intro
动机:解决空间纠缠的问题。参考图上色通常是:输入线稿/草图(sketch)+ 一张参考彩色图(reference),希望输出的颜色/材质"像参考图",但结构/布局"像线稿"。困难在于:reference 的图像特征(尤其是 ViT/CLIP 的 token)天然带有布局、大小、对象共现等语义,当 reference 是"只有角色的立绘/大头照"时,这些语义很容易"越权",导致模型在背景里也"长出角色碎片/衣服/头发纹理",或者把角色配色污染到背景------这就是空间纠缠。
论文:让模型在注意力层面做"前景/背景分治"。
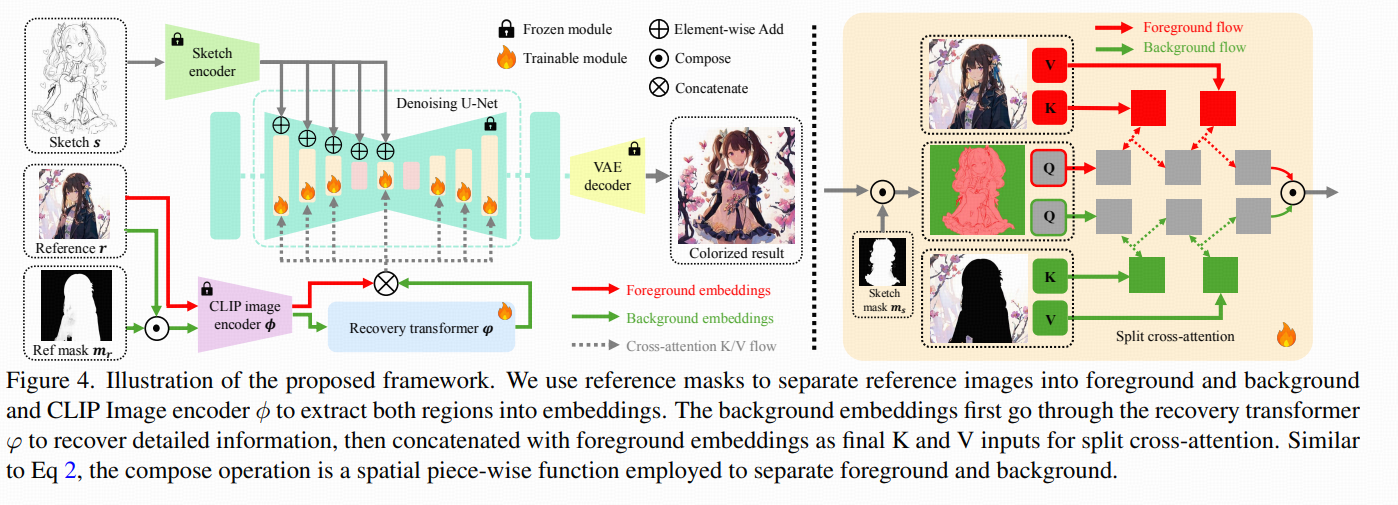
总体框架:一个"带参考 token 的 LDM",但把 Cross-Attention 改造了。
backbone 是 latent diffusion(VAE latent 空间里做 U-Net 去噪),用 OpenCLIP 的 ViT 从参考图抽取 local tokens 当作 reference embeddings,通过 cross-attention 注入到 U-Net。
关键创新:把 cross-attention 分裂成前景一套、背景一套,并且用 LoRA 让这两套参数轻量可训练。
method
前景/背景掩码用开源的动画图像分割工具自动抽取:
-
线稿的前景 mask:ms
-
参考图的前景 mask:mr
然后设阈值 tss,tsr 把像素判成前景/背景(大于阈值为前景)。等于告诉模型"哪些位置属于角色(foreground),哪些位置属于背景(background)"。
Split Cross-Attention
(真正的"分治"发生在注意力里)
传统 cross-attention 里,某个位置的特征 z 通过同一套 Wq,Wk,Wv去和同一套参考 embeddings 做注意力。
论文把它改成:同一层注意力里,前景位置走前景分支,背景位置走背景分支:
-
前景分支:用 前景 LoRA 参数 + 参考图整体 embeddings e=ϕ(r)
-
背景分支:用 背景 LoRA 参数 + 背景 embeddings eb
并且在训练时,按线稿 mask 做条件分流:
这里 W^=Wpretrained+WLoRA,也就是说原始预训练权重冻结,训练的只是 LoRA 增量。
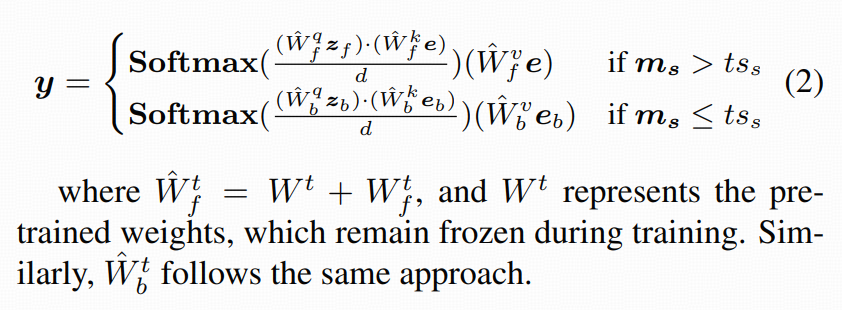
直觉上会觉得:"把背景区域裁出来提 embedding 不就完了?"------论文说不行。
原因是:前景/背景纹理、色调、细节分布差异很大 ,直接把背景 embeddings 生硬塞进背景分支,会导致结构保持/画面质量/风格化都变差。于是它加了一个可训练的 recovery transformer φ,专门"修复/适配"背景 embeddings:
-
e=ϕ(r) 来自整张 reference
-
eb=φ(ϕ(rb)),其中 rb 是 reference 的背景区域
也就是:背景不是"裁出来就用",而是"裁出来 → 过 recovery transformer 再用"。
Switchable inference mode
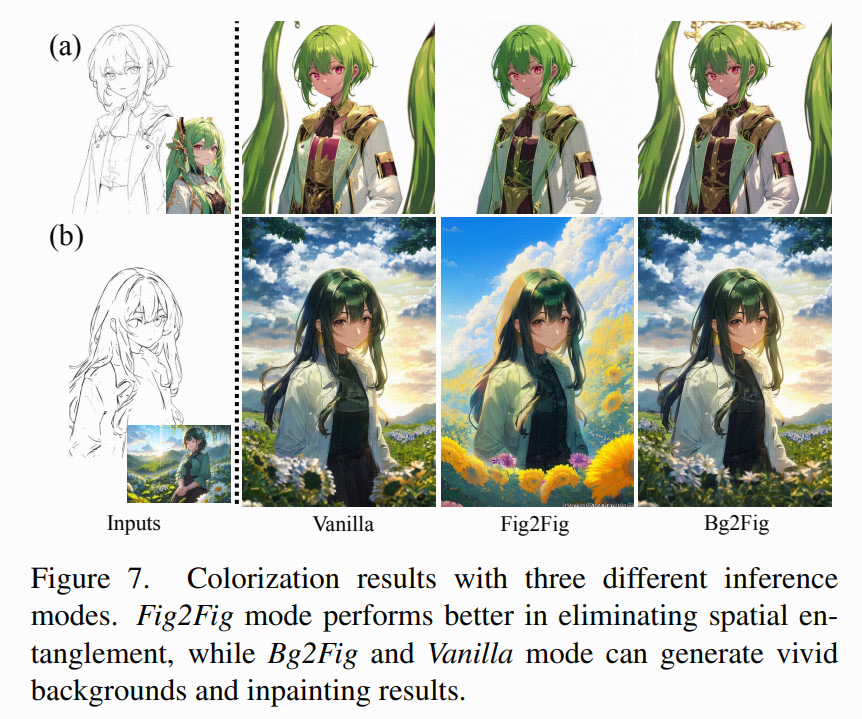
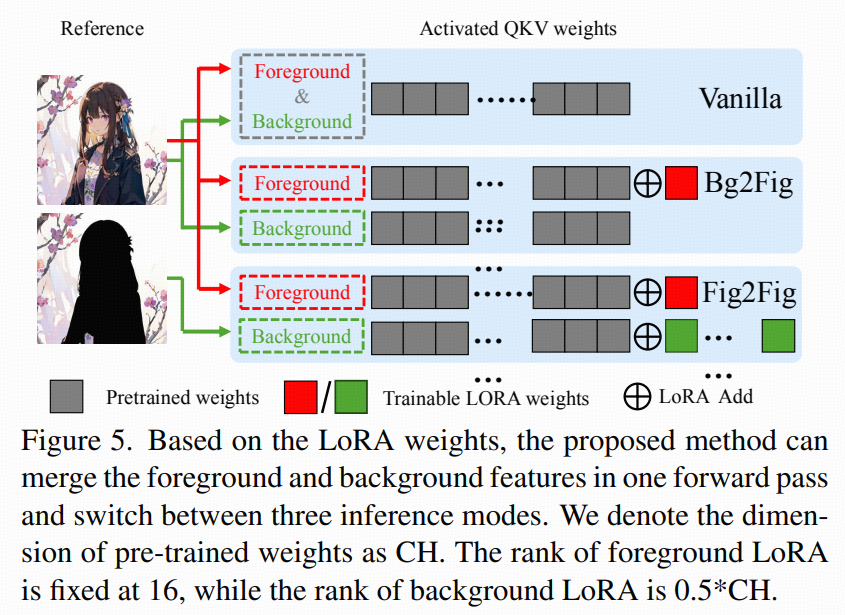
论文没有死板地要求"必须分割+必须双分支"。它设计了三种推理模式,按使用场景切换:
-
Vanilla:只用预训练 cross-attention(不开 LoRA、不用 recovery transformer)
-
适用:大多数普通情况
-
弱点:reference 是"纯角色图"时容易空间纠缠
-
-
Bg2Fig:只开"前景 LoRA"(背景主要靠模型自己生成)
-
适用:reference 背景很复杂、语义很乱,或者你根本不想抄 reference 背景,只想抄角色配色
-
这模式在角色上色上优于 Vanilla;背景生成上往往比 Fig2Fig 更自然(因为没被强行用背景 embeddings 约束)。
-
-
Fig2Fig:前景+背景 LoRA 全开 + recovery transformer,全程 mask 引导做严格分治
-
适用:figure-to-figure(参考图是角色图且背景简单)
-
优点:最能消灭空间纠缠
-
代价:对于需要"补画/大面积空白"的情况,mask 外区域可能因为缺少参考信息而表现不如另外两种。
-
LoRA 的规模设置(为什么它说"轻量",但背景 LoRA 其实不小)
论文明确给了 LoRA rank 的策略:
-
前景 LoRA rank 固定 16
-
背景 LoRA rank = 0.5×min(Dq,Dkv)(比前景大得多)
直观解释:背景风格/纹理空间更大、变化更多,给更大的低秩容量;角色颜色更"可控",rank 16 已经够用。
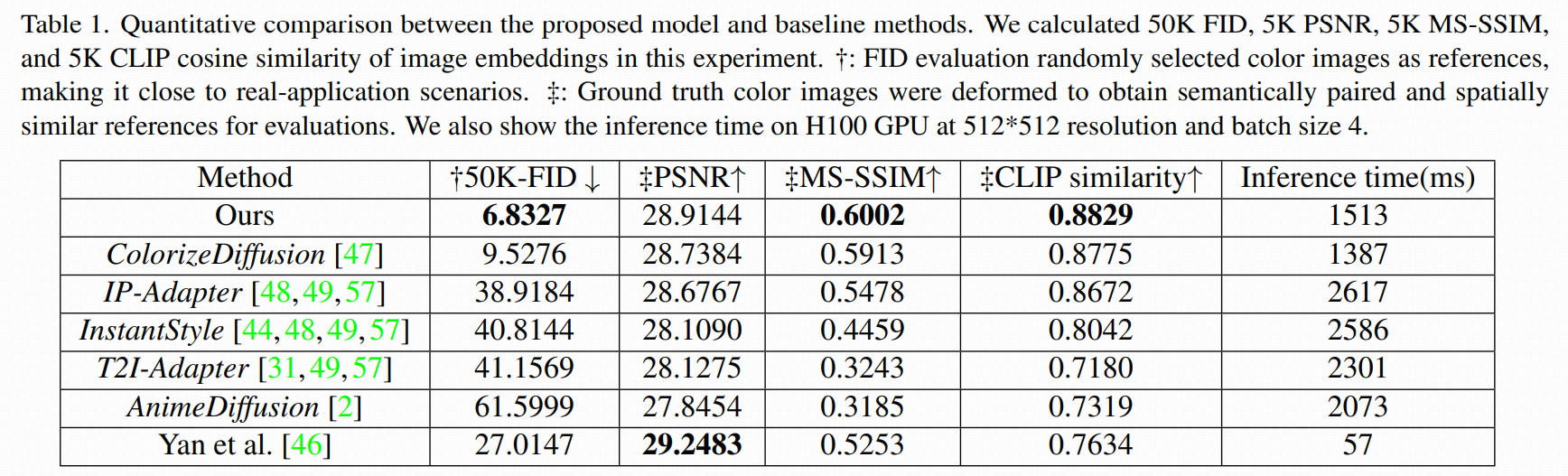
experiment
-
数据:Danbooru2021 ,构成 (sketch, color, mask) 三元组
-
训练集:4.8M 三元组
-
验证集:52,000 三元组(与训练集互斥)
-
-
训练日程:
-
先训练 U-Net + sketch encoder 6 epochs
-
冻结 backbone,再训练 recovery transformer + switchable LoRAs 3 epochs
-
-
参考输入 dropout:至少 50% reference 被丢弃(用于缓解训练/推理参考不匹配带来的偏移)