首先针对西储大学轴承数据集进行专业化的数据预处理,将四个类别的振动信号文本文件加载并分割成固定长度的样本片段,每个样本包含1024个采样点的单通道时序数据,通过标准化处理消除幅值差异,采用分层抽样策略划分训练集、验证集和测试集,确保各类别比例平衡且避免数据泄露。接着构建多尺度卷积特征提取网络,设计三个并行的卷积分支分别使用64、32、16不同尺寸的卷积核,大尺度分支关注信号的长期趋势和低频成分,中尺度分支提取信号的周期性特征和中等频率分量,小尺度分支捕捉信号的瞬态冲击和高频细节,每个分支经过卷积、批归一化、非线性激活和自适应池化处理,然后将多尺度特征在通道维度拼接并通过1×1卷积进行融合降维,形成包含全面时频信息的统一特征表示。随后进入胶囊网络处理阶段,首先通过卷积操作将标量特征转换为向量形式的初级胶囊,每个初级胶囊包含多个维度的特征信息,在此基础上引入注意力机制,为每个初级胶囊计算动态权重,通过两层全连接网络评估不同胶囊对故障诊断的重要性,使用Sigmoid函数生成0到1之间的注意力分数,实现对关键故障特征的自动聚焦和无关特征的抑制。然后执行简化的动态路由过程,每个故障类别对应一个独立的变换矩阵,将加权后的初级胶囊映射到高级胶囊空间,通过squash函数进行非线性激活并保持向量方向,最后对所有胶囊进行平均池化聚合形成代表不同故障类型的数字胶囊。最后进行多分类决策,将各个类别的数字胶囊拼接后通过全连接层映射到四个故障类别,使用Softmax函数输出每个类别的概率分布,采用交叉熵损失函数进行端到端训练,结合数据增强策略防止过拟合,通过学习率衰减和早停机制优化训练过程,最终在独立测试集上实现高精度轴承故障诊断。
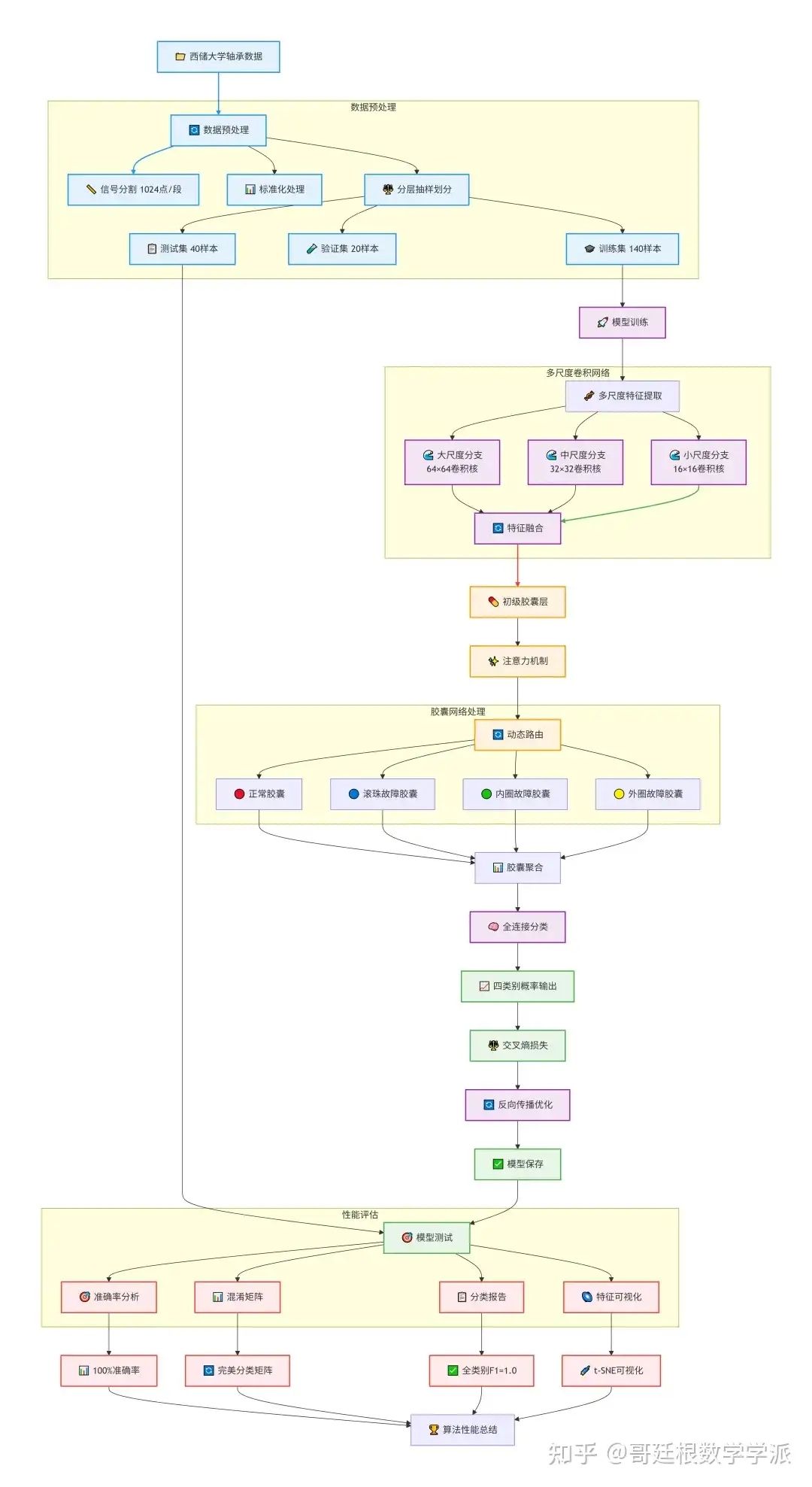
第一步:数据采集与加载准备
获取西储大学轴承数据集的四个类别振动信号文件,分别对应正常状态、滚珠故障、内圈故障和外圈故障的原始时域数据,每个文件包含数万个采样点的连续振动信号,建立标准化的数据加载接口确保不同故障类型数据的统一处理。
第二步:信号分割与预处理操作
将每个长序列振动信号按照固定长度进行重叠分割,生成多个独立样本片段以便于批量训练,对每个样本进行零均值单位方差的标准化处理消除信号幅值差异,确保不同工况下采集的数据具有可比性。
第三步:数据集划分与平衡处理
采用分层抽样策略将样本划分为训练集、验证集和测试集三个独立部分,严格控制每个故障类别在三类数据集中的比例保持一致,确保模型评估的公正性和可靠性,同时设置样本数量上限维持类别平衡。
第四步:多尺度卷积特征提取设计
构建三个并行的卷积神经网络分支,分别配置大尺寸卷积核捕捉信号的长期趋势和低频特征,中等尺寸卷积核提取信号的周期性波动特征,小尺寸卷积核聚焦信号的瞬态冲击和高频成分,每个分支独立进行卷积运算、批量归一化和非线性激活。
第五步:特征融合与维度统一处理
将三个尺度分支提取的特征图在通道维度上进行拼接整合,通过一乘一卷积核进行特征融合和通道数调整,生成包含全局趋势、中期波动和局部细节的综合性特征表示,为后续胶囊化转换提供统一输入。
第六步:初级胶囊层向量化转换
通过卷积操作将传统神经网络中的标量特征表示转换为胶囊网络特有的向量形式,每个空间位置的特征点映射为包含多个维度的胶囊向量,保留特征之间的相对关系和姿态信息,构建初级胶囊层作为后续处理的基础单元。
第七步:注意力机制特征重要性评估
为每个初级胶囊计算动态重要性权重,通过两层全连接网络评估不同胶囊对最终故障诊断任务的贡献程度,使用Sigmoid激活函数生成零到一之间的注意力分数,实现关键故障特征的自动聚焦和无关特征抑制。
第八步:动态路由与胶囊聚合处理
执行胶囊网络的信息路由过程,每个故障类别对应独立的变换矩阵将加权后的初级胶囊映射到高级特征空间,通过squash函数进行非线性激活保持向量方向,最后对同类胶囊进行平均池化聚合形成代表不同故障类型的数字胶囊。
第九步:多分类输出与概率计算
将各类别的数字胶囊向量拼接后通过全连接层映射到四个故障类别,使用Softmax激活函数计算每个类别的概率分布,采用交叉熵损失函数衡量预测概率与真实标签之间的差异,为端到端训练提供优化目标。
第十步:训练优化与防过拟合策略
采用自适应矩估计优化算法进行参数更新,结合数据增强技术增加训练样本多样性,实施学习率衰减策略在训练后期精细调整参数,引入早停机制在验证集性能不再提升时终止训练,有效防止模型过拟合。
第十一步:独立测试集全面性能评估
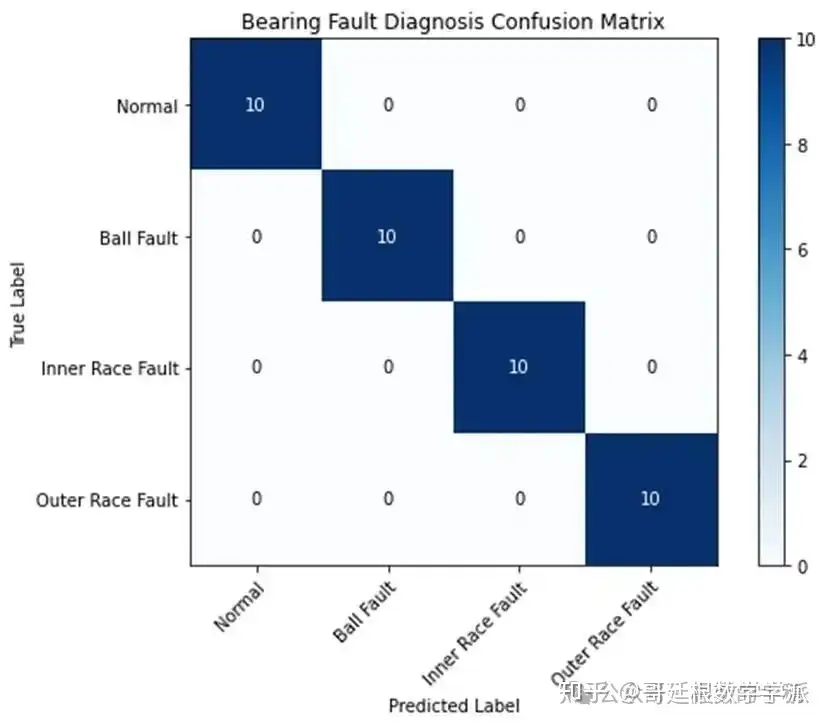
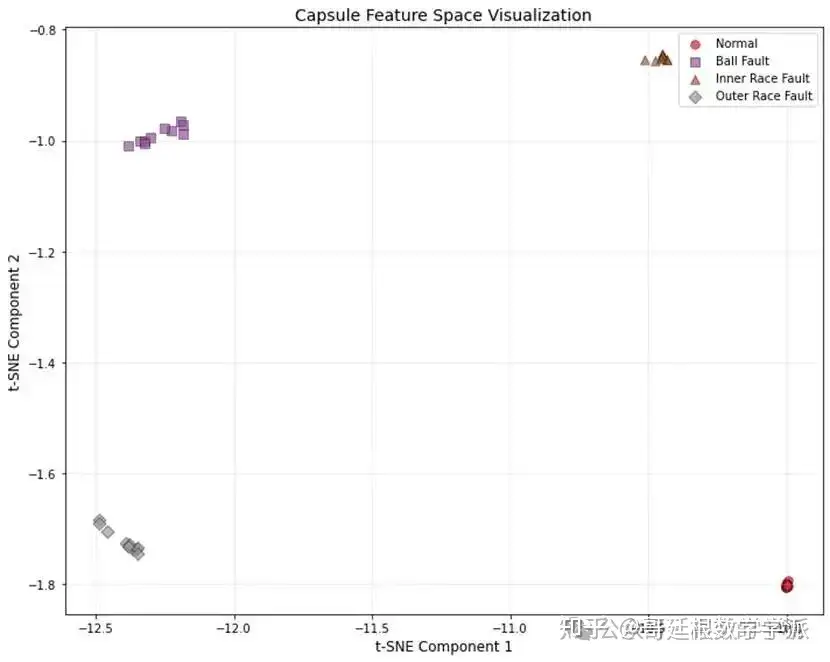
在完全独立的测试集上进行模型最终性能评估,计算整体分类准确率、每个类别的精确率召回率和F1分数,绘制混淆矩阵直观展示各类别的识别情况,使用t-SNE技术可视化胶囊特征空间分布。
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import os
import glob
from scipy import signal
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
from sklearn.manifold import TSNE
import warnings
warnings.filterwarnings('ignore')
# 设置随机种子确保可重复性
torch.manual_seed(42)
np.random.seed(42)
# ==================== 1. 西储大学轴承数据加载器 ====================
class CWRUBearingDataLoader:
"""西储大学轴承数据加载器"""
def __init__(self, data_folder='data', sample_length=1024, sampling_rate=12000):
"""
Args:
data_folder: 数据文件夹路径
sample_length: 每个样本的长度
sampling_rate: 采样频率(赫兹)
"""
self.data_folder = data_folder
self.sample_length = sample_length
self.sampling_rate = sampling_rate
# 西储大学数据标签映射
self.label_mapping = {
'98raw': 0, # 正常状态
'106raw': 1, # 滚珠故障(球故障)
'119raw': 2, # 内圈故障
'131raw': 3 # 外圈故障
}
self.fault_names = ['正常', '滚珠故障', '内圈故障', '外圈故障']
def load_txt_file(self, file_path):
"""加载单个txt文件"""
try:
data = np.loadtxt(file_path)
return data.reshape(-1) # 确保是一维数组
except Exception as e:
print(f"加载文件 {file_path} 出错: {e}")
return None
def segment_signal(self, signal_data, overlap_ratio=0.5):
"""将长信号分割成多个样本"""
n_samples = len(signal_data)
step = int(self.sample_length * (1 - overlap_ratio))
segments = []
for start in range(0, n_samples - self.sample_length, step):
end = start + self.sample_length
segment = signal_data[start:end]
# 确保段长度正确
if len(segment) == self.sample_length:
segments.append(segment)
return np.array(segments)工学博士,担任《Mechanical System and Signal Processing》等期刊审稿专家,擅长领域:现代信号处理,机器学习,深度学习,数字孪生,时间序列分析,设备缺陷检测、设备异常检测、设备智能故障诊断与健康管理PHM等。
参考文章:
基于多尺度特征提取和注意力自适应动态路由胶囊网络的工业轴承故障诊断算法(Pytorch) - 哥廷根数学学派的文章
https://zhuanlan.zhihu.com/p/1992980794113799908