目录
- 0.背景
- [1.Faster R-CNN](#1.Faster R-CNN)
- [2. RPN的原理](#2. RPN的原理)
- [3. RPN候选区域的训练](#3. RPN候选区域的训练)
-
- [3.1 训练样本anchor标记](#3.1 训练样本anchor标记)
- [3.2 训练损失](#3.2 训练损失)
- [4. Faster R-CNN训练](#4. Faster R-CNN训练)
- [5. 效果对比](#5. 效果对比)
0.背景
在Fast R-CNN还存在着瓶颈问题:Selective Search(选择性搜索)。
要找出所有的候选框,这个也非常耗时。那我们有没有一个更加高效的方法来求出这些候选框呢?
1.Faster R-CNN
在Faster R-CNN中加入一个提取边缘的神经网络,也就说找候选框的工作也交给神经网络来做了。这样,目标检测的四个基本步骤(候选区域生成,特征提取,分类,位置精修)终于被统一到一个深度网络框架之内。
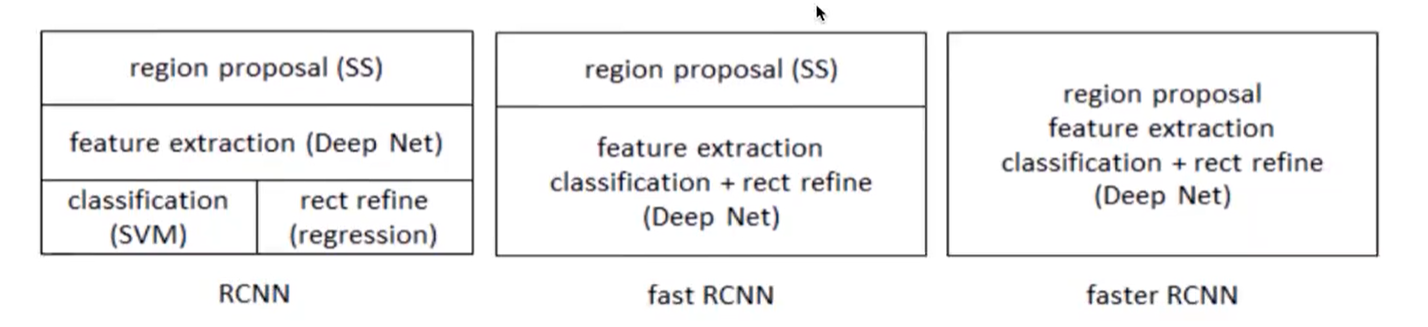
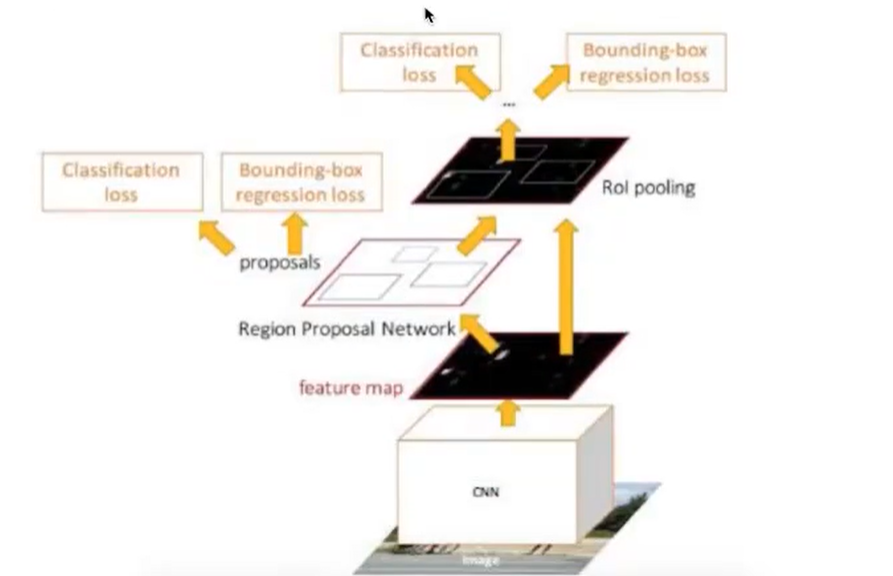
Faster R-CNN可以简单地看成是区域生成网络+Fast R-CNN的模型,用区域生成网络(Region Proposal Network,简称RPN)来代替FastR-CNN中的选择性搜索方法,结构如下:
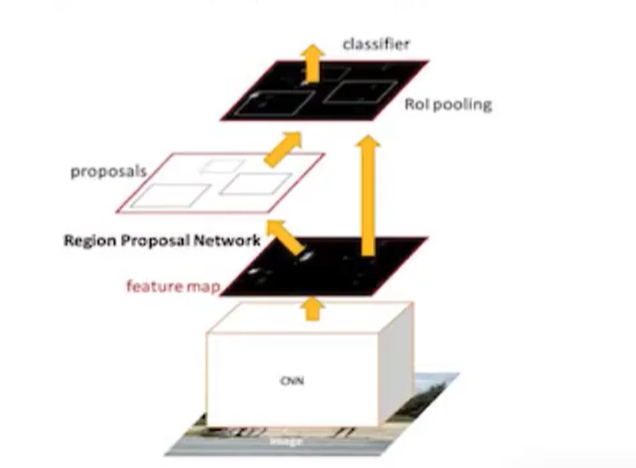
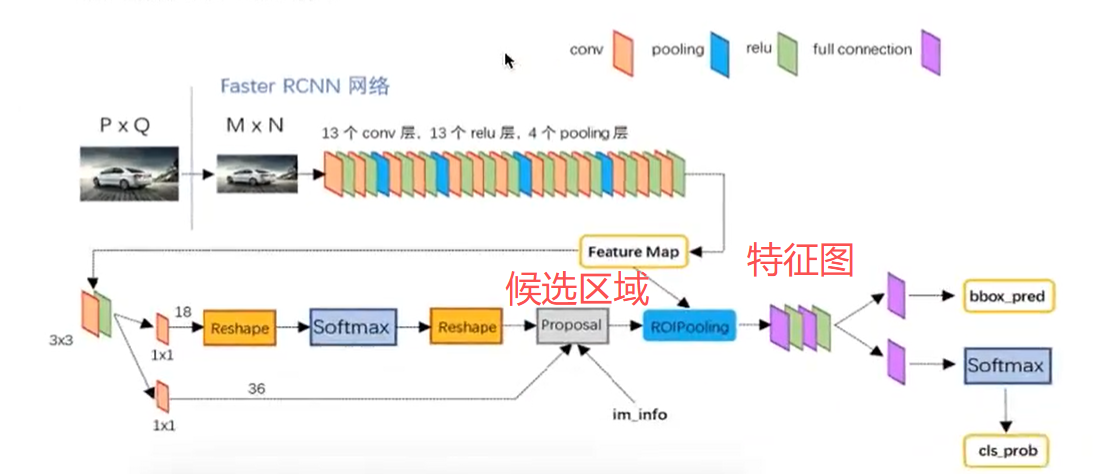
1、首先向CNN网络(VGG-16)输入任意大小图片
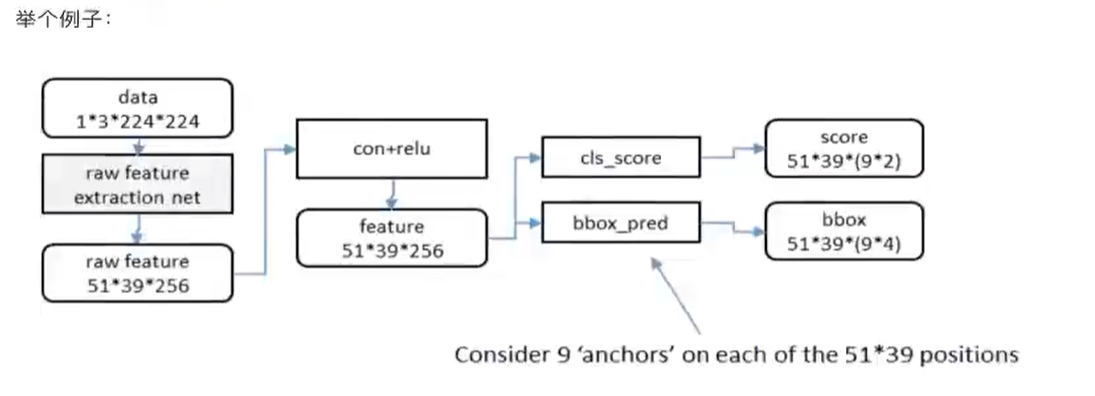
2、Faster RCNN使用一组基础的conv+relu+pooling层提取feature map。该feature map被共享用于后续RPN层和全连接层。
3、Region Proposal Networks。RPN网络用于生成region proposals,该层通过softmax判断anchors属于foreground或者background,再利用boundingboxregression修正anchors获得精确的proposals,输出其Top-N(默认为300)的区域给Rolpooling生成anchors ->softmax分类器提取fg anchors ->bboxreg回归fg anchors ->Proposal Layer生成proposals
4、第2步得到的高维特征图和第3步输出的区域建合并输入Rol池化层(类),该输出到全连接层判定目标类
5、利用proposal feature maps计算每个proposal的不同类别概率,同时bounding box regression获得检测框最终的精确位置
2. RPN的原理
RPN网络的主要作用是得出比较准确的候选区域。整个过程分为两步
- 用nxn(默认3x3=9)的大小窗口去扫描特征图,每个滑窗位置映射到一个低维的向量(默认256维),并为每个滑窗位置考虑k种(在论文设计中k=9)可能的参考窗口(论文中称为anchors)
- 低维特征向量输入两个并行连接的1x1卷积层然后得出两个部分:reg窗口回归层(用于修正位置)和cls窗口分类层(是否为前景或背景概率)
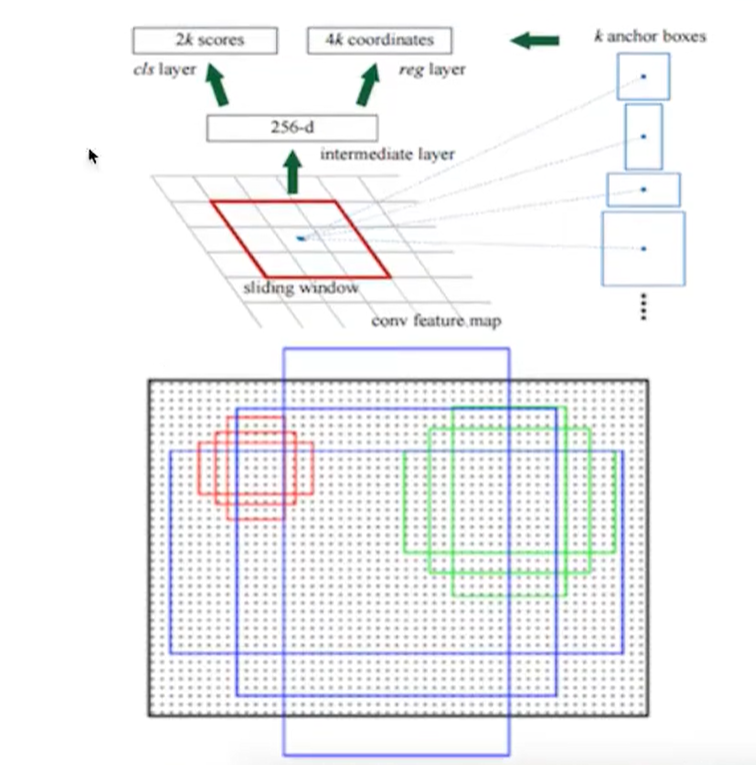
在原图中框出多尺度、多种长宽3*3卷积核的中心点对应原图上的位置,将该点作为anchor的中心点,比的anchors,三种尺度{128,256,512},三种长宽比{1:1,1:2,2:1}
3. RPN候选区域的训练
3.1 训练样本anchor标记
1.每个ground-truth box有着最高的loU的anchor标记为正样本
2.剩下的anchor/anchors与任何ground-truth box的loU大于0.7记为正样本,loU小于0.3,记为负样本
3.剩下的样本全部忽略
正负样本比例为1:3
3.2 训练损失
- RPN classification(anchor good/bad),二分类,是否有物体,是、否-
- RPNregression(anchor->proposal),回归
- 注:这里使用的损失函数和Fast R-CNN内的损失函数原理类似,同时最小化两种代价候选区域的训练是为了让得出来的 正确的候选区域, 并且候选区域经过了回归微调。
在这基础之上做Fast RCNN训练是得到特征向量做分类预测和回归预测。
4. Faster R-CNN训练
Faster R-CNN的训练分为两部分,即两个网络的训练。前面已经说明了RPN的训练损失,这里输出结果部分的的损失(这两个网络的损失合并一起训练):
Fast R-CNN classification(over classes),所有类别分类N+1
Fast R-CNN regression (bbox regression)
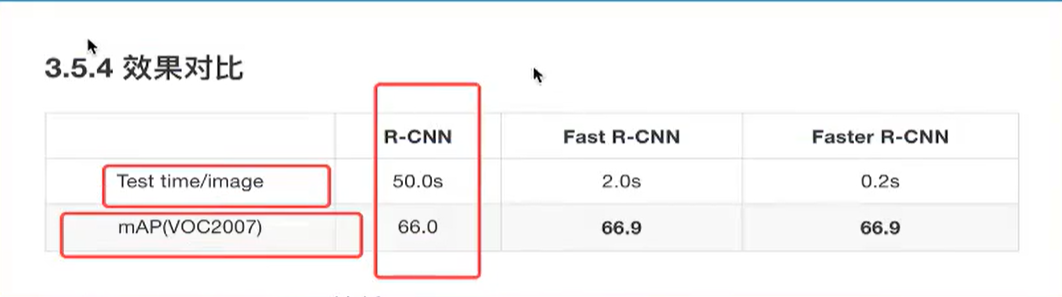
5. 效果对比