在通往通用人工智能(AGI)的征途中, 如何让机器像人类一样同时看懂画面、听懂声音,并进行连贯的视听创作,始终是多模态领域面临的巨大挑战。

如何突破视觉与听觉在物理层面的感知壁垒,实现多感官感知的协同统一?现有模型在音画同步性与任务通用性之间普遍存在难以兼顾的困境: 其一,因缺乏深度的时空融合机制, 易引发音画时空错位问题; 其二,受架构设计的固有局限 ,难以同步适配感知理解与内容生成两类核心任务。
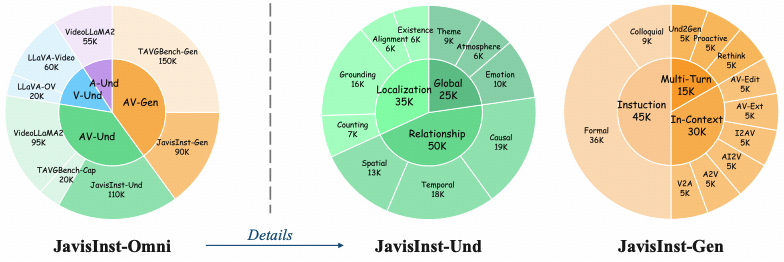
近期,新加坡国立大学联合香港中文大学发布的NeurIPS 2025 论文《JavisGPT: A Unified Multi-modal LLM for Sounding-Video Comprehension and Generation》,该研究提出了一种基于SyncFusion(时空音视频融合)的全新范式。 该研究通过构建Encoder-LLM-Decoder的统一架构,不仅实现了音频信息向视频帧的直接注入与高精度时空对齐,更打破了理解与生成任务之间的壁垒 ,通过引入JavisInst-Omni大规模指令数据集,为多模态大模型在 复杂有声视频的连贯理解与生成 领域确立了新的标尺。
打破"感-生"分离的视听鸿沟
在通用人工智能(AGI)向多模态领域纵深发展的当下,尽管大语言模型(LLM)在静态视觉-语言任务中取得了显著突破,但针对有声视频的全链路建模仍面临严峻挑战。现有的主流研究范式主要受困于以下双重技术桎梏:
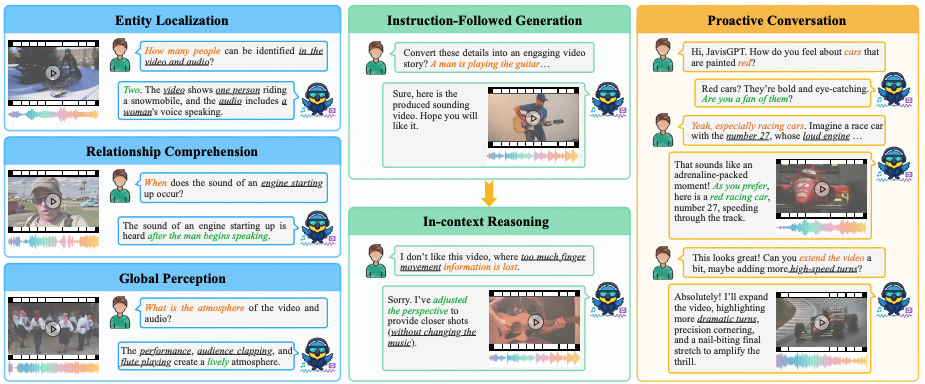
首先,模态异构性(Modality Heterogeneity)导致的时空错位。视频中的视觉帧与音频流在物理属性上存在天然差异, 传统的多模态方法往往采用松散耦合(Loose Coupling)策略 ------即简单地将视觉与听觉特征进行线性拼接。这种粗粒度的融合方式缺乏深度的时空交互机制,难以捕捉视听信号在毫秒级时间轴上的本征对齐,导致模型在处理高动态场景时,无法建立声音事件与视觉动作之间精确的因果映射。
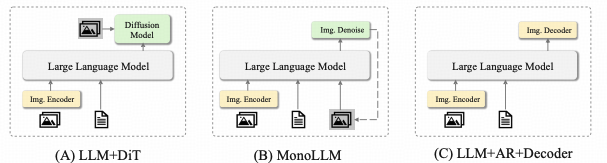
更为关键的挑战在于, 当前主流学术范式普遍面临理解与生成环节的二元割裂困境: 现有模型或局限于被动式视听问答任务(如Video-LLM系列模型),或仅能完成单向视频生成任务(如DiT模型),尚未能在统一语义空间内实现全双工(Full-duplex)视听交互功能。
此类"感知-生成分离"的架构性瓶颈,显著制约了多模态大模型在真实复杂场景下的推理与创作效能。
模型:SyncFusion 驱动的统一架构范式
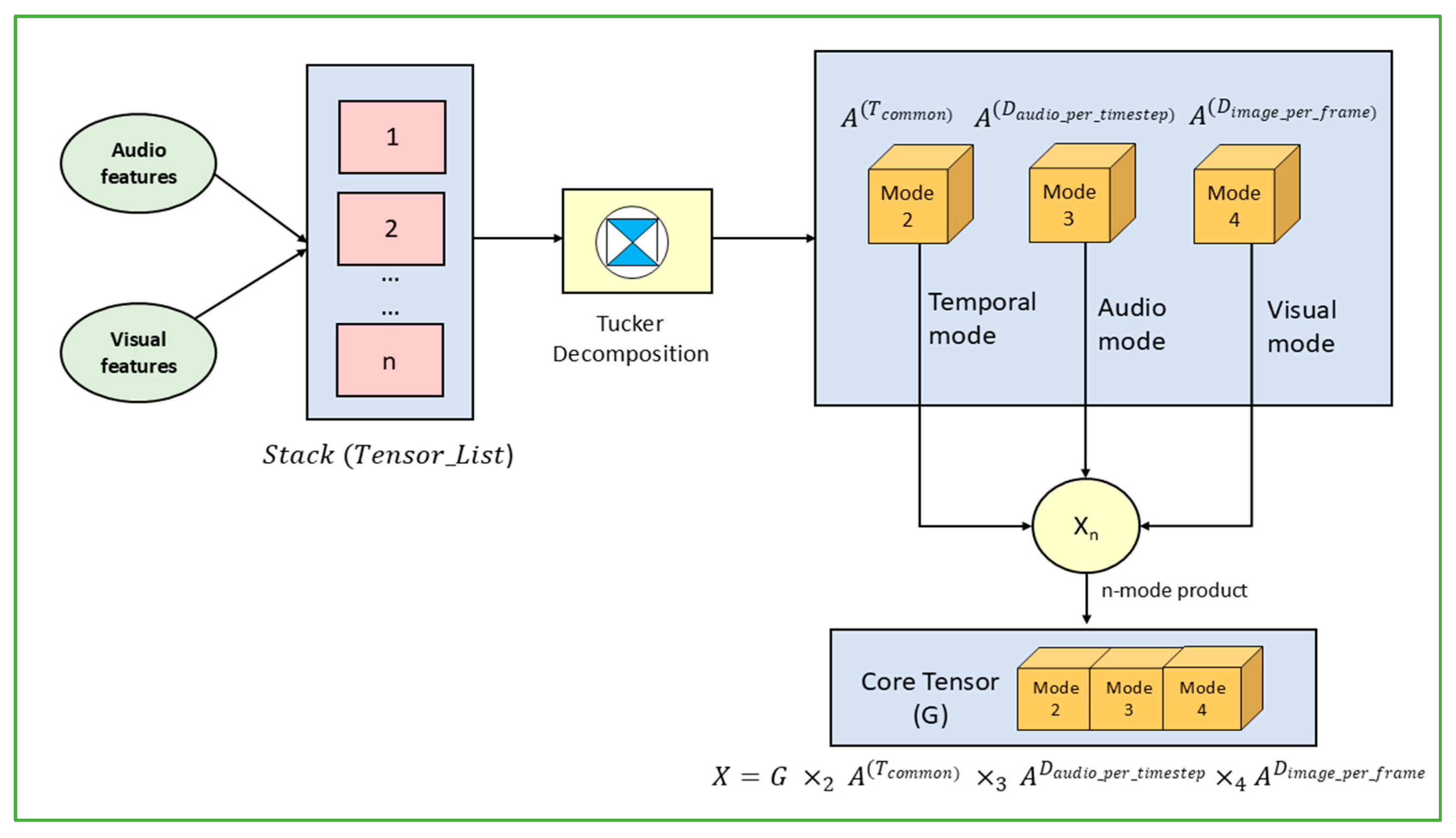
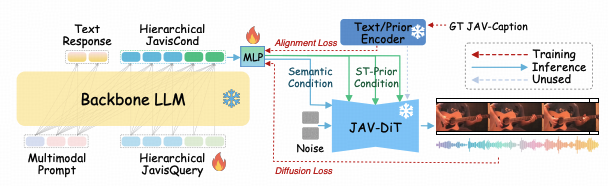
为彻底破解上述理解-生成割裂难题, JavisGPT摒弃了传统方案中视觉与语音模型简单拼接的松散架构设计,创新性地构建了全链路统一(End-to-End Unified)的Encoder-LLM-Decoder架构体系。
该架构借鉴人类大脑多模态信息处理机制,实现了感知(Encoders)-认知(LLM)-创作(Decoder)的有机串联,具体可分为三部分:
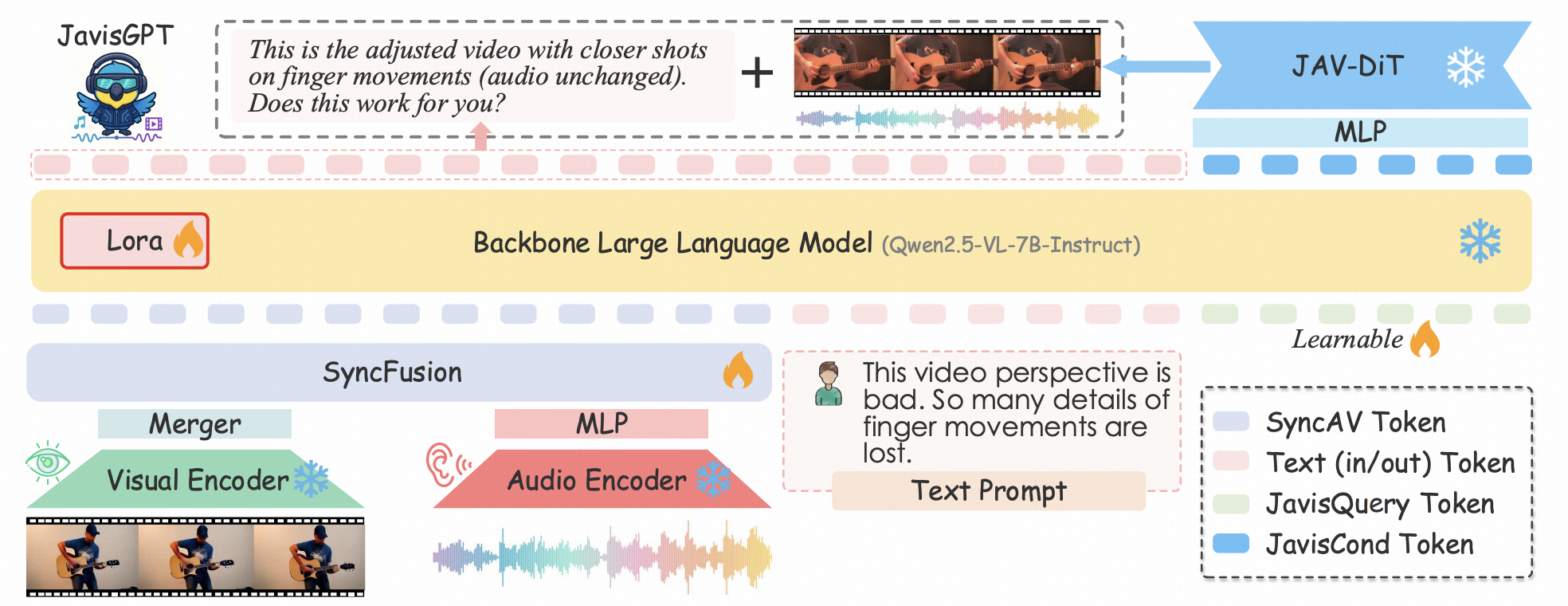
1.前端统一感知(Unified Perception): 采用Qwen2.5-VL与BEATs分别作为视觉与听觉感知接口 ,精准捕获环境中的视觉光影特征与听觉声波细节;
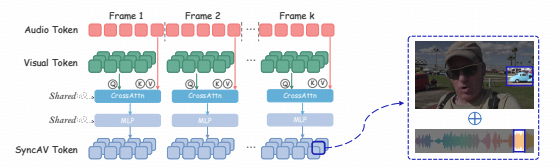
- 中枢融合认知(Cognitive Processing):区别于传统架构的粗糙特征拼接, 感知层面获取的多模态特征通过核心组件SyncFusion完成毫秒级时空精准对齐 ,随后输入LLM认知中枢进行深度语义推理;
- 后端生成创作(Generative Action):当触发创作任务时,LLM输出特定控制信号(JavisQuery),驱动后端JAV-DiT生成器完成视觉画面绘制与听觉声音合成的协同任务。
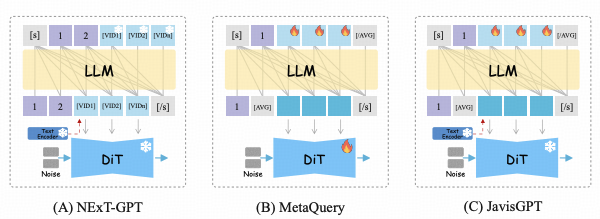
这一环环相扣的闭环架构设计, 使JavisGPT成为首个在单一网络权重下,同时具备高保真多模 态感知与高一致性生成能力的通用多模态大模型。

三阶段渐进式训练
为了让模型逐步掌握从基础感知到复杂创作的能力,研究设计了严谨的三阶段训练管线:

- 多模态预训练: 让模型学会"看"和"听",对齐基础特征;
- 音视频微调: 强化模型对同步性的理解,确保生成的视频口型对得上、撞击声卡得准;
- 大规模指令微调: 引入JavisInst-Omni数据集,激发模型遵循复杂人类指令进行推理和交互的能力。
实验:多维基准下的性能新高
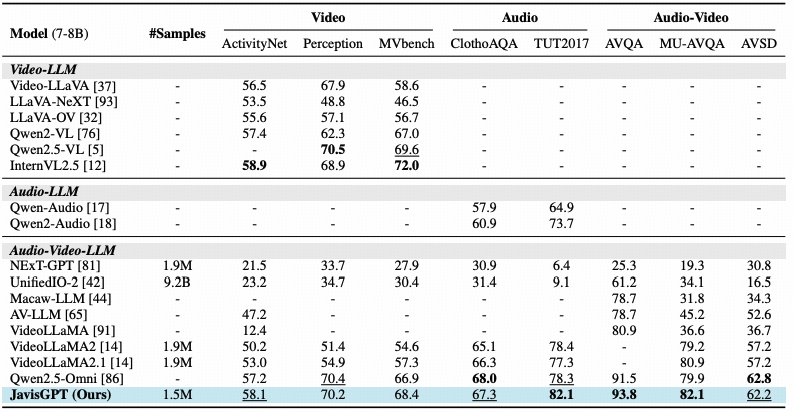
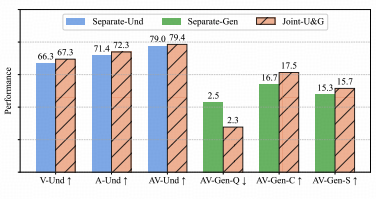
为了验证JavisGPT的有效性,研究团队在多个权威基准上进行了严苛的测试。 实验结果表明,该模型在理解与生成两个维度上均取得了SOTA性能。
理解与生成的双重SOTA
在视听理解任务中,得益于Qwen2.5-VL强大的视觉编码与SyncFusion的精准对齐, JavisGPT在处理复杂的声音定位与语义推理问题时,准确率显著优于现有的Video-LLM基线模型。
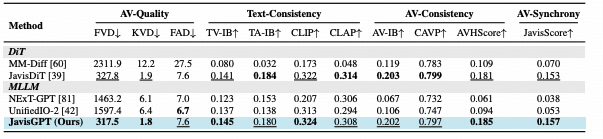
而在生成任务上,模型展现出了卓越的多模态一致性(Cross-modal Consistency)。 无论是生成画面的保真度,还是声音与动作的同步性,JavisGPT 均确立了新的性能标杆。
效率与性能的双重最优解
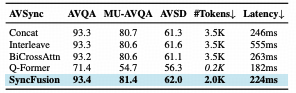
在多模态融合策略中,计算开销与模态对齐精度的权衡取舍,始终是制约该领域技术落地的核心瓶颈。
实验数据表明,SyncFusion 融合机制成功 突破了 高精度必然伴随高推理延迟的技术桎梏。 在音频 - 视频问答任务中,该机制可实现与BiCrossAttn方法持平的93.4%准确率;与此同时,依托其高效的Token压缩策略,模型推理延迟由555ms锐减至 224ms,且在显存占用层面亦表现出显著优势。上述结果充分验证,借助交叉注意力机制将音频特征向视频帧特征空间进行注入,是实现多模态特征高效时空对齐的最优技术路径。
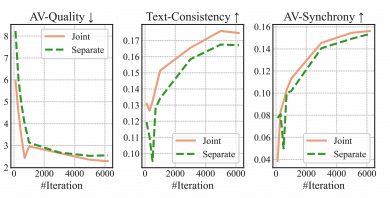
训练动力学分析:收敛速度与稳定性
为了进一步探究统一架构的优化特性,研究团队可视化了训练过程中的性能曲线。 结果显示,相比于分离式架构,联合训练不仅在最终性能上更高,在收敛速度上也展现出明显优势。
特别是在音画同步性和文本一致性两个维度上,联合训练的曲线始终包裹着分离训练的曲线。这表明,在统一的语义空间内进行多任务学习,能够有效规避局部最优解,帮助模型更快地掌握复杂的多模态交互规律。
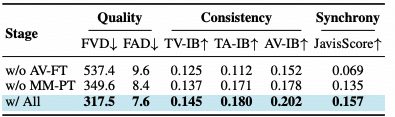
训练范式验证:三阶段管线的不可或缺性
JavisGPT采用的预训练-微调-指令调优三阶段管线。 实验显示,若移除音视频微调阶段,衡量声画同步性的核心指标JavisScore出现了灾难性下降(从 0.157 跌至 0.069)。
通用的多模态预训练虽然赋予了模型基础的感知能力,但只有通过专门的音视频对齐微调,模型才能捕捉到毫秒级的物理同步规律。 每一个训练阶段都是构建高保真有声视频生成能力必不可少的基石。
总结与展望:迈向全能多模态智能的一大步
JavisGPT的提出, 不仅是对现有有声视频处理方案的一次技术革新,更是对多模态大模型交互范式的一次重构。
通过构建数学上对齐、架构上统一的解决方案,JavisGPT成功打破了视觉与听觉的物理隔离, 确立了"感-生一体"的新标尺。 这一工作为未来打造更具交互性、更懂物理世界的 AI 助手(如数字人、自动化影视创作)奠定了坚实的理论与技术基础。

未来,随着模型的进一步迭代,我们有理由期待JavisGPT在更开放、更复杂的真实世界场景中展现出更惊人的潜力。