在汽车制造厂的最终检测线旁,一沓沓纸质车辆合格证正等待着被录入系统。这些看似普通的文件,却是车辆出厂、销售、注册、上路的法定"身份证",承载着车辆识别代号(VIN)、发动机号、排放标准、生产日期等数十项关键信息。传统的人工录入方式,不仅效率低下、成本高昂,平均每份需要5-10分钟,且极易因疲劳或疏忽导致错误,一个数字的误录都可能引发后续销售、税务乃至合规环节的连锁问题。如何快速、准确、结构化地"读懂"这些文件,成为困扰汽车产业链多年的痛点。
基于计算机视觉技术与自然语言处理技术深度融合的车辆合格证识别技术应运而生。这套系统不再满足于简单的"看"到文字,而是致力于真正地"读懂"文档,为行业带来了革命性的效率与精度提升。
技术原理:双引擎驱动的深度理解
传统OCR技术如同一个"高度近视的抄写员",只能机械地识别和输出图像中的字符,却无法理解字符间的逻辑关系、文档的固定格式以及具体字段的业务含义。车辆合格证识别技术构建了一个 "视觉感知(CV)→ 语义理解(NLP)→ 结构化输出与逻辑校验"的协同智能闭环。
1.图像预处理与版面分析(CV层)
- 系统首先对上传的合格证图像进行自适应增强,包括去噪、纠偏、光照校正等操作,以应对拍摄角度倾斜、反光、模糊等现实场景挑战。随后,基于深度学习的目标检测与分割模型(如改进型YOLO或Mask R-CNN)对证件整体结构进行解析,精准定位关键字段区域(如车辆识别代号VIN、发动机号、制造企业名称、发证日期等)。
2.多模态文字识别(OCR + NLP层)
- 在定位基础上,车辆合格证识别系统调用高精度OCR引擎对各字段进行文字识别。针对合格证中常见的印刷体、手写批注混合、低对比度文本等问题,车辆合格证识别技术采用上下文感知的字符识别模型,并结合NLP中的语言模型,对识别结果进行语义校正。例如,当OCR误将"京"识别为"亰"时,NLP模块可根据"车牌归属地"语义规则自动修正。
3.结构化输出与逻辑校验(NLP+规则引擎)
- 识别后的文本通过命名实体识别(NER)技术提取结构化字段,并依据国家《车辆合格证管理规范》内置业务规则进行逻辑一致性校验(如VIN码校验位验证、车型与排量匹配性检查等),确保输出数据的合规性与可用性。
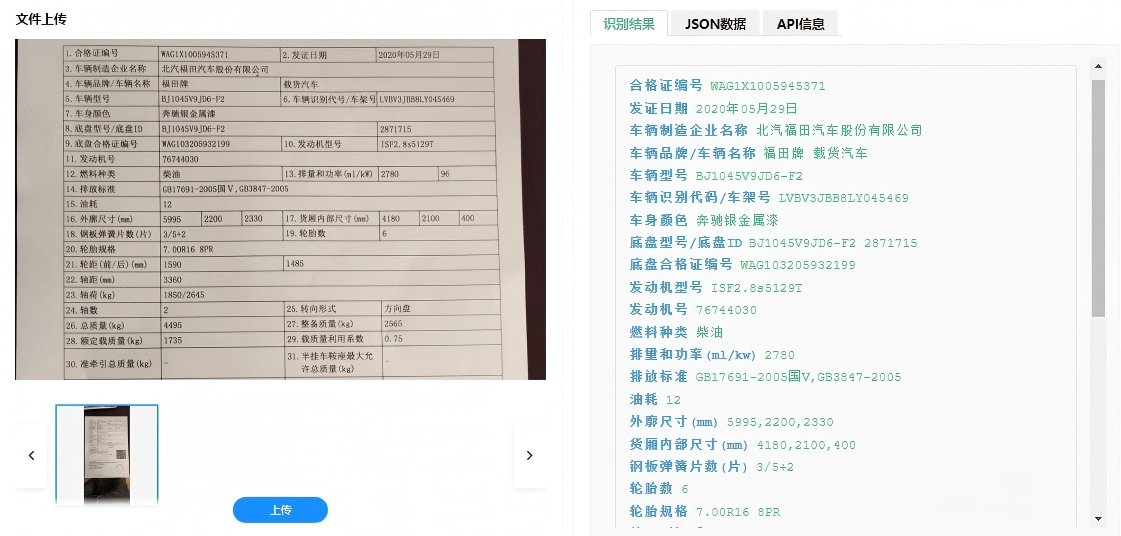
车辆合格证识别功能特点
- 高精度识别:在复杂背景、低质量图像条件下,关键字段识别准确率超过99.5%,远超传统OCR方案。
- 多版本兼容:支持2004年至今所有版本的国产机动车整车出厂合格证,自动适配不同排版格式。
- 端云协同部署:既可部署于本地服务器满足数据安全要求,也支持云端API调用,灵活适配不同客户IT架构。
- 智能纠错与学习:系统具备持续学习能力,可通过少量样本微调模型,快速适应新样式或特殊字段。
- 全流程可追溯:提供识别过程可视化日志,包括原始图像、字段定位框、识别置信度及校验结果,便于审计与复核。
应用场景:赋能汽车全产业链数字化
- 汽车生产与出厂管理(源头):
- 在总装线末端,自动识别并关联合格证与车辆VIN码,实现车辆信息"一键出厂",确保"车证一致",高效完成出厂核查与物流追踪。
- 经销商库存与销售管理(流通):
- 车辆到店后,快速扫描合格证,信息自动录入DMS,完成车辆入库。在销售环节,快速提取信息用于生成销售合同、办理临牌、对接金融服务,提升客户购车体验。
- 车辆登记与车管业务(监管):
- 为车辆管理所、税务部门提供技术支持,实现合格证信息的快速自动录入与核验,加速新车上牌流程,同时为环保信息核查、车辆税收征管提供准确数据基础。
- 二手车交易与金融服务(衍生):
- 在二手车交易中,快速识别原始合格证或相关文件,辅助车辆身份核实与价值评估。在汽车金融领域,为抵押登记、资产盘查提供高效、可信的数据抓取工具。
- 行业大数据分析与监管:
- 服务于行业协会或研究机构,通过对海量合格证信息的结构化提取与分析,可以洞察车型分布、排放标准升级、产能地域流向等宏观趋势,为产业决策提供数据支撑。
车辆合格证识别技术,生动诠释了"CV是感知世界的眼睛,NLP是理解世界的头脑"这一理念。其成功不仅在于解决了具体的业务痛点,更在于为整个汽车产业的数字化转型提供了一个坚实、智能的数据入口。随着技术的持续迭代和与产业链各环节的深度融合,这项技术将持续推动汽车行业在效率、准确性与智能化水平上迈向新的台阶,让每一辆车的"数字身份"都能被快速、准确地理解和运用,驶向更加智慧的未来。