近期,注意力机制+强化学习这个方向迎来了重磅突破。苏黎世联邦理工学院机器人系统实验室在《Science Robotics》(IF=26.1)中提出了一种创新的控制框架:
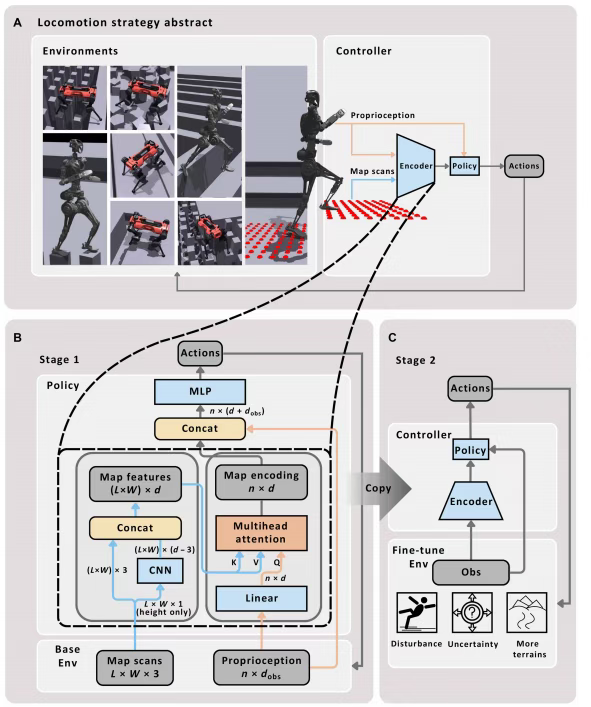
该框架通过结合强化学习和多头注意力机制,让机器人在面对不同类型地形时,能做到精准判断和灵活适应,从而实现100%障碍穿越成功率!
值得一提的是,当前注意力机制+强化学习这个方向已从方法创新阶段进入了性能优化和应用拓展阶段,而这篇顶刊成果,正是该趋势在机器人控制领域的完美范例!对于想做这个方向的论文er说,属于必看文章!
当然这方向还有不少值得参考的成果,我已经帮大家筛选并整理了11篇高质量的文章,包含顶会顶刊,附代码,先学习一下前人的思路再入手,能高效地找到自己的idea。
全部论文+开源代码需要的同学看文末
ARiADNE: A Reinforcement learning approach using Attention-based Deep Networks for Exploration
**关键词:**Reinforcement Learning、Attention Mechanism、Autonomous Robot Exploration、Graph Neural Networks、Non-Myopic Planning
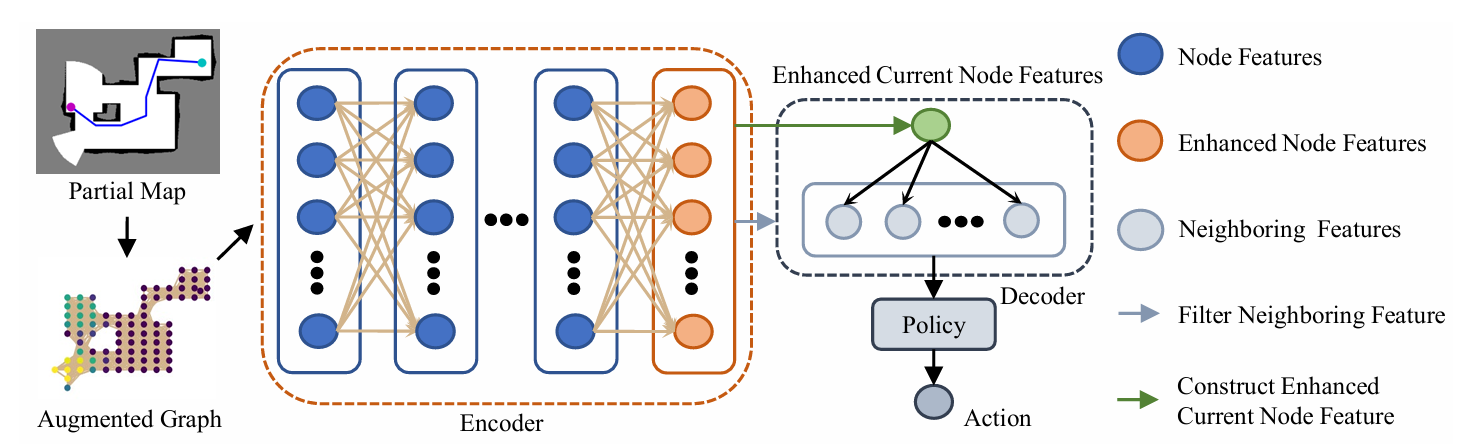
**方法:**论文提出的 ARiADNE 方法,通过基于注意力机制的深度网络(政策网络与评论网络)学习部分地图中不同区域的多尺度依赖关系并隐式预测探索潜在收益,结合软演员 - 评论者(SAC)强化学习算法,实现自主机器人探索任务中实时、非近视的路径规划,平衡地图利用与新区域探索的权衡。
创新点:
-
设计基于多头注意力的地图编码模块,结合机器人本体感受信息,自动聚焦可行落脚点,实现地形感知的可解释性与精准性。
-
提出两阶段强化学习训练 pipeline,先在基础地形上初始化地图编码学习,再引入复杂地形与不确定性微调,兼顾泛化能力与鲁棒性。
-
构建端到端的整体控制框架,无需依赖模型预测控制等上层规划模块,直接将感知信息映射为关节级动作,统一了学习型方法的鲁棒性与模型型方法的精准性。
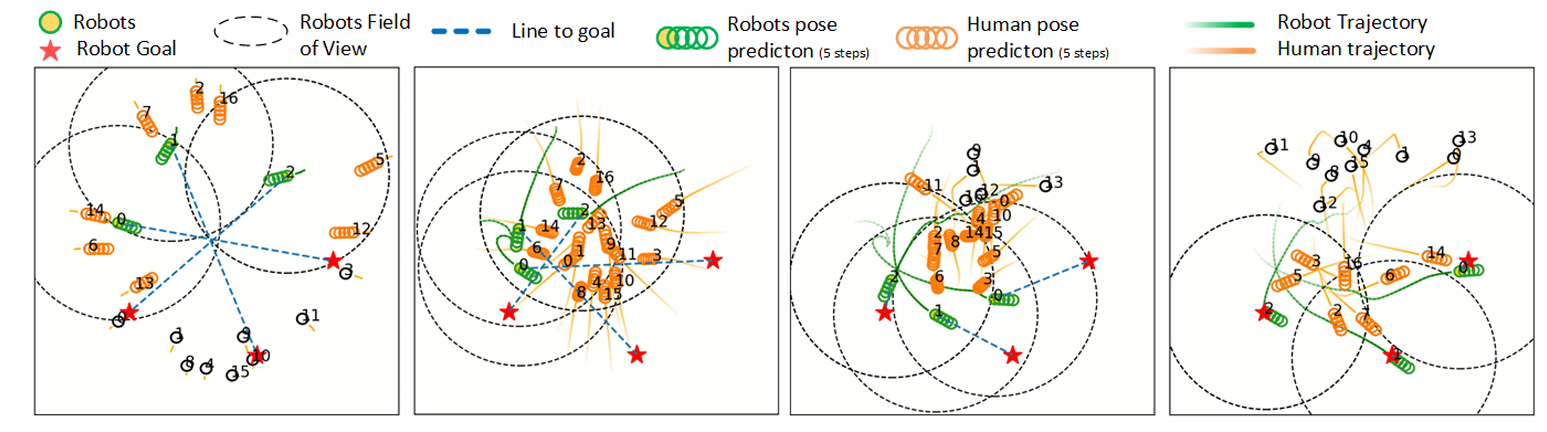
Attention Graph for Multi-Robot Social Navigation with Deep Reinforcement Learning
**关键词:**Multi-Robot Social Navigation、Graph Neural Network、Attention Mechanism、Deep Reinforcement Learning、Centralized Training Decentralized Execution
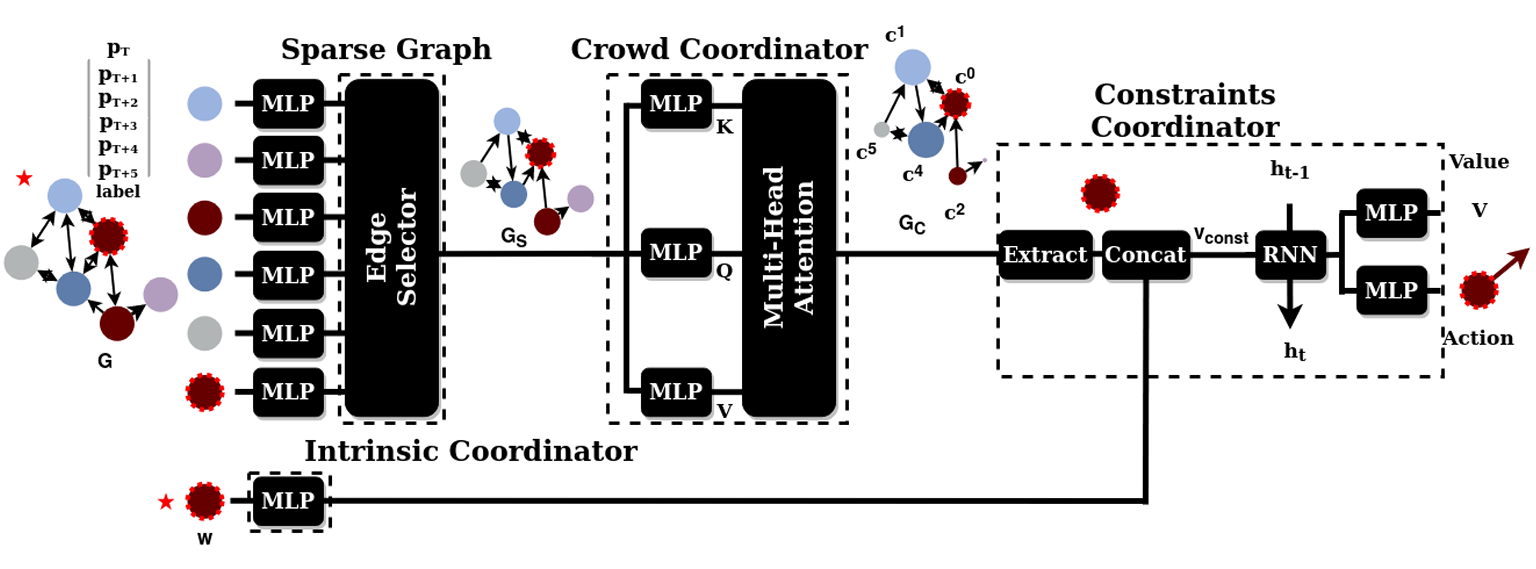
**方法:**论文提出的 MultiSoc 方法,通过边缘选择器和人群协调器两个结合注意力机制的图神经网络提取实体间多尺度交互特征,结合多智能体近端策略优化(MAPPO)强化学习算法,实现多机器人在拥挤环境中的社会感知导航与隐式协调。
创新点:
-
设计双图神经网络架构,结合注意力机制构建实体交互图,精准捕捉机器人与人类、机器人之间的多尺度依赖关系。
-
引入可定制密度元参数,通过边缘选择器动态调整交互图稀疏度,适配不同拥挤程度的导航场景。
-
基于集中式训练分布式执行范式,结合MAPPO强化学习算法,实现多机器人隐式协调与社会感知导航。
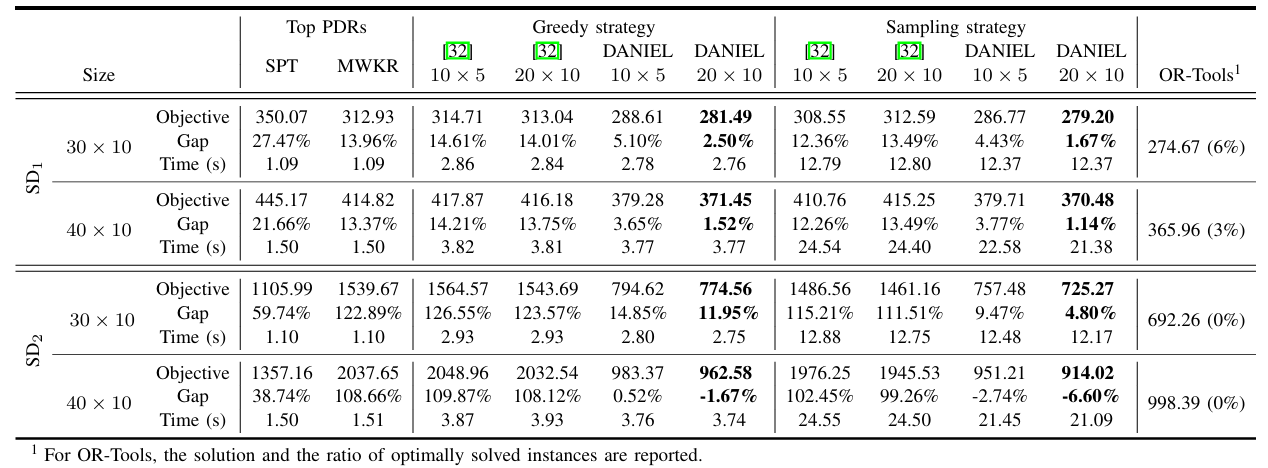
Flexible Job Shop Scheduling via Dual Attention Network Based Reinforcement Learning
**关键词:**Flexible Job Shop Scheduling 、Deep Reinforcement Learning、Self-Attention Mechanism、Dual-Attention Network、End-to-End Learning
**方法:**论文提出的 DANIEL 方法,通过由操作消息注意力块和机器消息注意力块组成的双注意力网络(DAN)精准提取柔性作业车间调度中操作与机器的复杂关联特征,结合近端策略优化(PPO)强化学习算法,构建端到端学习框架,同步解决操作排序与机器分配问题,实现高效调度决策。
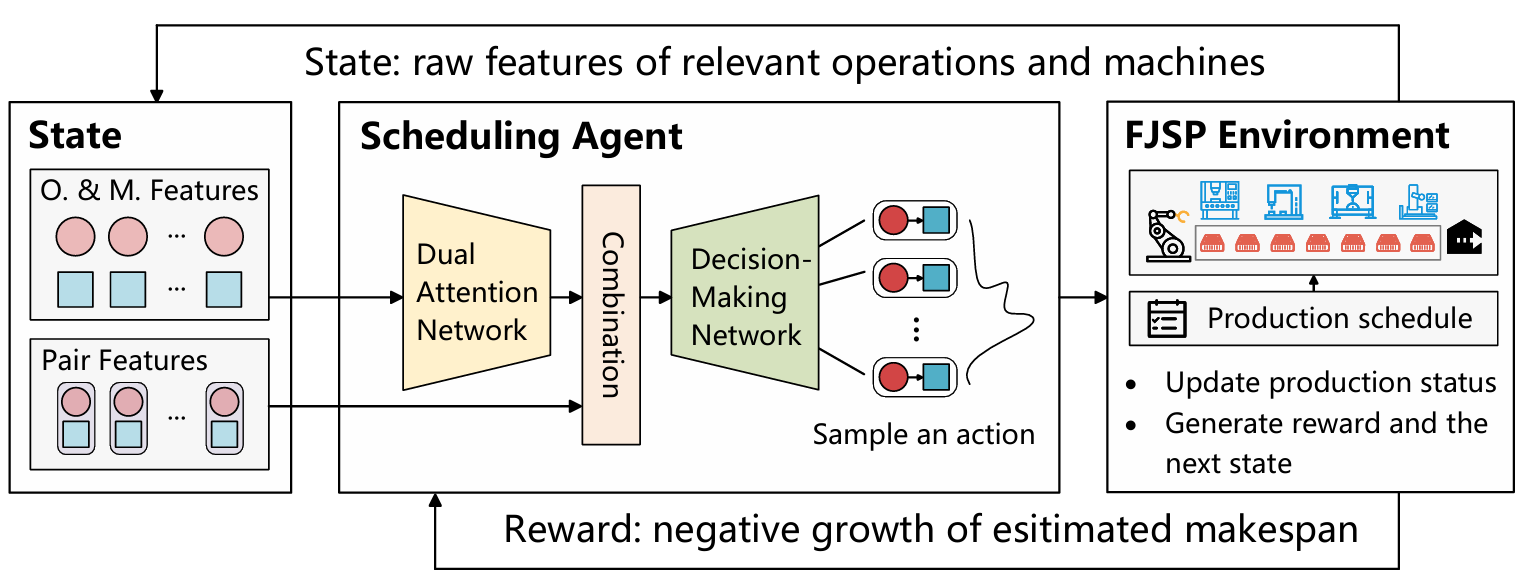
创新点:
-
设计双注意力网络,分别捕捉操作间的优先级约束和机器间的动态竞争关系,精准提取调度关键特征。
-
提出紧凑状态表示,仅保留决策相关的操作和机器信息,随调度推进动态缩减状态空间。
-
构建端到端强化学习框架,基于PPO算法同步优化操作排序与机器分配,兼具泛化能力与调度效率。
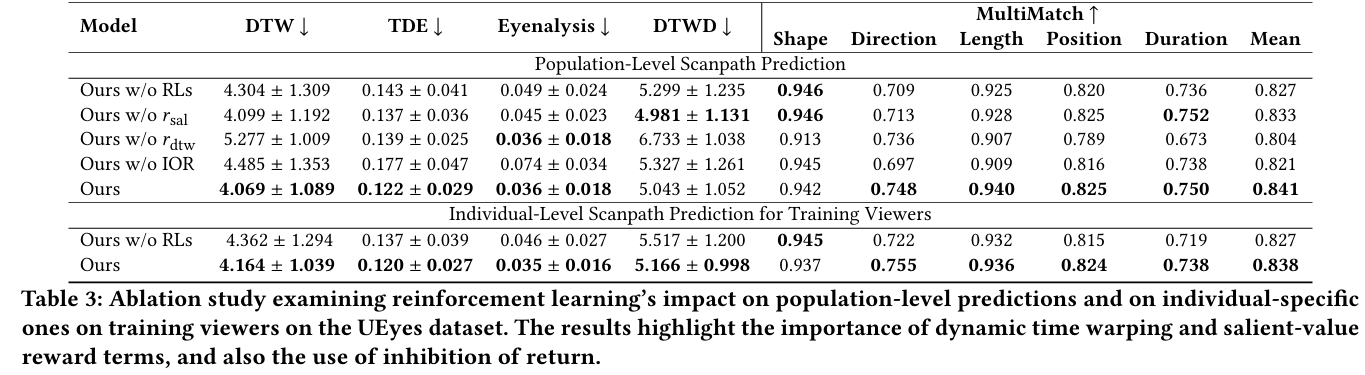
EyeFormer: Predicting Personalized Scanpaths with Transformer-Guided Reinforcement Learning
**关键词:**EyeFormer、Transformer、Reinforcement Learning、Personalized Scanpath Prediction、Policy Network
**方法:**论文提出的 EyeFormer 方法,以 Transformer 为策略网络(借助注意力机制捕捉注视序列的长程依赖),结合强化学习(REINFORCE 算法)优化含非可微目标的奖励函数,实现个体和群体层面的扫描路径预测,可输出注视位置与时长等完整时空信息,还支持少量样本驱动的个性化预测。
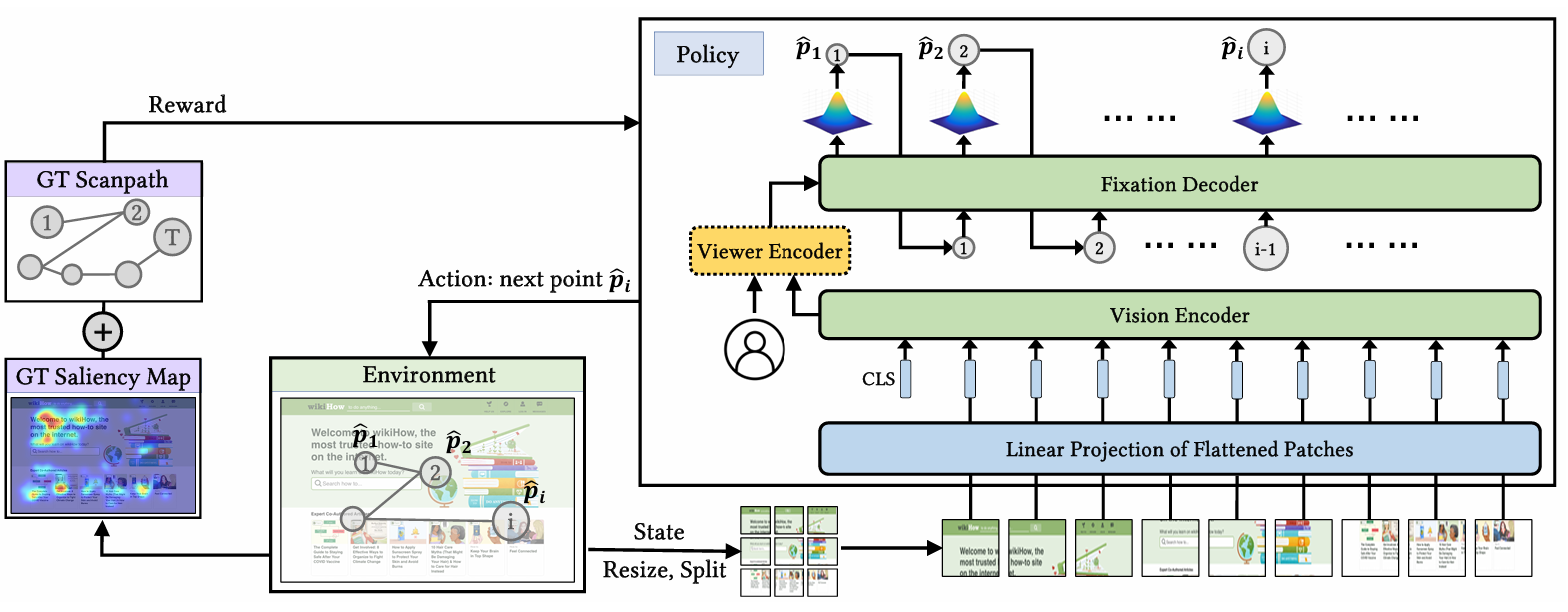
创新点:
-
采用Transformer+强化学习框架,通过注意力机制捕捉注视序列长程依赖,结合REINFORCE算法优化非可微奖励,精准预测扫描路径的时空特征。
-
支持个性化扫描路径生成,利用 viewer 编码器学习个体注视偏好,仅需少量样本即可适配特定用户。
-
统一适配GUI和自然场景,通过融合DTWD和显著性奖励及IOR机制,兼顾扫描路径的顺序合理性与区域显著性。
关注下方《学姐带你玩AI》🚀🚀🚀
回复"222"获取全部方案+开源代码
码字不易,欢迎大家点赞评论收藏