创新算法,可以水论文
创新算法,可以水论文
算法主要实现了一种面向机械故障诊断的自适应置信度惩罚深度校准方法。
首先,算法加载西储大学轴承振动信号数据,对原始信号进行加噪处理以模拟实际工业环境中的噪声干扰,然后将信号分割为固定长度的样本段并进行零均值归一化预处理。接着,算法构建一维ResNet-18深度神经网络模型作为故障分类器,该模型专门设计用于处理时间序列振动信号。在训练阶段,算法采用自适应置信度惩罚(AdaCP)损失函数替代传统的交叉熵损失,该损失函数包含两个关键部分:标准交叉熵项用于确保分类准确性,以及基于信息熵的惩罚项用于调整模型输出分布的置信度水平。算法的核心创新在于自适应机制------将置信度区间划分为多个子区间,每个区间分配独立的惩罚系数α,这些系数根据验证集上各区间内样本的平均置信度与平均准确率之间的校准误差进行动态调整:当模型在某个置信区间过度自信时(置信度高于实际准确率),增加该区间的惩罚系数以降低模型的过度自信;当模型缺乏自信时(置信度低于实际准确率),减小惩罚系数以恢复模型的信心。这种精细化调整通过指数更新规则实现,使得模型在整个训练过程中能够自适应的平衡准确率与校准质量。训练完成后,算法在测试集上全面评估模型性能,不仅计算分类准确率,还重点评估校准质量指标包括期望校准误差、负对数似然和布里尔分数。最后,算法生成多种可视化分析图表,包括训练过程曲线、可靠性图表、混淆矩阵以及AdaCP动态调整过程图,为用户提供直观的可信度评估依据,从而建立一种用户可参与决策的可信机械故障诊断范式。
开始
│
├─数据加载与预处理阶段
│ ├─读取西储大学轴承振动信号文件
│ ├─添加高斯噪声模拟低信噪比环境
│ ├─滑动窗口分割信号为样本段
│ ├─零均值归一化处理
│ └─划分训练集、验证集、测试集
│
├─模型构建阶段
│ └─构建一维ResNet-18深度神经网络
│
├─AdaCP初始化阶段
│ ├─划分置信度区间为多个子区间
│ ├─初始化各区间惩罚系数α
│ └─设置自适应调整参数
│
├─模型训练阶段(迭代执行)
│ ├─前向传播计算预测分布
│ ├─计算自适应置信度惩罚损失
│ │ ├─计算交叉熵损失项
│ │ ├─计算信息熵惩罚项
│ │ ├─根据样本置信度确定所属区间
│ │ ├─获取对应区间的惩罚系数α
│ │ └─组合计算总损失:L = 交叉熵 - α×熵
│ ├─反向传播更新网络参数
│ ├─定期验证并调整惩罚系数
│ │ ├─在验证集上计算各区间校准误差
│ │ ├─根据校准误差更新对应区间α值
│ │ └─保持系数在合理范围内
│ └─记录训练指标
│
├─模型测试阶段
│ ├─在测试集上进行预测
│ ├─计算分类准确率
│ ├─计算校准质量指标(ECE, NLL, Brier Score)
│ └─生成可靠性分析数据
│
├─结果可视化阶段
│ ├─绘制训练历史曲线
│ ├─绘制可靠性图表
│ ├─绘制AdaCP动态调整过程
│ └─绘制混淆矩阵
│
├─模型保存阶段
│ └─保存训练好的模型及参数
│
└─结束详细算法步骤:
第一步:准备机械振动信号数据。从西储大学轴承数据集加载四种不同健康状态的振动信号文件,包括正常状态、滚珠故障、内圈故障和外圈故障。为模拟真实工业环境,向原始信号添加指定信噪比的高斯噪声。采用滑动窗口方法将连续振动信号分割为固定长度的样本段,确保每个样本包含足够的故障特征信息。对每个样本进行零均值归一化处理,消除幅度变化影响。最后将全体样本随机划分为训练集、验证集和测试集,确保各类别样本比例合理。
第二步:构建深度神经网络模型。设计并实现一维版本的ResNet-18网络结构,该网络包含初始卷积层、批归一化层、多个残差块序列、全局平均池化层和全连接分类层。网络专门适配一维振动信号输入,通过多层次特征提取学习故障的深层表征。
第三步:初始化自适应置信度惩罚机制。将置信度范围零到一均匀划分为多个子区间,每个区间对应一个独立的惩罚系数。所有区间初始使用相同的惩罚系数值。设置自适应调整的关键参数,包括初始惩罚强度、调整敏感系数和最大允许惩罚值。
第四步:执行自适应训练过程。在训练循环中,首先对训练批次进行数据增强操作,包括随机缩放、拉伸和裁剪,提升模型泛化能力。前向传播计算样本的预测概率分布,根据样本对真实标签的置信度确定其所属的置信区间,获取对应的惩罚系数。计算自适应损失函数,该函数由标准交叉熵项减去惩罚系数乘以预测分布的信息熵组成。通过反向传播算法更新网络权重参数。定期在验证集上评估模型,计算每个置信区间内样本的平均置信度与平均准确率之间的差异作为校准误差,根据误差方向和大小按指数规则调整对应区间的惩罚系数:对于过度自信区间增大惩罚,对于缺乏自信区间减小惩罚。持续迭代直至训练轮次完成。
第五步:全面评估模型性能。在独立测试集上运行训练完成的模型,收集所有样本的预测标签和置信度分数。计算总体分类准确率评估模型判别能力。通过期望校准误差量化模型置信度校准程度,该指标衡量置信度与准确率在不同置信区间的一致性。计算负对数似然评估概率预测质量,计算布里尔分数评估概率预测的准确性。同时生成可靠性图表数据,展示各置信区间的置信度与准确率对应关系。
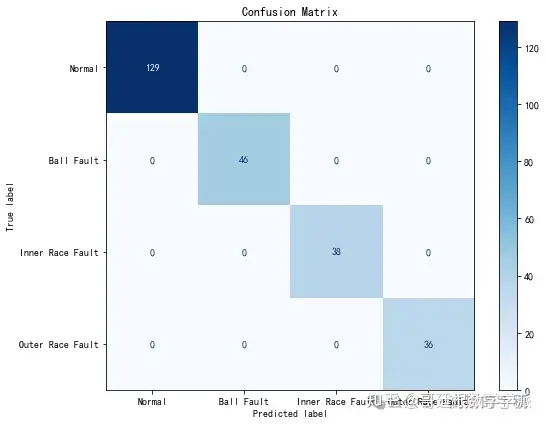
第六步:生成可视化分析结果。绘制训练过程中损失和准确率的变化曲线,监控模型收敛情况。绘制可靠性图表,直观展示模型校准效果,理想情况下置信度与准确率应对角线对齐。绘制自适应惩罚系数的动态调整过程,展示各置信区间惩罚系数的演化轨迹。绘制混淆矩阵,分析各类别间的误判情况。
第七步:保存完整模型系统。将训练好的网络权重参数、自适应惩罚系数历史、训练过程记录和测试评估结果打包保存,形成完整的可信故障诊断模型系统,便于后续部署和应用。
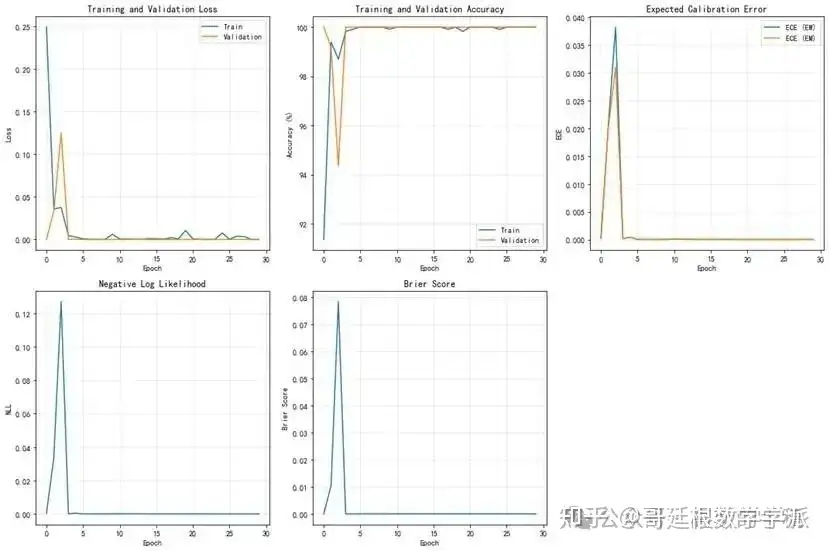
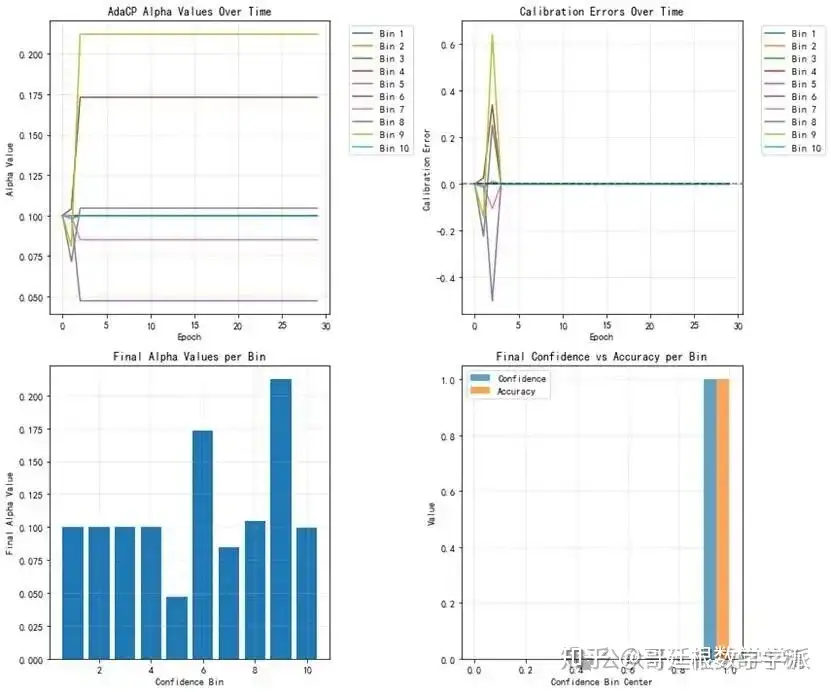
表现:
高准确率:训练、验证和测试集准确率都接近100%
完美校准:
ECE(期望校准误差)为0.0000,接近完美
NLL(负对数似然)和Brier Score都非常低
表明模型不仅准确,而且置信度估计也很准确
AdaCP有效工作:
α值在不同置信区间有不同的调整(从0.047到0.212)
这表明AdaCP确实在自适应地调整不同区间的惩罚强度
参考文章:
面向可信机械故障诊断的自适应置信度惩罚深度校准算法(Pytorch) - 哥廷根数学学派的文章 -
https://zhuanlan.zhihu.com/p/1984895480384214659