在 Linux 2.6 内核之前,进程调度采用的是 O (n) 算法 ------ 调度器需要遍历所有就绪进程才能找到优先级最高的那个,进程数量越多,调度效率越低,严重影响多任务场景的性能。而 2.6 内核引入的 O (1) 调度算法,彻底解决了这一痛点,其核心就是设计了高效的调度队列结构,让调度器无论面对多少进程,都能在常数时间内找到最优进程,大幅提升了系统吞吐量。本文从调度队列的核心数据结构、工作流程、优先级管理三个维度,拆解 O (1) 调度队列的设计精髓,帮你理解 "常数时间调度" 的底层逻辑,看透 Linux 内核的高效调度秘诀。
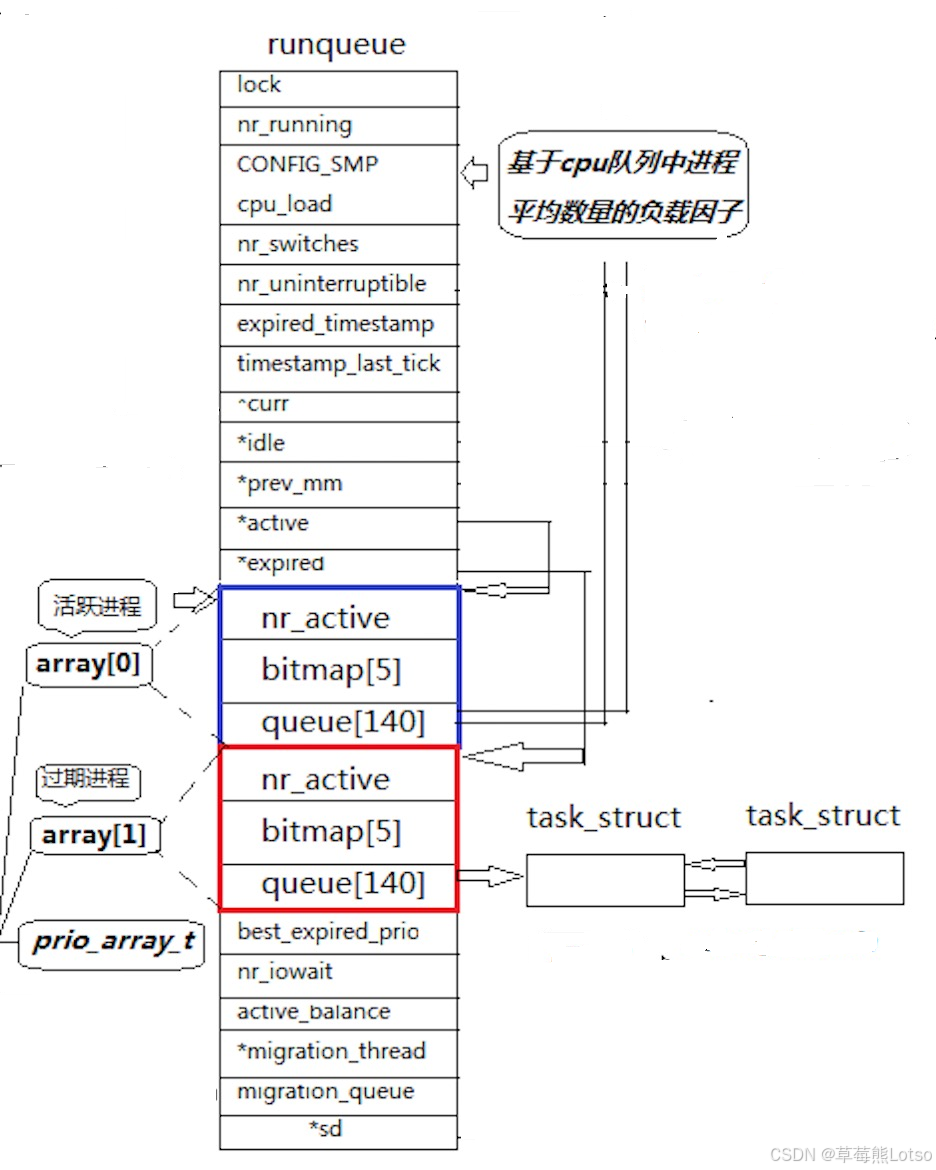
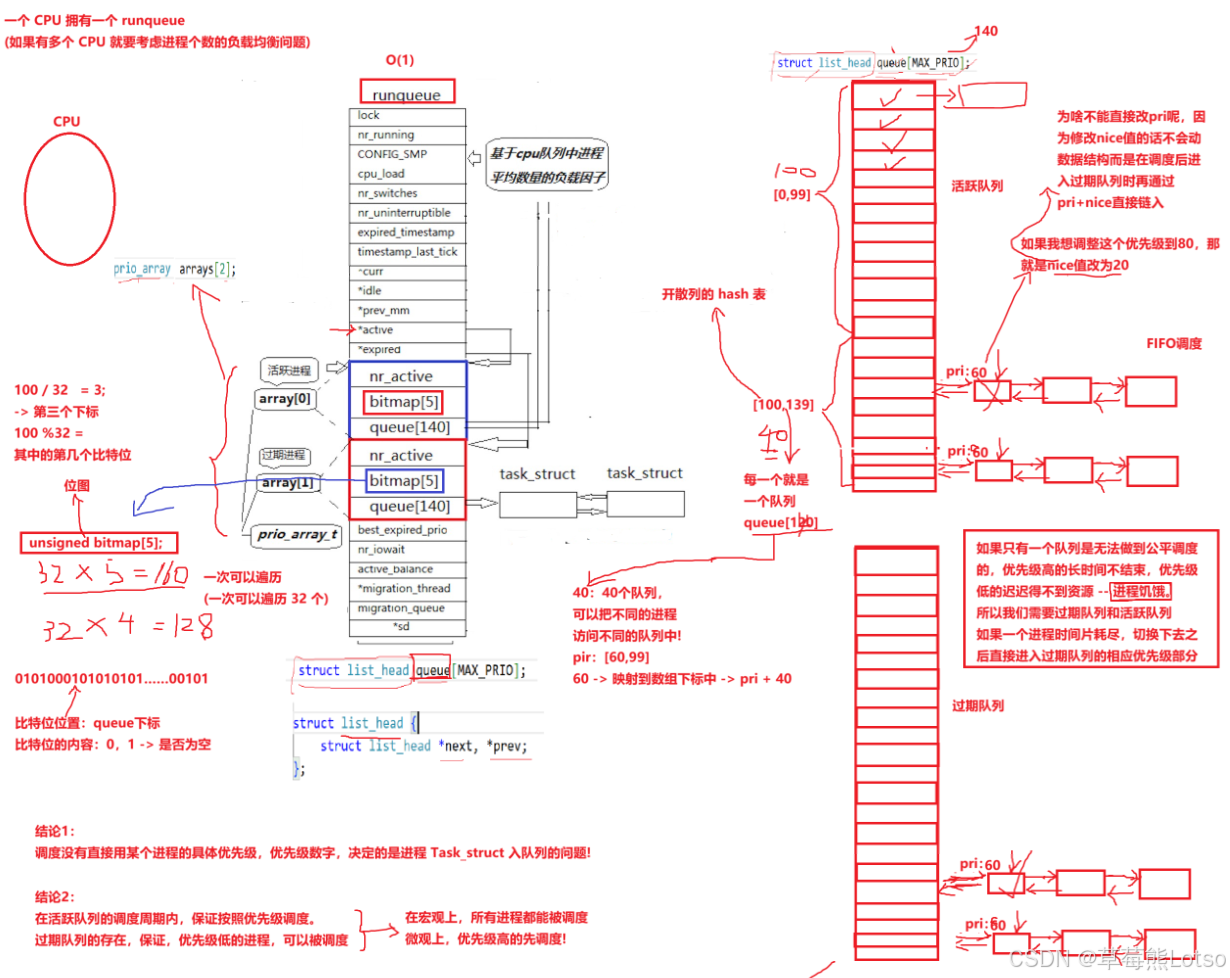
struct rq {
spinlock_t lock;
/*
* nr_running and cpu_load should be in the same cacheline because
* remote CPUs use both these fields when doing load calculation.
*/
unsigned long nr_running;
unsigned long raw_weighted_load;
#ifdef CONFIG_SMP
unsigned long cpu_load[3];
#endif
unsigned long long nr_switches;
/*
* This is part of a global counter where only the total sum
* over all CPUs matters. A task can increase this counter on
* one CPU and if it got migrated afterwards it may decrease
* it on another CPU. Always updated under the runqueue lock:
*/
unsigned long nr_uninterruptible;
unsigned long expired_timestamp;
unsigned long long timestamp_last_tick;
struct task_struct *curr, *idle;
struct mm_struct* prev_mm;
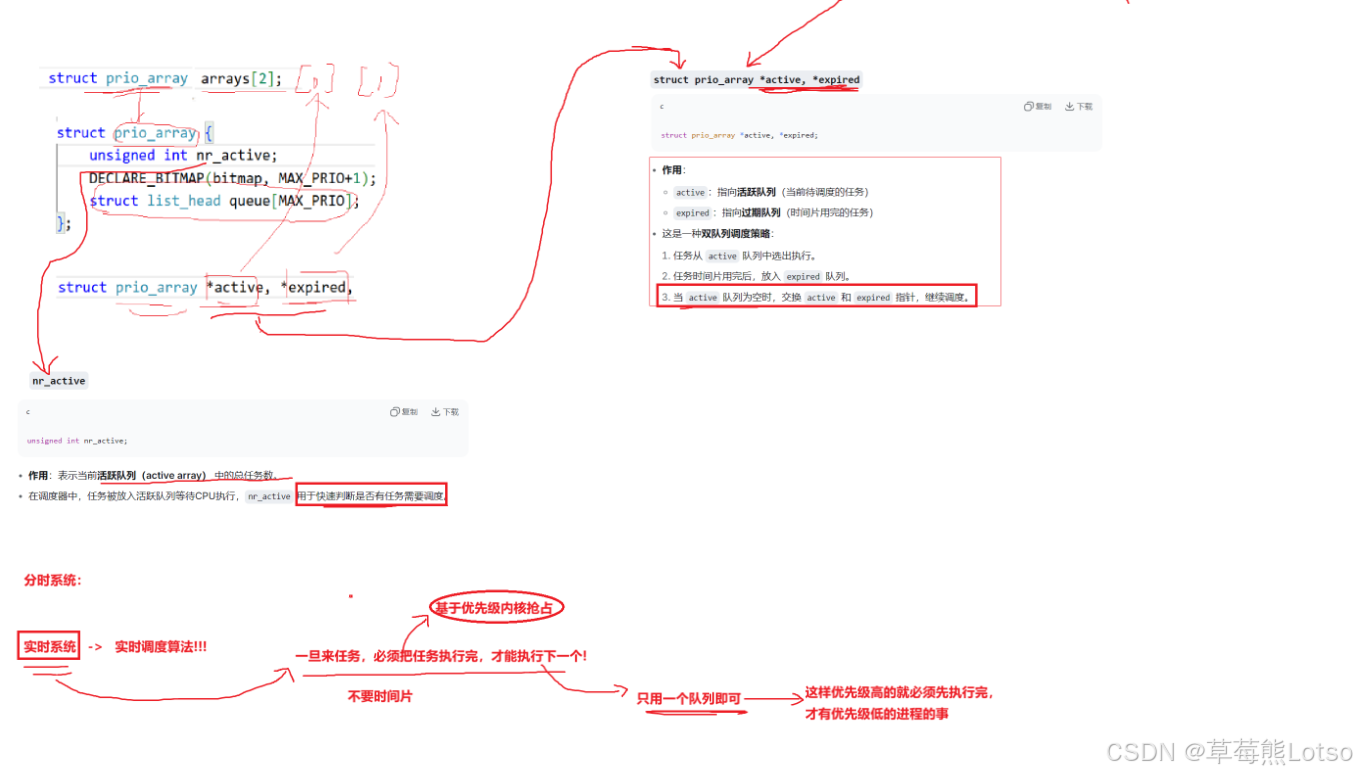
struct prio_array *active, *expired, arrays[2];
int best_expired_prio;
atomic_t nr_iowait;
#ifdef CONFIG_SMP
struct sched_domain* sd;
/* For active balancing */
int active_balance;
int push_cpu;
struct task_struct* migration_thread;
struct list_head migration_queue;
#endif
#ifdef CONFIG_SCHEDSTATS
/* latency stats */
struct sched_info rq_sched_info;
/* sys_sched_yield() stats */
unsigned long yld_exp_empty;
unsigned long yld_act_empty;
unsigned long yld_both_empty;
unsigned long yld_cnt;
/* schedule() stats */
unsigned long sched_switch;
unsigned long sched_cnt;
unsigned long sched_goidle;
/* try_to_wake_up() stats */
unsigned long ttwu_cnt;
unsigned long ttwu_local;
#endif
struct lock_class_key rq_lock_key;
};
/*
* These are the runqueue data structures:
*/
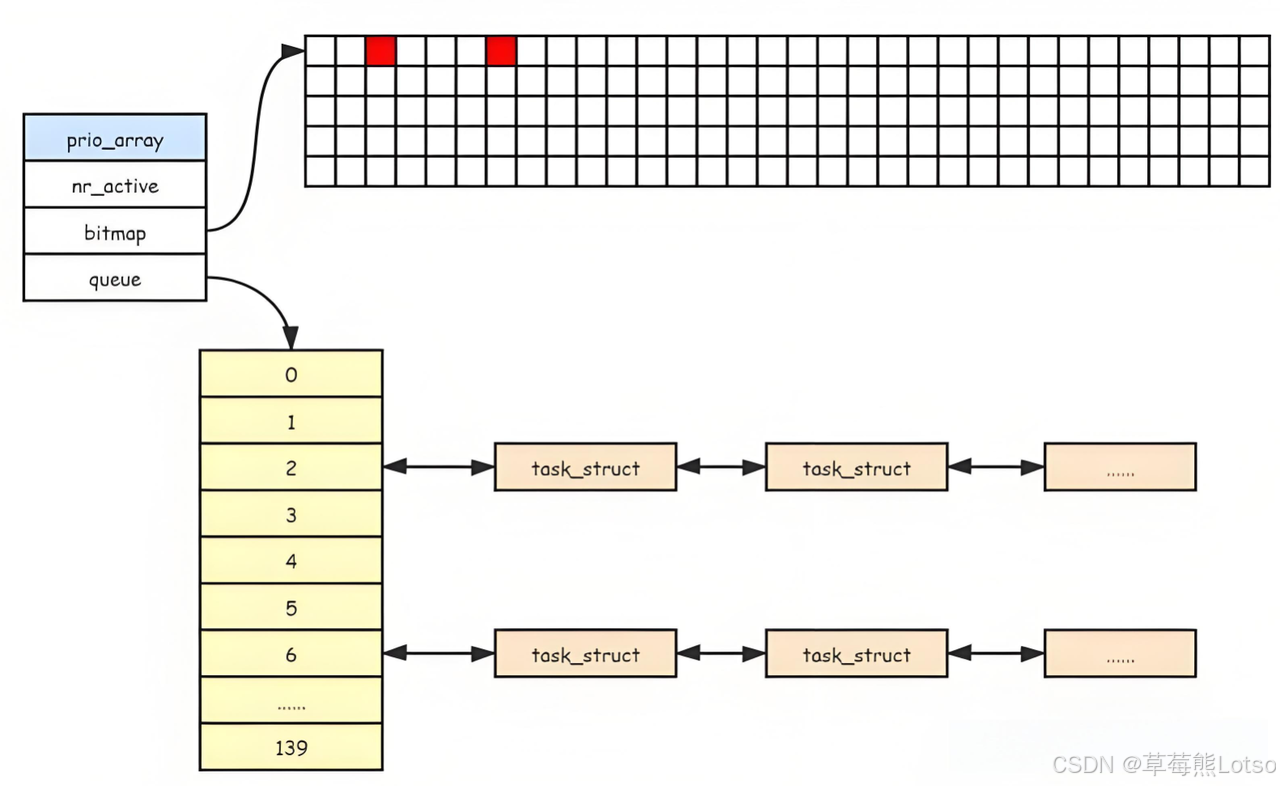
struct prio_array {
unsigned int nr_active;
DECLARE_BITMAP(bitmap, MAX_PRIO + 1); /* include 1 bit for delimiter */
struct list_head queue[MAX_PRIO];
};