文章目录
1、RNN概念
循环神经网络(RNN)入门介绍
循环神经网络(Recurrent Neural Network,简称 RNN)是一类专门用于处理序列数据的神经网络。与传统的前馈神经网络(Feedforward Neural Network)不同,RNN 具有"记忆"能力,可以利用之前的信息来影响当前的输出。
- 什么是序列数据?
在理解 RNN 之前,先明确"序列数据"的含义:
- 序列数据是指按时间或顺序排列的一组数据点。
- 每个数据点不仅有自己的信息,还和前后数据点存在依赖关系。
常见的序列数据例子:
- 自然语言:一个句子中的单词按顺序出现,比如 "我 爱 学习"。
- 语音信号:声音随时间变化的波形。
- 股票价格:每天的收盘价构成的时间序列。
- 视频帧:每一帧图像按时间顺序播放。
这些数据的关键特点是:当前时刻的数据往往和过去的数据有关。
- 为什么普通神经网络处理不了序列?
普通的前馈神经网络(如多层感知机 MLP)假设输入之间是相互独立的。例如,你输入一张图片,它只根据这张图片做判断,不会考虑"上一张图片是什么"。
但在处理序列时,这种独立性假设不成立。比如在句子 "我今天去__" 中,要预测下一个词,必须知道前面说了什么。这就需要一种能记住历史信息的模型------这就是 RNN 的作用。
- RNN 的核心思想:引入"循环"
RNN 的关键创新在于:在网络中引入了循环连接,使得信息可以在时间维度上传递。
结构图解(文字描述):
想象一个基本的 RNN 单元,在每个时间步 t t t,它接收两个输入:
- 当前时刻的输入 x t x_t xt(比如第 t t t 个单词);
- 上一时刻的隐藏状态 h t − 1 h_{t-1} ht−1(即"记忆")。
然后,它计算当前时刻的隐藏状态 h t h_t ht,公式如下:
h t = tanh ( W h h t − 1 + W x x t + b ) h_t = \tanh(W_h h_{t-1} + W_x x_t + b) ht=tanh(Whht−1+Wxxt+b)
其中:
- W h W_h Wh、 W x W_x Wx 是可学习的权重矩阵;
- b b b 是偏置项;
- tanh \tanh tanh 是激活函数(也可以用其他,如 ReLU,但传统 RNN 常用 tanh)。
这个 h t h_t ht 既包含了当前输入的信息,也融合了之前所有时刻的信息(通过 h t − 1 h_{t-1} ht−1 传递而来),因此被称为"隐藏状态"或"记忆状态"。
💡 注意 :虽然理论上 h t h_t ht 包含了从 t = 0 t=0 t=0 到当前的所有历史信息,但实际上由于梯度消失等问题,RNN 很难记住太远的过去(后面会讲)。
- RNN 如何用于实际任务?
RNN 可以根据任务需求设计不同的输入/输出结构。常见模式有:
(1) 一对一(One-to-One)
- 输入一个向量,输出一个结果。
- 这其实就是普通神经网络,不是 RNN 的典型用法。
(2) 一对多(One-to-Many)
- 输入一个东西,生成一个序列。
- 例子:图像描述生成(输入一张图,输出一句描述句子)。
(3) 多对一(Many-to-One)
- 输入一个序列,输出一个结果。
- 例子:情感分析(输入一句话,判断是正面还是负面)。
(4) 多对多(Many-to-Many)
- 输入序列,输出另一个序列。
- 例子:
- 同步多对多:每个输入对应一个输出,如词性标注(每个词标一个词性)。
- 异步多对多:输入完整后再开始输出,如机器翻译(输入整个中文句子,再输出英文句子)。
- RNN 的训练:时间展开(Unrolling)
为了训练 RNN,我们通常将它沿时间维度"展开",变成一个深层网络。
例如,如果一个序列有 5 个时间步( x 1 , x 2 , . . . , x 5 x_1, x_2, ..., x_5 x1,x2,...,x5),就把 RNN 展开成 5 层,每层共享相同的权重 W h , W x W_h, W_x Wh,Wx。
这种展开方式使得我们可以用反向传播算法 来更新参数,只不过这个过程叫 BPTT(Backpropagation Through Time)。
- RNN 的局限性
尽管 RNN 很巧妙,但它有两个主要问题:
(1) 梯度消失(Vanishing Gradient)
- 在 BPTT 过程中,误差反向传播时,梯度会不断乘以小于 1 的数(因为 tanh 导数最大为 1)。
- 经过多个时间步后,梯度变得极小,导致早期时间步的参数几乎不更新。
- 结果:RNN 难以学习长期依赖(long-term dependencies)。
(2) 梯度爆炸(Exploding Gradient)
- 虽然较少见,但如果权重较大,梯度可能指数级增长,导致训练不稳定。
- 通常可通过**梯度裁剪(Gradient Clipping)**缓解。
📌 正是因为这些问题,后来发展出了更强大的变体:LSTM 和 GRU,它们通过门控机制有效缓解了梯度消失问题。
- 小结
| 特点 | 说明 |
|---|---|
| 适用数据 | 序列数据(文本、语音、时间序列等) |
| 核心机制 | 隐藏状态 h t h_t ht 在时间步之间传递信息 |
| 优势 | 能利用历史信息,适合处理顺序依赖 |
| 缺点 | 难以捕捉长期依赖,存在梯度消失/爆炸问题 |
| 后续发展 | LSTM、GRU、Transformer(现代主流) |
如果你刚接触深度学习,建议先掌握 RNN 的基本思想,再逐步学习 LSTM 和 Transformer。RNN 虽然现在在很多任务中被取代,但它的"循环"思想是理解序列建模的基础。
2、RNN应用场景
- 自然语言处理(NLP):文本生成、语言建模、机器翻译、情感分析等。
- 时间序列预测:股市预测、气象预测、传感器数据分析等。
- 语音识别:将语音信号转换为文字。
- 音乐生成:通过学习音乐的时序模式来生成新乐曲。
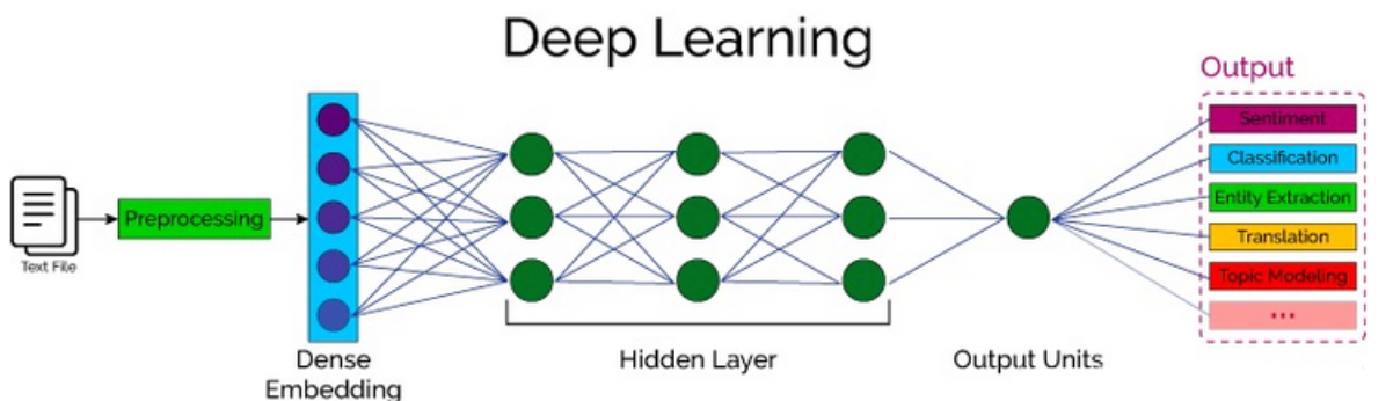
3、自然语言处理概述
自然语言处理(Nature language Processing, NLP)研究的主要是通过计算机算法来理解自然语言。
对于自然语言来说,处理的数据主要就是人类的语言,例如:汉语、英语、法语等,该类型的数据不像我们前面接触过的结构化数据、或者图像数据可以很方便的进行数值化。
NLP的目标是让机器能够"听懂"和"读懂"自然语言,并进行有效的交流和分析。
NLP涵盖了从文本到语音、从语音到文本的各个方面,它涉及多种技术,包括语法分析、语义理解、情感分析、机器翻译等。