在复杂开放环境中实现类人驾驶行为是自动驾驶领域的核心挑战。现有基于学习的规划方法(如模仿学习)在平衡多目标、保证安全性方面存在不足,且过度依赖规则化后处理。本文提出一种基于 Transformer 的 Diffusion Planner,首次将扩散模型的强大能力应用于自动驾驶闭环规划。该模型通过联合建模预测与规划任务,利用轨迹得分函数梯度学习和灵活的分类器引导机制,在无需规则化优化的前提下,有效捕捉多模态驾驶行为,同时保证轨迹安全性与适应性。在大规模真实世界数据集 nuPlan 和新增的 200 小时配送车辆数据集上的评估表明,Diffusion Planner 实现了当前最优的闭环性能,且在不同驾驶风格下具备稳健的迁移能力。

原文链接:https://arxiv.org/pdf/2501.15564
代码链接:https://zhengyinan-air.github.io/Diffusion-Planner
沐小含持续分享前沿算法论文,欢迎关注...
1 引言
1.1 自动驾驶规划的核心挑战
自动驾驶作为交通领域的基石技术,旨在实现更安全、高效的出行模式。其核心挑战在于:在复杂开放环境中,需同时满足安全性、效率性和舒适性要求,实现类人驾驶行为。当前规划方法主要分为两类:
- 规则化规划:基于人类知识定义驾驶行为边界,在工业应用中已取得初步成功,但对未定义的新交通场景适应性差,规则修改需大量工程投入。
- 基于学习的规划:通过模仿学习从数据中克隆人类驾驶技能,训练过程简洁且可通过扩展训练资源提升性能,但存在显著局限性。
1.2 现有学习型规划方法的三大痛点
- 多模态行为建模不足:人类驾驶存在丰富的多模态行为(如路口可左转、右转或直行),现有行为克隆方法即使采用大型 Transformer 架构或多轨迹采样,也难以保证对复杂数据分布的拟合。
- 分布外场景鲁棒性差:面对训练数据外的场景时,模型输出轨迹质量下降,需依赖规则化方法进行轨迹优化或过滤,陷入规则化方法的固有局限。
- 多目标平衡与适应性欠缺:仅通过模仿学习难以覆盖多样化驾驶需求,辅助损失函数惩罚不安全行为易导致多目标冲突;训练后模型难以灵活调整行为以满足个性化需求。
1.3 扩散模型的解决方案
扩散模型(Diffusion Model)的特性使其成为解决上述问题的理想选择:
- 强大的复杂数据分布建模能力,可有效捕捉多模态驾驶行为;
- 高质量生成能力,通过合理结构设计可提升轨迹质量,摆脱对规则化后处理的依赖;
- 灵活的引导机制,无需额外训练即可适配多样化规划需求。
1.4 本文核心贡献
- 首次将扩散模型与专用架构结合,应用于高性能运动规划,无需过度依赖规则化优化;
- 在 nuPlan 数据集上实现当前最优性能,生成比基线模型更稳健、平滑的轨迹;
- 通过灵活引导机制,实现运行时个性化驾驶行为调整,满足实际应用需求;
- 收集并开源 200 小时配送车辆数据集,兼容 nuPlan 框架,验证模型迁移能力。
2 相关工作
2.1 规则化规划
规则化方法通过预定义规则主导自动驾驶决策,具备高度可控性和可解释性,已在真实场景中广泛验证。但核心局限在于:无法处理超出预定义规则的新型复杂场景,扩展性差。
2.2 基于学习的规划
基于学习的规划以行为克隆为核心,已从早期的 CNN、RNN 架构扩展到 Transformer,后者在拟合复杂数据分布方面表现更优。但现有方法存在关键缺陷:
- 缺乏多模态驾驶行为建模的理论保证,闭环规划中易出现误差累积;
- 仍需依赖规则化方法进行轨迹优化或选择,违背了用学习替代预定义规则的初衷;
- 多目标平衡困难,训练后行为调整灵活性不足,难以适配个性化驾驶偏好。
2.3 相关领域的扩散模型应用
扩散模型已在决策领域初步探索,但在自动驾驶规划中的应用尚未充分:
- 运动预测与交通仿真:聚焦开环性能或仿真多样性,输出不直接用于控制;
- 规划相关研究:仅将扩散损失应用于现有框架或简单堆叠参数,缺乏专用设计,仍需依赖后处理保证性能。
本文通过专用架构设计,充分释放扩散模型在自动驾驶闭环规划中的潜力,实现性能突破。
3 基础知识铺垫
3.1 闭环规划与开环规划的区别
- 开环规划:仅基于静态条件进行决策,不考虑实时环境反馈;
- 闭环规划:需无缝集成实时感知、预测与控制,车辆需持续评估环境、预测周边车辆行为并执行精确操作,需应对传感器噪声和环境不确定性等动态挑战。
3.2 扩散模型与引导机制
3.2.1 扩散模型基本原理
扩散概率模型通过逆转 "前向扩散过程" 生成输出:
- 前向过程:逐步向原始数据
添加高斯噪声,生成一系列带噪数据
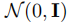 。其中
。其中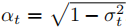 ,
, - 逆向去噪过程:可通过扩散 ODE 等价表示,模型
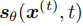 拟合概率得分
拟合概率得分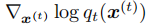 ,通过学习得分函数,扩散模型具备建模任意复杂分布的强大表达能力。
,通过学习得分函数,扩散模型具备建模任意复杂分布的强大表达能力。
3.2.2 分类器引导机制
分类器引导通过分类器 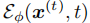 的得分梯度修改原始扩散得分,从而生成偏好数据。与规则化优化相比,该机制直接提升模型固有能力,无需依赖需大量人工投入和目标数据收集的次优后处理,在自动驾驶中具备更高灵活性。
的得分梯度修改原始扩散得分,从而生成偏好数据。与规则化优化相比,该机制直接提升模型固有能力,无需依赖需大量人工投入和目标数据收集的次优后处理,在自动驾驶中具备更高灵活性。
4 方法论:Diffusion Planner 设计
4.1 任务重定义:联合建模预测与规划
自动驾驶中,自车(ego vehicle)与周边车辆存在紧密交互,预测与规划任务具有协同性。现有方法通过专用子模块或额外损失函数处理这种协同关系,导致框架复杂且建模能力受限。
本文将任务重定义为未来轨迹生成问题,联合建模自车规划与周边车辆预测:
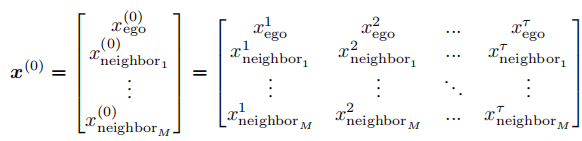
其中, 表示自车未来
步轨迹,
表示第
个周边车辆的未来轨迹。通过单一损失函数联合训练:
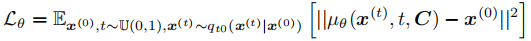
无需额外损失函数即可实现车辆间协同行为。
4.2 模型架构:扩散 Transformer 设计
Diffusion Planner 基于扩散 Transformer(Diffusion Transformer)构建,架构如图 1 所示,核心分为场景信息编码、导航信息融合和去噪解码三大模块。
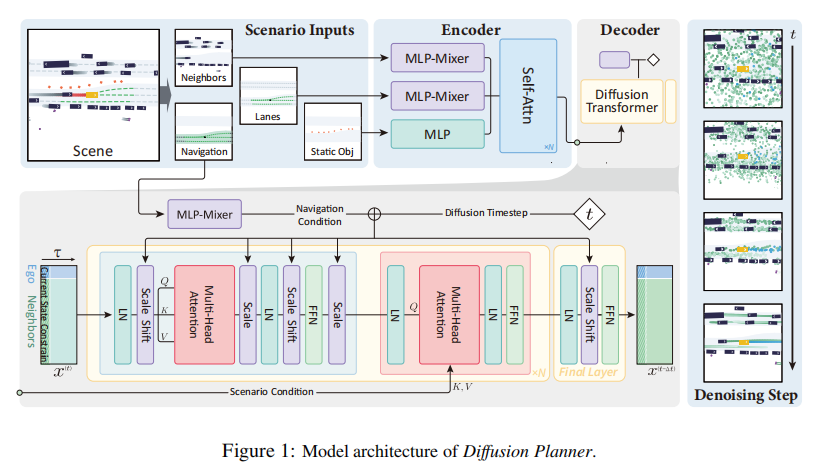
4.2.1 场景信息编码
场景信息包括静态目标(坐标、航向、尺寸、类别等)、车道和周边车辆状态,处理流程如下:
-
静态目标:通过 MLP 提取特征表示;
-
车道与周边车辆:采用 MLP-Mixer 网络提取特征,捕捉全局结构信息;
-
特征融合:将所有特征拼接后输入 Transformer 编码器进行聚合,得到场景特征
-
跨注意力融合:通过多头跨注意力(MHCA)将场景特征与轨迹特征融合,增强场景感知能力:
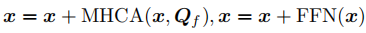
4.2.2 导航信息融合
导航信息以路线车道集合形式表示,包含关键的行驶路线引导。处理过程:
- 通过 MLP-Mixer 提取导航特征
- 与扩散时间步条件
4.2.3 去噪解码
采用扩散模型的逆向去噪过程,通过学习得分函数梯度,逐步将带噪轨迹去噪为高质量规划轨迹。解码器通过多头注意力和前馈网络(FFN)实现轨迹细化,结合尺度缩放与偏移(Scale Shift)机制增强模型表达能力。
4.3 基于分类器引导的规划行为对齐
在真实自动驾驶场景中,规划系统需同时满足多重需求:既要保证绝对安全,又要兼顾乘坐舒适性,还需根据用户偏好调整行驶风格(如经济模式、运动模式)。传统方法要么通过复杂的多目标损失函数训练,导致目标间冲突;要么依赖规则化后处理,灵活性不足。而 Diffusion Planner 借助扩散模型与能量模型(Energy-Based Models)的天然关联,通过分类器引导机制,实现了推理阶段无需额外训练的灵活行为调整,为解决这一核心难题提供了高效方案。
4.3.1 引导机制的核心原理
分类器引导的本质是通过 "能量函数编码偏好 + 梯度调整轨迹分布",在不改变模型参数的前提下,将原始驾驶行为分布引导至目标行为分布。其完整逻辑链条如下:
1. 分布转换逻辑
设模型训练习得的原始驾驶行为分布为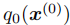 (
(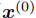 为轨迹序列),我们希望注入安全、舒适等偏好,生成目标分布
为轨迹序列),我们希望注入安全、舒适等偏好,生成目标分布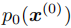 。两者满足如下关系:
。两者满足如下关系:
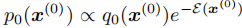
其中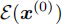 为能量函数,用于量化轨迹满足偏好的程度 ------ 轨迹越符合偏好(如更安全、更舒适),能量值越低;反之则能量值越高。指数项相当于为优质轨迹赋予更高权重,从而引导模型生成更符合需求的输出。
为能量函数,用于量化轨迹满足偏好的程度 ------ 轨迹越符合偏好(如更安全、更舒适),能量值越低;反之则能量值越高。指数项相当于为优质轨迹赋予更高权重,从而引导模型生成更符合需求的输出。
2. 梯度调整机制
扩散模型的生成过程依赖对轨迹概率得分的学习,分类器引导通过修改这一得分实现分布引导。根据扩散 ODE 理论,原始概率得分梯度为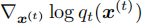 (
( 为第
步带噪轨迹)。引入引导后,目标得分梯度需结合能量函数的梯度进行修正:
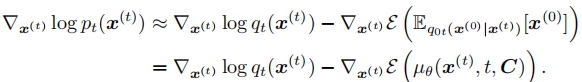
该公式的核心创新在于无需额外训练分类器 :通过扩散后验采样技术(Diffusion Posterior Sampling),直接利用训练好的扩散模型解码器 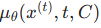 (输入为带噪轨迹
(输入为带噪轨迹 、时间步
和场景条件 C),近似计算轨迹的期望能量
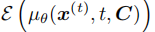 ,从而避免了额外训练分类器带来的计算开销和数据依赖。
,从而避免了额外训练分类器带来的计算开销和数据依赖。
3. 关键约束条件
引导机制的有效实施需满足一个核心条件:能量函数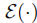 必须是可微的。这是因为梯度调整依赖能量函数对轨迹的导数计算 ------ 若能量函数不可微,则无法通过梯度下降引导轨迹生成方向。幸运的是,自动驾驶场景中绝大多数轨迹评估指标(如碰撞距离、速度偏差、车道偏离度等)均可设计为可微函数,为引导机制的落地提供了基础。
必须是可微的。这是因为梯度调整依赖能量函数对轨迹的导数计算 ------ 若能量函数不可微,则无法通过梯度下降引导轨迹生成方向。幸运的是,自动驾驶场景中绝大多数轨迹评估指标(如碰撞距离、速度偏差、车道偏离度等)均可设计为可微函数,为引导机制的落地提供了基础。
4.3.2 四大核心能量函数设计
论文针对自动驾驶核心需求,设计了四类可微能量函数,覆盖安全、舒适、速度控制、车道保持四大场景,且支持灵活组合使用。每类函数的设计逻辑均贴合实际驾驶需求,具体如下:
1. 避撞能量函数(Collision Avoidance)
-
核心目标:确保自车与周边车辆、行人等障碍物保持安全距离。
-
计算逻辑 :在每个时间戳
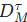 (正数表示无碰撞,负数表示已碰撞)。能量函数定义为:
(正数表示无碰撞,负数表示已碰撞)。能量函数定义为: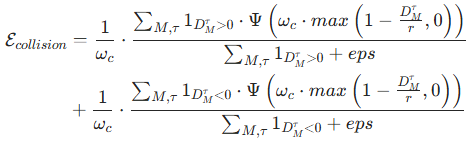
-
参数说明:
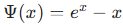 :确保能量函数平滑可微,避免梯度突变;
:确保能量函数平滑可微,避免梯度突变;- 1⋅:指示函数,分别统计有碰撞风险(>0)和已碰撞(<0)的情况;
- eps:数值稳定性项,避免分母为 0。
2. 车道保持能量函数(Staying within Drivable Area)
- 核心目标:确保自车始终行驶在可驾驶区域内(如车道线内),避免偏离道路。
- 计算逻辑:
-
利用欧氏符号距离场(Euclidean Signed Distance Field)并行计算可驾驶区域的可微成本图
-
能量函数定义为
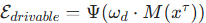
其中
-
- 关键特性:并行计算确保能量函数高效求解,适配实时规划需求。
3. 目标速度维持能量函数(Target Speed Maintenance)
-
核心目标:使自车行驶速度贴合用户设定的目标速度范围(如高速路 100km/h、城区 30km/h)。
-
计算逻辑 :首先计算生成轨迹的平均速度
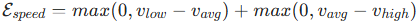
-
设计巧思:通过分段最大值函数确保能量仅在速度超出目标范围时生效,避免过度引导导致速度僵硬。
4. 舒适性能量函数(Comfort)
-
核心目标:减少车辆加减速带来的颠簸感,尤其是纵向加加速度(Jerk)------ 这是影响乘坐舒适性的关键指标。
-
计算逻辑 :以纵向加加速度为核心指标,仅当 Jerk 超出舒适阈值
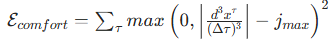
-
参数说明:
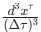 为纵向加加速度(Jerk),平方项用于放大较大偏差的惩罚力度,确保轨迹平滑。
为纵向加加速度(Jerk),平方项用于放大较大偏差的惩罚力度,确保轨迹平滑。
4.3.3 引导机制的三大核心优势
1. 训练无关的灵活性
引导机制在推理阶段生效,无需对模型进行额外训练 ------ 只需根据场景需求选择对应的能量函数(或组合),即可实现行为调整。例如:
- 高速场景:组合 "避撞 + 目标速度维持" 引导,优先保证效率;
- 城区拥堵场景:组合 "避撞 + 舒适性 + 车道保持" 引导,优先保证安全和乘坐体验。
2. 多目标组合的兼容性
不同能量函数可灵活叠加,且梯度计算可并行执行,避免了传统多目标训练中 "权重调优" 的难题。论文通过实验验证了组合引导的有效性:如图 2 所示,仅开启避撞引导时,自车为躲避后方来车会偏离车道;而同时开启车道保持引导后,车辆能在避免碰撞的前提下,始终行驶在可驾驶区域内,实现了安全与合规的兼顾。
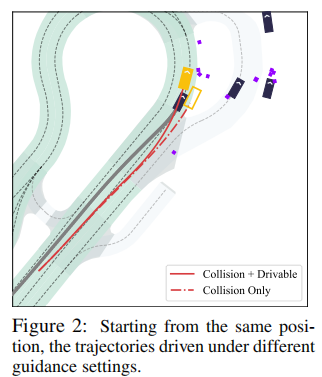
3. 轻量化的计算开销
得益于 "无需额外训练分类器" 的设计,引导机制仅需在扩散模型推理过程中增加能量函数的梯度计算,额外开销极低。结合论文后续的工程优化(如 DPM-Solver 快速采样),整个规划流程(含引导计算)可达到 20Hz 的推理频率,完全满足自动驾驶实时性要求。
4.4 闭环规划的工程实现细节
4.4.1 数据预处理
- 数据增强:对当前状态添加随机扰动,通过插值生成物理可行的过渡轨迹,增强模型抗干扰能力;
- 坐标转换:从全局坐标系转换为自车中心坐标系,降低模型学习难度;
- 归一化:采用 z-score 归一化处理纵向与横向距离差异,稳定训练过程。
4.4.2 推理优化
- 快速采样:采用 DPM-Solver 实现快速轨迹采样,提升推理效率;
- 确定性增强:通过低温采样(Low-temperature Sampling)提高规划过程的确定性;
- 性能指标:以 10Hz 频率生成未来 8 秒轨迹及周边车辆预测,推理频率达 20Hz,满足实时性要求。
5 实验设计与分析
5.1 实验设置
5.1.1 数据集
- nuPlan 数据集:大规模真实世界自动驾驶规划基准,包含 Val14、Test14 和 Test14-hard 三个测试集,评估闭环非反应式(NR)和反应式(R)两种模式;
- 配送车辆数据集:新增 200 小时真实世界配送车辆驾驶数据,涵盖多种城市驾驶场景,车辆行为更保守,包含自行车道行驶、密集人车交互等特殊场景,兼容 nuPlan 评估框架。
5.1.2 基线模型
分为三类基线,覆盖规则化、基于学习和混合式方法:
- 规则化:IDM(经典规则化方法)、PDM-Closed(nuPlan 挑战赛冠军的规则化版本);
- 基于学习:UrbanDriver(策略梯度优化)、GameFormer(博弈论建模交互)、PlanTF(Transformer 架构)、PLUTO(对比学习增强);
- 混合式:PDM-Hybrid(规则化 + 学习结合)、GameFormer w/refine(学习 + 规则化后处理)。
5.1.3 评估指标
采用 nuPlan 标准评分体系,总分 0-100 分,分数越高性能越好,涵盖安全性(碰撞率、最小安全距离 TTC)、可行性(车道保持)、舒适性和进度完成度等维度。
5.2 主要实验结果
5.2.1 nuPlan 数据集结果
表 1 展示了 Diffusion Planner 在 nuPlan 数据集上的闭环规划结果。核心结论:
- 无后处理的 Diffusion Planner 在所有基于学习的基线中表现最优,性能接近或超越规则化方法;
- 加入后处理模块后(Diffusion Planner w/refine.),性能超越所有基线(包括混合式方法),达到当前最优水平,甚至超过人类驾驶性能;
- 与 Transformer-based 基线(PlanTF、PLUTO)相比,Diffusion Planner 充分利用扩散模型优势,在多模态建模和轨迹质量上更具竞争力;
- GameFormer 因模型能力有限,严重依赖规则化后处理,无后处理时性能显著下降。
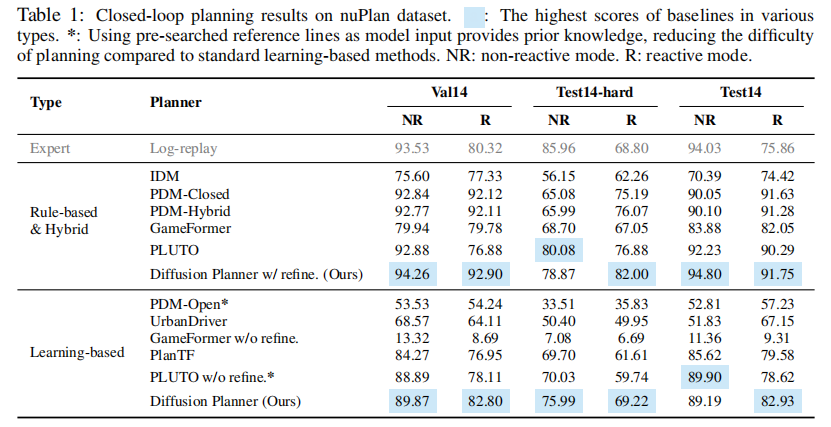
注:* 表示使用预搜索参考线作为输入,降低规划难度;NR = 非反应式模式,R = 反应式模式;表格中部分数据因原文排版调整,保持核心对比关系。
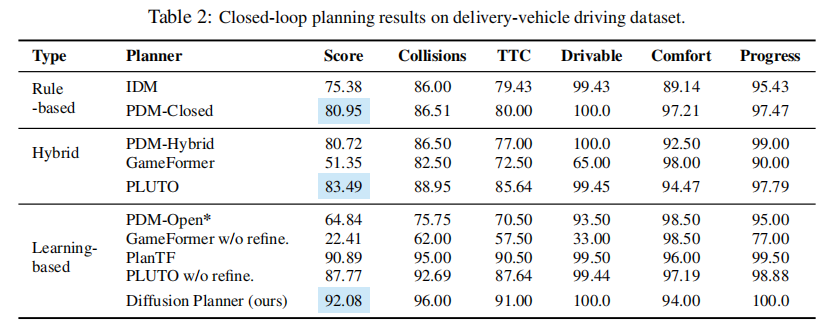
5.2.2 配送车辆数据集结果
表 2 展示了在 200 小时配送车辆数据集上的评估结果。核心结论:
- PDM、GameFormer、PLUTO 等专为 nuPlan 设计的模型,在配送车辆场景中性能下降,迁移能力有限;
- Diffusion Planner 表现出最强的迁移能力,总分达 92.08 分,在碰撞率(96.00)、车道保持(100.0)和进度完成度(100.0)等关键指标上均排名第一;
- 验证了 Diffusion Planner 在不同驾驶风格(配送车辆更保守)和场景(自行车道、密集交互)下的稳健性。
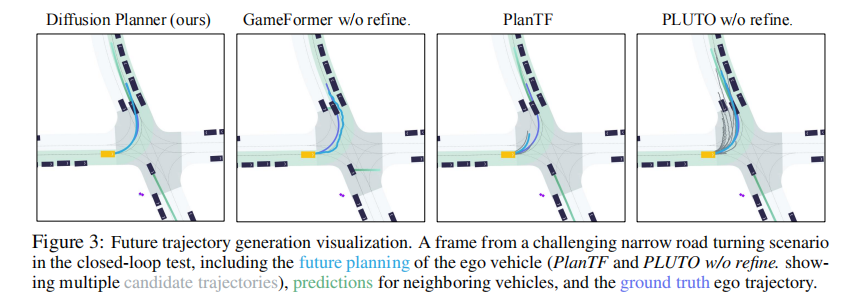
5.3 定性结果分析
5.3.1 轨迹生成质量可视化
图 3 展示了狭窄道路转弯场景下的轨迹生成结果。可以看到:
- Diffusion Planner 生成的自车轨迹平滑,且能准确预测周边车辆行为,合理考虑前车速度,体现了预测与规划联合建模的优势;
- GameFormer w/o refine. 生成的轨迹不光滑,周边车辆预测不准确,解释了其对后处理的依赖;
- PlanTF 和 PLUTO w/o refine. 虽能采样多条轨迹,但多数轨迹质量较低,实用性差。
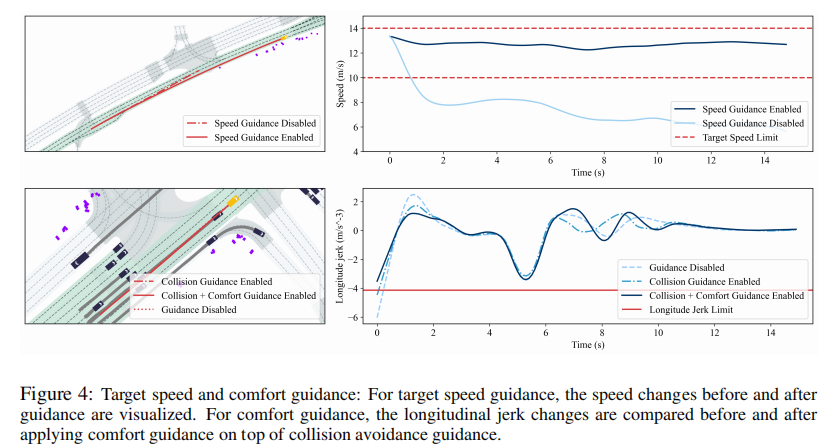
5.3.2 引导机制效果验证
图 4 展示了目标速度引导和舒适性引导的效果:
- 目标速度引导:开启后轨迹速度能准确贴合设定目标,关闭时速度波动较大;
- 舒适性引导:在避撞引导基础上添加舒适性引导后,纵向加加速度(Jerk)显著降低,符合舒适阈值要求。
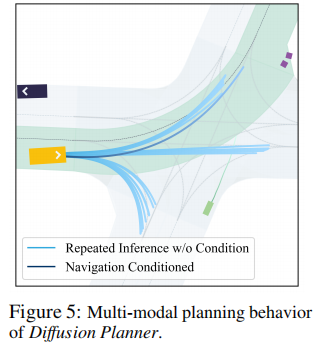
5.4 模型特性实证研究
5.4.1 多模态规划行为
为验证模型对多模态行为的捕捉能力,在无导航信息和有导航信息两种条件下,对同一路口场景进行多次推理。结果如图 5 所示:
- 无导航条件:模型生成左转、右转、直行三种截然不同的合理轨迹,体现多模态建模能力;
- 有导航条件:模型准确遵循导航指令,仅生成左转轨迹,证明模型能灵活切换行为模式。
5.4.2 消融实验
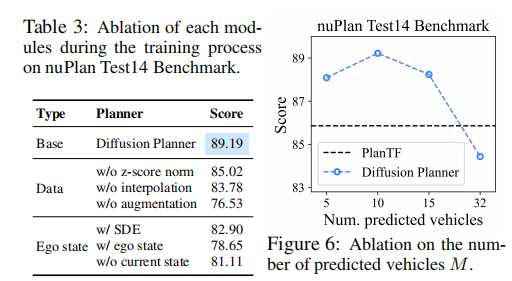
原文通过消融实验验证了关键模块的作用(部分结果如表3和图 6 所示):
-
预测车辆数量影响:预测周边车辆数量越多,模型对交互场景的处理能力越强,轨迹安全性和合理性提升;
-
联合建模的重要性:去除联合预测模块后,规划性能显著下降,验证了预测与规划协同的必要性;
-
引导机制的贡献:关闭引导机制时,模型在特殊场景(如避撞 + 车道保持)下性能下降,体现引导机制的灵活性价值。
6 模型局限性与未来工作
6.1 主要局限性
- 横向灵活性不足:由于训练数据中直线行驶场景占比高,车道变更等大幅横向运动场景少,模型在需显著横向移动的场景中表现欠佳;
- 采样效率权衡:扩散模型的高性能依赖多次模型推理,采样效率有待进一步提升;
- 端到端训练欠缺:当前模型输入为结构化数据,未直接使用图像输入,未能实现完全端到端训练。
6.2 未来改进方向
- 增强横向运动能力:收集更多包含大幅横向移动的训练数据,结合强化学习奖励机制,或设计更有效的扩散引导机制;
- 提升采样效率:采用一致性模型(Consistency Models)或蒸馏式采样方法,进一步加速推理过程;
- 端到端架构设计:修改编码器架构,支持图像输入,实现感知 - 预测 - 规划的端到端训练。
7 总结
本文提出的 Diffusion Planner 首次将扩散模型的强大能力与专用 Transformer 架构结合,为自动驾驶闭环规划提供了新范式。其核心创新在于:通过联合建模预测与规划任务,利用扩散模型的多模态分布建模能力和灵活的分类器引导机制,在无需规则化后处理的前提下,实现了安全性、适应性与个性化的统一。在大规模真实世界数据集上的全面评估验证了模型的优越性,新增的 200 小时配送车辆数据集进一步证明了其稳健的迁移能力。尽管存在部分局限性,Diffusion Planner 仍为自动驾驶规划提供了高性能、高适应性的解决方案,为未来类人自动驾驶系统的发展奠定了重要基础。