【强化学习】第十章:随机高斯策略
高斯策略属于强化学习的基于策略优化 的分支,用于解决连续动作空间中的任务,本来是打算写入第八章的,但是在Actor-Critic框架中,使用高斯策略能实现更稳定、更高效的策略优化,彼时AC又没讲,所以思来想去,这部分就只能单独开一个篇章讲解了。
所以,本文文承第八、九章节,如果有八、九章节的基础,本文就是顺水推舟,理所当然。
1、随机高斯策略的应用场景
本章节之前的所有算法都只能用于求有限个离散动作 的最优策略问题。比如有限个动作的确定性最优策略 、有限个动作的随机性最优策略 ,都是针对有限个离散动作的场景。但是实际中,我们会遇到求连续动作空间中的最优策略问题。
随机高斯策略是求解连续动作空间中最优策略的方法之一。此后我们还会学到DPG-->DDPG-->优化后的TD3模型,这些算法都可以解决动作空间连续的问题。
但是DPG、DDPG和TD3的策略都是连续动作空间的确定性策略 。随机高斯策略求出的是连续动作空间中的随机性策略,就是有概率的策略,我们可以根据动作的概率去对动作进行抽样,得到连续动作空间中一个最优的确定性动作。
2、策略函数的架构设计 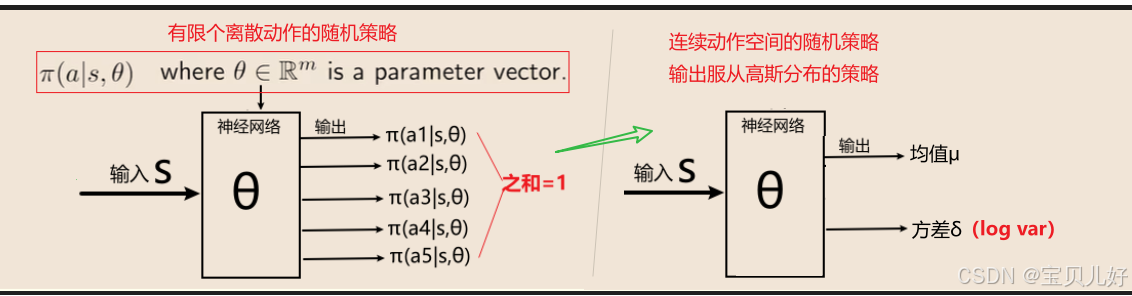 (1)左图的输出是有限个动作的随机策略。本篇章学右图,输出的是某个概率分布的参数,具体到这里就是高斯分布的参数:均值和方差。当然你可以根据你自己的实际情况,你可以学习你自己需要的概型。本篇是高斯概型。
(1)左图的输出是有限个动作的随机策略。本篇章学右图,输出的是某个概率分布的参数,具体到这里就是高斯分布的参数:均值和方差。当然你可以根据你自己的实际情况,你可以学习你自己需要的概型。本篇是高斯概型。
(2)上图的策略函数都是用神经网络来拟合,当然你可以用任何函数拟合,只要效果好,都是可以的,不是只局限于神经网络。这里以神经网络为例。
(3)对于左图,输出有限个动作的随机概率,我们之前是特别强调:神经网络的输出层是要加softmax层 的。
但是对于右图,输出层就不适合 添加任何非线性变换了,直接回归两个数值即可。也就是输出层只要两个神经元即可,一个表示高斯分布的均值μ,一个表示高斯分布的方差δ。
(4)我们一般不直接回归方差δ ,而是回归一个log(var) ,就是方差的自然对数。为啥是log(var),而不直接就是方差δ?因为方差都是大于0的数-->大于0的数,经过log以后,就可正可负-->可正可负正符合神经网络的输出。所以我们把神经网络的输出看作是log(var),比去限制网络的输出范围更加简单方便,需要方差时再变换一下即可。
(5)策略函数输出的是高斯分布的参数:均值和方差。但是我们想得到的是连续动作空间中的一个确定性动作,所以我们只要在这个分布中随机采样一个动作输出即可。
3、从策略函数的数据流角度分析策略梯度
我们上面的策略函数架构是极简的形式,我看有的资料是创建两个网络,一个网络输出均值,一个网络输出方差。其实个人感觉没必要这么麻烦,一个网络直接回归2个值也是可以的。为了节省画图的时间,我就用别人的架构图梳理一下策略函数的数据流: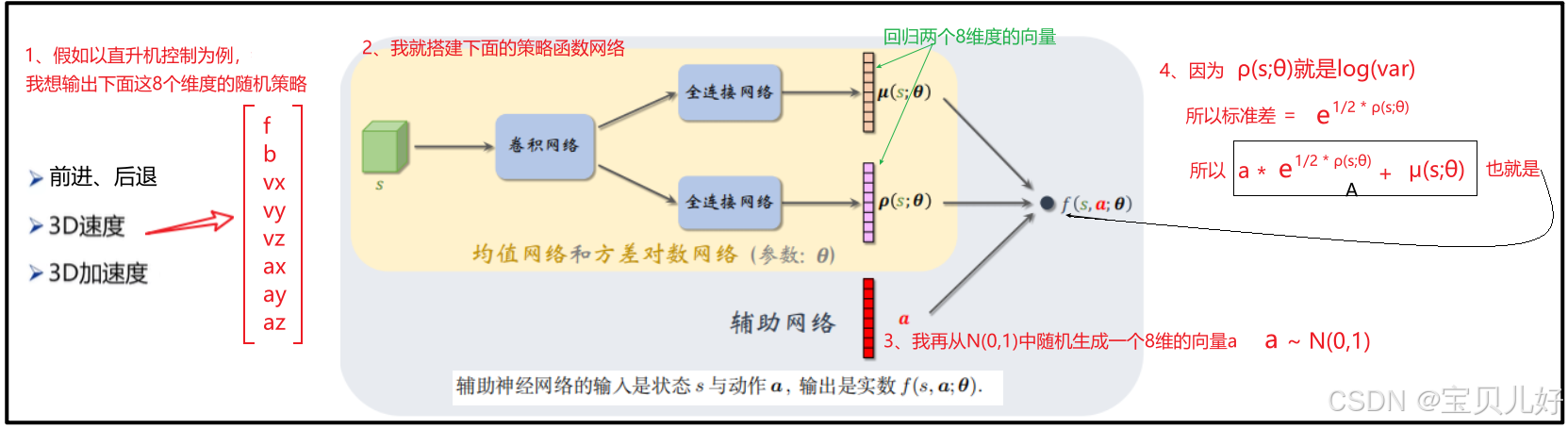 (1)采样公式为:a = μ + σ*ϵ,其中ϵ∼N(0,1)是标准正态噪声。
(1)采样公式为:a = μ + σ*ϵ,其中ϵ∼N(0,1)是标准正态噪声。
(2)策略函数的正向传播是:输入网络状态s,输出8对儿(μ,log(var))。然后从一个标准正态分布中随机采样一个8维的向量,-->每个维度都乘 标准差加均值-->输出连续动作空间中的一个确定性动作f。所以f(s,a,θ)是一个确定性的数值,就是上图的A。
(3)上图3处的操作叫重参数技巧 ,在深度学习生成网络AVE模型中就有这个操作。感兴趣可参考: https://blog.csdn.net/friday1203/article/details/137709966
(4)我们要求策略函数梯度,优化策略函数,那我们就得看数据流是否可以顺利反向传播。从f(s,a,θ)到(μ,log(var))的映射关系就是上图的A处,可导可微,这部分梯度是可以顺利回传的。从(μ,log(var))到s是神经网络,自然更可以顺利回传。可见反向求梯度毫无障碍。
4、策略梯度的计算-->策略函数的优化
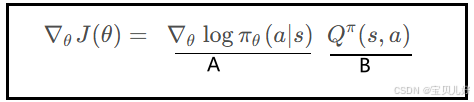
这是我们第八章推导出来的策略梯度公式,由A、B两部分组成:
(1)A部分就是上图中从f->s反向传播的梯度。前面从数据流角度描述了从f->s可以丝滑求导。
(2)B部分是从策略π 下采集经验数据,从经验数据中学习而来。那策略π是什么呢? 策略π是用来指导行动action,从而生成经验数据的。而从经验数据中学习q(s,a)又有MC方法和TD方法,所以随机高斯策略的实现又分基于REINFORCE的实现方法和基于AC的实现方法:
策略π是用来指导行动action,从而生成经验数据的。而从经验数据中学习q(s,a)又有MC方法和TD方法,所以随机高斯策略的实现又分基于REINFORCE的实现方法和基于AC的实现方法:
5、小结
高斯策略提供了一个可学习、可微、易实现的方式让策略梯度算法在连续动作空间中工作,从而"使得policy(在梯度更新下)收敛到最优或近似最优解。严格来说,高斯策略往往收敛于局部最优,但是在很多连续控制任务中,局部最优已经是相当好了。
对七、八、九章节非常熟悉的同学,本篇章就非常非常简单。本篇的难点(或者说新知识点)只有一个:重参数技巧,以及在重参数操作下,梯度计算的微小变化。也就是从策略网络的输出(均值,log(var))到随机采样,这个映射过程中的梯度问题。想明白后其实特别特别简单,就是高斯分布的映射关系,而高斯分布又是处处可导可微。这点想明白后,随机高斯策略就不攻自破了。
PS.这是有史以来最简短、一天成稿的一篇博文。但是我还是详细写出了每个细节点,作为笔记方便以后查阅。