introduce
目标:输入目标线稿、参考彩色图(同一角色、但姿态/尺度/视角可能差很多)、(可选)用户给的匹配点,输出:彩色结果,要求颜色与身份细节跟参考图一致 ,并且结构跟线稿一致。
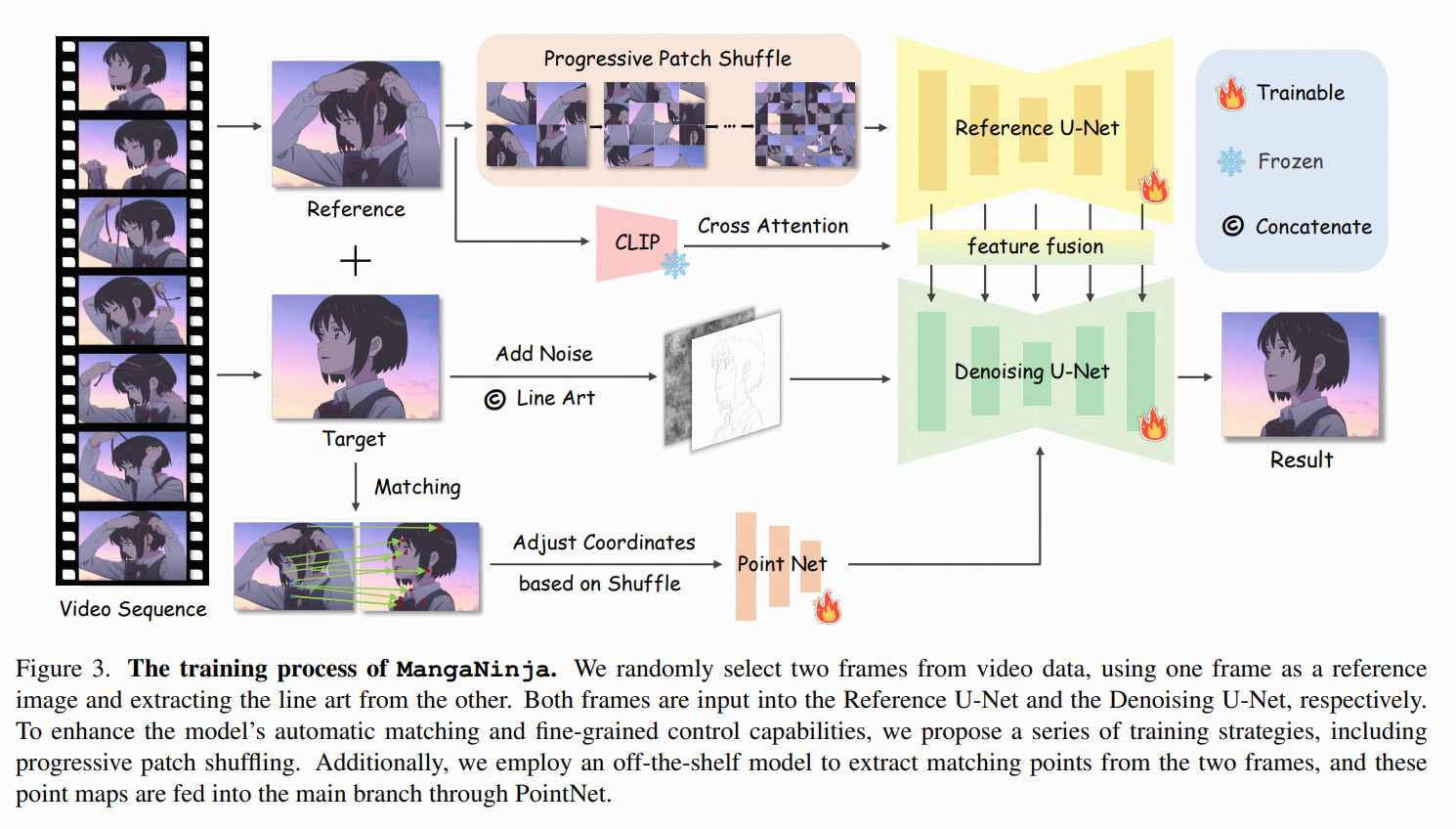
训练对:anime video:同一角色跨帧身份一致,但会出现缩放、姿态变化、旋转、遮挡、细节缺失。从同一个视频片段里随机抽两帧 ,一帧当参考,另一帧当目标;对目标帧用现成线稿提取器得到 line art。训练时再用 LightGlue 从两帧里提对应点对,作为"伪标注"的稀疏对应监督。
method
核心架构:双分支(Reference U-Net + Denoising U-Net)
MangaNinja 本质是一个 latent diffusion 的改造:用 VAE 把图压到 latent,再在 latent 空间做扩散去噪。论文里明确参考图先编码成 4 通道 latent 再送入 Reference U-Net。
2.1 Reference U-Net
作用:把参考图"拆开揉碎"成多层特征。
作者说 line art 上色"细节要求很严",难点在于要把参考图编码得足够细粒度,所以引入额外的 Reference U-Net 专门抽参考图多层特征。可以理解为:multi-level feature bank。
2.2 Denoising U-Net
做扩散去噪,但条件不是文本,而是"线稿 + 参考图 + 点"主干去噪网络。输入条件有三类:
-
线稿结构条件。 把单通道线稿复制成 3 通道后,也走 VAE 压到 latent;然后与噪声 latent 拼接 ,最终输入变成 8 通道 (噪声 latent 4ch + 线稿 latent 4ch)。
(也试了把线稿走 ControlNet,效果差不多,但为省资源选了拼接方案。)
-
"参考图语义提示"条件:CLIP 图像 embedding 替代文本 embedding。 直接把原本扩散模型里的 text embedding 换成 CLIP encoder 提取的 image embedding。把"提示词"变成了"参考图的全局语义/风格提示",但真正的精细对齐靠下面的注意力融合与点引导。
-
点引导条件:PointNet 产生的点特征
这个是 3.3 的重点,后面展开。
参考特征怎么注入主干去噪(注意力层 K/V 拼接)
很多 reference-guided 方法会在 cross-attn 上做文章,但 MangaNinja 的关键点是:
把 Reference U-Net 与 Denoising U-Net 在对应层的 self-attention里做融合------
具体做法:在 Denoising U-Net 的某个 self-attn 层,用目标分支的 Qtar去同时 attend:
-
目标自己的 Ktar,Vtar
-
参考分支的 Kref,Vref
写成论文公式(Eq. 1)就是把 K/V 直接 concat:
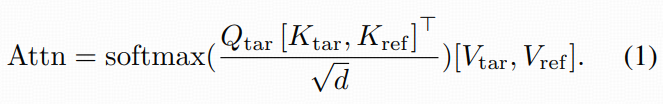
-
同一层里,目标 token 不仅能看自己,还能看参考分支对应层的 token。
-
多层(multi-level)都这么注入,就等于给了一个"从粗到细"的参考检索通路。
Progressive patch shuffle for local matching
(逼它学局部对应,而不是偷懒学全局风格)
观察到:线稿给的结构太强了,模型很容易只做粗全局匹配(比如整体色调/风格搬运),结果局部语义对齐学不牢,这会直接破坏"精确参考跟随"这件事。
所以提出 progressive patch shuffle:
-
把参考图切成小 patch
-
随机打乱 patch 的位置,破坏整体结构一致性
-
这样模型没法靠"整体轮廓相似"偷懒,只能学更细的局部线索(甚至像素级)去建立对应关系
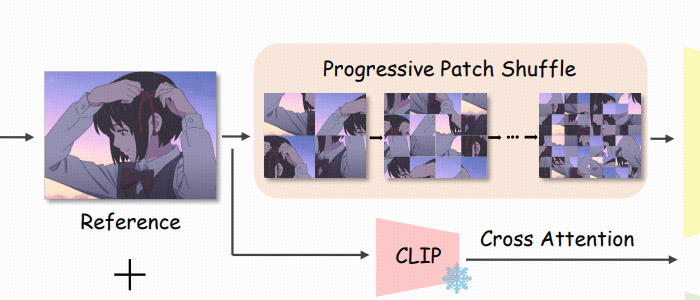
coarse-to-fine:打乱强度从弱到强,patch 网格从 2×2逐步加到 32×32。
当成"课程学习":
-
早期:还允许一些全局线索
-
后期:几乎逼着你必须会局部语义匹配
另外还配合翻转、旋转等增强,让参考与目标差异更大。
2.3 Fine-grained Point Control
细粒度点控制(PointNet + 注意力注入)
动机:哪怕有隐式对应学习,线稿仍会丢掉很多彩色细节(阴影、花纹、局部材质),导致对应歧义;而工业流程里也需要一个轻量交互方式。
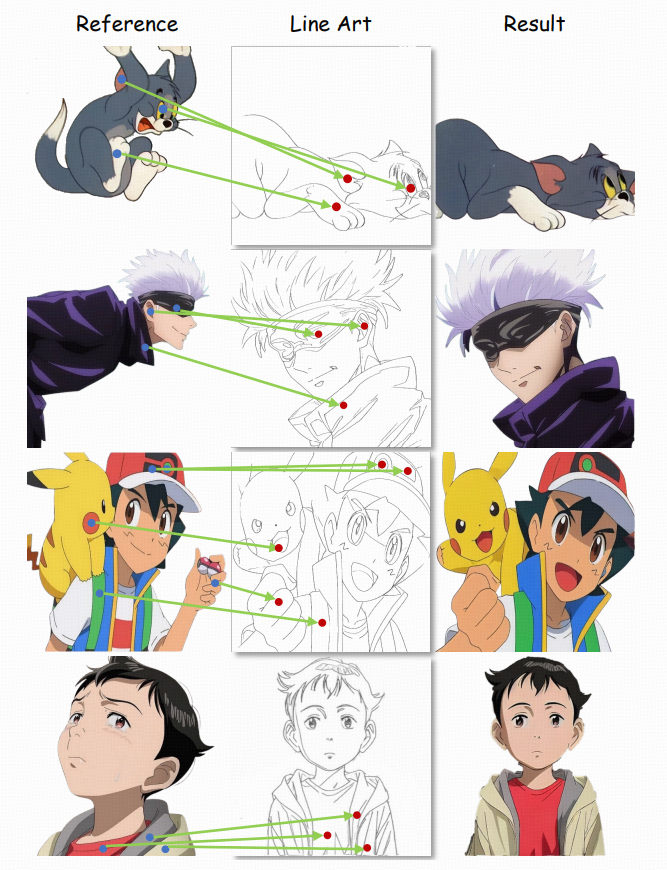
点对怎么表示:把匹配点对表示成两张与输入同分辨率的单通道点图(point maps):
-
对每一对匹配点,在参考点图与线稿点图的对应坐标上,填入相同的整数 ID(比如 1,2,3...)
-
其它位置为 0
-
训练时随机采样最多 24 对,也允许采 0 对(意味着推理时也可以完全不用点,靠自动匹配)
这等价于在空间上给模型一个"稀疏但无歧义"的锚点集合。

PointNet 编码与注入方式(Eq. 2)
作者这里的 PointNet 不是经典点云 PointNet,而是"卷积堆叠 + SiLU"把点图编码成多尺度 embedding。
然后把点 embedding 注入注意力:他们不是 concat,而是加到 Q 和 K 上(相当于对注意力相似度打偏置),公式 Eq. 2:
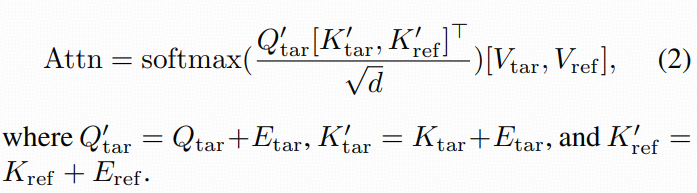
再用 Qtar′去 attend Ktar′,Kref′。
直观理解:点 embedding 会让"点附近/同 ID 的位置"在注意力里更容易互相对齐,从而把参考图的颜色细节更确定地拉到线稿对应部位。
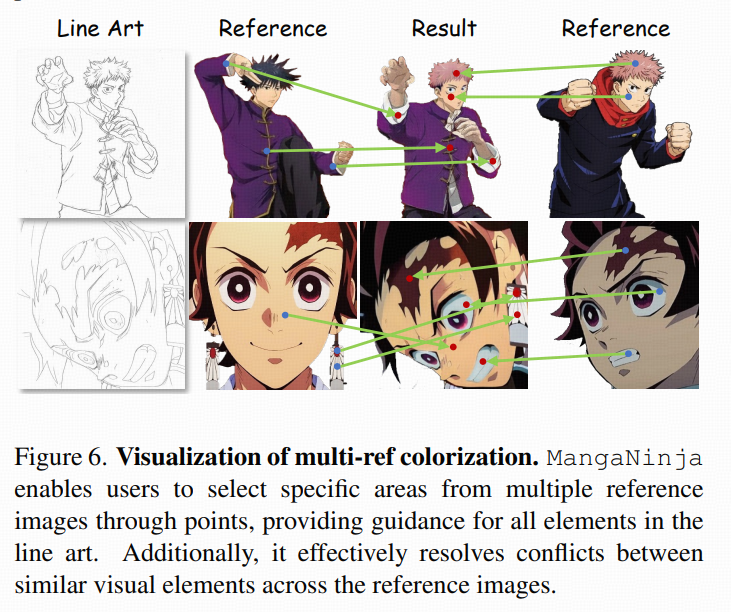
点控制与 patch shuffle 的配套:坐标要跟着 shuffle 调整
如果参考图 patch 被打乱了,那么点图的坐标也必须按同样 shuffle 规则调整,否则点对就对不上了。
训练与推理的关键策略:Condition Dropping、Multi-CFG、Two-stage Training
Condition dropping:让模型"别太依赖某一个条件"
常见的 condition dropping:
-
随机丢掉线稿条件
-
逼模型在没有线稿结构提示时,也要能从参考图重建目标图,从而提升生成能力
更重要的是对点控制的帮助:当线稿被 drop 时,点对这种稀疏但精确的信号会迫使模型学会"看到点就要对齐"。
Multi classifier-free guidance:
把"参考跟随强度"和"点控制强度"拆开调。推理时用多路 CFG,把三种预测组合起来(Eq. 3):
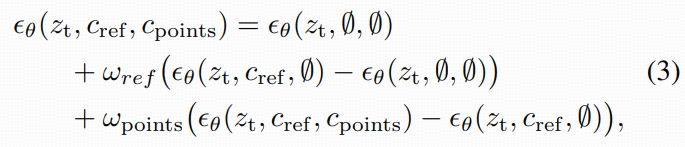
-
无条件:ϵθ(zt,∅,∅)
-
只有参考:ϵθ(zt,cref,∅)
-
参考 + 点:ϵθ(zt,cref,cpoints)
并用两个系数分别控制:ωref与 ωpoints。
-
ωref越大 → 越依赖"自动匹配 + 参考跟随"
-
想做更复杂、自动对不齐的任务 → 提高 ωpoints放大点的影响力
Two-stage training
-
第一阶段:同时对参考和点做 dropping,学会三件事:无条件生成、参考对齐、点对齐
-
第二阶段:只训练 PointNet(其他模块不动),强化 PointNet 编码点图的能力,从而更强点控
experiment