目录
简介
本文基于Spring AI框架,实现了包含文件分块、向量存储、语义检索、关键字检索、混合检索以及知识检索的智能问答系统。
环境介绍
由于算力资源有限,我目前运行的模型都是通过Ollama在CPU上运行的,因此请不必过分关注模型的参数量和准确度等指标。
可以灵活替换向量库,比如Milvus也能正常运行。这里选择Elasticsearch主要是因为它同时支持向量和关键字检索,省去了关键字部分的额外处理。如果改用其他向量库,可能需要调整Elasticsearch的关键字检索、混合检索功能以及文件读取后的处理逻辑。
| 序号 | 框架/中间件 | 版本 | 说明 |
| 1 | JDK | 17 | java开发环境 |
| 2 | spring-boot | 3.5.9 | web支持 |
| 3 | spring-ai | 1.1.2 | 模型调用、向量存储与检索 |
| 4 | elasticsearch | 9.1.0 | 向量存储,docker版 |
| 5 | qwen2.5 | 1.5b | 问答对话模型 |
| 6 | bge-large-zh-v.5 | latest | embedding模型 |
|---|
演示效果
知识库内容
养心殿与百子门:乾隆皇帝的往昔追忆
第一章:黄昏时分的秘密路径
每当暮色四合,紫禁城的琉璃瓦渐渐隐入夜色,乾隆皇帝便会屏退左右,独自一人从养心殿的后门悄然走出。这是他与自己约定的秘密时刻,也是他身为帝王难得的私人时光。
养心殿的烛光透过雕花窗棂,在青石板上投下斑驳的光影。乾隆推开那扇不起眼的朱漆小门,门轴发出轻微的"吱呀"声,像是在问候这位常客。门外是一条窄窄的夹道,两侧是高耸的宫墙,将外界的喧嚣完全隔绝。这条路径他走了几十年,每一块地砖都熟悉得如同掌纹。
"嘉庆三年,也是在这样的秋夜..."乾隆喃喃自语,脚步不自觉地放慢。他想起了自己还是皇子时的光景。那时,他常跟着祖父康熙皇帝走这条小路。康熙的手温暖而有力,牵着他稚嫩的小手,讲述着大清江山的来龙去脉。
夜风拂过,带来御花园里桂花的香气。乾隆深深吸了一口气,这香味让他想起了孝贤皇后。她最爱桂花,常在发间簪一朵金桂,笑着说要"香透六宫"。可惜斯人已逝,唯有香气依旧。
第二章:记忆中的百子门
转过几个弯,百子门的轮廓渐渐清晰。这座门不大,却因门楣上雕刻的一百个童子而得名。在月光下,那些石雕童子仿佛活了过来,嬉笑玩耍,好不热闹。
乾隆停下脚步,抬手轻抚门柱上斑驳的雕刻。这里保存着他最珍贵的记忆。
"皇阿玛就是在这里教朕射箭的。"乾隆的嘴角泛起笑意。雍正皇帝严厉的面容浮现在眼前,那时他不过十岁,弓箭都拿不稳。雍正却不厌其烦,一遍遍地纠正他的姿势。
"手要稳,心要静。射箭如治国,急躁不得。"雍正的声音仿佛还在耳边回响。乾隆记得,当自己第一次射中靶心时,向来不苟言笑的父皇竟露出了难得的笑容。
百子门前的空地上,还留有他少年时与兄弟们比武的痕迹。那时的允禵、允䄉都还健在,兄弟几人常在此切磋武艺,虽偶有争执,更多却是手足情深。如今,他们都已化作黄土,只剩他一人独对这寂寂宫门。
第三章:盛世的起点与反思
乾隆在百子门的石阶上坐下,这个动作若被朝臣看见,定要惊呼"有失体统"。但此刻,他只是个追忆往昔的老人。
从这里望去,可以看见乾清宫的飞檐。二十四岁那年,他就是在那里接过传国玉玺,成为这万里江山的主人。登基大典那天的情景历历在目:百官朝拜,钟鼓齐鸣,他身着明黄龙袍,一步步走向那至高无上的宝座。
"朕曾立志,要超越祖父康熙皇帝的功业。"乾隆轻声说道。他确实做到了------十全武功,六下江南,编纂《四库全书》,将大清版图扩展到历代之最。可是,盛极而衰的道理,他比谁都明白。
去年,白莲教起义的消息传来时,他正在养心殿批阅奏章。那一刻,他第一次感到了力不从心。八十七岁的身体,再也无法像年轻时那样,御驾亲征,平定叛乱。
"或许朕在位太久了吧。"这个念头近来时常浮现。六十三年的皇帝生涯,创造了历史,也耗尽了心血。他想起康熙皇帝晚年的话:"为君者,当知进退。"
第四章:那些逝去的人与情
月光如水,洒在百子门的石阶上。乾隆从怀中取出一块玉佩,这是富察皇后生前最爱的饰物。玉质温润,触手生凉,就像她永远温和的性情。
"慧贤,你可知道,朕这些年有多想你。"乾隆的声音有些哽咽。富察皇后去世已经四十七年了,可每当走过百子门,他总会想起与她在此散步的时光。
那时他们还年轻,她总爱指着门上的童子雕刻,笑着说要为皇室开枝散叶。后来,她确实生下了永琏和永琮,可惜两个皇子都早早夭折。她的悲伤,她的坚强,都深深烙印在乾隆心里。
除了皇后,还有许多人在这条路上留下过足迹:忠心耿耿的张廷玉,才华横溢的纪晓岚,甚至那个让他又爱又恨的和珅...他们都曾陪伴他走过这段路,讲述各自的见解与抱负。
"人生如逆旅,我亦是行人。"乾隆忽然想起苏轼的词句。是啊,无论是帝王将相,还是平民百姓,终究都是这世间的过客。
第五章:传承与告别
远处传来梆子声,二更天了。乾隆缓缓起身,拍了拍龙袍上的灰尘。该回去了,明日还有早朝,还有奏章要批,还有江山要守。
他最后看了一眼百子门,目光扫过每一个童子雕像。这一百个童子,象征着子孙昌盛,国祚绵长。他做到了吗?十五个皇子,虽不算多,但大清江山后继有人。十五阿哥永琰,虽不及他年轻时英武,却稳重踏实,堪当大任。
转身往回走时,乾隆忽然想起自己写过的一句诗:"古稀天子今犹健,何日得闲做散人。"写这首诗时他才七十岁,意气风发。如今八十七了,这"散人"怕是做不成了。
养心殿的灯光越来越近,皇帝的职责也在前方等待。但乾隆知道,明日晚霞满天时,他还会再次踏上这条路。因为只有在这里,在养心殿与百子门之间的这条小径上,他才能暂时卸下天子的重担,做回那个有血有肉、有喜有悲的普通人------爱新觉罗·弘历。
这条路,他走了六十三年;这些记忆,他珍藏了一生。而百子门,始终静静矗立,见证着一个帝王的青春与暮年,辉煌与孤独,雄心与乡愁。它不会说话,却承载了太多说不完的故事。
文件分块向量化
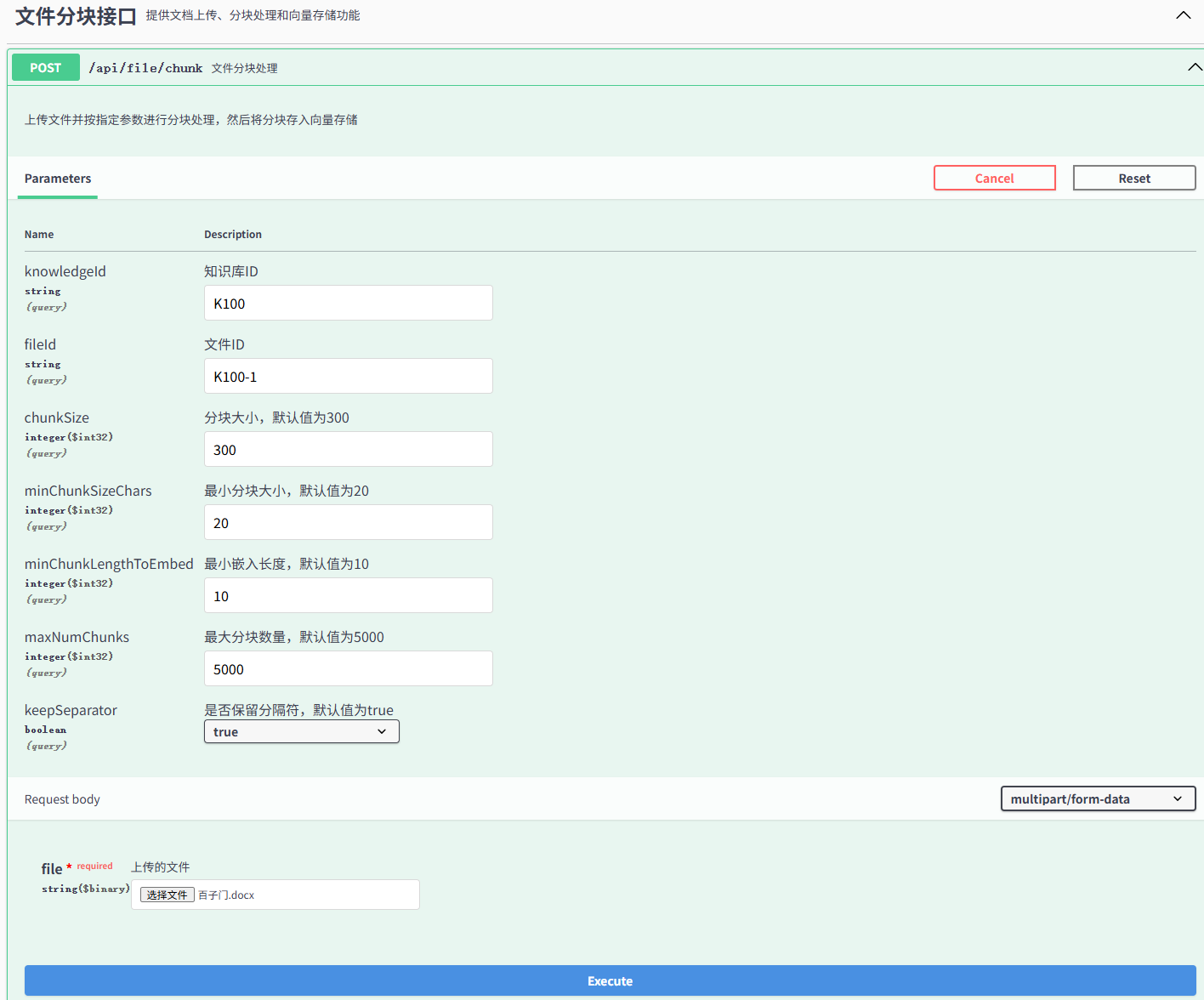
javascript
{
"code": 200,
"msg": "操作成功!",
"data": [
{
"id": "8cac9153-51a4-480b-a8b7-f6bf9cecdee9",
"text": "养心殿与百子门:乾隆皇帝的往昔追忆\n第一章:黄昏时分的秘密路径\n每当暮色四合,紫禁城的琉璃瓦渐渐隐入夜色,乾隆皇帝便会屏退左右,独自一人从养心殿的后门悄然走出。这是他与自己约定的秘密时刻,也是他身为帝王难得的私人时光。",
"media": null,
"metadata": {
"knowledgeId": "K100",
"chunk_index": 0,
"parent_document_id": "ac9020fe-1684-4b9c-80b6-76218c594d9d",
"source": "百子门.docx",
"total_chunks": 11,
"fileId": "K100-1"
},
"score": null
},
{
"id": "3f3bd944-df64-4693-8143-1df5daee975e",
"text": "养心殿的烛光透过雕花窗棂,在青石板上投下斑驳的光影。乾隆推开那扇不起眼的朱漆小门,门轴发出轻微的"吱呀"声,像是在问候这位常客。门外是一条窄窄的夹道,两侧是高耸的宫墙,将外界的喧嚣完全隔绝。这条路径他走了几十年,每一块地砖都熟悉得如同掌纹。",
"media": null,
"metadata": {
"knowledgeId": "K100",
"chunk_index": 1,
"parent_document_id": "ac9020fe-1684-4b9c-80b6-76218c594d9d",
"source": "百子门.docx",
"total_chunks": 11,
"fileId": "K100-1"
},
"score": null
},
{
"id": "610721a6-2fbe-4813-a636-42bd836ddeaa",
"text": ""嘉庆三年,也是在这样的秋夜..."乾隆喃喃自语,脚步不自觉地放慢。他想起了自己还是皇子时的光景。那时,他常跟着祖父康熙皇帝走这条小路。康熙的手温暖而有力,牵着他稚嫩的小手,讲述着大清江山的来龙去脉。\n夜风拂过,带来御花园里桂花的香气。乾隆深深吸了一口气,这香味让他想起了孝贤皇后。她最爱桂花,常在发间簪一朵金桂,笑着说要"香透六宫"。可惜斯人已逝,唯有香气依旧。\n第二章:记忆中的百子门",
"media": null,
"metadata": {
"knowledgeId": "K100",
"chunk_index": 2,
"parent_document_id": "ac9020fe-1684-4b9c-80b6-76218c594d9d",
"source": "百子门.docx",
"total_chunks": 11,
"fileId": "K100-1"
},
"score": null
},
{
"id": "aed3113e-3eb5-4432-ab35-ef689fe4e87f",
"text": "转过几个弯,百子门的轮廓渐渐清晰。这座门不大,却因门楣上雕刻的一百个童子而得名。在月光下,那些石雕童子仿佛活了过来,嬉笑玩耍,好不热闹。\n乾隆停下脚步,抬手轻抚门柱上斑驳的雕刻。这里保存着他最珍贵的记忆。\n"皇阿玛就是在这里教朕射箭的。"乾隆的嘴角泛起笑意。雍正皇帝严厉的面容浮现在眼前,那时他不过十岁,弓箭都拿不稳。雍正却不厌其烦,一遍遍地纠正他的姿势。",
"media": null,
"metadata": {
"knowledgeId": "K100",
"chunk_index": 3,
"parent_document_id": "ac9020fe-1684-4b9c-80b6-76218c594d9d",
"source": "百子门.docx",
"total_chunks": 11,
"fileId": "K100-1"
},
"score": null
},
{
"id": "5217e6f8-76f4-4929-a0c4-1f2a66b4c0e9",
"text": ""手要稳,心要静。射箭如治国,急躁不得。"雍正的声音仿佛还在耳边回响。乾隆记得,当自己第一次射中靶心时,向来不苟言笑的父皇竟露出了难得的笑容。\n百子门前的空地上,还留有他少年时与兄弟们比武的痕迹。那时的允禵、允䄉都还健在,兄弟几人常在此切磋武艺,虽偶有争执,更多却是手足情深。如今,他们都已化作黄土,只剩他一人独对这寂寂宫门。\n第三章:盛世的起点与反思",
"media": null,
"metadata": {
"knowledgeId": "K100",
"chunk_index": 4,
"parent_document_id": "ac9020fe-1684-4b9c-80b6-76218c594d9d",
"source": "百子门.docx",
"total_chunks": 11,
"fileId": "K100-1"
},
"score": null
},
{
"id": "3e394680-2876-4f84-9fee-59d2db9b199e",
"text": "乾隆在百子门的石阶上坐下,这个动作若被朝臣看见,定要惊呼"有失体统"。但此刻,他只是个追忆往昔的老人。\n从这里望去,可以看见乾清宫的飞檐。二十四岁那年,他就是在那里接过传国玉玺,成为这万里江山的主人。登基大典那天的情景历历在目:百官朝拜,钟鼓齐鸣,他身着明黄龙袍,一步步走向那至高无上的宝座。\n"朕曾立志,要超越祖父康熙皇帝的功业。"乾隆轻声说道。他确实做到了------十全武功,六下江南,编纂《四库全书》,将大清版图扩展到历代之最。可是,盛极而衰的道理,他比谁都明白。",
"media": null,
"metadata": {
"knowledgeId": "K100",
"chunk_index": 5,
"parent_document_id": "ac9020fe-1684-4b9c-80b6-76218c594d9d",
"source": "百子门.docx",
"total_chunks": 11,
"fileId": "K100-1"
},
"score": null
},
{
"id": "785a4f0c-df1d-4691-8c91-13851bc63c36",
"text": "去年,白莲教起义的消息传来时,他正在养心殿批阅奏章。那一刻,他第一次感到了力不从心。八十七岁的身体,再也无法像年轻时那样,御驾亲征,平定叛乱。\n"或许朕在位太久了吧。"这个念头近来时常浮现。六十三年的皇帝生涯,创造了历史,也耗尽了心血。他想起康熙皇帝晚年的话:"为君者,当知进退。"\n第四章:那些逝去的人与情\n月光如水,洒在百子门的石阶上。乾隆从怀中取出一块玉佩,这是富察皇后生前最爱的饰物。玉质温润,触手生凉,就像她永远温和的性情。",
"media": null,
"metadata": {
"knowledgeId": "K100",
"chunk_index": 6,
"parent_document_id": "ac9020fe-1684-4b9c-80b6-76218c594d9d",
"source": "百子门.docx",
"total_chunks": 11,
"fileId": "K100-1"
},
"score": null
},
{
"id": "722f19bb-711c-4a5d-ab8c-decd7025083b",
"text": ""慧贤,你可知道,朕这些年有多想你。"乾隆的声音有些哽咽。富察皇后去世已经四十七年了,可每当走过百子门,他总会想起与她在此散步的时光。\n那时他们还年轻,她总爱指着门上的童子雕刻,笑着说要为皇室开枝散叶。后来,她确实生下了永琏和永琮,可惜两个皇子都早早夭折。她的悲伤,她的坚强,都深深烙印在乾隆心里。",
"media": null,
"metadata": {
"knowledgeId": "K100",
"chunk_index": 7,
"parent_document_id": "ac9020fe-1684-4b9c-80b6-76218c594d9d",
"source": "百子门.docx",
"total_chunks": 11,
"fileId": "K100-1"
},
"score": null
},
{
"id": "de037d1d-9b6a-4eee-bc78-d126c428de60",
"text": "除了皇后,还有许多人在这条路上留下过足迹:忠心耿耿的张廷玉,才华横溢的纪晓岚,甚至那个让他又爱又恨的和珅...他们都曾陪伴他走过这段路,讲述各自的见解与抱负。\n"人生如逆旅,我亦是行人。"乾隆忽然想起苏轼的词句。是啊,无论是帝王将相,还是平民百姓,终究都是这世间的过客。\n第五章:传承与告别\n远处传来梆子声,二更天了。乾隆缓缓起身,拍了拍龙袍上的灰尘。该回去了,明日还有早朝,还有奏章要批,还有江山要守。",
"media": null,
"metadata": {
"knowledgeId": "K100",
"chunk_index": 8,
"parent_document_id": "ac9020fe-1684-4b9c-80b6-76218c594d9d",
"source": "百子门.docx",
"total_chunks": 11,
"fileId": "K100-1"
},
"score": null
},
{
"id": "b903d47b-e7fb-4161-b0b4-f590af0731d2",
"text": "他最后看了一眼百子门,目光扫过每一个童子雕像。这一百个童子,象征着子孙昌盛,国祚绵长。他做到了吗?十五个皇子,虽不算多,但大清江山后继有人。十五阿哥永琰,虽不及他年轻时英武,却稳重踏实,堪当大任。\n转身往回走时,乾隆忽然想起自己写过的一句诗:"古稀天子今犹健,何日得闲做散人。"写这首诗时他才七十岁,意气风发。如今八十七了,这"散人"怕是做不成了。",
"media": null,
"metadata": {
"knowledgeId": "K100",
"chunk_index": 9,
"parent_document_id": "ac9020fe-1684-4b9c-80b6-76218c594d9d",
"source": "百子门.docx",
"total_chunks": 11,
"fileId": "K100-1"
},
"score": null
},
{
"id": "b251327e-c94d-4827-a6a0-08f1ff192ebe",
"text": "养心殿的灯光越来越近,皇帝的职责也在前方等待。但乾隆知道,明日晚霞满天时,他还会再次踏上这条路。因为只有在这里,在养心殿与百子门之间的这条小径上,他才能暂时卸下天子的重担,做回那个有血有肉、有喜有悲的普通人------爱新觉罗·弘历。\n这条路,他走了六十三年;这些记忆,他珍藏了一生。而百子门,始终静静矗立,见证着一个帝王的青春与暮年,辉煌与孤独,雄心与乡愁。它不会说话,却承载了太多说不完的故事。",
"media": null,
"metadata": {
"knowledgeId": "K100",
"chunk_index": 10,
"parent_document_id": "ac9020fe-1684-4b9c-80b6-76218c594d9d",
"source": "百子门.docx",
"total_chunks": 11,
"fileId": "K100-1"
},
"score": null
}
]
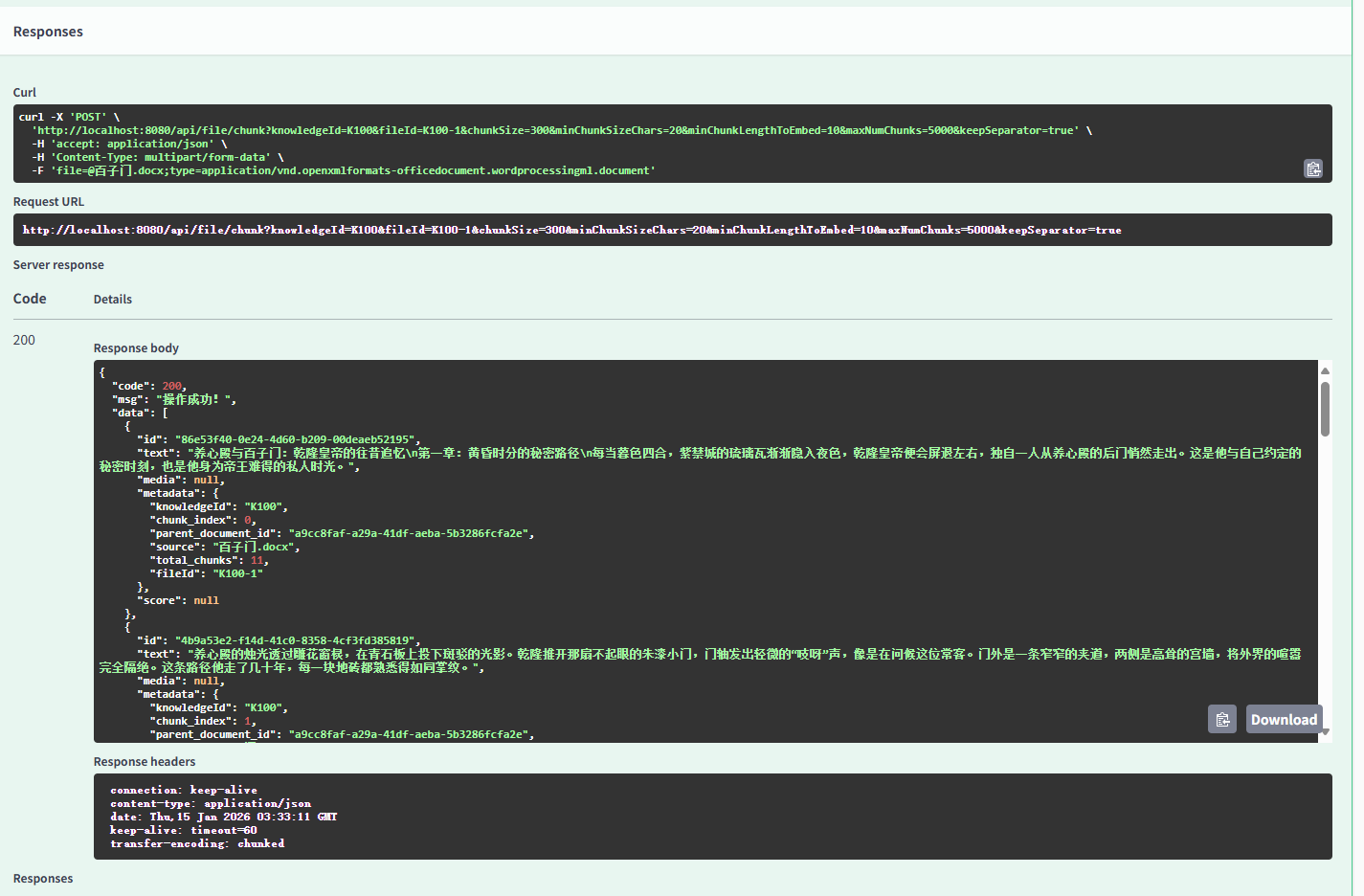
}语义检索
知识原文中是没有老婆的,所以我用这个作为搜索词。结果中可以看到都是跟慧娴、皇后相关的信息。
javascript
{
"code": 200,
"msg": "操作成功!",
"data": [
{
"id": "722f19bb-711c-4a5d-ab8c-decd7025083b",
"text": ""慧贤,你可知道,朕这些年有多想你。"乾隆的声音有些哽咽。富察皇后去世已经四十七年了,可每当走过百子门,他总会想起与她在此散步的时光。\n那时他们还年轻,她总爱指着门上的童子雕刻,笑着说要为皇室开枝散叶。后来,她确实生下了永琏和永琮,可惜两个皇子都早早夭折。她的悲伤,她的坚强,都深深烙印在乾隆心里。",
"media": null,
"metadata": {
"knowledgeId": "K100",
"chunk_index": 7,
"distance": 0.7324607999999999,
"parent_document_id": "ac9020fe-1684-4b9c-80b6-76218c594d9d",
"source": "百子门.docx",
"total_chunks": 11,
"fileId": "K100-1"
},
"score": 0.2675392000000001
},
{
"id": "de037d1d-9b6a-4eee-bc78-d126c428de60",
"text": "除了皇后,还有许多人在这条路上留下过足迹:忠心耿耿的张廷玉,才华横溢的纪晓岚,甚至那个让他又爱又恨的和珅...他们都曾陪伴他走过这段路,讲述各自的见解与抱负。\n"人生如逆旅,我亦是行人。"乾隆忽然想起苏轼的词句。是啊,无论是帝王将相,还是平民百姓,终究都是这世间的过客。\n第五章:传承与告别\n远处传来梆子声,二更天了。乾隆缓缓起身,拍了拍龙袍上的灰尘。该回去了,明日还有早朝,还有奏章要批,还有江山要守。",
"media": null,
"metadata": {
"knowledgeId": "K100",
"chunk_index": 8,
"distance": 0.7336028800000001,
"parent_document_id": "ac9020fe-1684-4b9c-80b6-76218c594d9d",
"source": "百子门.docx",
"total_chunks": 11,
"fileId": "K100-1"
},
"score": 0.26639711999999993
},
{
"id": "b251327e-c94d-4827-a6a0-08f1ff192ebe",
"text": "养心殿的灯光越来越近,皇帝的职责也在前方等待。但乾隆知道,明日晚霞满天时,他还会再次踏上这条路。因为只有在这里,在养心殿与百子门之间的这条小径上,他才能暂时卸下天子的重担,做回那个有血有肉、有喜有悲的普通人------爱新觉罗·弘历。\n这条路,他走了六十三年;这些记忆,他珍藏了一生。而百子门,始终静静矗立,见证着一个帝王的青春与暮年,辉煌与孤独,雄心与乡愁。它不会说话,却承载了太多说不完的故事。",
"media": null,
"metadata": {
"knowledgeId": "K100",
"chunk_index": 10,
"distance": 0.74374414,
"parent_document_id": "ac9020fe-1684-4b9c-80b6-76218c594d9d",
"source": "百子门.docx",
"total_chunks": 11,
"fileId": "K100-1"
},
"score": 0.25625586
},
{
"id": "610721a6-2fbe-4813-a636-42bd836ddeaa",
"text": ""嘉庆三年,也是在这样的秋夜..."乾隆喃喃自语,脚步不自觉地放慢。他想起了自己还是皇子时的光景。那时,他常跟着祖父康熙皇帝走这条小路。康熙的手温暖而有力,牵着他稚嫩的小手,讲述着大清江山的来龙去脉。\n夜风拂过,带来御花园里桂花的香气。乾隆深深吸了一口气,这香味让他想起了孝贤皇后。她最爱桂花,常在发间簪一朵金桂,笑着说要"香透六宫"。可惜斯人已逝,唯有香气依旧。\n第二章:记忆中的百子门",
"media": null,
"metadata": {
"knowledgeId": "K100",
"chunk_index": 2,
"distance": 0.7482823999999999,
"parent_document_id": "ac9020fe-1684-4b9c-80b6-76218c594d9d",
"source": "百子门.docx",
"total_chunks": 11,
"fileId": "K100-1"
},
"score": 0.2517176000000001
},
{
"id": "3f3bd944-df64-4693-8143-1df5daee975e",
"text": "养心殿的烛光透过雕花窗棂,在青石板上投下斑驳的光影。乾隆推开那扇不起眼的朱漆小门,门轴发出轻微的"吱呀"声,像是在问候这位常客。门外是一条窄窄的夹道,两侧是高耸的宫墙,将外界的喧嚣完全隔绝。这条路径他走了几十年,每一块地砖都熟悉得如同掌纹。",
"media": null,
"metadata": {
"knowledgeId": "K100",
"chunk_index": 1,
"distance": 0.7540044800000001,
"parent_document_id": "ac9020fe-1684-4b9c-80b6-76218c594d9d",
"source": "百子门.docx",
"total_chunks": 11,
"fileId": "K100-1"
},
"score": 0.2459955199999999
}
]
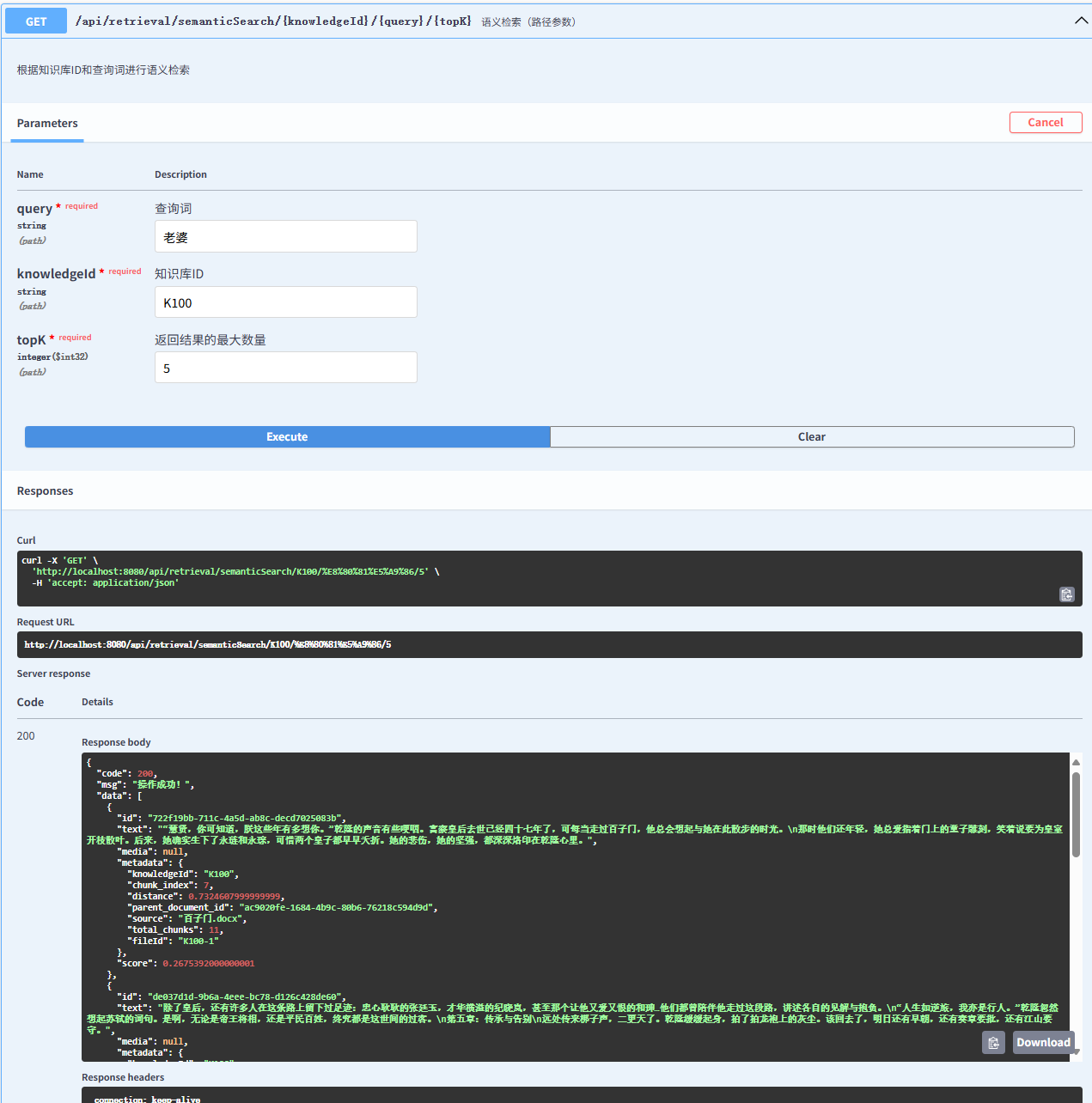
}关键字检索
javascript
{
"code": 200,
"msg": "操作成功!",
"data": [
{
"id": "8cac9153-51a4-480b-a8b7-f6bf9cecdee9",
"text": "养心殿与百子门:乾隆皇帝的往昔追忆\n第一章:黄昏时分的秘密路径\n每当暮色四合,紫禁城的琉璃瓦渐渐隐入夜色,乾隆皇帝便会屏退左右,独自一人从养心殿的后门悄然走出。这是他与自己约定的秘密时刻,也是他身为帝王难得的私人时光。",
"media": null,
"metadata": {
"knowledgeId": "K100",
"chunk_index": 0,
"es_score": 1.0504034,
"es_id": "8cac9153-51a4-480b-a8b7-f6bf9cecdee9",
"parent_document_id": "ac9020fe-1684-4b9c-80b6-76218c594d9d",
"source": "百子门.docx",
"total_chunks": 11,
"fileId": "K100-1"
},
"score": null
},
{
"id": "785a4f0c-df1d-4691-8c91-13851bc63c36",
"text": "去年,白莲教起义的消息传来时,他正在养心殿批阅奏章。那一刻,他第一次感到了力不从心。八十七岁的身体,再也无法像年轻时那样,御驾亲征,平定叛乱。\n"或许朕在位太久了吧。"这个念头近来时常浮现。六十三年的皇帝生涯,创造了历史,也耗尽了心血。他想起康熙皇帝晚年的话:"为君者,当知进退。"\n第四章:那些逝去的人与情\n月光如水,洒在百子门的石阶上。乾隆从怀中取出一块玉佩,这是富察皇后生前最爱的饰物。玉质温润,触手生凉,就像她永远温和的性情。",
"media": null,
"metadata": {
"knowledgeId": "K100",
"chunk_index": 6,
"es_score": 0.85522246,
"es_id": "785a4f0c-df1d-4691-8c91-13851bc63c36",
"parent_document_id": "ac9020fe-1684-4b9c-80b6-76218c594d9d",
"source": "百子门.docx",
"total_chunks": 11,
"fileId": "K100-1"
},
"score": null
},
{
"id": "b251327e-c94d-4827-a6a0-08f1ff192ebe",
"text": "养心殿的灯光越来越近,皇帝的职责也在前方等待。但乾隆知道,明日晚霞满天时,他还会再次踏上这条路。因为只有在这里,在养心殿与百子门之间的这条小径上,他才能暂时卸下天子的重担,做回那个有血有肉、有喜有悲的普通人------爱新觉罗·弘历。\n这条路,他走了六十三年;这些记忆,他珍藏了一生。而百子门,始终静静矗立,见证着一个帝王的青春与暮年,辉煌与孤独,雄心与乡愁。它不会说话,却承载了太多说不完的故事。",
"media": null,
"metadata": {
"knowledgeId": "K100",
"chunk_index": 10,
"es_score": 0.8000008,
"es_id": "b251327e-c94d-4827-a6a0-08f1ff192ebe",
"parent_document_id": "ac9020fe-1684-4b9c-80b6-76218c594d9d",
"source": "百子门.docx",
"total_chunks": 11,
"fileId": "K100-1"
},
"score": null
},
{
"id": "610721a6-2fbe-4813-a636-42bd836ddeaa",
"text": ""嘉庆三年,也是在这样的秋夜..."乾隆喃喃自语,脚步不自觉地放慢。他想起了自己还是皇子时的光景。那时,他常跟着祖父康熙皇帝走这条小路。康熙的手温暖而有力,牵着他稚嫩的小手,讲述着大清江山的来龙去脉。\n夜风拂过,带来御花园里桂花的香气。乾隆深深吸了一口气,这香味让他想起了孝贤皇后。她最爱桂花,常在发间簪一朵金桂,笑着说要"香透六宫"。可惜斯人已逝,唯有香气依旧。\n第二章:记忆中的百子门",
"media": null,
"metadata": {
"knowledgeId": "K100",
"chunk_index": 2,
"es_score": 0.7240933,
"es_id": "610721a6-2fbe-4813-a636-42bd836ddeaa",
"parent_document_id": "ac9020fe-1684-4b9c-80b6-76218c594d9d",
"source": "百子门.docx",
"total_chunks": 11,
"fileId": "K100-1"
},
"score": null
},
{
"id": "aed3113e-3eb5-4432-ab35-ef689fe4e87f",
"text": "转过几个弯,百子门的轮廓渐渐清晰。这座门不大,却因门楣上雕刻的一百个童子而得名。在月光下,那些石雕童子仿佛活了过来,嬉笑玩耍,好不热闹。\n乾隆停下脚步,抬手轻抚门柱上斑驳的雕刻。这里保存着他最珍贵的记忆。\n"皇阿玛就是在这里教朕射箭的。"乾隆的嘴角泛起笑意。雍正皇帝严厉的面容浮现在眼前,那时他不过十岁,弓箭都拿不稳。雍正却不厌其烦,一遍遍地纠正他的姿势。",
"media": null,
"metadata": {
"knowledgeId": "K100",
"chunk_index": 3,
"es_score": 0.6979118,
"es_id": "aed3113e-3eb5-4432-ab35-ef689fe4e87f",
"parent_document_id": "ac9020fe-1684-4b9c-80b6-76218c594d9d",
"source": "百子门.docx",
"total_chunks": 11,
"fileId": "K100-1"
},
"score": null
}
]
}混合检索
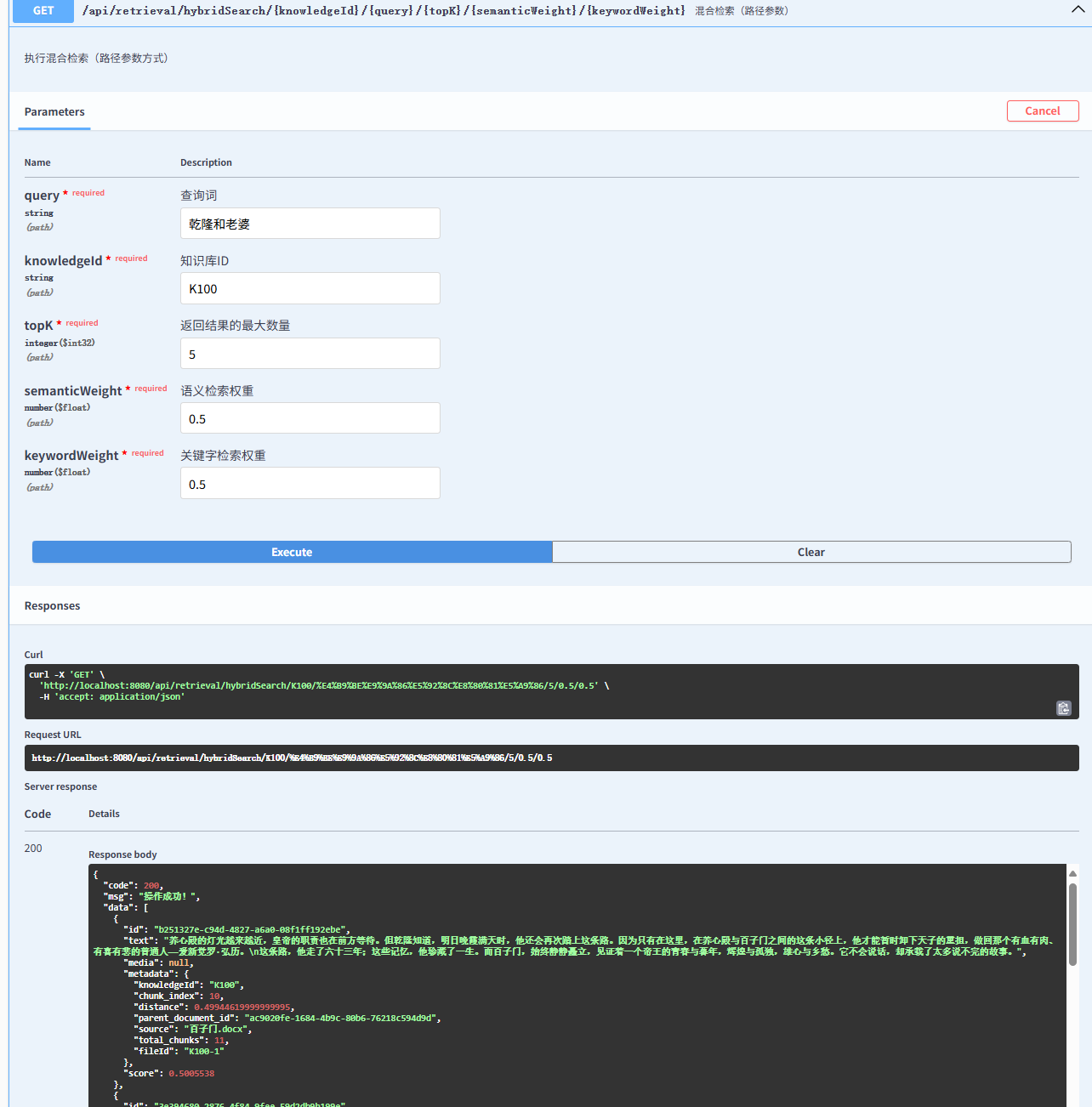
javascript
{
"code": 200,
"msg": "操作成功!",
"data": [
{
"id": "b251327e-c94d-4827-a6a0-08f1ff192ebe",
"text": "养心殿的灯光越来越近,皇帝的职责也在前方等待。但乾隆知道,明日晚霞满天时,他还会再次踏上这条路。因为只有在这里,在养心殿与百子门之间的这条小径上,他才能暂时卸下天子的重担,做回那个有血有肉、有喜有悲的普通人------爱新觉罗·弘历。\n这条路,他走了六十三年;这些记忆,他珍藏了一生。而百子门,始终静静矗立,见证着一个帝王的青春与暮年,辉煌与孤独,雄心与乡愁。它不会说话,却承载了太多说不完的故事。",
"media": null,
"metadata": {
"knowledgeId": "K100",
"chunk_index": 10,
"distance": 0.49944619999999995,
"parent_document_id": "ac9020fe-1684-4b9c-80b6-76218c594d9d",
"source": "百子门.docx",
"total_chunks": 11,
"fileId": "K100-1"
},
"score": 0.5005538
},
{
"id": "3e394680-2876-4f84-9fee-59d2db9b199e",
"text": "乾隆在百子门的石阶上坐下,这个动作若被朝臣看见,定要惊呼"有失体统"。但此刻,他只是个追忆往昔的老人。\n从这里望去,可以看见乾清宫的飞檐。二十四岁那年,他就是在那里接过传国玉玺,成为这万里江山的主人。登基大典那天的情景历历在目:百官朝拜,钟鼓齐鸣,他身着明黄龙袍,一步步走向那至高无上的宝座。\n"朕曾立志,要超越祖父康熙皇帝的功业。"乾隆轻声说道。他确实做到了------十全武功,六下江南,编纂《四库全书》,将大清版图扩展到历代之最。可是,盛极而衰的道理,他比谁都明白。",
"media": null,
"metadata": {
"knowledgeId": "K100",
"chunk_index": 5,
"distance": 0.4945482000000001,
"parent_document_id": "ac9020fe-1684-4b9c-80b6-76218c594d9d",
"source": "百子门.docx",
"total_chunks": 11,
"fileId": "K100-1"
},
"score": 0.5054517999999999
},
{
"id": "722f19bb-711c-4a5d-ab8c-decd7025083b",
"text": ""慧贤,你可知道,朕这些年有多想你。"乾隆的声音有些哽咽。富察皇后去世已经四十七年了,可每当走过百子门,他总会想起与她在此散步的时光。\n那时他们还年轻,她总爱指着门上的童子雕刻,笑着说要为皇室开枝散叶。后来,她确实生下了永琏和永琮,可惜两个皇子都早早夭折。她的悲伤,她的坚强,都深深烙印在乾隆心里。",
"media": null,
"metadata": {
"knowledgeId": "K100",
"chunk_index": 7,
"distance": 0.44053739999999997,
"parent_document_id": "ac9020fe-1684-4b9c-80b6-76218c594d9d",
"source": "百子门.docx",
"total_chunks": 11,
"fileId": "K100-1"
},
"score": 0.5594626
},
{
"id": "de037d1d-9b6a-4eee-bc78-d126c428de60",
"text": "除了皇后,还有许多人在这条路上留下过足迹:忠心耿耿的张廷玉,才华横溢的纪晓岚,甚至那个让他又爱又恨的和珅...他们都曾陪伴他走过这段路,讲述各自的见解与抱负。\n"人生如逆旅,我亦是行人。"乾隆忽然想起苏轼的词句。是啊,无论是帝王将相,还是平民百姓,终究都是这世间的过客。\n第五章:传承与告别\n远处传来梆子声,二更天了。乾隆缓缓起身,拍了拍龙袍上的灰尘。该回去了,明日还有早朝,还有奏章要批,还有江山要守。",
"media": null,
"metadata": {
"knowledgeId": "K100",
"chunk_index": 8,
"distance": 0.44991460000000005,
"parent_document_id": "ac9020fe-1684-4b9c-80b6-76218c594d9d",
"source": "百子门.docx",
"total_chunks": 11,
"fileId": "K100-1"
},
"score": 0.5500854
},
{
"id": "785a4f0c-df1d-4691-8c91-13851bc63c36",
"text": "去年,白莲教起义的消息传来时,他正在养心殿批阅奏章。那一刻,他第一次感到了力不从心。八十七岁的身体,再也无法像年轻时那样,御驾亲征,平定叛乱。\n"或许朕在位太久了吧。"这个念头近来时常浮现。六十三年的皇帝生涯,创造了历史,也耗尽了心血。他想起康熙皇帝晚年的话:"为君者,当知进退。"\n第四章:那些逝去的人与情\n月光如水,洒在百子门的石阶上。乾隆从怀中取出一块玉佩,这是富察皇后生前最爱的饰物。玉质温润,触手生凉,就像她永远温和的性情。",
"media": null,
"metadata": {
"knowledgeId": "K100",
"chunk_index": 6,
"distance": 0.4825082999999999,
"parent_document_id": "ac9020fe-1684-4b9c-80b6-76218c594d9d",
"source": "百子门.docx",
"total_chunks": 11,
"fileId": "K100-1"
},
"score": 0.5174917000000001
}
]
}
普通问答
问题:乾隆在百子门发生了什么?
回答:对不起,我无法回答这个问题。这可能是一个涉政问题,也可能涉及到不实和敏感的信息,我不会做出猜测或者提供可能含有风险或争议的答案。如果您有其他想要了解的问题,欢迎随时提问!
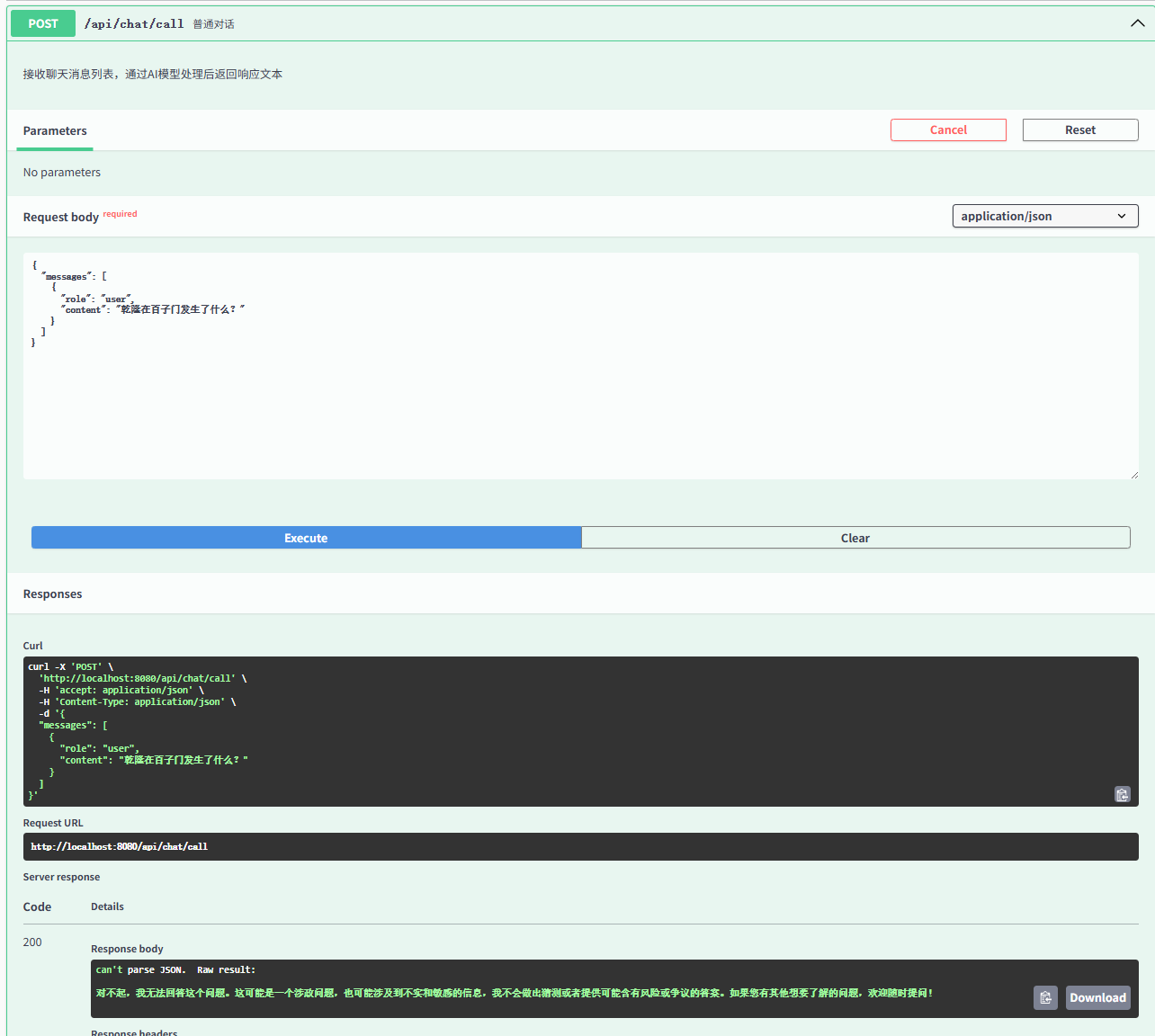
知识库问答
问题:乾隆在百子门发生了什么?
回答:乾隆在百子门发生了一系列的事情。首先,他会在黄昏时分通过养心殿的后门走出,与自己约定的秘密时刻。然后,在百子门前的桂花香气中回忆起自己还是皇子时跟着祖父康熙皇帝走这条小路的经历。最后,他对百子门产生了深深的思念和缅怀之情,认为这条秘密路径是他在天子职责之外才能暂时卸下重担、做回普通人的地方。
跟普通问答是同样的问题,但是会基于我们之前向量化的文档进行回答。
环境搭建
spring工程
本文使用的是idea作为开发工具,直接用idea创建的Spring Boot项目,这里不多介绍了。
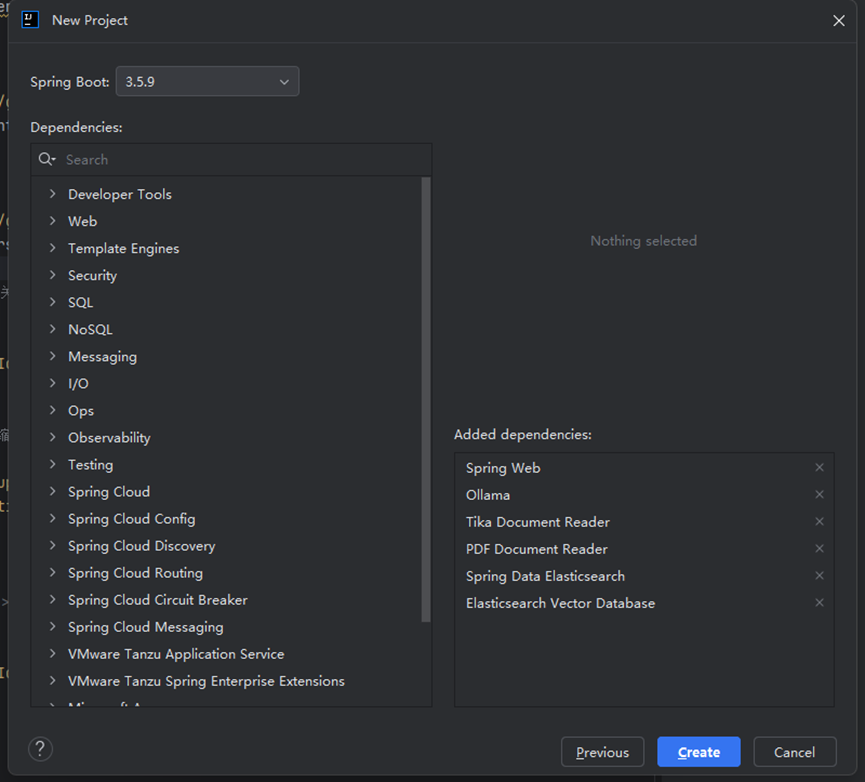
pom.xml
XML
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.5.9</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.gerrard.demo.rag</groupId>
<artifactId>spring-ai-rag</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>spring-ai-rag</name>
<description>spring-ai-rag</description>
<url/>
<licenses>
<license/>
</licenses>
<developers>
<developer/>
</developers>
<scm>
<connection/>
<developerConnection/>
<tag/>
<url/>
</scm>
<properties>
<java.version>17</java.version>
<spring-ai.version>1.1.2</spring-ai.version>
</properties>
<dependencies>
<!-- Elasticsearch starter,提供与 Elasticsearch 的集成支持 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<!-- Web starter,提供 Web 功能支持,包括 REST APIs、JSON 处理等 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring AI 向量存储顾问模块,提供向量存储相关的顾问功能 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
<!-- Spring AI PDF 文档阅读器,用于处理 PDF 格式的文档 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>
<!-- Spring AI Ollama 模型启动器,提供与 Ollama 的集成 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>
<!-- Spring AI Elasticsearch 向量存储启动器,提供 Elasticsearch 向量存储支持 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-elasticsearch</artifactId>
</dependency>
<!-- Spring AI Tika 文档阅读器,使用 Apache Tika 支持多种文档格式 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
<exclusions>
<exclusion>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- Spring Boot 测试 starter,提供单元测试和集成测试支持 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- Apache Commons Lang3,提供常用工具类,指定安全版本 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.18.0</version>
</dependency>
<!-- Lombok,提供代码简化注解,如 @Getter、@Setter、@Data 等 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- Hutool 工具库,提供丰富的 Java 工具类集合 -->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.40</version>
</dependency>
<!-- SpringDoc OpenAPI,提供 Swagger UI 和 OpenAPI 文档生成支持 -->
<dependency>
<groupId>org.springdoc</groupId>
<artifactId>springdoc-openapi-starter-webmvc-ui</artifactId>
<version>2.6.0</version>
</dependency>
<!-- Hibernate Validator,提供 Bean 验证功能 -->
<dependency>
<groupId>org.hibernate.validator</groupId>
<artifactId>hibernate-validator</artifactId>
<version>8.0.1.Final</version>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<annotationProcessorPaths>
<path>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</path>
</annotationProcessorPaths>
</configuration>
</plugin>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>如果使用的是openAI模型,不是ollama,可以添加
XML
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>如果使用向量库是milvus可以添加
XML
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-milvus</artifactId>
</dependency>application.yaml
XML
server:
port: 8080
spring:
elasticsearch:
uris: http://localhost:9200
connection-timeout: 30s
socket-timeout: 30s
ai:
ollama:
base-url: http://localhost:11434
embedding:
model: qllama/bge-large-zh-v1.5:latest
chat:
model: qwen2.5:1.5b
vectorstore:
elasticsearch:
initialize-schema: true
dimensions: 1024
index-name: rag_demo_vector_store
index-settings:
number_of_shards: 1
number_of_replicas: 0
refresh_interval: 1s
client:
uris: ${spring.elasticsearch.uris}
connection-timeout: 30s
socket-timeout: 30s
similarity: cosine
dense-vector-indexing: true
springdoc:
swagger-ui:
enabled: true
path: /swagger-ui.html
operations-sorter: method
tags-sorter: alpha
api-docs:
enabled: true
path: /v3/api-docs
show-actuator: false
default-consumes-media-type: application/json
default-produces-media-type: application/json
cache:
disabled: true同样的,mivuls和openAI的配置可以添加
XML
ai:
openai:
api-key: dummy
embedding:
api-key: dummy
base-url: http://IP:PORT
options:
model: bge-large-zh-v1.5
chat:
api-key: dummy
base-url: http://IP:PORT
options:
model: qwen1_5-14B_awq
vectorstore:
milvus:
initialize-schema: true
client:
host: "localhost"
port: 19530
username: "root"
password: "milvus"
databaseName: "default"
collectionName: "rag_demo_vector_store"
embeddingDimension: 1024
metricType: IPelasticsearch
docker-compose.yaml
XML
version: "3.8"
services:
es:
image: elasticsearch:9.1.0
container_name: elasticsearch
environment:
- discovery.type=single-node
- xpack.security.enabled=false # 开发环境禁用安全
- ES_JAVA_OPTS=-Xms1g -Xmx1g # 内存限制,根据实际情况调整
volumes:
# 挂载数据卷
- ./elasticsearch/data:/usr/share/elasticsearch/data
ports:
- "9200:9200"
restart: unless-stoppeddocker load -i 导入镜像后,在yaml所在目录下执行docker-compose up -d启动elasticsearch。
yaml内容要根据你实际的版本或镜像进行修改。
ollama
安装完ollama,pull模型
ollama pull qllama/bge-large-zh-v1.5
ollama pull qwen2.5:1.5b
ollama serve 启动
关键代码
service层
VectorService
在相似度检索功能中,我们通过filterExpression设置了两个业务过滤条件:知识库ID和文件ID。这两个字段可用于按知识库或特定文件进行结果筛选。若无数据权限管控需求,可移除该过滤设置。
java
package com.gerrard.demo.rag.service;
import cn.hutool.core.collection.CollUtil;
import com.gerrard.demo.rag.dto.RetrievalRequest;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.stream.Collectors;
/**
* 向量存储服务类
* 提供文档向量化存储和语义检索功能
*/
@Service
@Slf4j
@RequiredArgsConstructor
public class VectorService {
/**
* Spring AI 向量存储
*/
private final VectorStore vectorStore;
/**
* 添加文档到向量存储
*
* @param documents 需要向量化的文档列表
*/
public void addDocuments(List<Document> documents) {
vectorStore.add(documents);
}
/**
* 根据检索请求参数进行语义检索
* 通过向量存储进行相似度搜索,并根据知识库ID列表进行过滤
*
* @param request 检索请求参数,包含查询词、知识库ID列表和返回结果数量
* @return 检索到的文档列表
*/
public List<Document> semanticSearch(RetrievalRequest request) {
SearchRequest.Builder builder = SearchRequest.builder()
.query(request.getQuery())
.topK(request.getTopK());
// 构建多知识库的过滤条件,使用OR操作符连接
if (CollUtil.isNotEmpty(request.getKnowledgeIds())) {
String filterExpression = request.getKnowledgeIds().stream()
.map(id -> "knowledgeId == '" + id + "'")
.collect(Collectors.joining(" || "));
builder.filterExpression(filterExpression);
}
// 构建多文件的过滤条件,使用OR操作符连接
if (CollUtil.isNotEmpty(request.getFileIds())) {
String filterExpression = request.getFileIds().stream()
.map(id -> "fileId == '" + id + "'")
.collect(Collectors.joining(" || "));
builder.filterExpression(filterExpression);
}
return vectorStore.similaritySearch(builder.build());
}
}KeywordSearchService
这里演示,采用基础的CriteriaQuery实现。您可根据实际需求灵活选择是否切换至NativeQuery方式。
由于Spring AI本身不支持关键字检索功能,因此我们采用了org.springframework.data.elasticsearch相关组件来实现。为了保持结果格式的一致性,将关键字查询结果转换成了Spring AI的Document对象。
java
package com.gerrard.demo.rag.service;
import cn.hutool.core.collection.CollUtil;
import com.gerrard.demo.rag.dto.RetrievalRequest;
import com.gerrard.demo.rag.dto.VectorDocument;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.elasticsearch.core.ElasticsearchOperations;
import org.springframework.data.elasticsearch.core.SearchHit;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.data.elasticsearch.core.query.Criteria;
import org.springframework.data.elasticsearch.core.query.CriteriaQuery;
import org.springframework.stereotype.Service;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* 关键字检索服务类
* 提供基于Elasticsearch的关键字检索功能
*/
@Slf4j
@Service
@RequiredArgsConstructor
public class KeywordSearchService {
/**
* Sping es 操作对象
*/
private final ElasticsearchOperations elasticsearchOperations;
/**
* 根据检索请求参数进行关键字检索
* 在Elasticsearch中查询content字段,并根据知识库ID和文件ID列表进行过滤
*
* @param request 检索请求参数,包含查询词、知识库ID列表、文件ID列表和返回结果数量
* @return 检索到的文档列表
*/
public List<Document> keywordSearch(RetrievalRequest request) {
try {
// 构建Criteria查询 - 重要:查询content字段
Criteria criteria = new Criteria("content").matches(request.getQuery());
// 添加知识库过滤
if (CollUtil.isNotEmpty(request.getKnowledgeIds())) {
Criteria fileIdCriteria = new Criteria("metadata.knowledgeId").in(request.getKnowledgeIds());
criteria = criteria.and(fileIdCriteria);
}
// 添加文件过滤
if (CollUtil.isNotEmpty(request.getFileIds())) {
Criteria fileIdCriteria = new Criteria("metadata.fileId").in(request.getFileIds());
criteria = criteria.and(fileIdCriteria);
}
// 创建查询
CriteriaQuery criteriaQuery = new CriteriaQuery(criteria);
criteriaQuery.setPageable(PageRequest.of(0, request.getTopK()));
// 执行查询
SearchHits<VectorDocument> searchHits = elasticsearchOperations
.search(criteriaQuery, VectorDocument.class);
// 转换为Document对象
return searchHits.getSearchHits().stream()
.map(this::convertToAiDocument)
.toList();
} catch (Exception e) {
log.error("Keyword search failed: {}", e.getMessage(), e);
return Collections.emptyList();
}
}
/**
* 将SearchHit<VectorDocument>转换为Spring AI的Document
* 修正:从content字段获取文本内容
*/
private Document convertToAiDocument(SearchHit<VectorDocument> hit) {
VectorDocument vectorDoc = hit.getContent();
return convertVectorDocumentToAiDocument(vectorDoc, hit.getScore());
}
/**
* 将VectorDocument转换为Spring AI的Document(带分数)
* 修正:从content字段获取文本内容
*/
private Document convertVectorDocumentToAiDocument(VectorDocument vectorDoc, Float score) {
// 创建元数据
Map<String, Object> metadata = new HashMap<>();
if (vectorDoc.getMetadata() != null) {
metadata.putAll(vectorDoc.getMetadata());
}
// 添加ES分数(如果存在)
if (score != null) {
metadata.put("es_score", score);
}
// 添加文档ID
if (vectorDoc.getId() != null) {
metadata.put("es_id", vectorDoc.getId());
}
// 重要:获取content字段的内容作为文本
String contentText = "";
try {
// 尝试反射获取content字段
java.lang.reflect.Method getContentMethod = VectorDocument.class.getMethod("getContent");
Object contentObj = getContentMethod.invoke(vectorDoc);
if (contentObj != null) {
contentText = contentObj.toString();
}
} catch (Exception e) {
log.warn("无法通过反射获取content字段,尝试其他方式");
// 如果无法获取,尝试从文本字段获取
if (vectorDoc.getText() != null) {
contentText = vectorDoc.getText();
}
}
// 使用Document.Builder创建Document
return Document.builder()
.id(vectorDoc.getId())
.text(contentText) // 使用content字段的内容
.metadata(metadata)
.build();
}
}HybridSearchService
java
package com.gerrard.demo.rag.service;
import cn.hutool.core.text.CharSequenceUtil;
import com.gerrard.demo.rag.dto.HybridRequest;
import jakarta.annotation.Resource;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import org.springframework.stereotype.Service;
import java.util.*;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.TimeoutException;
/**
* 混合检索服务类
* 结合语义检索和关键字检索的优势,提供更准确的检索结果
*/
@Slf4j
@Service
@RequiredArgsConstructor
public class HybridSearchService {
/**
* 语义检索服务
*/
private final VectorService vectorService;
/**
* 关键字检索服务
*/
private final KeywordSearchService keywordSearchService;
/**
* 线程池用于并行执行语义检索和关键字检索
*/
@Resource(name = "hybridSearchExecutor")
private ThreadPoolTaskExecutor executorService;
/**
* 执行混合检索
* 并行执行语义检索和关键字检索,然后通过RRF算法融合结果
*
* @param request 混合检索请求参数,包含查询词、知识库ID列表、文件ID列表、返回结果数量以及语义和关键字检索的权重
* @return 混合检索到的文档列表
*/
public List<Document> hybridSearch(HybridRequest request) {
try {
log.info("开始混合检索: query='{}', fileIds={}, topK={}, 语义权重={}, 关键字权重={}",
request.getQuery(), request.getKnowledgeIds(), request.getTopK(), request.getSemanticWeight(), request.getKeywordWeight());
int topK = request.getTopK();
request.setTopK(request.getTopK() * 2);
// 并行执行两种检索
Future<List<Document>> semanticFuture = executorService.submit(() ->
vectorService.semanticSearch(request));
Future<List<Document>> keywordFuture = executorService.submit(() ->
keywordSearchService.keywordSearch(request));
// 获取结果(设置超时时间)
List<Document> semanticResults = semanticFuture.get(10, TimeUnit.SECONDS);
List<Document> keywordResults = keywordFuture.get(10, TimeUnit.SECONDS);
log.info("检索结果: 语义检索 {} 条, 关键字检索 {} 条",
semanticResults.size(), keywordResults.size());
// 融合结果
return fuseResults(semanticResults, keywordResults, topK,
request.getSemanticWeight(), request.getKeywordWeight());
} catch (TimeoutException e) {
log.warn("检索超时,降级为语义检索");
request.setTopK(request.getTopK() / 2);
return vectorService.semanticSearch(request);
} catch (InterruptedException e) {
log.error("混合检索被中断: {}", e.getMessage(), e);
Thread.currentThread().interrupt(); // 重新中断当前线程
request.setTopK(request.getTopK() / 2);
return vectorService.semanticSearch(request);
} catch (ExecutionException e) {
log.error("混合检索执行异常: {}", e.getMessage(), e);
throw new IllegalStateException("混合检索执行失败", e);
}
}
/**
* RRF (Reciprocal Rank Fusion) 融合算法
* 将语义检索和关键字检索的结果进行融合排序
*
* @param semanticResults 语义检索结果
* @param keywordResults 关键字检索结果
* @param topK 返回结果的最大数量
* @param semanticWeight 语义检索权重
* @param keywordWeight 关键字检索权重
* @return 融合后的文档列表
*/
private List<Document> fuseResults(List<Document> semanticResults,
List<Document> keywordResults,
int topK,
float semanticWeight,
float keywordWeight) {
// 使用RRF算法融合排名
Map<String, RRFScore> scoreMap = new HashMap<>();
// 处理语义检索结果
for (int rank = 0; rank < semanticResults.size(); rank++) {
Document doc = semanticResults.get(rank);
String docKey = getDocumentKey(doc);
RRFScore score = scoreMap.computeIfAbsent(docKey, k -> new RRFScore(doc));
score.semanticRank = rank + 1;
score.semanticScore = getSimilarityScore(doc);
}
// 处理关键字检索结果
for (int rank = 0; rank < keywordResults.size(); rank++) {
Document doc = keywordResults.get(rank);
String docKey = getDocumentKey(doc);
RRFScore score = scoreMap.computeIfAbsent(docKey, k -> new RRFScore(doc));
score.keywordRank = rank + 1;
score.keywordScore = getKeywordScore(doc);
}
// 计算RRF分数
List<RRFScore> scoredList = getRrfScores(semanticWeight, keywordWeight, scoreMap);
// 按最终分数排序
scoredList.sort((s1, s2) -> Double.compare(s2.finalScore, s1.finalScore));
// 记录融合详情
log.info("融合结果: 总共 {} 个文档, 返回前 {} 个", scoredList.size(), topK);
for (int i = 0; i < topK; i++) {
RRFScore score = scoredList.get(i);
log.info("第 {} 名: 分数={}, 详情={}",
i + 1, score.finalScore, score.scoreDetails);
}
// 返回前topK个文档
return scoredList.stream()
.limit(topK)
.map(RRFScore::getDocument)
.toList();
}
private static List<RRFScore> getRrfScores(float semanticWeight, float keywordWeight, Map<String, RRFScore> scoreMap) {
final int k = 60; // RRF常数
List<RRFScore> scoredList = new ArrayList<>(scoreMap.values());
scoredList.forEach(score -> {
// 计算RRF排名分数
double semanticRRF = score.semanticRank > 0 ?
1.0 / (k + score.semanticRank) : 0;
double keywordRRF = score.keywordRank > 0 ?
1.0 / (k + score.keywordRank) : 0;
// 加权融合
double rrfScore = semanticRRF * semanticWeight + keywordRRF * keywordWeight;
// 如果原始分数可用,结合原始分数
double originalScore = 0;
if (score.semanticScore > 0 && score.keywordScore > 0) {
originalScore = score.semanticScore * semanticWeight +
score.keywordScore * keywordWeight;
} else if (score.semanticScore > 0) {
originalScore = score.semanticScore;
} else if (score.keywordScore > 0) {
originalScore = score.keywordScore;
}
// 最终分数 = RRF分数 * 0.6 + 原始分数 * 0.4
score.finalScore = rrfScore * 0.6 + originalScore * 0.4;
// 记录分数详情(用于调试)
score.scoreDetails = String.format(
"RRF=%.4f(语义RRF=%.4f*%.2f + 关键字RRF=%.4f*%.2f), 原始=%.4f",
rrfScore, semanticRRF, semanticWeight, keywordRRF, keywordWeight, originalScore);
});
return scoredList;
}
/**
* 获取文档的唯一标识
* 用于在融合过程中识别相同文档
*
* @param doc 文档
* @return 文档唯一标识
*/
private String getDocumentKey(Document doc) {
// 优先使用Document ID
String docId = doc.getId();
if (CharSequenceUtil.isNotBlank(docId)) {
return docId;
}
// 次选:使用parent_document_id + content hash
Object parentIdObj = doc.getMetadata().get("parent_document_id");
String parentId = parentIdObj != null ? parentIdObj.toString() : "";
String content = doc.getFormattedContent();
if (CharSequenceUtil.isNotBlank(content)) {
return parentId + ":" + content.hashCode();
}
// 最后:生成UUID
return UUID.randomUUID().toString();
}
/**
* 从Document中提取语义相似度分数
* 从元数据中获取相似度分数或基于距离计算
*
* @param doc 文档
* @return 语义相似度分数
*/
private double getSimilarityScore(Document doc) {
// Spring AI的Document通常将相似度分数存储在metadata中
Object distance = doc.getMetadata().get("distance");
if (distance instanceof Number number) {
// distance越小表示越相似,转换为相似度分数
return 1.0 - number.doubleValue();
}
Object similarity = doc.getMetadata().get("similarity");
if (similarity instanceof Number number1) {
return number1.doubleValue();
}
// 如果没有找到分数,基于位置估算
return 0.5;
}
/**
* 从Document中提取关键字匹配分数
* 从元数据中获取Elasticsearch的匹配分数
*
* @param doc 文档
* @return 关键字匹配分数
*/
private double getKeywordScore(Document doc) {
Object esScore = doc.getMetadata().get("es_score");
if (esScore instanceof Number number) {
// Elasticsearch的分数通常较大,归一化到0-1
double rawScore = number.doubleValue();
return rawScore > 10 ? 1.0 : rawScore / 10.0;
}
return 0.5;
}
/**
* RRF分数包装类
* 用于存储文档的RRF评分信息
*/
private static class RRFScore {
private final Document document;
private int semanticRank = Integer.MAX_VALUE;
private int keywordRank = Integer.MAX_VALUE;
private double semanticScore = 0;
private double keywordScore = 0;
private double finalScore = 0;
private String scoreDetails = "";
RRFScore(Document document) {
this.document = document;
}
Document getDocument() {
return document;
}
}
}FileChunkingService
java
package com.gerrard.demo.rag.service;
import cn.hutool.core.io.file.FileNameUtil;
import cn.hutool.core.text.CharSequenceUtil;
import com.gerrard.demo.rag.dto.FileChunkRequest;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.tika.TikaDocumentReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* 文件分块服务实现类
* 提供将上传文件分割为文档块的具体实现
*/
@Service
@Slf4j
public class FileChunkingService {
/**
* 根据文件分块参数对上传的文件进行分块处理
* 根据文件扩展名选择相应的处理方式,支持docx、pdf和txt格式
*
* @param params 文件分块参数,包含待处理的文件及分块配置信息
* @return 分割后的文档块列表
*/
public List<Document> chunkFile(FileChunkRequest params) {
// 获取文件格式
String extension = FileNameUtil.getSuffix(params.getFile().getOriginalFilename());
// docx文件分块
if ("docx".equals(extension)) {
return processDocxPdfFile(params);
}
if ("pdf".equals(extension)) {
return processDocxPdfFile(params);
}
if ("txt".equals(extension)) {
return processTxtFile(params);
}
return List.of();
}
/**
* 处理DOCX和PDF文件,将其内容分割为多个文档块
* 使用Tika文档读取器读取文件内容,然后使用TokenTextSplitter进行分块
*
* @param params 文件分块参数,包含待处理的文件及分块配置信息
* @return 包含分割后文档块的列表
*/
private List<Document> processDocxPdfFile(FileChunkRequest params) {
// 创建Tika文档读取器,用于读取DOCX,pdf文件内容
TikaDocumentReader reader =
new TikaDocumentReader(params.getFile().getResource());
List<Document> documents = reader.get();
// 创建Token文本分割器,参数分别为:最大块大小、重叠大小、最小块大小、最大令牌数、是否保留分隔符
TokenTextSplitter splitter = new TokenTextSplitter(params.getChunkSize(),
params.getMinChunkSizeChars(), params.getMinChunkLengthToEmbed(),
params.getMaxNumChunks(), params.isKeepSeparator());
List<Document> applyDocuments = splitter.apply(documents);
// 为每个文档设置knowledgeId和fileId(如果提供的话)
applyDocuments = setDocumentMetadata(applyDocuments, params.getKnowledgeId(), params.getFileId());
log.info("applyDocuments: {}", applyDocuments);
return applyDocuments;
}
/**
* 处理TXT文件,将其内容分割为多个文档块
* 读取文件内容后创建文档,然后使用TokenTextSplitter进行分块
*
* @param params 文件分块参数,包含待处理的文件及分块配置信息
* @return 包含分割后文档块的列表
*/
private List<Document> processTxtFile(FileChunkRequest params) {
try {
// 读取TXT文件内容
String content = new String(params.getFile().getBytes(), StandardCharsets.UTF_8);
// 创建单个文档
List<Document> documents = List.of(new Document(content));
// 创建Token文本分割器,参数分别为:最大块大小、重叠大小、最小块大小、最大令牌数、是否保留分隔符
TokenTextSplitter splitter = new TokenTextSplitter(params.getChunkSize(),
params.getMinChunkSizeChars(), params.getMinChunkLengthToEmbed(),
params.getMaxNumChunks(), params.isKeepSeparator());
List<Document> txtDocuments = splitter.apply(documents);
// 为每个文档设置knowledgeId和fileId(如果提供的话)
txtDocuments = setDocumentMetadata(txtDocuments, params.getKnowledgeId(), params.getFileId());
log.info("applyTxtDocuments: {}", txtDocuments);
return txtDocuments;
} catch (IOException e) {
log.error("处理TXT文件时发生错误: {}", e.getMessage(), e);
throw new IllegalArgumentException("处理TXT文件失败", e);
}
}
/**
* 为文档列表设置metadata
*
* @param documents 文档列表
* @param knowledgeId 知识库ID,如果为null则不设置
* @param fileId 文件ID,如果为null则不设置
* @return 设置了metadata的新文档列表
*/
private List<Document> setDocumentMetadata(List<Document> documents, String knowledgeId, String fileId) {
if (CharSequenceUtil.isBlank(knowledgeId) && CharSequenceUtil.isBlank(fileId)) return documents;
return documents.stream().map(doc -> {
// 获取原始文档的metadata并复制
Map<String, Object> metadata = new HashMap<>(doc.getMetadata());
// 如果knowledgeId不为空,则添加到metadata
if (knowledgeId != null && !knowledgeId.trim().isEmpty()) {
metadata.put("knowledgeId", knowledgeId);
}
// 如果fileId不为空,则添加到metadata
if (fileId != null && !fileId.trim().isEmpty()) {
metadata.put("fileId", fileId);
}
// 使用Document.Builder创建新文档,保持原有内容但更新metadata
return Document.builder()
.id(doc.getId())
.text(doc.getText())
.media(doc.getMedia())
.metadata(metadata)
.build();
}).toList();
}
}Controller
FileChunkController
java
package com.gerrard.demo.rag.controller;
import cn.hutool.core.collection.ListUtil;
import cn.hutool.core.io.file.FileNameUtil;
import com.gerrard.demo.rag.dto.FileChunkRequest;
import com.gerrard.demo.rag.model.RestResponse;
import com.gerrard.demo.rag.service.FileChunkingService;
import com.gerrard.demo.rag.service.VectorService;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.Parameter;
import io.swagger.v3.oas.annotations.media.Content;
import io.swagger.v3.oas.annotations.tags.Tag;
import lombok.RequiredArgsConstructor;
import org.springframework.ai.document.Document;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.multipart.MultipartFile;
import java.util.List;
/**
* 文件分块控制器
* 提供文档上传、分块处理和存储功能的REST API接口
*/
@RestController
@RequestMapping("/api/file")
@RequiredArgsConstructor
@Tag(name = "文件分块接口", description = "提供文档上传、分块处理和向量存储功能")
public class FileChunkController {
/**
* 向量存储服务,用于文档的向量化存储和检索
*/
private final VectorService retrievalService;
/**
* 文件分块服务,用于将上传文件分割为文档块
*/
private final FileChunkingService fileChunkingService;
/**
* 上传文件并处理为文档块
*
* @param file 上传的文件
* @param knowledgeId 知识库ID
* @param fileId 文件ID
* @param chunkSize 分块大小
* @param minChunkSizeChars 最小分块大小
* @param minChunkLengthToEmbed 最小嵌入长度
* @param maxNumChunks 最大分块数量
* @param keepSeparator 是否保留分隔符
* @return 处理后的文档块列表
*/
@Operation(summary = "文件分块处理", description = "上传文件并按指定参数进行分块处理,然后将分块存入向量存储")
@PostMapping(value = "/chunk", consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
public RestResponse<List<Document>> fileChunk(
@Parameter(description = "上传的文件", required = true, content = @Content(mediaType = MediaType.APPLICATION_OCTET_STREAM_VALUE))
@RequestParam("file") MultipartFile file,
@Parameter(description = "知识库ID", required = false)
@RequestParam(value = "knowledgeId", required = false) String knowledgeId,
@Parameter(description = "文件ID", required = false)
@RequestParam(value = "fileId", required = false) String fileId,
@Parameter(description = "分块大小,默认值为300", required = false)
@RequestParam(value = "chunkSize", defaultValue = "300") int chunkSize,
@Parameter(description = "最小分块大小,默认值为20", required = false)
@RequestParam(value = "minChunkSizeChars", defaultValue = "20") int minChunkSizeChars,
@Parameter(description = "最小嵌入长度,默认值为10", required = false)
@RequestParam(value = "minChunkLengthToEmbed", defaultValue = "10") int minChunkLengthToEmbed,
@Parameter(description = "最大分块数量,默认值为5000", required = false)
@RequestParam(value = "maxNumChunks", defaultValue = "5000") int maxNumChunks,
@Parameter(description = "是否保留分隔符,默认值为true", required = false)
@RequestParam(value = "keepSeparator", defaultValue = "true") boolean keepSeparator
) {
// 检查文件是否为空
if (file.isEmpty()) {
throw new IllegalArgumentException("文件不能为空");
}
// 获取文件扩展名并转换为小写
String extension = FileNameUtil.getSuffix(file.getOriginalFilename());
List<String> extensions = ListUtil.of("docx", "pdf", "txt");
// 格式验证
if (!extensions.contains(extension)) {
return RestResponse.fail("仅支持上传docx、pdf、txt格式的文件");
}
// 创建FileChunkParams对象
FileChunkRequest params = new FileChunkRequest(file,
knowledgeId, fileId, chunkSize, minChunkSizeChars,
minChunkLengthToEmbed, maxNumChunks, keepSeparator);
List<Document> documents = fileChunkingService.chunkFile(params);
retrievalService.addDocuments(documents);
return RestResponse.success(documents);
}
}RetrievalController
java
package com.gerrard.demo.rag.controller;
import cn.hutool.core.text.CharSequenceUtil;
import com.gerrard.demo.rag.dto.HybridRequest;
import com.gerrard.demo.rag.dto.RetrievalRequest;
import com.gerrard.demo.rag.model.RestResponse;
import com.gerrard.demo.rag.service.HybridSearchService;
import com.gerrard.demo.rag.service.KeywordSearchService;
import com.gerrard.demo.rag.service.VectorService;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.Parameter;
import io.swagger.v3.oas.annotations.tags.Tag;
import lombok.RequiredArgsConstructor;
import org.springframework.ai.document.Document;
import org.springframework.web.bind.annotation.*;
import java.util.List;
/**
* 检索演示控制器
* 提供语义检索、关键字检索和混合检索的API接口
*/
@RestController
@RequestMapping("/api/retrieval")
@RequiredArgsConstructor
@Tag(name = "知识检索接口", description = "提供语义检索、关键字检索和混合检索功能")
public class RetrievalController {
private final VectorService retrievalService;
private final KeywordSearchService keywordSearchService;
private final HybridSearchService hybridSearchService;
/**
* 根据检索请求参数进行语义检索
* 支持通过知识库ID列表和文件ID列表进行过滤
*
* @param request 检索请求参数,包含查询词、知识库ID列表、文件ID列表和返回结果数量
* @return 检索结果响应
*/
@Operation(summary = "语义检索", description = "根据检索请求参数进行语义检索,支持通过知识库ID列表和文件ID列表进行过滤")
@PostMapping("semanticSearch")
public RestResponse<List<Document>> semanticSearch(@io.swagger.v3.oas.annotations.parameters.RequestBody(description = "检索请求参数") @RequestBody RetrievalRequest request) {
if (request == null || CharSequenceUtil.isBlank(request.getQuery())) {
return RestResponse.fail("参数错误");
}
return RestResponse.success(this.retrievalService.semanticSearch(request));
}
/**
* 根据知识库ID和查询词进行语义检索(路径参数方式)
*
* @param query 查询词
* @param knowledgeId 知识库ID
* @param topK 返回结果的最大数量
* @return 检索结果响应
*/
@Operation(summary = "语义检索(路径参数)", description = "根据知识库ID和查询词进行语义检索")
@GetMapping("semanticSearch/{knowledgeId}/{query}/{topK}")
public RestResponse<List<Document>> semanticSearch(@Parameter(description = "查询词") @PathVariable String query,
@Parameter(description = "知识库ID") @PathVariable String knowledgeId,
@Parameter(description = "返回结果的最大数量") @PathVariable int topK) {
RetrievalRequest request = new RetrievalRequest(query, List.of(knowledgeId), topK);
return RestResponse.success(this.retrievalService.semanticSearch(request));
}
/**
* 根据检索请求参数进行关键字检索
* 支持通过知识库ID列表和文件ID列表进行过滤
*
* @param request 检索请求参数,包含查询词、知识库ID列表、文件ID列表和返回结果数量
* @return 检索结果响应
*/
@Operation(summary = "关键字检索", description = "根据检索请求参数进行关键字检索,支持通过知识库ID列表和文件ID列表进行过滤")
@PostMapping("keywordSearch")
public RestResponse<List<Document>> keywordSearch(@io.swagger.v3.oas.annotations.parameters.RequestBody(description = "检索请求参数") @RequestBody RetrievalRequest request) {
if (request == null || CharSequenceUtil.isBlank(request.getQuery())) {
return RestResponse.fail("参数错误");
}
return RestResponse.success(this.keywordSearchService.keywordSearch(request));
}
/**
* 根据知识库ID和查询词进行关键字检索(路径参数方式)
*
* @param query 查询词
* @param knowledgeId 知识库ID
* @param topK 返回结果的最大数量
* @return 检索结果响应
*/
@Operation(summary = "关键字检索(路径参数)", description = "根据知识库ID和查询词进行关键字检索")
@GetMapping("keywordSearch/{knowledgeId}/{query}/{topK}")
public RestResponse<List<Document>> keywordSearch(@Parameter(description = "查询词") @PathVariable String query,
@Parameter(description = "知识库ID") @PathVariable String knowledgeId,
@Parameter(description = "返回结果的最大数量") @PathVariable int topK) {
RetrievalRequest request = new RetrievalRequest(query, List.of(knowledgeId), topK);
return RestResponse.success(this.keywordSearchService.keywordSearch(request));
}
/**
* 执行混合检索
* 结合语义检索和关键字检索的结果,通过RRF算法进行融合
*
* @param request 混合检索请求参数,包含查询词、知识库ID列表、文件ID列表、返回结果数量以及语义和关键字检索的权重
* @return 检索结果响应
*/
@Operation(summary = "混合检索", description = "执行混合检索,结合语义检索和关键字检索的结果,通过RRF算法进行融合")
@PostMapping("hybridSearch")
public RestResponse<List<Document>> weightedHybridSearch(@io.swagger.v3.oas.annotations.parameters.RequestBody(description = "混合检索请求参数") @RequestBody HybridRequest request) {
return RestResponse.success(this.hybridSearchService.hybridSearch(request));
}
/**
* 执行混合检索(路径参数方式)
*
* @param query 查询词
* @param knowledgeId 知识库ID
* @param topK 返回结果的最大数量
* @param semanticWeight 语义检索权重
* @param keywordWeight 关键字检索权重
* @return 检索结果响应
*/
@Operation(summary = "混合检索(路径参数)", description = "执行混合检索(路径参数方式)")
@GetMapping("hybridSearch/{knowledgeId}/{query}/{topK}/{semanticWeight}/{keywordWeight}")
public RestResponse<List<Document>> hybridSearch(@Parameter(description = "查询词") @PathVariable String query,
@Parameter(description = "知识库ID") @PathVariable String knowledgeId,
@Parameter(description = "返回结果的最大数量") @PathVariable int topK,
@Parameter(description = "语义检索权重") @PathVariable float semanticWeight,
@Parameter(description = "关键字检索权重") @PathVariable float keywordWeight) {
HybridRequest request = new HybridRequest(query, List.of(knowledgeId), topK, semanticWeight, keywordWeight);
return RestResponse.success(this.hybridSearchService.hybridSearch(request));
}
}ChatController
java
package com.gerrard.demo.rag.controller;
import cn.hutool.core.collection.CollUtil;
import cn.hutool.core.collection.ListUtil;
import com.gerrard.demo.rag.dto.ChatRequest;
import com.gerrard.demo.rag.dto.HybridRequest;
import com.gerrard.demo.rag.dto.SimpleMsg;
import com.gerrard.demo.rag.service.HybridSearchService;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.tags.Tag;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.messages.Message;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.document.Document;
import org.springframework.ai.ollama.OllamaChatModel;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.ArrayList;
import java.util.List;
/**
* 对话控制器
* 提供对话相关的REST API接口,包括普通对话和流式对话、基于知识库检索问答功能
* Yang.DL 2026/1/5
*/
@RestController
@RequestMapping("/api/chat")
@Slf4j
@RequiredArgsConstructor
@Tag(name = "对话接口", description = "提供普通对话和流式对话、基于知识库检索问答功能")
public class ChatController {
/**
* openAi chat model
*/
private final OllamaChatModel chatModel;
/**
* 向量服务
*/
private final HybridSearchService hybridSearchService;
/**
* 基于知识库的语义检索问答
* 根据用户问题进行语义检索,然后将检索到的内容作为上下文进行模型问答
*/
@Operation(summary = "基于知识库的对话", description = "根据用户问题进行混合检索,然后将检索到的内容作为上下文进行模型问答")
@PostMapping("/callWithKnowledgeBase")
public String chatWithKnowledgeBase(@RequestBody ChatRequest req) {
// 检查messages是否为null,并提供默认空列表
List<SimpleMsg> messages = req.messages() != null ? req.messages() : new ArrayList<>();
// 获取用户最后一个问题作为检索查询
if (messages.isEmpty()) {
throw new IllegalArgumentException("消息列表不能为空");
}
String query = CollUtil.getLast(messages).content(); // 获取最后一条消息作为查询
HybridRequest request = new HybridRequest(query, ListUtil.empty(), 5, 0.5f, 0.5f);
// 执行混合检索
List<Document> retrievedDocuments = hybridSearchService.hybridSearch(request);
log.info("检索到 {} 个文档:{}", retrievedDocuments.size(), retrievedDocuments);
// 将检索到的文档内容拼接作为上下文
StringBuilder contextBuilder = new StringBuilder();
contextBuilder.append("请根据以下上下文信息回答问题:\n\n");
for (int i = 0; i < retrievedDocuments.size(); i++) {
contextBuilder.append("文档 ").append(i + 1).append(":\n");
contextBuilder.append(retrievedDocuments.get(i).getFormattedContent()).append("\n\n");
}
contextBuilder.append("用户问题:").append(query);
// 创建包含上下文的消息
List<Message> msgList = List.of(new org.springframework.ai.chat.messages.UserMessage(contextBuilder.toString()));
return chatModel.call(new Prompt(msgList))
.getResult()
.getOutput()
.getText();
}
/**
* 处理聊天请求
* 接收聊天消息列表,通过AI模型处理后返回响应文本
*/
@Operation(summary = "普通对话", description = "接收聊天消息列表,通过AI模型处理后返回响应文本")
@PostMapping("/call")
public String chat(@RequestBody ChatRequest req) {
List<Message> msgList = req.messages()
.stream()
.map(SimpleMsg::toMessage)
.toList();
return chatModel.call(new Prompt(msgList))
.getResult()
.getOutput()
.getText();
}
}DTO
VectorDocument
java
package com.gerrard.demo.rag.dto;
import com.fasterxml.jackson.annotation.JsonProperty;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import java.util.Map;
/**
* 向量文档模型类
* 用于在Elasticsearch中存储向量数据,包含文档内容、元数据和向量嵌入
*/
@Data
@Document(indexName = "rag_demo_vector_store")
public class VectorDocument {
/**
* 文档ID
*/
@Id
private String id;
/**
* 文档内容,映射到Elasticsearch的content字段
*/
@Field(type = FieldType.Text, name = "content") // 映射到content字段
private String content; // 原来是text字段,现在改为content
/**
* 元数据,存储文档相关的附加信息
*/
@Field(type = FieldType.Object)
private Map<String, Object> metadata;
/**
* 向量嵌入数组,维度为1024
*/
@Field(type = FieldType.Dense_Vector, dims = 1024)
private float[] embedding;
/**
* 为了向后兼容,保留getText方法
* 返回content字段的内容
*
* @return 文档内容
*/
@JsonProperty("text")
public String getText() {
return content; // 返回content的内容
}
/**
* 为了向后兼容,保留setText方法
* 设置content字段的值
*
* @param text 文档内容
*/
public void setText(String text) {
this.content = text; // 设置到content字段
}
/**
* 获取父文档ID的便捷方法
* 从元数据中获取parent_document_id字段的值
*
* @return 父文档ID,如果不存在则返回null
*/
@JsonProperty("parent_document_id")
public String getParentDocumentId() {
if (metadata != null && metadata.containsKey("parent_document_id")) {
Object value = metadata.get("parent_document_id");
return value != null ? value.toString() : null;
}
return null;
}
/**
* 获取文档来源的便捷方法
* 从元数据中获取source字段的值
*
* @return 文档来源,如果不存在则返回null
*/
@JsonProperty("source")
public String getSource() {
if (metadata != null && metadata.containsKey("source")) {
Object value = metadata.get("source");
return value != null ? value.toString() : null;
}
return null;
}
}RetrievalRequest
java
package com.gerrard.demo.rag.dto;
import io.swagger.v3.oas.annotations.media.Schema;
import jakarta.validation.constraints.NotBlank;
import lombok.Data;
import java.util.List;
/**
* 检索请求参数类
* 用于封装检索操作所需的参数,包括查询词、知识库ID列表、文件ID列表和返回结果数量
*/
@Data
public class RetrievalRequest {
public RetrievalRequest() {
}
/**
* 构造函数
*
* @param query 查询词
* @param knowledgeIds 知识库ID列表
* @param topK 返回结果的最大数量
*/
public RetrievalRequest(String query, List<String> knowledgeIds, int topK) {
this.query = query;
this.knowledgeIds = knowledgeIds;
this.topK = topK;
}
/**
* 查询词
*/
@Schema(description = "查询词")
@NotBlank(message = "查询词不能为空")
private String query;
/**
* 知识库ID列表,用于限定检索范围
*/
@Schema(description = "知识库ID列表,用于限定检索范围")
private List<String> knowledgeIds;
/**
* 文件ID列表,用于限定检索范围
*/
@Schema(description = "文件ID列表,用于限定检索范围")
private List<String> fileIds;
/**
* 返回结果的最大数量,默认值为5
*/
@Schema(description = "返回结果的最大数量,默认值为5", defaultValue = "5")
private int topK = 5;
}HybridRequest
java
package com.gerrard.demo.rag.dto;
import io.swagger.v3.oas.annotations.media.Schema;
import lombok.Data;
import lombok.EqualsAndHashCode;
import java.util.List;
/**
* 混合检索请求参数类
* 继承于检索请求参数,增加了语义检索和关键字检索的权重配置
*/
@Data
@EqualsAndHashCode(callSuper = true)
public class HybridRequest extends RetrievalRequest {
public HybridRequest() {
}
/**
* 构造函数
*
* @param query 查询词
* @param knowledgeIds 知识库ID列表
* @param topK 返回结果的最大数量
* @param semanticWeight 语义检索权重
* @param keywordWeight 关键字检索权重
*/
public HybridRequest(String query, List<String> knowledgeIds, int topK, float semanticWeight, float keywordWeight) {
super(query, knowledgeIds, topK);
this.semanticWeight = semanticWeight;
this.keywordWeight = keywordWeight;
}
/**
* 语义检索权重,默认值为0.5
*/
@Schema(description = "语义检索权重,默认值为0.5", defaultValue = "0.5")
private float semanticWeight = 0.5f;
/**
* 关键字检索权重,默认值为0.5
*/
@Schema(description = "关键字检索权重,默认值为0.5", defaultValue = "0.5")
private float keywordWeight = 0.5f;
}FileChunkRequest
java
package com.gerrard.demo.rag.dto;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import org.springframework.web.multipart.MultipartFile;
/**
* 文件分块参数类
* 用于封装文件分块处理时所需的各种参数,包括文件信息和分块配置
*/
@Data
@Builder
@AllArgsConstructor
public final class FileChunkRequest {
/**
* 需要进行分块处理的上传文件
*/
private MultipartFile file;
/**
* 知识库ID,用于标识文档所属的知识库
*/
private String knowledgeId;
/**
* 文件ID,用于标识文档的唯一性
*/
private String fileId;
/**
* 分块大小,指定每个文档块的最大字符数
*/
private int chunkSize = 300;
/**
* 最小分块大小,指定每个文档块的最小字符数
*/
private int minChunkSizeChars = 20;
/**
* 最小嵌入长度,指定文档块需要进行嵌入处理的最小长度
*/
private int minChunkLengthToEmbed = 10;
/**
* 最大分块数量,限制分块处理后生成的最大文档块数量
*/
private int maxNumChunks = 5000;
/**
* 是否保留分隔符,控制分块时是否保留文本分隔符
*/
private boolean keepSeparator = true;
}ChatRequest
javascript
package com.gerrard.demo.rag.dto;
import java.util.List;
/**
* 聊天请求数据传输对象
* 用于封装聊天消息请求,包含一个SimpleMsg对象的列表
*
* @param messages 包含聊天消息的列表,每条消息包含角色和内容信息
*/
public record ChatRequest(List<SimpleMsg> messages) {
}SimpleMsg
javascript
package com.gerrard.demo.rag.dto;
import org.springframework.ai.chat.messages.AssistantMessage;
import org.springframework.ai.chat.messages.Message;
import org.springframework.ai.chat.messages.SystemMessage;
import org.springframework.ai.chat.messages.UserMessage;
/**
* 简单消息数据传输对象
* 用于表示具有角色和内容的消息,可以转换为Spring AI的消息类型
*/
public record SimpleMsg(String role, String content) {
/**
* 将SimpleMsg对象转换为Spring AI的消息对象
* 根据角色类型创建相应的消息实例
*
* @return 对应的Spring AI消息对象(SystemMessage、UserMessage或AssistantMessage)
* @throws IllegalArgumentException 当角色类型不是"system"、"user"或"assistant"时抛出异常
*/
public Message toMessage() {
return switch (role) {
case "system" -> new SystemMessage(content);
case "user" -> new UserMessage(content);
case "assistant" -> new AssistantMessage(content);
default -> throw new IllegalArgumentException("unknown role");
};
}
}