目录
[1.锚框(anchor box)](#1.锚框(anchor box))
[(4)anchor box形状的选择](#(4)anchor box形状的选择)
1.锚框(anchor box)
(1)作用
- anchor box用于从一个图像中检测多个对象
(2)使用
- anchor box的思路是预先定义两个不同形状的anchor box,把预测结果和这两个anchor box关联起来。一般来说,你可能会用更多的anchor box,可能要5个甚至更多。
(3)例子
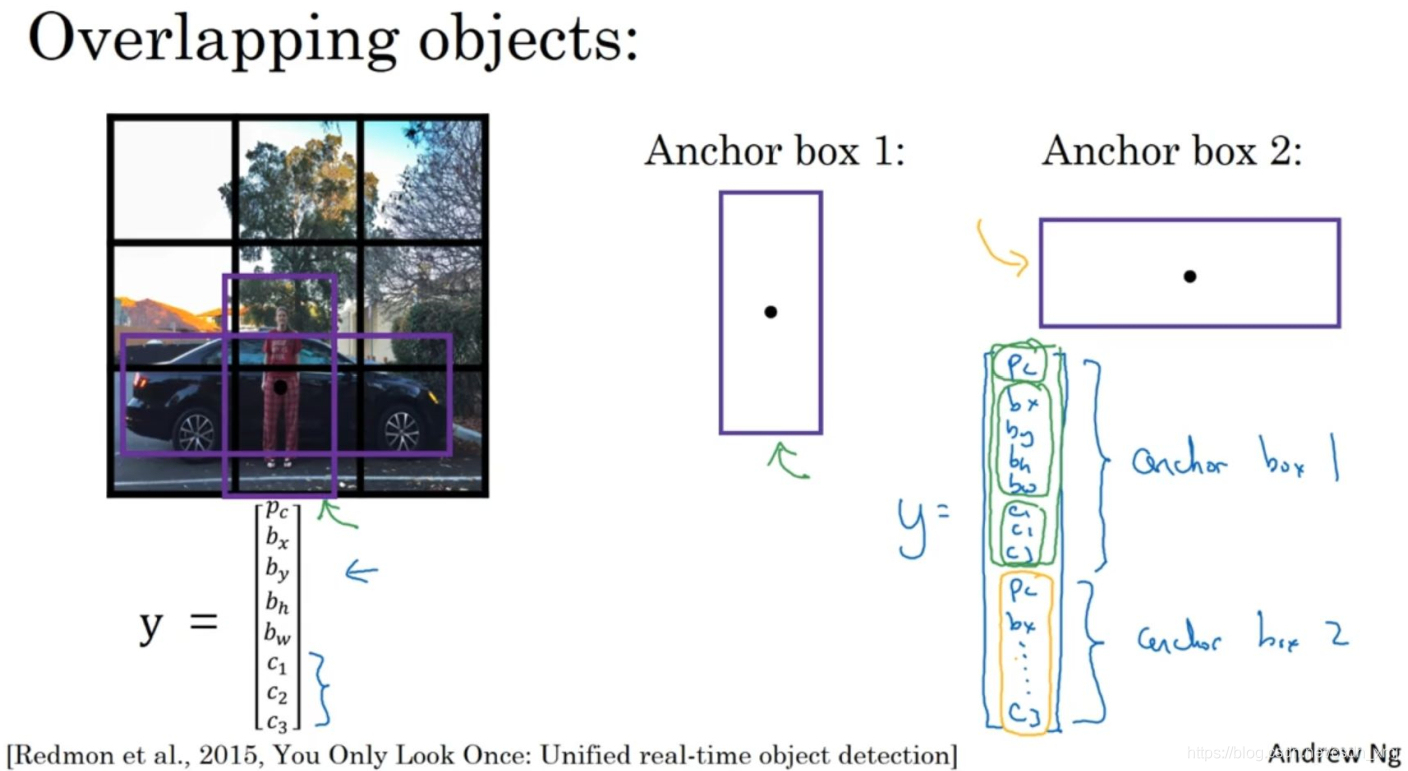
- 可以发现图中有人和车两个对象,假设我们要检测这2个对象,就要预先定义两个不同形状的anchor box,此时y的类别标签不再是图中左下角的 y,而是重复2次,变为右边的 y
- 前8个(上图中绿色方框标记的参数)是和anchor box 1关联的8个参数,后面的8个参数是和anchor box 2相关联。这下训练的识别卷积网络的输出就是3×3×16
(4)anchor box形状的选择
- 人工指定形状:人工选择5到10个anchor box形状,覆盖到检测对象的多种不同形状,
- k-平均算法(k-means)(YOLO算法中的):将几类对象形状聚类,如果我们用它来选择一组最具代表性的anchor box
2.完整YOLO算法示例⭐
- 一个检测人,车,摩托的例子。
(1)训练卷积网络
- 假设2个anchor box,图像分为3×3网格,所以网络输出为3×3×16。
(2)预测过程
- 对于这个测试图像

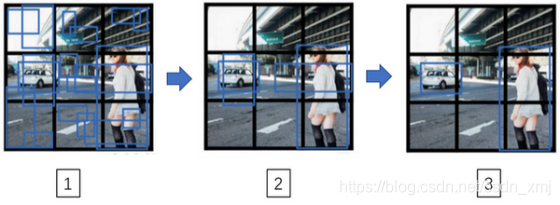
- 得到所有检测框:因为使用两个anchor box,那么对于9个格子中任何一个都会有两个预测框(注意有一些边界框可以超出所在格子的高度和宽度)
- 然后抛弃概率很低的预测框:去掉这些连神经网络都说,这里很可能什么都没有,所以你需要抛弃这些。
- 最后,非极大值抑制:有三个目标检测类别,人,汽车和摩托车,对于每个类别单独运行非极大值抑制,处理预测结果所属类别的边界框,运行三次来得到最终的预测结果。