
在深度学习(尤其是计算机视觉)的开发过程中,我们经常面临这样的需求:
- "这个特征图里,有多少像素的值超过了 0.5?"
- "我想把连续的置信度分数映射成离散的等级(高/中/低)。"
- "在这个 Batch 的分割 Mask 中,每一类的像素点各有多少?"
为了解决这些问题,PyTorch 提供了三个看似相似、实则各司其职的函数:torch.bucketize、torch.bincount 和 torch.histogram。很多人容易混淆它们,或者在只需要简单计数时误用了复杂的直方图函数。本文将从底层逻辑、函数关系到实战场景,带你彻底梳理这三个函数。
概念速览
我们可以用三个角色来比喻这三个函数:
torch.bucketize(寻址员):负责"定位"。它不关心总数,只告诉你每个元素属于哪个区间。torch.bincount(点票员):负责"计数"。它只处理整数,负责统计每个整数 ID 出现了多少次。torch.histogram(统计局):负责"宏观概览"。它是前两者的集大成者,直接把连续数据变成统计分布。
功能介绍
torch.bucketize ------ 离散化映射
它的核心作用是将连续的浮点数映射为离散的索引:
- 输入:任意数值张量。
- 核心参数:
boundaries(一维单调递增序列)。 - 输出:与输入形状相同的
Int64张量(存储的是边界的索引)。
加入边界是 [0, 10, 20]:
- 输入
5-> 落入[0, 10)-> 返回索引1 - 输入
25-> 大于20-> 返回索引3(越界)
python
import torch
boundaries = torch.tensor([0.0, 3.0, 5.0])
values = torch.tensor([1.0, 3.0, 6.0])
# right=False: boundaries[i-1] < input[m][n]...[l][x] <= boundaries[i]
# right=True: boundaries[i-1] <= input[m][n]...[l][x] < boundaries[i]
# 1.0, 3.0 在 (0.0, 3.0] -> index 1
# 6.0 在 5.0 之后 -> index 3
indices = torch.bucketize(values, boundaries)
# 结果: tensor([1, 1, 3])
print(indices)应用场景:
- Embedding Lookup 的前置步骤、将置信度分级。
- 特征量化中,对特征基于算好的量化点进行量化处理。
torch.bincount ------ 整数高效计数
它是 PyTorch 中处理非负整数统计的高效工具。
- 输入:必须是 1D 非负整数张量。
- 输出:1D 张量,长度默认为
max(input) + 1。 - 核心参数:
minlength:强制输出长度至少为 N。防止因为某个 Batch 缺少某类数据导致张量形状不固定。weights:如果指定,它计算的不再是次数,而是对应位置权重的累加和。
python
data = torch.tensor([1, 1, 3, 1])
# 统计频次
# 0出现0次, 1出现3次, 2出现0次, 3出现1次
counts = torch.bincount(data, minlength=5)
# 结果: tensor([0, 3, 0, 1, 0])
print(counts)应用场景:
- 语义分割计算 mIoU(统计混淆矩阵)
- 计算加权平均值。
这里要注意与torch.unique的区别。两者的核心区别就在于"位置"与"数值"的对应关系:
torch.bincount(稠密/直接映射):- 位置即数值:输出张量的第 i i i个位置(索引),专门用来存整数 i i i出现的次数。
- 填补空缺:如果你的输入只有
[1, 100],它必须生成一个长度为 101 的向量。为了存那个100,它被迫把中间的 2~99 全部填 0。 - 内存隐患:如果数据中有个极大值(比如 ID=1,000,000),哪怕只有一个数据,它也会申请一百万长度的数组,非常浪费内存。
torch.unique(稀疏/压缩映射):- 只存存在的:它不关心数值对应的索引位置,而是返回两个数组:
values(有什么数)和counts(出现了几次)。 - 紧凑:对于输入
[1, 100],它只返回values=[1, 100]和counts=[1, 1],完全没有中间的"空窗期"。
- 只存存在的:它不关心数值对应的索引位置,而是返回两个数组:
所以整体而言,
- 如果是分类任务(类别 0-10),数据稠密且范围固定 用
bincount(极快)。 - 如果是用户ID统计(ID可能是 9527),数据稀疏且范围巨大 ,用
unique(省内存)。
torch.histogram ------ 端到端直方图
这是最直观的统计工具。
- 输入:浮点数张量。
- 输出:
hist(频次) 和bin_edges(边界)。 - 特点:它内部其实隐式地执行了"分桶"和"计数"两个步骤。
python
data = torch.randn(1000)
# 将数据分为 10 个区间统计
hist, edges = torch.histogram(data, bins=10)
# tensor([ 4., 14., 64., 131., 194., 216., 199., 112., 53., 13.])
print(hist)
# tensor([-3.1851, -2.5927, -2.0003, -1.4079, -0.8154, -0.2230, 0.3694, 0.9619,
# 1.5543, 2.1467, 2.7391])
print(edges)应用场景:
- 数据分布的可视化:查看特征、 Loss 或梯度的分布情况。
三者关系的本质:A + B ≈ C
这三个函数之间存在着深层的推导关系:
Histogram ≈ bincount ( bucketize ( Input ) ) \text{Histogram} \approx \text{bincount}(\text{bucketize}(\text{Input})) Histogram≈bincount(bucketize(Input))
- 先用
bucketize把连续值变成离散的桶索引。 - 再用
bincount统计这些索引出现的次数。 - 这就等于
histogram的结果。
可视化验证案例:学生成绩分级
为了证明这一点,我们模拟一个"学生成绩统计"的任务:将 0-100 分的成绩分为 E, D, C, B, A 五个等级。
python
import matplotlib.pyplot as plt
import numpy as np
import torch
# 设置随机种子保证可复现
torch.manual_seed(42)
# ==========================================
# 1. 数据准备
# ==========================================
# 模拟 1000 个学生的成绩,符合正态分布,均值 75,标准差 12
scores = torch.randn(1000) * 12 + 75
scores = torch.clamp(scores, 0, 100) # 截断在 0-100 分之间
# 定义分数段边界 (5个区间需要6个边界)
# E: [0, 60), D: [60, 70), C: [70, 80), B: [80, 90), A: [90, 100]
boundaries = torch.tensor([0.0, 60.0, 70.0, 80.0, 90.0, 100.0])
grade_names = ["E (<60)", "D (60-70)", "C (70-80)", "B (80-90)", "A (90+)"]
# ==========================================
# 2. 方法 A: Bucketize + Bincount
# ==========================================
# A1. bucketize: 确定每个分数属于哪个桶 (返回索引)
# right=False 表示左闭右开 [ ),这是常用的逻辑
# 注意: bucketize 可能返回 0 (小于第一个边界) 或 len (大于最后一个边界)
# 在此案例中,因为我们要模拟 Histogram 的 bin 逻辑,通常期望索引范围是 1 到 len(boundaries)-1
# 为了对齐,我们做一点简单的索引调整逻辑
bin_indices = torch.bucketize(scores, boundaries, right=False) # 左闭右开
# 修正索引:bucketize 如果值 >= 0 且 < 60,会返回索引 1 (因为 0是第一个边界)
# bin_indices 的值域主要会在 1, 2, 3, 4, 5 对应五个区间
# 我们希望 0-60 是第0个桶。所以通常 index - 1。
bin_indices = torch.clamp(bin_indices, 1, len(boundaries) - 1) - 1
# A2. bincount: 统计每个桶里有多少人
# minlength=5 保证即使没人得 A 也能显示 0
counts_from_bincount = torch.bincount(bin_indices, minlength=len(boundaries) - 1)
print(f"方法A (Bucketize+Bincount) 计数: {counts_from_bincount}")
# ==========================================
# 3. 方法 B: 直接法 (Histogram)
# ==========================================
counts_from_hist, _ = torch.histogram(scores, bins=boundaries)
print(f"方法B (Histogram) 计数: {counts_from_hist}")
# 验证两者是否相等
assert torch.allclose(counts_from_bincount.float(), counts_from_hist), (
"统计结果不一致!"
)
# ==========================================
# 4. 可视化对比
# ==========================================
plt.figure(figsize=(15, 6))
# 子图 1: 原始数据的分布 (Bucketize 的作用对象)
plt.subplot(1, 3, 1)
plt.title("Step 1: Raw Data & Boundaries (Bucketize Input)")
plt.hist(scores.numpy(), bins=50, color="lightgray", alpha=0.7, label="Raw Scores")
for b in boundaries:
plt.axvline(b, color="r", linestyle="--", alpha=0.5)
plt.xlabel("Score")
plt.ylabel("Frequency")
plt.legend()
plt.text(
10, 5, "Bucketize determines\nwhich interval\neach point belongs to", fontsize=9
)
# 子图 2: 离散化后的索引 (Bincount 的作用对象)
plt.subplot(1, 3, 2)
plt.title("Step 2: Discretized Indices (Bincount Input)")
# 这里展示 bin_indices 的值
unique_ids, counts = torch.unique(bin_indices, return_counts=True)
plt.bar(unique_ids.numpy(), counts.numpy(), color="skyblue", edgecolor="black")
plt.xticks(range(5), grade_names, rotation=45)
plt.xlabel("Grade Class (Index)")
plt.ylabel("Count")
plt.text(-0.5, max(counts) * 0.9, "Bincount simply counts\nthese integers", fontsize=9)
# 子图 3: 最终直方图 (Histogram 的直接输出)
plt.subplot(1, 3, 3)
plt.title("Step 3: Final Histogram (Result)")
plt.bar(
range(5), counts_from_hist.numpy(), color="salmon", alpha=0.8, edgecolor="black"
)
plt.xticks(range(5), grade_names, rotation=45)
plt.xlabel("Grade Class")
plt.ylabel("Count")
plt.text(-0.5, max(counts) * 0.9, "Histogram does\nboth steps at once", fontsize=9)
plt.tight_layout()
plt.show()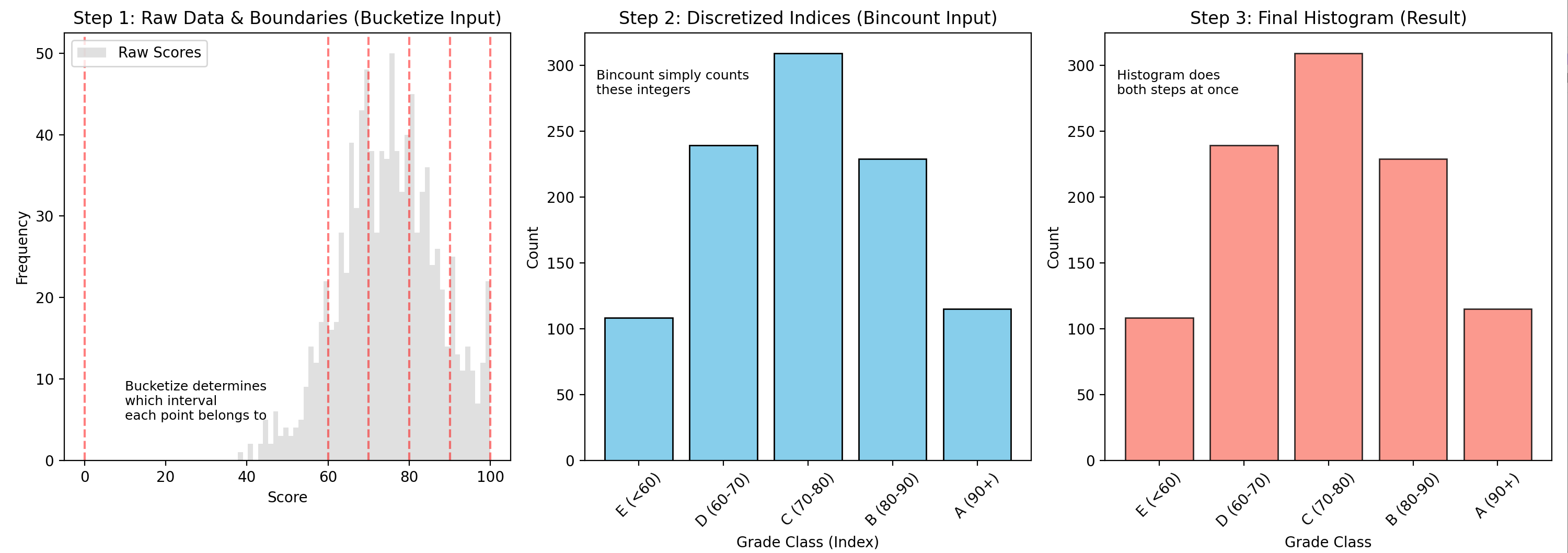
该用哪个?
工程中,选择哪个函数取决于实际数据类型和最终目的:
| 你的需求 | 推荐函数 | 理由 |
|---|---|---|
| 数据是连续的 (Float),我想看分布图 | torch.histogram |
最简单,一行代码出结果。 |
| 数据是连续的,但我需要知道"谁在哪* | torch.bucketize |
histogram 丢弃了空间位置信息,而 bucketize 保留了每个元素的索引。 |
| 数据是整数 (类别ID/Mask),我想统计个数 | torch.bincount |
速度最快,专为离散整数设计。 |
| 计算"加权"平均值或总和 | torch.bincount(weights=...) |
利用 weights 参数可以轻松实现 Scatter Add 的功能。 |
| 数据非常稀疏 (ID=1000000) | torch.unique |
bincount 会产生巨大的全 0 向量,浪费显存;unique 只存有的值。 |