uniad模型
模型的backbone
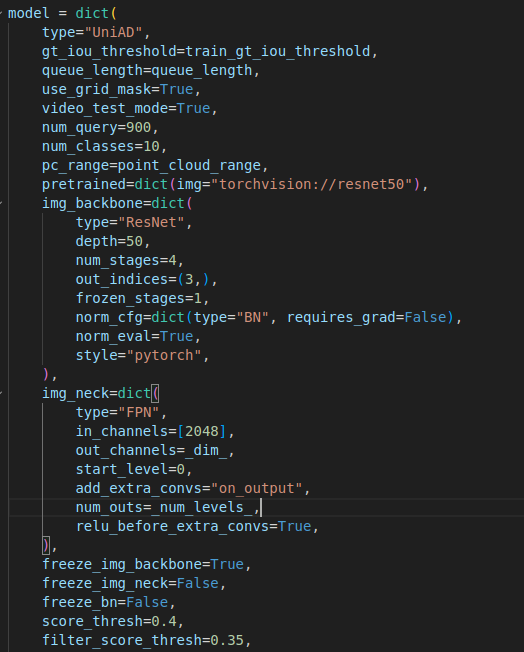
这段代码配置的是一个 UniAD(Unified Tracking and Detection)模型的超参数和架构。
model(模型配置)
整个 model 字典包含了所有关于模型结构、参数以及训练设置的信息。
-
type="UniAD"表示模型类型是
UniAD,它是一个集成了 目标检测 和 目标跟踪 的系统。 -
gt_iou_threshold=train_gt_iou_threshold这个参数用于设置 目标检测 中的 IoU 阈值,通常用来确定在训练时 ground truth (GT) 和预测框是否匹配。IoU(Intersection over Union)值越高,表示检测框和真实框的重叠程度越高。
train_gt_iou_threshold是外部传入的变量,用于动态设置这个阈值。 -
queue_length=queue_length
queue_length用于设置 队列长度 ,通常涉及模型的 记忆机制,例如 memory bank(记忆库)或者 batch 缓存。 -
use_grid_mask=True启用 grid mask,这通常用于数据增强中的遮挡操作。它可以随机将输入图像的一部分遮挡,以提高模型的鲁棒性。
-
video_test_mode=True设置是否启用视频测试模式。此配置通常在视频处理任务中使用,特别是当你在测试视频数据时,可能会有一些特殊的后处理需求。
-
num_query=900设置 查询数量 。在像 目标检测 或 Transformer-based 模型 中,query 表示输入到模型的对象数量或检测框数量。900 可能是该模型用于检测或跟踪的最大对象数。
-
num_classes=10设置类别数,表示模型需要区分的目标类别数量。此处设置为 10 类。
-
pc_range=point_cloud_range这个参数用于设置 点云范围 ,通常用于 LiDAR 传感器数据。
point_cloud_range是外部传入的变量,定义了点云数据的空间范围。 -
pretrained=dict(img="torchvision://resnet50")指定了一个预训练模型。这里选择了 ResNet-50 作为图像部分的预训练模型,并从
torchvision获取。预训练模型的使用有助于加速模型训练并提升性能。
img_backbone(图像主干网络)
img_backbone 配置图像的主干网络部分,用于从输入的图像中提取特征。
-
type="ResNet"使用 ResNet 作为主干网络,这是一种常见的深度卷积神经网络(CNN),特别适用于图像特征提取。
-
depth=50使用 ResNet-50,这个值指代 ResNet 的深度。50 表示网络有 50 层。
-
num_stages=4ResNet 通常由多个阶段(stages)组成,每个阶段负责不同尺度的特征提取。
num_stages=4表示 ResNet-50 有 4 个阶段。 -
out_indices=(3,)这个设置指定了要输出的特征层索引,
3表示输出最后一个阶段(即,ResNet-50 的第 4 个阶段)的特征图。 -
frozen_stages=1这个配置表示在训练过程中,ResNet 网络的前 1 个阶段是被冻结的,意味着这些层的参数在训练过程中不更新。通常用于迁移学习以减少计算量。
-
norm_cfg=dict(type="BN", requires_grad=False)使用 Batch Normalization (BN) 作为归一化方法,并且设置 BN 的参数不参与梯度更新。
requires_grad=False表示在训练过程中不更新 BN 参数。 -
norm_eval=True设置 BN 层在评估模式下保持不变,通常是在推理阶段(测试)使用。
-
style="pytorch"设置模型的初始化风格为 PyTorch 风格,确保预训练模型与 PyTorch 的实现兼容。
img_neck(图像 neck)
img_neck 配置了图像特征的后处理部分,通常用于对不同层的特征图进行融合或调整。
-
type="FPN"使用 Feature Pyramid Network (FPN),一种多尺度特征融合的架构,能够有效地捕获不同尺度的物体特征。
-
in_channels=[2048]输入特征图的通道数,
2048表示输入的特征图是从 ResNet-50 输出的最后一个阶段(第 4 个阶段),它的特征维度通常是 2048。 -
out_channels=_dim_输出特征图的通道数,
_dim_是一个外部传入的变量,通常代表模型中某一层的特征维度。 -
start_level=0设置从哪个层开始进行 FPN 操作,
0表示从 ResNet 的第一个阶段(最低分辨率的特征)开始。 -
add_extra_convs="on_output"在输出时添加额外的卷积层。这是 FPN 的一种常见做法,用于进一步调整和融合特征。
-
num_outs=_num_levels_输出的层数,
_num_levels_是外部传入的变量,表示要生成多少个尺度的输出特征图。 -
relu_before_extra_convs=True在添加额外卷积层之前是否应用 ReLU 激活函数。
True表示会应用。
其他设置
-
freeze_img_backbone=True冻结图像主干网络(ResNet-50),在训练过程中这些层的参数不会更新。这通常用于迁移学习,以减少训练的计算量。
-
freeze_img_neck=False不冻结图像 neck 部分,这意味着 FPN 部分的参数会在训练过程中更新。
-
freeze_bn=False不冻结 Batch Normalization 层,这样 BN 层的参数也会在训练中更新。
-
score_thresh=0.4这是 检测阈值,表示只有预测分数大于 0.4 的目标才会被视为有效目标进行后续处理。
-
filter_score_thresh=0.35另一个分数阈值,可能用于过滤低得分的检测结果或目标。
qim_args(Query Interaction Model 配置)
这个部分通常控制如何处理输入的 query(查询)。在 MOTR(或者类似 Transformer 模型)中,query 可能是指向量或特征集合。
-
qim_type="QIMBase"
qim_type是 Query Interaction Model 类型的设置,"QIMBase" 可能是一个基类或预设类型。具体的实现和效果取决于你使用的框架和模型。 -
merger_dropout=0这个设置控制在合并不同查询的过程中是否有丢弃(dropout)。
dropout=0表示没有随机丢弃,这意味着模型将考虑所有的输入。 -
update_query_pos=True是否更新查询的位置嵌入(positional encoding)。
True表示查询的位置会随着模型训练过程更新,这有助于捕捉不同时间步或空间位置的信息。 -
fp_ratio=0.3
fp_ratio可能与 feature pooling (特征池化)或者 fine-tuning (微调)有关。0.3表示在某个特定阶段,模型会保留30%的特征信息,进行进一步的优化。 -
random_drop=0.1在训练过程中随机丢弃部分输入 query,
0.1表示每次会随机丢弃10%的查询。这通常用于正则化,防止过拟合。
mem_args(Memory Bank 配置)
这个部分控制与 memory bank 相关的超参数,通常用于增强模型的记忆能力,尤其是在处理长时序或大规模数据时。
-
memory_bank_type="MemoryBank"
memory_bank_type决定了存储和访问记忆的方式,"MemoryBank" 可能是一个简单的存储类型,用于缓存过去的特征或查询结果。 -
memory_bank_score_thresh=0.0
memory_bank_score_thresh设置了一个阈值,通常用于筛选哪些记忆存储或特征需要被访问。如果某些存储的记忆得分低于这个阈值,它们可能就不会被使用。0.0表示没有阈值限制。 -
memory_bank_len=4
memory_bank_len设置了记忆库的长度。4表示记忆库最多会存储 4 个历史状态或特征(这通常是一个超参数,具体数值根据任务而定)。
模型的BEVFormerTrackHead部分
-
img.size()的大小为torch.Size([1, 5, 6, 3, 256, 416]),含义从左到右依次为:- 1 → batch size(批大小) :当前实现仅支持 BS=1
- 5 → queue length / num frames(时间序列长度):一个 clip 内的帧数
- 6 → num cameras(相机数量) :NuScenes 为 6
- 3 → channels(图像通道):RGB 三通道
- 256 → height(图像高):预处理后高度
- 416 → width(图像宽):预处理后宽度
代码位置提示
-
在
fusionad_track.py(line 413)明确按:pythonbs, len_queue, num_cams, C, H, W = imgs_queue.shape解包。
-
随后会 reshape 成:
python[bs * len_queue, num_cams, C, H, W] -
再在
extract_img_feat中按:pythonB, N, C, H, W = img.size()使用。
下面把这两句代码"按数据长什么样、每一步取到什么、为什么这样写"讲透,并用你给的实际尺寸做一个完整案例。
背景:你的输入是"时序 + 多相机"的 batch
你给的 img.size() 是:
img:torch.Size([1, 5, 6, 3, 256, 416])
按常见约定解释就是:
B=1:batch 里 1 个样本T=5:时序 5 帧N=6:每帧 6 个相机视角C=3:RGBH=256, W=416
所以 img[b, t, n] 取出来的是:第 b 个样本、第 t 帧、第 n 个相机的一张图,形状 [3, 256, 416]。
1)img_single = torch.stack([img_[i] for img_ in img], dim=0)
关键点:for img_ in img 是在遍历 batch 维(第 0 维)
因为 img 是一个 Tensor,直接 for img_ in img 等价于:
python
img_ = img[0] # 第一个样本
# 如果 B>1,还会有 img[1], img[2]...在你这里 B=1,所以循环只跑一次。
-
img_的形状:- 原来
img是[B, T, N, C, H, W] - 取出一个样本后变成
[T, N, C, H, W] - 所以
img_.size()=[5, 6, 3, 256, 416]
- 原来
然后取第 i 帧:img_[i]
img_[i]是在时间维T上取第 i 帧- 形状从
[T, N, C, H, W]变成[N, C, H, W]
也就是:
img_[i].size()=[6, 3, 256, 416]
最后 stack(..., dim=0) 把 batch 维堆回来
列表里每个元素都是一个样本在第 i 帧的图像(形状 [N, C, H, W]),把它们沿 dim=0 堆起来:
- 得到
img_single形状[B, N, C, H, W]
在你的例子里:
img_single.size()=[1, 6, 3, 256, 416]
✅ 这正好对应你观察到的:
img.size():[1, 5, 6, 3, 256, 416]img_single.size():[1, 6, 3, 256, 416]
一句话:它把"时序 T"这一维挑出第 i 帧,变成单帧输入,但保留 batch 和多相机维。
2)img_metas_single = [copy.deepcopy(img_metas[0][i])]
img_metas 通常是"按 batch、时间"组织的元信息(每帧一个 dict),常见结构是:
img_metas[b][t]是一个 dict- 比如包含
lidar2img、cam2img、img_shape、pad_shape、时间戳等
这句在做:
img_metas[0]:取 batch 的第 0 个样本(因为当前实现默认B=1)[i]:取该样本的第 i 帧元信息deepcopy:防止后续单帧前向里改 metas(比如改img_shape、batch_input_shape、pad_shape等)污染原来的时序 metas- 外面包一层
[...]:因为下游接口一般期望 metas 是 "长度为 B 的 list",哪怕 B=1 也要是 list
为什么这段代码"隐含 B=1"?
因为 metas 只取了 img_metas[0],完全没遍历 batch。
如果你把 batch_size 改成 2,比如:
img.size()=[2, 5, 6, 3, 256, 416]
那这句:
python
img_metas_single = [copy.deepcopy(img_metas[0][i])]只会拿到第 0 个样本的 metas,第 1 个样本的 metas 丢了,下游就会错位或报错。
B>1 时应该怎么写(对应 img_single 的做法)
跟 img_single 一样,应该对 batch 遍历:
python
img_metas_single = [copy.deepcopy(metas_i[i]) for metas_i in img_metas]
# 其中 metas_i = img_metas[b],metas_i[i] = img_metas[b][i]这样:
img_metas_single长度就是B- 每个元素都是对应样本的第 i 帧 dict
- 与
img_single[b]一一对应
用你这个尺寸做一个"逐步取值"小例子(直观理解)
假设 i = 3(第 4 帧):
-
原始:
img.shape = [1, 5, 6, 3, 256, 416]
-
取样本:
img_ = img[0]img_.shape = [5, 6, 3, 256, 416]
-
取第 3 帧:
frame = img_[3]frame.shape = [6, 3, 256, 416](6 个相机)
-
堆回 batch:
img_single = stack([frame], dim=0)img_single.shape = [1, 6, 3, 256, 416]
-
metas:
meta = img_metas[0][3](第 0 个样本、第 3 帧的 dict)img_metas_single = [deepcopy(meta)](长度为 1 的 list)