打开vLLM目录下的Codes目录下的LLm_chat.py文件。
一定要记得修改自己下载的本地模型地址!!!

cd /workspace/vLLM/Codes && python LLm_chat.py
测试一下

4. 使用vllm进行推理
PS:这个时候可能进行推理GPU可能会不够,因为我们上面运行了一个
py文件推理的,所以这个时候我们需要查看一下进程
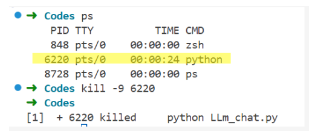
使用命令ps查看所有进程后,找到无关的PID,然后使用kill -9 PID杀死它,然后再运行步骤4即可!
比如我这里的是ID=6220,所以kill -9 6220,那么这个时候再看GPU会发现没有进程运行了。再继续下面的操作!
使用vllm进行推理qwen/Qwen-1_8B-Chat(LLm_sh.sh)
打开vLLM目录下的Codes目录下的LLm_sh.sh文件。
一定要记得修改自己下载的本地模型地址!!!

cd /workspace/vLLM/Codes && sh LLm_sh.sh
LLm_sh.sh文件内容如下:
# LLm serve 本地模型路径 vllm serve /workspace/vLLM/Qwen/Qwen2.5-1.5B-Instruct \ --dtype=half \ --port=8001 \ --trust-remote-code \ --chat-template /workspace/vLLM/Qwen/Qwen2.5-1.5B-Instruct/tokenizer_config.json \ --max-num-seqs 16 \ --gpu-memory-utilization 0.85 \ --enforce-eager \ --swap-space 4 参数解释: 1. vllm serve - 启动vLLM的推理服务 2. /workspace/vLLM/Qwen/Qwen2.5-1.5B-Instruct- 指定要加载的模型路径 3. --dtype=half - 使用半精度(FP16)加载模型,可以减少显存占用 4. --port=8001 - 指定服务监听的端口号为8001 5. --trust-remote-code - 信任并加载远程代码(如自定义的模型代码) 6. --chat-template /workspace/vLLM/Qwen/Qwen2.5-1.5B-Instruct/tokenizer_config.json - 指定聊天模板配置文件路径 7. --max-num-seqs 16 - 设置最大并发序列数为16 8. --gpu-memory-utilization 0.85 - 设置GPU显存利用率为85% 9. --enforce-eager - 强制使用eager模式(禁用图优化) 10. --swap-space 4 - 设置交换空间为4GB,用于处理超出显存的张量
启动成功!
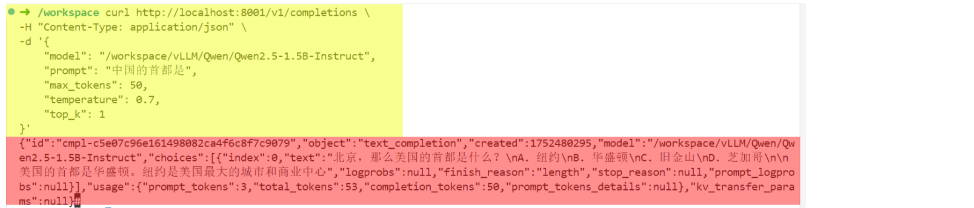
最后来测试一下 (新开一个终端哦~) :
curl http://localhost:8001/v1/completions \ -H "Content-Type: application/json" \ -d '{ "model": "/workspace/vLLM/Qwen/Qwen2.5-1.5B-Instruct", "prompt": "中国的首都是", "max_tokens": 50, "temperature": 0.7, "top_k": 1 }'
成功!!!