2025期末
汉诺塔之最少移动次数
本题要求实现一个函数,计算将 n 个盘子从汉诺塔的第一根柱子移动到第三根柱子所需的最少移动次数。移动必须遵守以下规则:
1)每次只能移动一个盘子;
2)任何时候大盘都不能放在小盘之上。
函数接口定义:
c
long long hanoi_moves(int n);其中 n 是用户传入的参数,为 1, 30 的正整数。函数应返回完成任务所需的最少移动次数(结果保证在 long long 范围内)。
裁判测试程序样例:
c
#include <stdio.h>
#include <stdlib.h>
long long hanoi_moves(int n);
int main() {
int n; scanf("%d", &n);
printf("%lld\n", hanoi_moves(n));
return 0;
}
/* 提交的实现函数的代码将自动补充在此处,从而使得以上代码能运行并实现指定功能。*/输入样例:
plain
3输出样例:
plain
7思路:
经典汉诺塔最少移动次数满足递推:
- 把 n 个盘从 1 移到 3:
- 先把上面 n-1 个从 1 移到 2(借助 3)→ 需要
T(n-1)步 - 再把最大的第 n 个从 1 移到 3 → 1 步
- 最后把 n-1 个从 2 移到 3(借助 1)→ 需要
T(n-1)步
- 先把上面 n-1 个从 1 移到 2(借助 3)→ 需要
所以:
T(n)=T(n−1)+1+T(n−1)=2T(n−1)+1
且 T(1)=1
这个递推的闭式解是:
T(n)= 2 n 2^n 2n -1
因为 n ∈ [1,30],2^30-1 = 1073741823,远小于 long long 上限,安全。
实现上最简单就是用位运算算 2^n:
1LL << n等于2^n- 答案就是
(1LL << n) - 1
c
long long hanoi_moves(int n)
{
return (1LL << n) - 1;
}合二为一
两个不同的事物突破界限,合二为一,融合在一起,从而构成一个具有新质态的整体,这是一种普遍存在的客观规律。
例如,两种不同的金属经过熔炼融合,能够生成具备特殊物理化学特性的合金;双声道音频合并为单声道音频。
中华民族的形成,正是各族群在历史长河中不断交融与发展而成的;
同样,人类的思想与文明也从未停止过交流与融合的脚步。
将给定的两行文本逐字符交替合并,融合为一行新文本。
本题要求实现一个函数mergeString(s1,s2),其功能为将字符串s1,s2逐字符合并,结果字符串存放在动态分配的存储空间中,返回结果字符串的首地址。请注意结果字符串的末尾须有表示字符串结束的空字符。
提示:实现动态内存分配的C语言库函数为malloc(),其函数原型为void *malloc(unsigned int size),其作用是在内存的动态存储区中分配一个长度为size的连续空间。此函数的返回值是分配区域的起始地址,或者说,返回的指针指向该分配区域的开始处。
malloc()函数的用法示例如下代码片段所示,实现了能根据用户输入的数据个数,动态创建能存放n个整数的存储空间,指针a指向此存储空间首地址,再将数组中元素依次赋值为1,2,...,n。
c
int n,i;
int *a;
scanf("%d",&n);
a=(int*)malloc(n*sizeof(int));
for(i=0;i<n;i++)
a[i]=i+1;函数接口定义:
c
char * mergeString(char * s1,char * s2);参数s1,s2分别为存放了第1行文本与第2行文本的字符数组的首地址。
裁判测试程序样例:
c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
char * mergeString(char * s1,char * s2);
int main(){
char s1[101],s2[101],*res;
gets(s1);//输入第1行字符串到字符数组s1中
gets(s2);//输入第2行字符串到字符数组s2中
res=mergeString(s1,s2);//将字符串s1,s2逐字符合并,返回结果字符串的首地址
printf("%s",res);//输出合并后的字符串
free(res);//释放res所指的动态分配的存储空间
return 0;
}
/* 提交的实现函数的代码将自动补充在此处,从而使得以上代码能运行并实现指定功能。*/输入样例1:
plain
12345678
abcdef ghijk输出样例1:
plain
1a2b3c4d5e6f7 8ghijk输入样例2:
plain
Good Good Study
Day Day Up输出样例2:
plain
GDoaoyd DGaoyo dU pStudy输入样例3:
plain
onetwothree
fourfivesix输出样例3:
plain
ofnoeutrwfoitvherseiex思路:
- 先算需要多少空间
设:
len1 = strlen(s1)len2 = strlen(s2)
合并后长度一定是:
plain
len1 + len2再加上结尾的 '\0':
plain
len1 + len2 + 1所以 malloc 这样写:
plain
char *res = (char*)malloc((len1 + len2 + 1) * sizeof(char));- 用三个下标完成交替合并
i指向 s1 当前取到哪j指向 s2 当前取到哪k指向 res 当前放到哪
不断循环:
- 如果
s1还有字符,放一个 - 如果
s2还有字符,放一个
直到两个都取完。
- 最后加上字符串结束符
plain
res[k] = '\0';
c
char * mergeString(char * s1, char * s2)
{
int len1 = strlen(s1);
int len2 = strlen(s2);
// 动态分配:len1 + len2 个字符 + 1个 '\0'
char *res = (char *)malloc((len1 + len2 + 1) * sizeof(char));
int i = 0, j = 0, k = 0;
// 交替取字符
while (i < len1 || j < len2)
{
if (i < len1) res[k++] = s1[i++];
if (j < len2) res[k++] = s2[j++];
}
// 补结束符
res[k] = '\0';
return res;
}大整数的正负性和奇偶性
大整数在现代密码学与信息安全、航空航天、物理学、高精度科学计算以及探索计算理论极限乃至理解宇宙尺度等方面有重要应用。例如,大整数分解的困难性是构成加密算法的数学基础,密钥越长,安全强度越高。全同态加密中的密文位宽可达数百万位。
现给定一个大整数n,其绝对值小于等于10的1000次方,请判断其正负性与奇偶性。
结果为五种情形:负奇数、负偶数、零、正奇数、正偶数。
输入格式:
一个大整数n。请注意:正整数可能带"+"号,0前可能带正负符号。
输出格式:
结果五种情形之一。
输入样例1:
plain
-123456789012345678901234567890123456789输出样例1:
plain
负奇数输入样例2:
plain
+1输出样例2:
plain
正奇数输入样例3:
plain
-0输出样例3:
plain
零思路:
- 先判断是不是 0
- 去掉开头的
+或- - 看剩下的数字是不是全是
'0'- 如果全是 0 → 输出 "零"
- 注意:
-0、+0、0000都算零
- 判断正负
如果不是 0:
- 原字符串首字符是
'-'→ 负数 - 否则(
'+'或数字开头)→ 正数
- 判断奇偶
看 最后一位数字:
0 2 4 6 8→ 偶数- 其他 → 奇数
c
#include <stdio.h>
#include <string.h>
int main() {
char s[1105]; // 1000位数字 + 符号 + '\0',多留点
scanf("%s", s);
int i = 0;
// 处理符号
int sign = 1; // 1表示正,-1表示负
if (s[0] == '-') {
sign = -1;
i = 1;
} else if (s[0] == '+') {
i = 1;
}
// 判断是否为0(去掉符号后全是0)
int allZero = 1;
for (int j = i; s[j] != '\0'; j++) {
if (s[j] != '0') {
allZero = 0;
break;
}
}
if (allZero) {
printf("零");
return 0;
}
// 判断奇偶(看最后一位)
int len = strlen(s);
char last = s[len - 1];
int isEven = (last == '0' || last == '2' || last == '4' || last == '6' || last == '8');
// 输出结果
if (sign < 0) {
if (isEven) printf("负偶数");
else printf("负奇数");
} else {
if (isEven) printf("正偶数");
else printf("正奇数");
}
return 0;
}签到记录去重
小明正在开发一个校园活动签到系统。每次活动开始时,参与者通过扫描二维码签到,系统会实时记录每个参与者的ID号。但由于网络波动或误操作,部分参与者可能被重复提交。为了统计实际参与人数并生成准确的签到名单,小明需要对原始签到记录进行去重处理,并保留ID首次出现的顺序,以反映真实的签到先后。
请你帮助小明编写一个程序,从包含重复ID号的签到记录中提取出唯一的、按首次出现顺序排列的ID号序列。
输入格式:
第一行输入一个正整数 N(1≤N≤100),表示签到记录中包含的ID号数量。
第二行输入 N 个正整数(每个正整数不超过 100),代表签到的参与者的ID号,正整数之间用一个空格分隔。
输出格式:
输出一行,包含去重后的ID号序列,按首次出现的顺序排列,学号之间用一个空格分隔。行末不得有多余空格。
输入样例:
plain
8
3 5 2 3 7 5 2 8输出样例:
plain
3 5 2 7 8思路:
用 cnt[id] 记录是否出现过:
- 第一次出现 → 输出/存下来
- 后面再出现 → 忽略
c
#include <stdio.h>
int main() {
int n;
scanf("%d", &n);
int cnt[101] = {0}; // 记录某个ID是否出现过
int b[101]; // 存放去重后的顺序结果
int j = 0;
for (int i = 0; i < n; i++) {
int x;
scanf("%d", &x);
if (cnt[x] == 0) {
b[j++] = x; // 第一次出现,加入结果
cnt[x] = 1; // 标记已出现
}
}
for (int k = 0; k < j; k++) {
if (k) printf(" "); // 不是第一个就先输出空格
printf("%d", b[k]);
}
return 0;
}时间点与区间的关系
在我们的生活中,很多诸如考试、提交材料、演讲、答辩等等事项均有起始和截止时间的限制。
例如某考试的起始时间为2025年1月4日14时0分0秒,截止时间为2025年1月4日17时0分0秒。
对于给定某考试起始时间和截止时间以及当前时间,求当前时间对应的考试状态。
在此约定:
(1)起始时间和截止时间采用"年-月-日 时:分:秒"形式,其中年月日时分秒均为非负整数,年为4位,月日时分秒均为2位,不足位的补前导0,时为24小时制。注意:日期中的冒号为半角字符":"而不是全角字符":"。
(2)开始的状态为三种:未开始、正开放、已截止。
(3)起始时刻对应的状态为正开放,截止时刻对应的状态为已截止。
输入格式:
输入为三行,其中第一二行表示某某考试的起始或截止时间。
注意,这两个时间中,所表示时间概念在前者为起始时间,所表示时间概念在后者为截止时间。
也就是说,输入的第一行中的时间可能为截止时间。
第三行为当前时间
输出格式:
当前时间对应的考试状态
输入样例:
plain
2025-01-04 17:00:00
2025-01-04 14:00:00
2025-01-03 13:59:59输出样例:
plain
未开始思路:
给你三个时间字符串(两个是考试起止时间,顺序不一定对),再给一个当前时间,判断状态:
- 当前时间 < 起始时间 → 未开始
- 起始时间 ≤ 当前时间 < 截止时间 → 正开放
- 当前时间 ≥ 截止时间 → 已截止
并且题目强调:
起始时刻算"正开放"
截止时刻算"已截止"
因为输入格式固定是:
plain
YYYY-MM-DD HH:MM:SS而且都补齐了前导 0
这种格式按字符串字典序比较,时间先后顺序和字符串大小完全一致!
例如:
plain
2025-01-04 14:00:00 < 2025-01-04 17:00:00字符串比较结果就是对的。
所以我们只要:
- 读入 s1、s2、now 三行
- 用
strcmp判断谁早谁晚,确定 start、end。strcmp(a, b) < 0表示:a 小于 b,也就是 a 在字典序上更靠前(更"早") - 比较 now 和 start/end 输出状态
⚠️ 注意:一行里面有空格,所以必须用 fgets 读整行。
c
#include <stdio.h>
#include <string.h>
int main() {
char s1[30], s2[30], now[30];
fgets(s1, sizeof(s1), stdin);
fgets(s2, sizeof(s2), stdin);
fgets(now, sizeof(now), stdin);
// 去掉每行末尾的 '\n'
s1[strcspn(s1, "\n")] = '\0';
s2[strcspn(s2, "\n")] = '\0';
now[strcspn(now, "\n")] = '\0';
// 确定开始时间 start 和截止时间 end(因为输入顺序可能反)
char *start = s1, *end = s2;
if (strcmp(s1, s2) > 0) { // s1 比 s2 晚,交换
start = s2;
end = s1;
}
// 判断状态
if (strcmp(now, start) < 0) {
printf("未开始");
} else if (strcmp(now, end) < 0) {
printf("正开放");
} else {
printf("已截止");
}
return 0;
}智能家居安全网关:异常指令拦截
背景介绍
随着物联网的普及,家家户户都安装了智能门锁和监控摄像头。为了防止黑客通过伪造过长的恶意数据包导致系统溢出或瘫痪,你作为安全工程师,需要为智能网关编写一个"指令清洗与威胁评估"模块。
设备接收到的原始数据是一串连续的数字信号,其中合法的控制指令以字符 'X' 作为结束符。黑客往往会在合法指令后附加大量随机噪声(即 'X' 之后的字符),试图混淆视听。
任务介绍
现在你的编程任务是:
(1) 数据清洗:从杂乱的数据流中提取出 'X' 之前的有效指令串。
(2)安全校验:利用"模3校验算法"对有效指令进行计算(即求该超长数字除以 3 的余数),根据余数判断当前的安全等级。
输入格式:
输入一个包含数字和结束标志 'X' 的字符串 S。
S 的总长度不超过 1000 位。
有效指令部分('X'之前)长度保证大于 10 位,且是0-9的数字。
'X' 之后可能包含任意干扰字符,应当被忽略。
输出格式:
第一行:输出清洗后的有效指令串(即 'X' 之前的所有数字)。
第二行:输出校验结果(模 3 的余数)及对应的安全状态代码,中间用空格分隔。
安全状态定义如下:
余数为 0:状态为 Green_Safe (表示绿色安全,指令正常)
余数为 1:状态为 Yellow_Risk (表示黄色风险,需进一步扫描)
余数为 2:状态为 Red_Attack (表示红色警报,立即阻断)
输入样例1:
plain
202601111500X1800输出样例1:
plain
202601111500
1 Yellow_Risk输入样例2:
plain
333333333333333333333333330Xn8ise输出样例2:
plain
333333333333333333333333330
0 Green_Safe思路:
- 清洗 :从左到右找到第一个
'X',X之前的部分就是有效指令串(保证都是数字且长度>10)。 - 模3计算 (大整数):用"逐位取模"
设rem=0,遍历每个数字字符d:
rem = (rem*10 + (d-'0')) % 3 - 按余数输出状态:
- 0 →
Green_Safe - 1 →
Yellow_Risk - 2 →
Red_Attack
c
#include <stdio.h>
#include <string.h>
int main() {
char s[1205];
if (!fgets(s, sizeof(s), stdin)) return 0;
// 去掉行尾换行
s[strcspn(s, "\n")] = '\0';
// 找到 'X'
int pos = -1;
for (int i = 0; s[i] != '\0'; i++) {
if (s[i] == 'X') { pos = i; break; }
}
// 题目保证有 X,这里做个兜底
if (pos == -1) pos = (int)strlen(s);
// 输出清洗后的有效指令串
for (int i = 0; i < pos; i++) putchar(s[i]);
putchar('\n');
// 计算模3余数
int rem = 0;
for (int i = 0; i < pos; i++) {
int d = s[i] - '0'; // 题目保证这里都是数字
rem = (rem * 10 + d) % 3;
}
// 输出余数 + 状态
if (rem == 0) printf("0 Green_Safe\n");
else if (rem == 1) printf("1 Yellow_Risk\n");
else printf("2 Red_Attack\n");
return 0;
}身份证验证系统
"数字身份"认证是现代社会的基石。作为公安机关信息系统的实习生,你被分配到一个关键任务:设计并实现二代居民身份证号码的智能验证模块。
身份证号码由18位字符组成,其中隐含着个人的出生信息和防伪校验码。你的系统需要同时验证两个核心要素:
(1)时间真实性:第7-14位构成的8位数字必须表示一个真实存在的日期
(2)数据完整性:通过内置的校验算法确保号码未被篡改
验证规则被封装在以下算法中:
将前17位数字与固定权重序列相乘并求和,对和与11取模数得到索引值。根据索引在预设映射表中查找验证字符,将该字符与身份证最后一位比对
输入格式
输入包含多行,每行一个18位字符串,表示待验证的身份证号码。 输入以单独一行"#"结束。 每个身份证号码保证长度为18位,可能包含数字0-9和大写字母X。
输出格式
对于每个身份证号码(不包括结束行"#"),输出一行验证结果,格式为: 身份证号码 验证结果
验证结果分为4种情况:
(1)如果身份证号码完全合法,输出:"Valid"
(2)如果前17位中存在不是数字的情况,则按日期错误处理,即:"Invalid: birth date error"
(3)如果出生日期无效(无论校验码是否正确),输出:"Invalid: birth date error"
(4)如果出生日期有效但校验码错误,输出:"Invalid: checksum error"
提示:
(1)权重系数序列为:7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2
(2)校验码映射关系:余数0-10分别对应字符:'1', '0', 'X', '9', '8', '7', '6', '5', '4', '3', '2'
(3)闰年判断规则:能被4整除但不能被100整除,或者能被400整除的年份为闰年。
(4)月份天数:1月31天,2月平年28天、闰年29天,3月31天,4月30天,5月31天,6月30天,7月31天,8月31天,9月30天,10月31天,11月30天,12月31天
(5)身份证号码中的X为大写字母,在计算时代表数字10
(6)前17位必须是数字字符,否则按日期错误处理(因为非数字字符无法转换为有效日期)
输入样例:
plain
11010519491231002X
110105194902300019
110105194912310029
320102199001011234
320102199013011234
#输出样例:
plain
11010519491231002X Valid
110105194902300019 Invalid: birth date error
110105194912310029 Invalid: checksum error
320102199001011234 Invalid: checksum error
320102199013011234 Invalid: birth date error思路:
对每行 18 位字符串 id:
- 先检查前 17 位是否全是数字
- 只要有一个不是
'0'..'9':直接按日期错误
输出:Invalid: birth date error
(题目要求:前17位非数字按日期错误处理)
- 解析出生日期(第 7-14 位,索引 6...13)
- year = id6...9,month = id10...11,day = id12...13
- 判断 month 是否 1...12
- 根据闰年规则算该月最大天数,再判断 day 是否在合法范围
- 若不合法:输出
Invalid: birth date error(不管校验码对不对)
- 出生日期合法后,再验校验码
权重序列(17个):
[7,9,10,5,8,4,2,1,6,3,7,9,10,5,8,4,2]
映射表(mod 11 的余数 0...10 对应):
"10X98765432"? 注意顺序要对:
题目给的是:
0-10 → '1','0','X','9','8','7','6','5','4','3','2'
所以用字符串:"10X98765432"不对 (那是 0:'1' 1:'0' 2:'X' ...)
正确字符串是:"10X98765432"其实正好对应:
index0='1',1='0',2='X',3='9',4='8',5='7',6='6',7='5',8='4',9='3',10='2' ✅
所以 map = "10X98765432" 是对的。
计算:
plain
sum = Σ (id[i]-'0') * w[i]
r = sum % 11
expect = map[r]若 expect == id[17] → Valid,否则 → Invalid: checksum error
c
#include <stdio.h>
#include <string.h>
#include <ctype.h>
static int is_leap(int y) {
return (y % 4 == 0 && y % 100 != 0) || (y % 400 == 0);
}
static int valid_date(int y, int m, int d) {
if (m < 1 || m > 12) return 0;
int mdays[] = {0,31,28,31,30,31,30,31,31,30,31,30,31};
int maxd = mdays[m];
if (m == 2 && is_leap(y)) maxd = 29;
return d >= 1 && d <= maxd;
}
int main() {
char id[200];
const int w[17] = {7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2};
const char map[12] = "10X98765432"; // 余数0..10 -> 校验码
while (fgets(id, sizeof(id), stdin)) {
id[strcspn(id, "\n")] = '\0';
if (strcmp(id, "#") == 0) break;
// 1) 前17位必须全是数字,否则按日期错误处理
int ok17 = 1;
for (int i = 0; i < 17; i++) {
if (!isdigit((unsigned char)id[i])) {
ok17 = 0;
break;
}
}
if (!ok17) {
printf("%s Invalid: birth date error\n", id);
continue;
}
// 2) 解析出生日期 YYYYMMDD (第7-14位 -> 下标6..13)
int y = (id[6]-'0')*1000 + (id[7]-'0')*100 + (id[8]-'0')*10 + (id[9]-'0');
int m = (id[10]-'0')*10 + (id[11]-'0');
int d = (id[12]-'0')*10 + (id[13]-'0');
if (!valid_date(y, m, d)) {
printf("%s Invalid: birth date error\n", id);
continue;
}
// 3) 校验码
long long sum = 0;
for (int i = 0; i < 17; i++) {
sum += (id[i] - '0') * w[i];
}
int r = (int)(sum % 11);
char expect = map[r];
if (id[17] == expect) {
printf("%s Valid\n", id);
} else {
printf("%s Invalid: checksum error\n", id);
}
}
return 0;
}测试题1
倒背如流
某牛人有倒背如流的超能力,也就是给定一行很长的英文,他能逐字符地倒背出来。
但这么牛的超能力对于会编程的你来说,应该时小菜一碟!
他没有告诉你的是,其实是背后的reverseStr函数的功劳!
函数接口定义:
c
//将字符指针s所指字符串中的字符倒序
void reverseStr(char * s);裁判测试程序样例:
c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
//将字符指针s所指字符串中的字符倒序
void reverseStr(char * s);
int main() {
char s[100+1];
gets(s);
reverseStr(s);
printf("result=%s\n",s);
return 0;
}
/* 请在这里填写答案 */输入格式:
一行长度不超过100的英文字符。
输出格式:
result=倒背的英文文本****
输入样例:
plain
Good good study, day day up! Nothing is difficult, if you try your best to do it.输出样例:
plain
result=.ti od ot tseb ruoy yrt uoy fi ,tluciffid si gnihtoN !pu yad yad ,yduts doog dooG解题思路: 逐字符倒序
解析main函数:
gets(s); 用 gets 读入一整行字符串(包括空格)
reverseStr(s); 把字符串首地址 s 传给 reverseStr
用两个指针:一个从左往右,一个从右往左,两两交换
为什么函数不用 return?
因为:reverseStr(s);
s 是数组名 → 本质是指针
函数里通过指针 直接修改原数组内容
所以:函数结束后,main 里的 s 已经被改好了
c
void reverseStr(char *s)
{
char *p = s;
char *q = s;
//*q 表示 q 指向的字符,只要不是 '\0',就继续往后走
while (*q) q++;
q--; // q 退回到最后一个"有效字符"
while (p < q) {
char t = *p;
*p = *q;
*q = t;
p++;
q--;
}
}1
中药别名
中医药,是中华民族的文化瑰宝。在千百年的发展中,受传承者文化水平、地方语言等多方面的影响,部分中药的名称发生了变化。出现了两个现象:
1、一种药物多个名称;
2、一个名称不同药物。
这种现象,容易给中药临床调配方剂造成错误,影响方剂本来的疗效,严重的还会造成医疗事故。
现在需要定义一个获取中药别名的函数。
函数接口定义:
c
char* getEpithet ( struct HerbMedicine *pHerb, int i );其中 <font style="color:rgb(231, 76, 60);">pHerb</font> 和 <font style="color:rgb(231, 76, 60);">i</font> 都是用户传入的参数。 <font style="color:rgb(231, 76, 60);">pHerb</font> 是指向一个中药结构体变量的指针。函数须返回 <font style="color:rgb(231, 76, 60);">pHerb</font> 指向的中药第i个别名,如果没有i个别名则输出"没有那么多别名!"。
裁判测试程序样例:
c
#include <stdio.h>
#define HERB_NAME_LEN 1000
#define HERB_EPITHET_NUM 10
char errorMsg[] = "没有那么多别名!";
struct HerbMedicine {
int herbNo;//中药编号
char name[HERB_NAME_LEN+1];//中药正名
char epithet[HERB_EPITHET_NUM][HERB_NAME_LEN+1];//每个中药保存最多HERB_EPITHET_NUM个别名
int epithetNum; // 别名个数
};
char* getEpithet(struct HerbMedicine *pHerb, int i);
int main()
{
struct HerbMedicine herb = {10000, "麦冬", {"麦门冬","杭寸冬","杭麦冬","寸冬","大麦冬"}, 5};
int i;
scanf("%d", &i);
printf("%s\n", getEpithet(&herb, i));
return 0;
}
/* 请在这里填写答案 */输入样例:
plain
1输出样例:
plain
麦门冬
c
char* getEpithet(struct HerbMedicine *pHerb, int i)
{
if (i <= 0 || i > pHerb->epithetNum) {
return errorMsg; // 别名序号不合法
}
return pHerb->epithet[i - 1]; // 第 i 个别名(i 从 1 开始)
}稀疏矩阵
稀疏矩阵可以用三元组的方式存储。
例如,以下矩阵A有6个非零元素。
!\[\](https://i-blog.csdnimg.cn/img_convert/27c21d08d35ff86860e5280b90c63185.png)
矩阵A可以用三个一维数组来存放:
data = 1, 2, 3, 5, 6, 4 : 按行罗列所有的非零元;
row = 0, 0, 1, 3, 3, 4: 所有非零元的行索引j ;
col = 0, 2, 2, 1, 2, 3: 所有非零元的列索引j
函数接口定义:
c
void restoreSparseMatrix(int matrix[ROW][COL], int* data, int* row, int* col, int n);函数功能是根据存放稀疏矩阵的非零元素的三个一维数组还原矩阵,还原的矩阵存放在matrix中。其中 <font style="color:rgb(231, 76, 60);">matrix, data, row, col</font> 和 <font style="color:rgb(231, 76, 60);">n</font> 都是用户传入的参数, <font style="color:rgb(231, 76, 60);">matrix</font> 是ROW行COL列的二维数组的首地址; <font style="color:rgb(231, 76, 60);">data, row</font> 和 <font style="color:rgb(231, 76, 60);">col</font> 是存放稀疏矩阵的n个非零元素的三个一维数组。
题目保证输入数据都能有效还原为矩阵。
裁判测试程序样例:
c
#include <stdio.h>
#define ROW 5
#define COL 4
void restoreSparseMatrix(int matrix[ROW][COL], int* data, int* row, int* col, int n);
int main(){
int matrix[ROW][COL];
int N;//非零元素个数
scanf("%d", &N);
int data[N], row[N], col[N];
for(int i = 0; i < N; i++){
scanf("%d", &data[i]);
}
for(int i = 0; i < N; i++){
scanf("%d", &row[i]);
}
for(int i = 0; i < N; i++){
scanf("%d", &col[i]);
}
restoreSparseMatrix(matrix, data, row, col, N);
for (int row = 0; row < ROW; row++) {
for (int col = 0; col < COL; col++) {
printf("%d ", matrix[row][col]);
}
printf("\n");
}
return 0;
}
/* 请在这里填写答案 */输入样例:
plain
6
1 2 3 5 6 4
0 0 1 3 3 4
0 2 2 1 2 3输出样例:
plain
1 0 2 0
0 0 3 0
0 0 0 0
0 5 6 0
0 0 0 4思路:
已知一个 ROW × COL 的矩阵 ,但只给你它的 n 个非零元素 ,
非零元素用三条一维数组保存:
data[k]:值row[k]:所在行col[k]:所在列
要你把原矩阵 完整还原 到 matrix 中。
1️⃣ 整个矩阵先清零
2️⃣ 遍历非零元素
3️⃣ 按 row / col 放回去
4️⃣ 完成
c
void restoreSparseMatrix(int matrix[ROW][COL], int* data, int* row, int* col, int n)
{
// 先全部置 0
for (int i = 0; i < ROW; i++) {
for (int j = 0; j < COL; j++) {
matrix[i][j] = 0;
}
}
// 再把非零元素放回对应位置
for (int k = 0; k < n; k++) {
matrix[row[k]][col[k]] = data[k];
}
}巡考
今年C程序设计课程联考有5个学校参加。这5个学校是湖南农业大学,吉首大学,怀化学院,湘南学院和湖南理工学院,编号分别为1到5。Dingding老师作为联考工作总协调老师需要进行巡考。各学校的监考老师如果遇到问题就会给Dingding老师发来一个代表该学校的数字,然后Dingding老师就要到该学校的考场了解情况。
输入格式:
输入1个考场编号N。
输出格式:
如果编号N正确,输出编号N对应的学校名称,否则输出"错误呼叫"。
输入样例:
plain
1输出样例:
plain
湖南农业大学
c
#include <stdio.h>
int main() {
int N;
scanf("%d", &N);
switch (N) {
case 1:
printf("湖南农业大学");
break;
case 2:
printf("吉首大学");
break;
case 3:
printf("怀化学院");
break;
case 4:
printf("湘南学院");
break;
case 5:
printf("湖南理工学院");
break;
default:
printf("错误呼叫");
break;
}
return 0;
}缅怀革命先烈
为策应中央红军突围转移,红军第2、第6军团于1934年10月底发起湘西攻势,创建根据地。红军第2、第6军团在湘鄂川黔战斗十个月,先后攻克永顺、大庸、桑植、桃源、慈利、澧州、津市、石门、临澧等县市,创建了湘鄂川黔革命根据地,钳制一部分追击中央红军的国民党军队,有力地配合了中央红军的战略转移。
吉首大学的Dingding同学想前往3个革命故地缅怀革命先烈,每次去往一个地方,需要计算总行程(公里)。
输入格式:
输入数据有3行,每行包含一个地名(不超过5个汉字)和一个正整数,分别为前往的革命故地的往返行程(公里)。
输出格式:
输出前往3个革命故地的总行程(公里)。
输入样例:
plain
永顺 121
大庸 179
桑植 203输出样例:
plain
前往革命故地永顺、大庸、桑植的总行程503公里
c
#include <stdio.h>
int main() {
char name1[20], name2[20], name3[20]; // 足够存储5个汉字
int dist1, dist2, dist3;
scanf("%s %d", name1, &dist1);
scanf("%s %d", name2, &dist2);
scanf("%s %d", name3, &dist3);
int total = dist1 + dist2 + dist3;
printf("前往革命故地%s、%s、%s的总行程%d公里\n",
name1, name2, name3, total);
return 0;
}成绩等级互转
将五级制的成绩等级有两种:简称A,B,C,D,E以及全称Excellent,Good,Medium,Pass,Fail。请编程实现对输入的等级成绩简称与全称的相互转换。以上名称均区分大小写,除了这10种等级名外的其它成绩均输出Error。
输入格式:
一个长度不超过9个字符的成绩等级的简称或全称。
输出格式:
对应的全称或简称。
输入样例1:
plain
A输出样例1:
plain
Excellent输入样例2:
plain
Good输出样例2:
plain
B输入样例3:
plain
good输出样例3:
plain
Error
c
#include <stdio.h>
#include <string.h>
int main() {
char s[20];
scanf("%s", s);
if (strcmp(s, "A") == 0) printf("Excellent");
else if (strcmp(s, "B") == 0) printf("Good");
else if (strcmp(s, "C") == 0) printf("Medium");
else if (strcmp(s, "D") == 0) printf("Pass");
else if (strcmp(s, "E") == 0) printf("Fail");
else if (strcmp(s, "Excellent") == 0) printf("A");
else if (strcmp(s, "Good") == 0) printf("B");
else if (strcmp(s, "Medium") == 0) printf("C");
else if (strcmp(s, "Pass") == 0) printf("D");
else if (strcmp(s, "Fail") == 0) printf("E");
else printf("Error");
return 0;
}共识有几条
如今小明和小红两个人作为新时代新青年,对于中国精神也在不断地学习中。他们将自己已经掌握的内容以序号的形式展现,想知道双方同时掌握的精神基因有几种。
输入格式:
第一行包含两个整数 𝑛, 𝑚 (1 ≤ 𝑛 ≤ 50, 1 ≤ 𝑚 ≤ 50) - 小明和小红分别所掌握的精神基因数量。
第二行包含 𝑛 个整数𝑎1,𝑎2,...,𝑎𝑛(1 ≤ 𝑎𝑖 ≤ 100) - 小明所掌握的精神基因序列(保证两两不相同)。
第三行包含 𝑚 个整数𝑏1,𝑏2,...,𝑏𝑚(1 ≤ 𝑏𝑖 ≤ 100) - 小红所掌握的精神基因序列(保证两两不相同)。
输出格式:
输出包括一行一个数字,表示为两人同时掌握的精神基因的个数。
输入样例1:
plain
4 3
1 3 4 2
8 1 2输出样例1:
plain
2输入样例2:
plain
1 1
1
2输出样例2:
plain
0
c
#include <stdio.h>
int main() {
int n, m;
scanf("%d %d", &n, &m);
int seen[101] = {0}; // 序号范围 1~100
for (int i = 0; i < n; i++) {
int x;
scanf("%d", &x);
seen[x] = 1; // 标记小明掌握的精神基因
}
int count = 0;
for (int i = 0; i < m; i++) {
int x;
scanf("%d", &x);
if (seen[x]) count++; // 小红掌握的也在小明中
}
printf("%d", count);
return 0;
}社会主义法律
我们知道一部宪法的颁布需要全国人民代表大会上三分之二以上的人表决同意(三分之二以上,不包括三分之二)。如今有一部法律需要通过大会上 𝑛 个人表决,我们将 𝑛 个人所投的票看成一个字符串,其中"1"表示同意,"0"表示不同意,不存在弃权。
现在请你统计并整理,告诉大家这部法案能否通过。
输入格式:
第一行包含一个整数 𝑛 (1 ≤ 𝑛 ≤ 100) - 大会上的人数。
第二行包含了一个长度为 𝑛 的字符串 𝑠 ('0' ≤ 𝑠𝑖 ≤ '1') ------ 投票情况。
输出格式:
输出仅包含一个字符串,若法案能通过,则输出"YES",否则输出"NO"。(注意:输出字符串均为大写,不需要输出引号)
输入样例1:
plain
6
111100输出样例1:
plain
NO输入样例2:
plain
6
111011输出样例2:
plain
YEScnt大于n的三分之二成立,在代码里写成:cnt * 3 > 2 * n
c
#include <stdio.h>
int main() {
int n;
char s[105];
scanf("%d", &n);
scanf("%s", s);
int cnt = 0;
for (int i = 0; i < n; i++) {
if (s[i] == '1') cnt++;
}
// "三分之二以上,不包括三分之二" -> cnt > 2n/3
if (cnt * 3 > 2 * n) printf("YES");
else printf("NO");
return 0;
}规范命名
小明在文件命名的时候经常不注意大小写,格式比较混乱。
现要求你写一个程序将目录下的文件统一规范的格式,即文件名的第一个字符如果是字母要大写,其他字母小写。
如Test、test则需整理成Test;2-test是规范的
输入格式:
第一行一个数字n,表示有n个文件名要统一,n不超过100。
接下来n行,每行一个单词,长度不超过20,表示文件的名字。文件名由字母、数字和-组成。
输出格式:
n行,每行一个单词,对应统一后的文件名。
输入样例:
plain
4
Test
data
2-TEST
problem-6输出样例:
plain
Test
Data
2-test
Problem-6
c
#include <stdio.h>
int main() {
int n;
scanf("%d", &n);
char s[25];
for (int i = 0; i < n; i++) {
scanf("%s", s);
// 处理第 1 个字符
if (s[0] >= 'a' && s[0] <= 'z') {
s[0] = s[0] - 'a' + 'A';
} else if (s[0] >= 'A' && s[0] <= 'Z') {
// 已经是大写,保持不变
}
// 处理后面的字符:字母都转小写
for (int j = 1; s[j] != '\0'; j++) {
if (s[j] >= 'A' && s[j] <= 'Z') {
s[j] = s[j] - 'A' + 'a';
}
}
printf("%s\n", s);
}
return 0;
}更好的答案:
c
#include <stdio.h>
#include <ctype.h>
int main(){
int n;
scanf("%d",&n);
char s[101];
for(int i=0;i<n;i++){
scanf("%s",s);
if(isalpha(s[0])) s[0]=toupper(s[0]);
for(int j=1;s[j];j++){
if(isalpha(s[j])) s[j]=tolower(s[j]);
}
printf("%s",s);
}
}劳动教育活动
Dingding老师负责安排劳动教育活动的场地。请编写程序帮Dingding老师计算需要安排多少个场地?
输入格式:
第一行是一个正整数N,表示参加劳动教育活动的班级个数。
第二行有N个正整数,分别是这些班级的学生人数。
第三行是一个正整数C,表示每个劳动教育活动场地能接纳的学生人数。
输出格式:
输出一个正整数,表示需要的劳动教育活动场地的数量。
输入样例:
plain
2
32 25
30输出样例:
plain
2正确的向上取整公式(必须记住):ans = (sum + C - 1) / C;
c
#include <stdio.h>
int main() {
int N, C;
scanf("%d", &N);
int sum = 0, x;
for (int i = 0; i < N; i++) {
scanf("%d", &x);
sum += x;
}
scanf("%d", &C);
int ans = (sum + C - 1) / C; // 向上取整
printf("%d", ans);
return 0;
}泊车收费
2023年9月,长沙市为规范管理、疏导交通、便民利民,进一步优化机动车路边泊位停放服务收费标准。
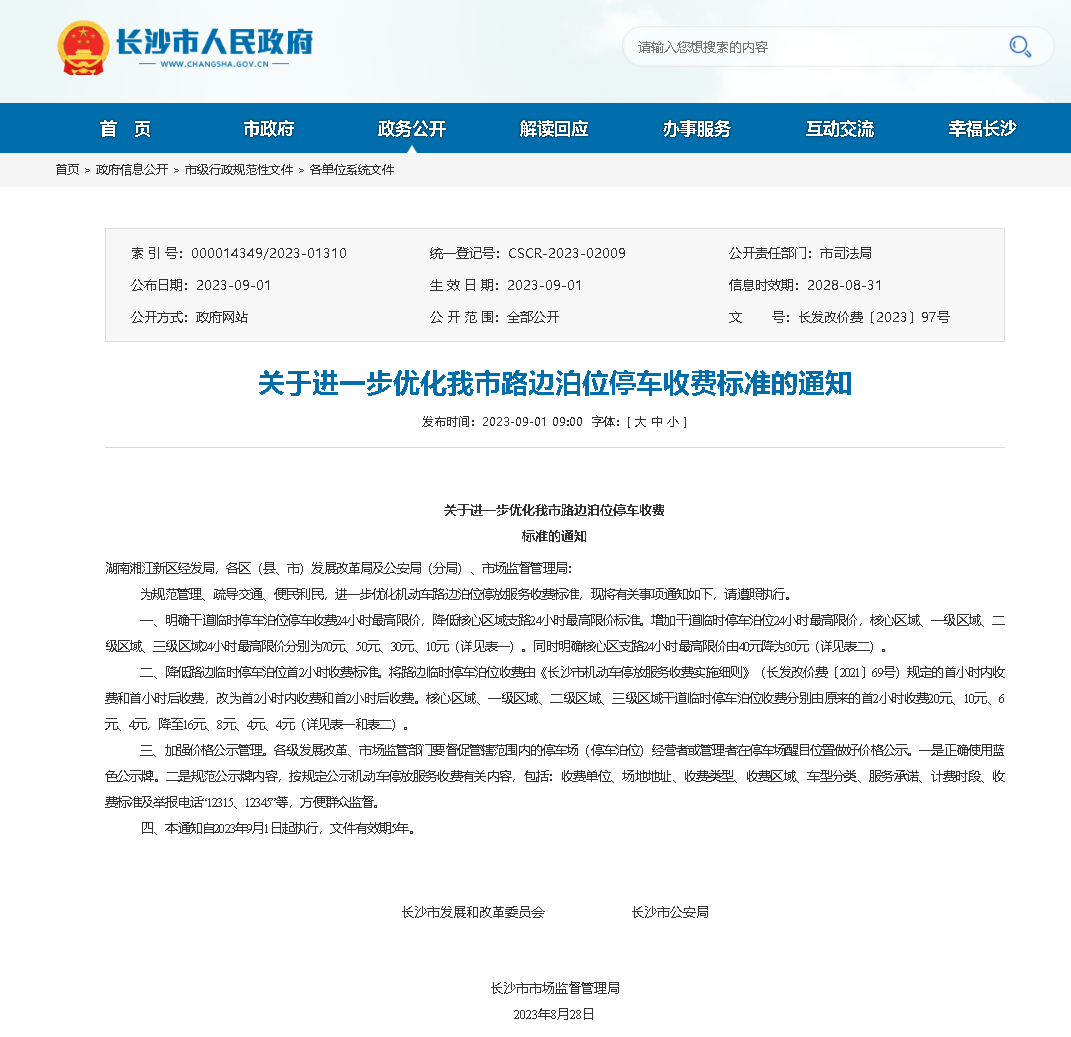
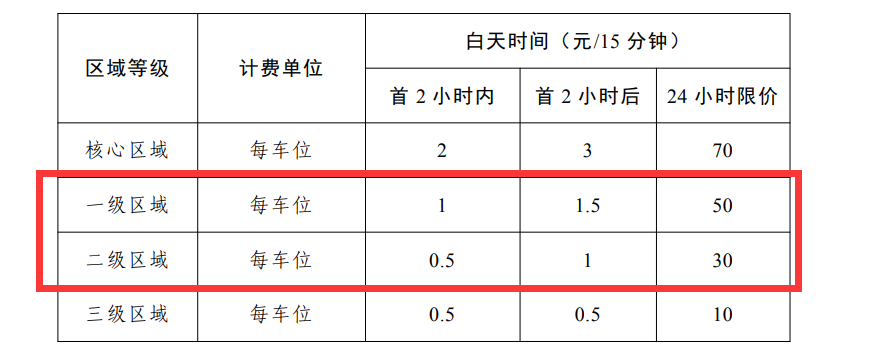
Dingding老师根据自己的情况做了如下记录:
- 如果停在1级区域,停车时间在30分钟以内的免费;从30分钟后开始计算收费计时N,120分钟以内的部分按每15分钟1元的标准计费,超过120分钟的部分按每15分钟1.5元的标准计费,不足15分钟的部分按比例收费,保留小数点后1位;每次收费上限是50元。
- 如果停在2级区域,停车时间在30分钟以内的免费;从30分钟后开始计算收费计时N,120分钟以内的部分按每15分钟0.5元的标准计费,超过120分钟的部分按每15分钟1元的标准计费,不足15分钟的部分按比例收费,保留小数点后1位;每次收费上限是30元。
请编写程序帮Dingding老师计算停车费。
输入格式:
输入一行数据,第1个数据为1或2,分别表示1级区域或者2级区域;第2个数据保证是整数N(1≤N≤720),表示停车总时长(单位:分钟)。
输出格式:
输出Dingding老师需要缴纳的费用(单元:元),需保留小数点后1位。
输入样例1:
plain
1 31输出样例1:
plain
0.1输入样例2:
plain
2 358输出样例2:
plain
17.9输入样例3:
plain
1 121输出样例3:
plain
6.1解题思路:
输入:
area:区域(1 或 2),决定费率和封顶N:停车总时长(分钟)
免费:
- 前 30 分钟免费
→ 只有当N > 30才进入计费
计费时间:
t = N - 30(分钟)
分段:
- 第一段:
t中最多前 120 分钟 (也就是免费后 30~150 分钟这段),费率rate1(按 15 分钟计费) - 第二段:
t中超过 120 分钟 的部分,费率rate2(按 15 分钟计费)
封顶:
- 最终费用
fee不能超过cap
每段费用都长这样:
- 第一段费用:
(t1 / 15.0) * rate1 - 第二段费用:
(t2 / 15.0) * rate2
总费用:
fee = (t1/15.0)*rate1 + (t2/15.0)*rate2fee = min(fee, cap)
c
#include <stdio.h>
int main() {
int area, N;
scanf("%d %d", &area, &N);
double rate1, rate2, cap;
if (area == 1) {
rate1 = 1.0;
rate2 = 1.5;
cap = 50.0;
} else {
rate1 = 0.5;
rate2 = 1.0;
cap = 30.0;
}
double fee = 0.0;
if (N > 30) {
int t = N - 30;
int t1 = 0, t2 = 0;
if (t <= 120) {
t1 = t;
} else {
t1 = 120;
t2 = t - 120;
}
fee = (t1 / 15.0) * rate1
+ (t2 / 15.0) * rate2;
if (fee > cap) fee = cap;
}
printf("%.1f", fee);
return 0;
}图像拼接并旋转
给定以像素矩阵表示的两幅图像,求对两幅图像进行横向或列向拼接后再旋转的新图像。
在此假定,不管是拼接还是旋转后图像的行数与列数均不超过100。像素值为0~255的整数。
输入格式:
第一行为图像A的行数r1、列数c1,其后的r1行,每行有c1个由空格分隔的整数,表示图像A对应行列的像素值。
接下来的一行为图像B的行数r2、列数c2,其后的r2行,每行有c2个由空格分隔的整数,表示图像B对应行列的像素值。
最后一行为两个空格分隔为三部分。
第一部分有如下四种取值:A/B,B/A,A-B,B-A,分别表示图像A拼接在图像B上方、图像B拼接在图像A上方、图像A拼接在图像B的左侧、图像A拼接在图像B的左侧。输入数据已经确保了图像A,B在竖向拼接时的两者列数相等,水平拼接时两者行数相等。
第二部分有如下两种取值:R,L,分别表示对拼接后的图像右旋、左旋。
第三部分为一个正整数,表示旋转的度数,该整数是90的整数倍。
输出格式:
首先输出拼接得到的图像。每两个数据之间仅有一个空格分隔,不能有多余的空格。
然后输出一个空行。
最后输出拼接并旋转后的图像。
输入样例:
plain
3 4
1 2 3 4
5 6 7 8
9 0 1 2
2 4
1 3 5 7
2 4 6 8
A/B R 450输出样例:
plain
1 2 3 4
5 6 7 8
9 0 1 2
1 3 5 7
2 4 6 8
2 1 9 5 1
4 3 0 6 2
6 5 1 7 3
8 7 2 8 4
c
#include <stdio.h>
#include <string.h>
#define MAX 105
int A[MAX][MAX], B[MAX][MAX], C[MAX][MAX], T[MAX][MAX];
void printMat(int M[MAX][MAX], int r, int c) {
for (int i = 0; i < r; i++) {
for (int j = 0; j < c; j++) {
if (j) putchar(' ');
printf("%d", M[i][j]);
}
putchar('\n');
}
}
// 将 M(r,c) 右旋 90 度,结果写到 out(c,r)
void rotateRight90(int M[MAX][MAX], int r, int c, int out[MAX][MAX]) {
for (int i = 0; i < r; i++)
for (int j = 0; j < c; j++)
out[j][r - 1 - i] = M[i][j];
}
// 把 src 复制到 dst
void copyMat(int dst[MAX][MAX], int src[MAX][MAX], int r, int c) {
for (int i = 0; i < r; i++)
for (int j = 0; j < c; j++)
dst[i][j] = src[i][j];
}
int main() {
int r1, c1, r2, c2;
scanf("%d%d", &r1, &c1);
for (int i = 0; i < r1; i++)
for (int j = 0; j < c1; j++)
scanf("%d", &A[i][j]);
scanf("%d%d", &r2, &c2);
for (int i = 0; i < r2; i++)
for (int j = 0; j < c2; j++)
scanf("%d", &B[i][j]);
char op[8], dir[2];
int deg;
scanf("%s %s %d", op, dir, °);
// 1) 拼接得到 C
int rC = 0, cC = 0;
if (strcmp(op, "A/B") == 0) { // A在上,B在下
rC = r1 + r2; cC = c1;
for (int i = 0; i < r1; i++)
for (int j = 0; j < c1; j++)
C[i][j] = A[i][j];
for (int i = 0; i < r2; i++)
for (int j = 0; j < c2; j++)
C[r1 + i][j] = B[i][j];
} else if (strcmp(op, "B/A") == 0) { // B在上,A在下
rC = r1 + r2; cC = c1;
for (int i = 0; i < r2; i++)
for (int j = 0; j < c2; j++)
C[i][j] = B[i][j];
for (int i = 0; i < r1; i++)
for (int j = 0; j < c1; j++)
C[r2 + i][j] = A[i][j];
} else if (strcmp(op, "A-B") == 0) { // A在左,B在右
rC = r1; cC = c1 + c2;
for (int i = 0; i < r1; i++) {
for (int j = 0; j < c1; j++) C[i][j] = A[i][j];
for (int j = 0; j < c2; j++) C[i][c1 + j] = B[i][j];
}
} else { // "B-A" : B在左,A在右
rC = r1; cC = c1 + c2;
for (int i = 0; i < r2; i++) {
for (int j = 0; j < c2; j++) C[i][j] = B[i][j];
for (int j = 0; j < c1; j++) C[i][c2 + j] = A[i][j];
}
}
// 输出拼接图像
printMat(C, rC, cC);
putchar('\n');
// 2) 旋转
int k = (deg / 90) % 4; // 需要旋转的90度次数
if (k < 0) k += 4;
// 左旋 k 次 等价于 右旋 (4-k) 次
if (dir[0] == 'L') k = (4 - k) % 4;
int curR = rC, curC = cC;
int cur[MAX][MAX];
copyMat(cur, C, curR, curC);
for (int t = 0; t < k; t++) {
rotateRight90(cur, curR, curC, T);
// 旋转后尺寸交换
int newR = curC, newC = curR;
copyMat(cur, T, newR, newC);
curR = newR; curC = newC;
}
// 输出旋转后的图像
printMat(cur, curR, curC);
return 0;
}测试题2
数组区段的最大最小值
本题要求实现一个函数,找出数组中一部分数据的最大值和最小值。
题目保证没有无效数据。
函数接口定义:
c
void sublistMaxMin ( int* from, int* to, int* max, int* min );其中 from和to都是用户传入的参数,分别存放数组部分数据的起始地址和结束地址,并且from<=to。
其中max和min为用户传入的地址,分别用于在sublistMaxMin中保存from至to对应区段中数组元素的最大值和最小值的地址。
裁判测试程序样例:
c
#include <stdio.h>
void sublistMaxMin ( int* from, int* to, int* max, int* min );
int main()
{
int list[1000];
int len=0;
int from, to, max, min;
scanf("%d", &len);
int i;
for(i=0; i<len; i++){
scanf("%d", &list[i]);
}
scanf("%d%d", &from, &to);
sublistMaxMin(list+from, list+to, &max, &min);
printf("list[%d-%d]: max = %d, min = %d\n", from, to, max, min);
return 0;
}
/* 请在这里填写答案 */输入样例:
plain
5
1 2 3 4 5
0 4输出样例:
plain
list[0-4]: max = 5, min = 1
c
void sublistMaxMin(int* from, int* to, int* max, int* min) {
// from 指向子数组的第一个元素
// to 指向子数组的最后一个元素
int *p = from; // p指向第一个元素
// 初始化max和min为第一个元素的值
// 把 from 指向的值写进 max 指向的变量里
*max = *from; // 这里需要解引用,获取值
*min = *from; // 这里需要解引用,获取值
for(; p <= to; p++) {
if(*p > *max) *max = *p;
if(*p < *min) *min = *p;
}
}计算总分
请编写一个函数sum,函数的功能是:计算一个由结构体表示的包含多门课程成绩组成的学生的总成绩。
函数接口定义:
c
double sum(struct student stu);其中 stu是用户传入的参数。函数须返回学生的总成绩。
裁判测试程序样例:
c
#include <stdio.h>
struct student{
int sid;
char name[20];
double math; //此数据成员表示数学程成绩
double english; //此数据成员表示英语课程成绩
double program; //此数据成员表示编程课程成绩
};
double sum(struct student st);
int main(){
struct student st;
scanf("%d%s%lf%lf%lf",&st.sid, st.name, &st.math, &st.english, &st.program);
printf("%.2f\n",sum(st));
return 0;
}
/* 请在这里填写答案 */输入样例:
plain
1000 xiaopeng 90 90 90输出样例:
plain
270.00
c
double sum(struct student st)
{
return st.math + st.english + st.program;
}移形换位
个人信息类型Person的定义如下:
c
typedef struct person {
char name[20];//姓名
int age;//年龄
} Person;请编写函数,交换两个人的基本信息。
函数接口定义:
c
void personSwap(Person *x, Person *y);说明:参数 x 和 y 为指向两个Person类型变量的指针。函数交换两个指针所指结构体变量的值。
裁判测试程序样例:
c
#include <stdio.h>
#include <string.h>
typedef struct person {
char name[20];//姓名
int age;//年龄
} Person;
void personSwap(Person *x, Person *y);
int main(){
Person a, b;
scanf("%s %d", a.name, &a.age);
scanf("%s %d", b.name, &b.age);
personSwap(&a, &b);
printf("%s %d\n",a.name, a.age);
printf("%s %d\n",b.name, b.age);
return 0;
}
/* 请在这里填写答案 */输入样例:
plain
李浩 18
王彤 20输出样例:
plain
王彤 20
李浩 18
c
void personSwap(Person *x, Person *y)
{
Person t = *x;
*x = *y;
*y = t;
}程序设计联考2
自从湖南农业大学、吉首大学和怀化学院组织程序设计课程联考以后,举办联考的经验越来丰富。尤其是湘南学院加入到联考以后,受益学生越来越多,得到了高教教师的广泛赞许。为了掌握具体的受益学生数,需要对历年联考参与的学生数目进行统计。
请编写程序根据历届参加联考的学生数据表统计出联考受益学生总数。
输入格式:
第一行为正整数n(0<n<=100),接下来有n行数据,每行数据的格式为:联考年份 学校名称 参考人数。学校名称的长度不超过20个汉字,参考人数为不超过2000的正整数。
输出格式:
在一行中输出联考受益学生总数。
输入样例:
plain
4
2021 湖南农业大学 437
2021 吉首大学 418
2021 怀化学院 629
2021 湘南学院 126输出样例:
plain
1610
c
#include <stdio.h>
int main() {
int n;
scanf("%d", &n);
int year, num;
char school[100];
long long sum = 0;
for (int i = 0; i < n; i++) {
scanf("%d %s %d", &year, school, &num);
sum += num;
}
printf("%lld\n", sum);
return 0;
}图像焦点
本题目要求输入一个存放灰度图像的二维数组并计算该图像的焦点像素的位置。题目定义一个像素周围3X3范围内的9个像素的平均灰度值为该像素的亮度系数,亮度系数最大的像素为焦点像素。题目设定图像之外的灰度值都是0。如果图像为空,默认焦点为(0,0).
输入格式:
第一行是灰度图像的高度h(h<=500)和宽度w(w<=600);
接下来是存放灰度图像的二维数组,灰度值取值范围0, 255。
输出格式:
输出第一个焦点像素所在位置,即空格分隔的行号与列号。所谓"第一个"按从上到下从左到右的顺序而定。
输入样例:
plain
10 8
1 1 1 1 1 1 1 4
1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1
1 1 5 1 1 1 1 1
1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 3
1 1 1 1 1 1 1 1
1 1 1 3 1 1 1 1
1 1 1 3 1 1 1 1
1 1 1 2 1 1 1 1输出样例:
plain
8 2
c
#include <stdio.h>
#define HMAX 500
#define WMAX 600
static int a[HMAX + 2][WMAX + 2]; // 四周补0
static long long ps[HMAX + 3][WMAX + 3]; // 前缀和(多一行一列方便)
int main() {
int h, w;
if (scanf("%d %d", &h, &w) != 2) return 0;
if (h <= 0 || w <= 0) {
printf("0 0\n");
return 0;
}
// 读入到补0后的数组 a[i+1][j+1]
for (int i = 0; i < h; i++) {
for (int j = 0; j < w; j++) {
scanf("%d", &a[i + 1][j + 1]);
}
}
// 计算前缀和 ps,范围 [0..h+1][0..w+1]
for (int i = 1; i <= h + 2; i++) {
for (int j = 1; j <= w + 2; j++) {
ps[i][j] = ps[i - 1][j] + ps[i][j - 1] - ps[i - 1][j - 1] + a[i - 1][j - 1];
}
}
long long bestSum = -1;
int bestR = 0, bestC = 0;
// 对原图每个像素(i,j) 计算其3x3邻域和(在补0图中左上角是(i, j),右下角是(i+2, j+2))
for (int i = 0; i < h; i++) {
for (int j = 0; j < w; j++) {
int r1 = i, c1 = j; // 补0图坐标
int r2 = i + 2, c2 = j + 2;
// 用前缀和求矩形和:注意 ps 下标比 a 多1
long long sum3x3 = ps[r2 + 2][c2 + 2] - ps[r1 + 1][c2 + 2] - ps[r2 + 2][c1 + 1] + ps[r1 + 1][c1 + 1];
if (sum3x3 > bestSum) {
bestSum = sum3x3;
bestR = i;
bestC = j;
}
}
}
// 输出"第一个"焦点像素的位置(按扫描顺序已保证)
printf("%d %d\n", bestR, bestC);
return 0;
}旅游景点状态
凤凰风景区某核心景点,出于文物保护的考虑,当参观人数达到一定程度的时候(假定3000人次),需要设置为"预警"状态,提示相关部门采取措施。请编写程序,根据实时输入的当日人数,输出该景点的状态。当人数不足3000时,输出"正常"状态,否则,输出"预警"状态。
输入格式:
当日人数n(0<=n<=100000)
输出格式:
在一行中输出景点的状态。
输入样例:
plain
100输出样例:
plain
正常
c
#include <stdio.h>
int main() {
int n;
scanf("%d", &n);
if (n < 3000) printf("正常\n");
else printf("预警\n");
return 0;
}湘西州红色景区推荐
湘西州有许多非常有特色的红色景区,请编写程序,针对不同年龄段的人群特点,根据距离出发点(假设从州府吉首市出发)的远近和交通方便程度等因素,自动推荐最合适的红色景区。年龄过大或过小(小于10岁,大于等于80岁),输出"不推荐";大于等于10岁,小于20岁,输出"十八洞";大于等于20岁,小于40岁,输出"龙山茨岩塘";大于等于40岁,小于60岁,输出"永顺塔卧";大于等于60岁,小于80岁,推荐"湘西州博物馆"。
输入格式:
一个表示游客年龄的正整数age(0<=age<=200).
输出格式:
推荐结果
输入样例:
plain
100输出样例:
plain
不推荐
c
#include <stdio.h>
int main() {
int age;
scanf("%d", &age);
if (age < 10 || age >= 80) printf("不推荐\n");
else if (age < 20) printf("十八洞\n");
else if (age < 40) printf("龙山茨岩塘\n");
else if (age < 60) printf("永顺塔卧\n");
else printf("湘西州博物馆\n");
}竞赛报名表检查
当前,同学们对参加某学科竞赛的积极性很高,纷纷在报名表上填写了自己的学号和姓名。但是,存在有些学生忘记了填写报名表,也有些学生多次填写了报名表。请编写程序,查看某学生填写报名表的次数。
输入格式:
第一行输入报名表的行数N(0<=N<10000).
接下来输入N行,每行包含学号(6位正整数)和姓名(长度不超过10个的汉字字符)
最后一行是待查询的学生的学号(6位正整数)。
输出格式:
在一行中输出该学生填写报名表的次数。
输入样例:
plain
5
210203 张三
210204 李四
210205 王五
210206 周六
210203 张三
210203输出样例:
plain
2
c
#include <stdio.h>
int main() {
int N;
scanf("%d", &N);
int ids[10000];
char name[64];
for (int i = 0; i < N; i++) {
scanf("%d %s", &ids[i], name);
}
int query;
scanf("%d", &query);
int cnt = 0;
for (int i = 0; i < N; i++) {
if (ids[i] == query) cnt++;
}
printf("%d\n", cnt);
}疫情后健康状况统计
当前,学校要求开学时统计各班同学们的健康状况。请编写程序,根据输入的学生健康状态清单,统计各种状态的人数。其中学号用六位整数表示,如220102,数字0代表"未感染",数字1代表"阳过",数字2代表"阳康"。
输入格式:
在第一行中给出1个正整数N(不超过100),表示学生个数。
接下来N行的每一行包括学号和健康状态。
输出格式:
输出三行。
第一行输出"未感染"及其未感染人数。
第二行输出"阳过"及其阳过人数。
第三行输出"阳康"及其阳康人数。
输入样例:
plain
5
220101 0
220102 1
220103 2
220104 2
220105 2输出样例:
plain
未感染 1
阳过 1
阳康 3
c
#include <stdio.h>
int main() {
int N;
scanf("%d", &N);
int id, status;
int cnt0 = 0, cnt1 = 0, cnt2 = 0;
for (int i = 0; i < N; i++) {
scanf("%d %d", &id, &status);
if (status == 0) cnt0++;
else if (status == 1) cnt1++;
else if (status == 2) cnt2++;
}
printf("未感染 %d\n", cnt0);
printf("阳过 %d\n", cnt1);
printf("阳康 %d\n", cnt2);
return 0;
}超级大力士
一只常见的小黑蚂蚁的体重在0.005g左右,但它们能举起超过自身体重400倍的物体,如果为难一下小蚂蚁,让它们把一头大象举起来,这些大力士能做到吗?
请编写程序计算需要多少只蚂蚁可以举起大象。本题假定蚂蚁的体重正好为0.005g,能举起来的重量恰好是400倍体重。
输入格式:
输入一行给出一个正数W(≤4000)代表大象体重数(公斤Kg)。
输出格式:
在一行中输出一个整数,表示蚂蚁的数量。
输入样例:
plain
3000输出样例:
plain
1500000
c
#include <stdio.h>
int main(){
int W;
scanf("%d", &W);
int elephant = W * 1000; // g
int per = 2; // g
int ants = (elephant + per - 1) / per;
printf("%d\n", ants);
return 0;
}传染病传播速度
R0值是基本传染数的简称,指的是在没有采取任何干预措施的情况下,平均每位感染者在传染期内使易感者个体致病的数量。数字越大说明传播能力越强,控制难度越大。一个人传染的人的数量可以用幂运算来计算。假设奥密克戎的R0为10,则1轮内有1人感染,2轮内有1 + 10^1=11人感染,3轮内有1 + 10 + 10^2=111人感染,4轮内有1 + 10 + 10^2 + 10^3=1111人感染,以此类推。
根据以上计算规则,对已知人口规模的城市和R0值,求需要经过几轮传播后会达到全民感染?
输入格式:
输入一行给出两个正整数N和R0,N(≤20000000)代表城市人口总量;R0表示病毒的传染基数,输入以空格分隔。
输出格式:
在一行中输出传播轮数。
输入样例:
plain
100000 10输出样例:
plain
6思路:
这是一个等比数列累加:
- 首项:1
- 公比:R0
- 每一轮新增人数 = 上一轮新增 × R0
你不需要算幂函数,也不需要公式,只要:
每一轮把"新增人数"乘以 R0,加进总人
c
#include <stdio.h>
int main() {
int N, R0;
scanf("%d %d", &N, &R0);
long long total = 1; // 当前累计感染人数
long long cur = 1; // 当前轮新增人数(R0 的幂)
int round = 1; // 当前传播轮数
while (total < N) {
cur *= R0; // 下一轮新增感染
total += cur; // 累计
round++;
}
printf("%d\n", round);
}今昔是何年
天干地支,简称为干支,源自中国远古时代对天象的观测。十干是指阏逢、旃蒙、柔兆、强圉、著雍、屠维、上章、重光、玄黓、昭阳。十二支是指困敦、赤奋若、摄提格、单阏、执徐、大荒落、敦牂、协洽、涒滩、作噩、阉茂、大渊献。简化后"甲、乙、丙、丁、戊、己、庚、辛、壬、癸"称为十天干,"子、丑、寅、卯、辰、巳、午、未、申、酉、戌、亥"称为十二地支。干支纪年一个周期的第1年为"甲子",第2年为"乙丑",第3年为"丙寅",...,第11年为"甲戌",第12年为"乙亥",第13年为"丙子",依此类推,60年一个周期;一个周期完了重复使用,周而复始。
已知2022年为"壬寅"年,1984年为"甲子"年,请根据给定的年份,求对应年份的干支。
输入格式:
第一行包含一个整数T(1≤T≤1000),表示一共有T个样例,后面T行,每行包含一个整数 Y (1≤Y≤5000),代表一个年份。
输出格式:
对于每个测试样例,输出相应的干支。
输入样例:
plain
4
1800
1984
2000
2023输出样例:
plain
庚申
甲子
庚辰
癸卯思路:
核心公式:
(x % m + m) % m
这是把 x 映射到 0~m-1 的安全写法
- 定义数组的时候:
c
char *gan[10]gan 是一个数组,数组里有 10 个元素,每个元素是 char*
用法实例:
c
char *gan[] = {"甲","乙","丙"};
printf("%s", gan[0]); // 打印 甲- 算年份的天干地支下标
(d % 12 + 12) 是在干嘛?把负数"拉回正数范围"
例 1:d = -1
plain
d % 12 = -1
-1 + 12 = 11回到了 0~11 范围
为什么还要再 % 12 一次?
这就是最后一步:
plain
(d % 12 + 12) % 12它的作用是:
不管你是刚好加完,还是加过头,
都统一压回 0~11
d = 5
plain
5 % 12 = 5
5 + 12 = 17
17 % 12 = 5
c
#include <stdio.h>
int main() {
char *gan[10] = {"甲","乙","丙","丁","戊","己","庚","辛","壬","癸"};
char *zhi[12] = {"子","丑","寅","卯","辰","巳","午","未","申","酉","戌","亥"};
int T;
scanf("%d", &T);
while (T--) {
int Y;
scanf("%d", &Y);
int d = Y - 1984;
int g = (d % 10 + 10) % 10;
int z = (d % 12 + 12) % 12;
printf("%s%s\n", gan[g], zhi[z]);
}
return 0;
}测试三
元旦晚会开支预算
假设你是一名班委,学院将举办一场元旦迎新晚会,你负责购买一些参会用品。你需要计算所需用品的总成本。每种用品的数量和单价可能不同,你需要将每种用品的数量与单价相乘,然后将所有用品的总费用加起来,得出总成本。
例如,你购买了多种用品(如气球、横幅、餐具等),每种用品的数量和单价不同。你的任务是计算所有用品的总成本。
函数接口定义:
c
unsigned int Calculate_Event_Cost(unsigned int* item_quantities, unsigned int* item_prices, unsigned int num_items);参数说明:
item_quantities:一个长度为 num_items 的整数数组,表示每种用品的购买数量。
item_prices:一个长度为 num_items 的整数数组,表示每种用品的单价。
num_items:表示用品的种类数,即数组 item_quantities 和 item_prices 的长度。
裁判测试程序样例:
c
#include <stdio.h>
unsigned int Calculate_Event_Cost(unsigned int* item_quantities, unsigned int* item_prices, unsigned int num_items);
int main()
{
unsigned int n;
scanf("%u", &n); //保证输入的n大于0
unsigned int quantities[n], prices[n];
for (int i = 0; i < n; i++) {
scanf("%d", &quantities[i]);
}
for (int i = 0; i < n; i++) {
scanf("%d", &prices[i]);
}
printf("%u", Calculate_Event_Cost(quantities, prices, n));
return 0;
}
/* 请在这里填写答案 */输入样例:
plain
4
10 5 20 0
2 3 1 888输出样例:
在这里给出相应的输出。例如:
plain
55
c
unsigned int Calculate_Event_Cost(unsigned int* item_quantities,
unsigned int* item_prices,
unsigned int num_items)
{
unsigned int total = 0;
for (unsigned int i = 0; i < num_items; i++) {
total += item_quantities[i] * item_prices[i];
}
return total;
}数组归并
计算机由于不同存储位置的大小和运行速度不同,在计算机中排序的时候有时候离不开外部排序,外部排序的思想离不开归并。现在希望你能够使用归并的思想解决一个问题。
给你两个非递减的数组序列,请你将他们归并为一个非递减的数组序列,并逆序输出两个序列合并的结果。两个数组的长度与都小于等于一百,数组的值大于等于 0 小于等于 100。
函数接口定义:
c
void merge(int* a, int n, int* b, int m);a,b 为两个非递减的数组,n 为数组 a 的长度,m 为数组 b 的长度。
裁判测试程序样例:
c
#include <stdio.h>
#define N 110
int a[N], b[N];
void merge(int* a, int n, int* b, int m);
int main()
{
int n, m;
scanf("%d%d", &n, &m);
for(int i = 0; i < n; i ++)
scanf("%d", &a[i]);
for(int i = 0; i < m; i ++)
scanf("%d", &b[i]);
merge(a, n, b, m);
return 0;
}输入样例:
在这里给出一组输入。例如:
plain
2 3
1 2
1 2 3输出样例:
在这里给出相应的输出。例如:
plain
3 2 2 1 1正确高效思路:双指针 + 从后往前
两个数组是 升序,最大的数一定在 数组末尾
用两个指针
i = n - 1 指向 a 的末尾
j = m - 1 指向 b 的末尾
每次比较 a[i] 和 b[j]
谁大,就先放进结果数组
指针往前移动
这样可以 一次扫描完成合并
c
void merge(int* a, int n, int* b, int m)
{
int i = n - 1, j = m - 1; // 从两个数组末尾开始取最大值
int c[210], k = 0; // 合并后的数组(n,m<=100)
while (i >= 0 && j >= 0) {
if (a[i] >= b[j]) c[k++] = a[i--];
else c[k++] = b[j--];
}
// 如果 b 先用完
while (i >= 0) c[k++] = a[i--];
while (j >= 0) c[k++] = b[j--];
for (int t = 0; t < k; t++) {
printf("%d ", c[t]); // 逆序输出结果(已是从大到小)
}
}运动打卡记录倒序
某系统有若干条运动打卡记录信息存放在数组中,现在需要将其倒序存放。
请设计函数void reverse(SportRecord * p,int n)实现将p所指数组起始地址处存放的n个结构体倒序存放。
其中SportRecord为自定义的结构体类型,p存放运动打卡信息结构体数组的首地址,n表示该数组中结构体的个数。
每条运动打卡记录包括信息项有:姓名、日期、项目、运动时长。
函数接口定义:
c
void reverse(SportRecord * p,int n);输入:
第一行为一个正整数n(n<=100)。其后的n行为空格分隔的运动打卡信息。
输出:
按输出举例的格式,输出倒序后的运动打卡记录。
裁判测试程序样例:
c
#include <stdio.h>
typedef struct{
char name[31];//姓名
char date[11];//日期
char sport[31];//项目
unsigned timeLen;//时长
} SportRecord;
void show(SportRecord* recs, int n);//函数接口定义
void reverse(SportRecord * p,int n);//函数接口定义
int main(){
int i,n;
scanf("%d",&n);
SportRecord * recs=malloc(n*sizeof(SportRecord));
for(i=0;i<n;i++)
scanf("%s %s %s %u", recs[i].name, recs[i].date,
recs[i].sport, &recs[i].timeLen);
reverse(recs,n);//倒序运动打卡记录
show(recs,n);//显示倒序后的运动打卡记录
return 0;
}
void show(SportRecord* recs, int n){
int i;
for(i=0;i<n;i++)
printf("姓名:%s,日期:%s,项目:%s,时长:%u分钟\n",
recs[i].name,recs[i].date,recs[i].sport,recs[i].timeLen);
}
/*请在此补充函数reverse的代码*/输入样例:
plain
10
张三 2024-12-25 跑步 30
李四 2024-12-26 打羽毛球 120
王五 2024-12-27 健身 65
赵六 2024-12-28 游泳 90
刘七 2024-12-29 打篮球 118
朱八 2024-12-30 跳拉丁舞 50
陈九 2024-12-31 踢足球 104
杜十 2025-01-01 骑自行车 63
吴依 2025-01-02 跳街舞 45
周而 2025-01-03 打乒乓球 75输出样例:
plain
姓名:周而,日期:2025-01-03,项目:打乒乓球,时长:75分钟
姓名:吴依,日期:2025-01-02,项目:跳街舞,时长:45分钟
姓名:杜十,日期:2025-01-01,项目:骑自行车,时长:63分钟
姓名:陈九,日期:2024-12-31,项目:踢足球,时长:104分钟
姓名:朱八,日期:2024-12-30,项目:跳拉丁舞,时长:50分钟
姓名:刘七,日期:2024-12-29,项目:打篮球,时长:118分钟
姓名:赵六,日期:2024-12-28,项目:游泳,时长:90分钟
姓名:王五,日期:2024-12-27,项目:健身,时长:65分钟
姓名:李四,日期:2024-12-26,项目:打羽毛球,时长:120分钟
姓名:张三,日期:2024-12-25,项目:跑步,时长:30分钟解题思路:
把输入的 n 条结构体记录整体倒过来输出
- 不是按日期排序
- 不是按时长排序
- 就是:第 1 条 ↔ 第 n 条,第 2 条 ↔ 第 n-1 条
c
void reverse(SportRecord *p, int n)
{
int i = 0, j = n - 1;
while (i < j) {
SportRecord tmp = p[i];
p[i] = p[j];
p[j] = tmp;
i++;
j--;
}
}半斤八两
在传统中国的度量衡系统里,一斤等于十六两,而现代中国采用公制单位,规定一斤为 500 克(即 0.5 千克),由此可得 1(旧制)两 = 500 克 ÷16 ≈ 31.25 克。在一些涉及传统文化(比如中药、古董交易等领域)的情况中,常常需要在传统的 "两" 这一计量单位与公制的 "克" 之间进行换算,若有以 "两" 为单位的重量,换算成公制单位 "克" 时,可将 "两" 的数值乘以 31.25;若有以 "克" 为单位的重量想转换为 "两",则可将克数除以 31.25。
请你编写一个 C 语言程序来实现上述的度量衡单位换算功能。具体要求如下:
程序开始运行后,提示用户输入一个整数选项,输入 <font style="color:rgb(231, 76, 60);">1</font> 表示要将传统度量衡中的 "两" 转换为 "克",输入 <font style="color:rgb(231, 76, 60);">2</font> 表示要将公制单位中的 "克" 转换为传统度量衡的 "两"。
根据用户输入的选项进行相应的操作:
若用户输入 <font style="color:rgb(231, 76, 60);">1</font>:接着提示用户输入一个表示 "两" 的数值(该数值为实数),然后按照 "两" 转 "克" 的换算规则(数值乘以 31.25)进行计算,并输出换算后对应的 "克" 的数值,结果保留两位小数。
若用户输入 <font style="color:rgb(231, 76, 60);">2</font>:接着提示用户输入一个表示 "克" 的数值(该数值为实数),然后按照 "克" 转 "两" 的换算规则(数值除以 31.25)进行计算,并输出换算后对应的 "两" 的数值,结果保留一位小数。
如果用户输入的选项既不是 <font style="color:rgb(231, 76, 60);">1</font> 也不是 <font style="color:rgb(231, 76, 60);">2</font>,则输出提示信息 "输入的选项不合法,请重新输入正确选项。",然后结束程序。
输入格式:
输入为两行,第一行输入一个整数,如果是1,则第二行输入一个表示"两"的数值;
如果是2,则第二行输入一个表示"克"的数值;如果第一行不是1或2,则第二行无需输入。
输出格式:
输出为一行,行末无换行和空格。
输入样例1:
在这里给出一组输入。例如:
plain
1
3.5输出样例1:
在这里给出相应的输出。例如:
plain
109.38输入样例2:
在这里给出一组输入。例如:
plain
2
109.38输出样例2:
在这里给出相应的输出。例如:
plain
3.5
c
#include <stdio.h>
#include <stdlib.h>
int main(){
int op;
double a,b;
scanf("%d",&op);
scanf("%lf",&a);
if(op==1){
b=a*31.25;
printf("%.2f",b);
}else if (op==2){
b=a/31.25;
printf("%.1f",b);
}else{
printf("输入的选项不合法,请重新输入正确选项。");
}
} 革命之路
在革命历史中,红军战士们常常需要长途跋涉执行任务。假设一位红军战士在一次行军任务中,每天行走的路程不同,但每天的行程都有重要意义。已知第一天行走的路程为 a 公里,从第二天开始,每天行走的路程比前一天多 d 公里( d 为正数,象征着革命事业不断前进的步伐),请编写一个 C 程序,计算前 n 天该红军战士行走的总路程。这不仅体现了红军战士坚韧不拔的行军精神,也反映了他们为革命事业不懈奋斗、不断积累成果的过程。
0≤a,d,n≤104
输入格式:
第一行三个整数表示第一天行走的路程a,每天增加的路程 d,以及天数 n
输出格式:
一个整数表示 n 天行走的总距离
输入样例:
plain
15 1 14输出样例:
plain
301思路:
等差数列前 n 项和 = 项数 ×(首项 + 末项)÷ 2
套入此题:
c
sum = n * (2 * a + (n - 1) * d) / 2;
c
#include <stdio.h>
int main(){
int a,d,n;
scanf("%d %d %d",&a,&d,&n);
int sum=n*(a+a+(n-1)*d)/2;
printf("%d",sum);
}学年学期
任务描述:
学年学期通常有如下两种表示方式:
例1:
方式1:2024-2025-1,意思为2024-2025学年的第1学期
方式2:2024年秋季学期,意思为2024学年中学期主体在秋季的那个学期
例2:
方式1:2024-2025-2,意思为2024-2025学年的第2学期
方式2:2025年春季学期,意思为2025学年中学期主体在春季的那个学期
现以方式1给出某学年学期,输出以方式2表示的该学年学期。
输入格式:
以方式1给出某学年学期
输出格式:
以方式2表示的该学年学期
输入样例:
在这里给出一组输入。例如:
plain
2024-2025-2输出样例:
在这里给出相应的输出。例如:
plain
2025年春季学期
c
#include <stdio.h>
int main() {
int y1, y2, term;
scanf("%d-%d-%d", &y1, &y2, &term);
if (term == 1) printf("%d年秋季学期", y1);
else if (term == 2) printf("%d年春季学期", y2);
return 0;
}游戏场景
一个游戏中,角色有不同的属性值,其中包括生命值(hp)、攻击力(attack)和防御力(defense)。现在需要根据不同的战斗场景来计算角色在受到对方攻击后的剩余生命值。假设战斗场景分为三种,通过输入一个整数 scene 来表示:
①scene 为 1 时,表示普通战斗场景。角色受到的伤害 damage 为对方攻击力减去自身防御力(若结果小于等于 0,则伤害为 1)。计算剩余生命值 remainingHp 为当前生命值减去伤害值。如果剩余生命值小于等于 0,则输出 "角色已死亡",否则输出剩余生命值,保留两位小数。
②scene 为 2 时,表示魔法战斗场景。角色受到的伤害 damage 为对方攻击力的 1.5 倍减去自身防御力的 0.8 倍(若结果小于等于 0,则伤害为 1)。同样计算剩余生命值 remainingHp 并按上述规则输出。
③scene 为 3 时,表示 boss 战斗场景。角色受到的伤害 damage 为对方攻击力的 2 倍减去自身防御力(若结果小于等于 0,则伤害为 1)。计算剩余生命值 remainingHp 并按上述规则输出。
如果输入的 scene 不是 1、2、3 中的任何一个值,则输出 "无效的战斗场景"。
输入格式:
第一行三个实数,表示自身生命值,防御力,对方攻击力,第二行一个整数表示战斗场景。
输出格式:
保留两位小数的剩余生命值或角色已死亡或无效的战斗场景。
输入样例:
plain
100 50 10
1输出样例:
plain
99.00
c
#include <stdio.h>
int main() {
double hp, defense, attack;
int scene;
double damage, remainingHp;
scanf("%lf %lf %lf", &hp, &defense, &attack);
scanf("%d", &scene);
if (scene == 1) { // 普通战斗
damage = attack - defense;
if (damage <= 0) damage = 1;
} else if (scene == 2) { // 魔法战斗
damage = attack * 1.5 - defense * 0.8;
if (damage <= 0) damage = 1;
} else if (scene == 3) { // boss 战
damage = attack * 2 - defense;
if (damage <= 0) damage = 1;
} else {
printf("无效的战斗场景");
//别忘了这个
return 0;
}
remainingHp = hp - damage;
if (remainingHp <= 0) {
printf("角色已死亡");
} else {
printf("%.2f", remainingHp);
}
return 0;
}四季阶梯电计价
2024年1月31日, 湖南省发改委网站发布《关于我省居民阶梯电价制度及有关事项的通知》。该通知自2024年2月1日起施行,有效期5年。
任务:
根据下表,计算"一户一表"分档电量下所需缴纳的电费。根据通知规定,春秋季(3、4、5、9、10、11月),冬夏季(1、2、6、7、8、12月)。

输入格式:
输入在一行中给出2个整数M和E,M表示月份(1-12),E表示该月使用的总电量(≥1,单位:千瓦时)。
输出格式:
输出结果固定有四行,每行只有1个浮点数。前三行分别表示第一、二、三档的分档电价,第四行表示前三行的总和。输出格式取小数点后1位(若未达到第二档的电量,则第二行和第三行均输出0.0)。
输入样例1:
plain
5 350输出样例1:
plain
117.6
95.7
0.0
213.3输入样例2:
plain
11 120输出样例2:
plain
70.6
0.0
0.0
70.6输入:M 月份,E 这个月总用电量(度/kWh)
- 春秋季:3、4、5、9、10、11 月
第二档上限是 350(也就是:200~350 属于第二档,>350 才第三档) - 冬夏季:1、2、6、7、8、12 月
第二档上限是 450(200~450 是第二档,>450 才第三档) e1:第一档用了多少度e2:第二档用了多少度e3:第三档用了多少度
单价在这儿:
plain
p1 = 0.588
p2 = 0.588 + 0.05 = 0.638
p3 = 0.588 + 0.30 = 0.888然后算钱:
plain
double c1 = e1 * p1;
double c2 = e2 * p2;
double c3 = e3 * p3;
double sum = c1 + c2 + c3;
c
#include <stdio.h>
int main() {
int M, E;
scanf("%d%d", &M, &E);
/* 分档电价(元/千瓦时) */
double p1 = 0.588;
double p2 = 0.588 + 0.05; /* 0.638 */
double p3 = 0.588 + 0.30; /* 0.888 */
/* 第二档上限:春秋(3,4,5,9,10,11)为350;冬夏(1,2,6,7,8,12)为450 */
int second_limit = (M==3||M==4||M==5||M==9||M==10||M==11) ? 350 : 450;
int e1 = 0, e2 = 0, e3 = 0;
if (E <= 200) {
e1 = E;
} else if (E <= second_limit) {
e1 = 200;
e2 = E - 200;
} else {
e1 = 200;
e2 = second_limit - 200;
e3 = E - second_limit;
}
double c1 = e1 * p1;
double c2 = e2 * p2;
double c3 = e3 * p3;
double sum = c1 + c2 + c3;
printf("%.1f\n%.1f\n%.1f\n%.1f", c1, c2, c3, sum);
return 0;
}产品评价分析师
在电商行业竞争日益激烈的当下,了解用户对于产品的真实反馈至关重要。你作为一家电商公司市场部门的工作人员,公司已经收集了海量用户对于某款产品的评价内容,这些评价内容以文本数据的形式存在,包含了各种各样丰富的信息。为了能从这些繁杂的文本数据中挖掘出有价值的洞察,你需要对这些评价内容进行深度分析,而其中一个基础且关键的步骤就是统计文本中各个英文字母出现的频次,通过分析字母的分布情况,进而推测用户常用描述词汇的特点,比如,如果字母'e'出现的次数特别多,那很可能用户在评价里经常会用到像'excellent'(优秀的)、'effective'(有效的)这类包含较多'e'的积极词汇,这意味着产品在某些方面得到了用户较高的认可;反之,若某个字母出现频率较低且对应的都是负面含义的词汇,那可能就是产品需要改进的地方。
现给定一个字符串,该字符串模拟的就是从众多用户对某款产品评价内容中提取出来的一部分(字符串中可能包含大小写英文字母、数字、标点符号以及各种特殊字符等任意组合),请你编写一个程序,实现对这个字符串中所出现的英文字母(不区分大小写)的次数进行准确统计。例如,字符串中的字母 'a' 和 'A' 应被视为同一个字母,它们出现的总次数要合并计算。最终,我们可以依据统计结果来分析用户在评价里常用描述词汇中字母的分布情况,以此为产品的优化和市场策略调整提供有力的数据支撑。
输入格式:
输入为一行字符串,其长度不超过 1000 个字符,字符串内容就是模拟的用户评价文本片段,包含各种类型的字符混合。
输出格式:
按照字母表顺序(小写字母顺序),每行输出一个字母及其在输入字符串中出现的次数(不区分大小写),格式为 字母 : 出现次数,即 a : 2,每个字符之间用空格分开;如果某个字母在输入字符串中未出现,则不输出对应行。每个输出行之间以换行符分隔。
输入样例:
在这里给出一组输入。例如:
plain
Hello, World!输出样例:
在这里给出相应的输出。例如:
plain
d : 1
e : 1
h : 1
l : 3
o : 2
r : 1
w : 1
c
#include <stdio.h>
#include <ctype.h>
int main() {
char s[1005]; // 字符串长度 ≤ 1000
int cnt[26] = {0};
// 用 fgets 读取一整行
fgets(s, sizeof(s), stdin);
// 遍历字符串
for (int i = 0; s[i]; i++) {
if (isalpha(s[i])) {
char c = tolower(s[i]);
cnt[c - 'a']++;
}
}
// 按字母表顺序输出
for (int i = 0; i < 26; i++) {
if (cnt[i] > 0) {
printf("%c : %d\n", 'a' + i, cnt[i]);
}
}
return 0;
}学习时间点记录助手
题目背景:
你是一名大一学生,正在为期末考试进行复习。在复习过程中,为了有效管理时间和监控复习进度,你需要定时记录每10分钟的学习时间点。你的复习开始于某个特定的时间点,并将在规定的总时长内完成。为了准确记录每个时间节点,你需要编写一个程序,帮助你每隔 10分钟 自动记录当前时间,直到复习结束。
任务要求:
输入:
(1)起始时间:以 HH:MM 格式表示,代表任务开始的时间。
(2)任务总时长:一个整数 X(1 ≤ X ≤ 120),表示任务的总持续时间,单位为分钟。
输出:
(1)从复习开始时间后的第一个 10分钟 开始,每隔 10分钟 输出一次当前时间,直到复习总时长结束。
(2)如果复习总时长不是 10的倍数,在最后剩余不足 10分钟 的时间段,也需输出一次最终的时间记录。
(3)输出格式为 序号 时间,其中序号从 1 开始,时间格式为 HH:MM。
(4)时间需要处理 24小时制 的跨天情况(例如,从 23:59 增加10分钟后应为 00:09)。
输入格式:
一行数据,包含两个部分,用空格分隔:
第一个部分为 HH:MM 格式的起始时间。
第二个部分为一个整数 X,表示任务总时长(分钟)。保证X在规定范围内。
输出格式:
每隔 10分钟 输出一次记录,直到任务结束。
每行包含两个部分:
(1)序号(从1开始)。
(2)当前时间,格式为 HH:MM。
输入样例:
在这里给出一组输入。例如:
plain
23:59 66输出样例1:
在这里给出相应的输出。例如:
plain
1 00:09
2 00:19
3 00:29
4 00:39
5 00:49
6 00:59
7 01:05输入样例:
在这里给出一组输入。例如:
c
12:15 120输出样例2:
在这里给出相应的输出。例如:
plain
1 12:25
2 12:35
3 12:45
4 12:55
5 13:05
6 13:15
7 13:25
8 13:35
9 13:45
10 13:55
11 14:05
12 14:15思路:
- 把起始时间 HH:MM 转成「总分钟数」
plain
总分钟 = HH * 60 + MM- 每次加 10 分钟,直到超过总时长 X
你要输出的时间点是:
plain
起始时间 + 10
起始时间 + 20
起始时间 + 30
...
起始时间 + X⚠️ 注意:
最后一次不一定是 +10
如果 X 不是 10 的倍数,最后一次是 +X
- 处理"跨天"(24 小时制)
一天一共有:
plain
24 * 60 = 1440 分钟所以只要:
plain
当前时间 = (起始分钟 + 增加分钟) % 1440就能自动回到 00:00
c
int main(){
// 小时,分钟,总时长
int h,m,X;
scanf("%d:%d %d",&h,&m,&X);
//变成分钟
int start=h*60+m;
// 题目序号从1开始
int idx=1;
// 第一个10分钟,每次加10,不超过总时长
for(int i=10;i<=X;i+=10){
//算当前时间
int cur=(start+i)%1440;
printf("%d %02d:%02d\n",idx++,cur/60,cur%60);
}
if(X%10!=0){
int cur=(start+X)%1440;
printf("%d %02d:%02d",idx,cur/60,cur%60);
}
}叛逆的计算机
计算机是人类用来解决计算的工具,它只认识 0 和 1 两个数字,但是人类日常生活却习惯十进制。现在小明有一台电脑,但是他的显示出现了一种奇怪的有规律的异常(叛逆),他会把 0 显示成 1,把 1 显示成 0。现在给你一个电脑显示的 0/1 串,请你输出他的真实十进制值是多少。
输入格式:
输入一个 0/1 串 S,S 的长度小于等于 30。(可能含有前导零)
输出格式:
输出真实十进制值。
输入样例:
在这里给出一组输入。例如:
c
0101输出样例:
在这里给出相应的输出。例如:
plain
10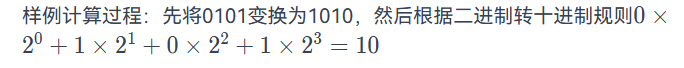
关键解题思路:
- 为什么定义char s35输入而不是int 类型
如果一开始写:
plain
int x;
scanf("%d", &x);实际读到的是:
plain
x = 101❌ 前导 0 丢失了
而这道题里:
0101 和 101
在 位数、处理顺序上是完全不同的
- 把"显示的位"翻成"真实的位"
题目说:
| 显示 | 实际 |
|---|---|
| 0 | 1 |
| 1 | 0 |
所以:
看到 '0' → 实际是 1
看到 '1' → 实际是 0
char bit = (si == '0') ? 1 : 0;
si 和bit的区别?
| 名字 | 类型 | 表示的东西 |
|---|---|---|
s[i] |
char |
字符 '0' 或 '1' |
bit |
char / int |
数值 0 或 1 |
- 边翻转,边转十进制(关键思想)
二进制转十进制通用公式
plain
当前值 = 当前值 × 2 + 当前位×2:相当于左移一位
+ 当前位:加上 0 或 1
val = val * 2 + bit;
c
#include <stdio.h>
int main() {
char s[35];
scanf("%s", s);
int val = 0;
for (int i = 0; s[i]; i++) {
int bit = (s[i] == '0') ? 1 : 0; // 0<->1 还原真实位
val = val * 2 + bit;
}
printf("%d", val);
return 0;
}子棋判胜负
五子棋的胜负规则十分简单,对弈双方先将至少5个自己棋子相连者为胜。
现对于给定对弈的当前棋局,判断是否已经分出胜负,如果已经分出胜负,那么是哪方胜出?
输入格式:
第一行为一个正整数N(N<=100),表示棋盘的大小,即每行每列最多可放棋子的个数为N。
其后N行N列为当前棋局。0表示未落子的空位,其中的1表示白子,2表示黑子。同行的列间为空格分隔。
输入已确保棋局合理,即不存在黑白双方都有5子相连的情形。
输出格式:
当前棋局的结果只能是以下三者之一:
(1)白方胜利
(2)黑方胜利
(3)胜负未分
注意:结果不能是"白子胜出"、"黑子胜出""胜负未决"、"胜负未定"或其它表达。
输入样例:
在这里给出一组输入。例如:
plain
15
0 0 0 0 0 0 0 1 1 0 0 0 0 0 0
0 0 0 0 0 2 2 2 2 1 0 0 0 0 0
0 0 0 0 1 0 2 1 0 2 2 0 0 0 0
1 0 0 1 0 2 0 1 2 2 2 2 1 0 0
0 2 1 2 2 2 2 1 1 1 1 2 2 0 0
2 1 2 0 2 1 0 2 2 2 1 1 1 2 0
2 1 1 2 1 1 1 1 2 2 2 1 1 1 1
0 0 1 0 2 1 1 1 2 1 2 1 1 0 0
0 1 1 1 2 1 2 1 2 1 1 2 2 2 0
0 2 1 0 1 2 2 2 1 0 2 0 1 0 0
0 1 2 2 2 2 1 1 2 2 2 0 0 0 0
0 0 0 0 0 2 1 1 1 2 1 0 0 0 0
0 0 0 0 1 2 2 2 0 1 1 0 0 0 0
0 0 0 0 0 1 1 2 1 0 1 0 0 0 0
0 0 0 0 0 0 0 0 1 0 0 2 0 0 0输出样例:
在这里给出相应的输出。例如:
plain
胜负未分
c
#include <stdio.h>
int main() {
int N;
scanf("%d", &N);
int g[105][105];
for (int i = 0; i < N; i++)
for (int j = 0; j < N; j++)
scanf("%d", &g[i][j]);
int dx[4] = {0, 1, 1, 1}; // 右、下、右下、右上
int dy[4] = {1, 0, 1, -1};
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
int p = g[i][j];
if (p == 0) continue;
for (int k = 0; k < 4; k++) {
int cnt = 1;
int x = i + dx[k], y = j + dy[k];
while (x >= 0 && x < N && y >= 0 && y < N && g[x][y] == p) {
cnt++;
if (cnt >= 5) {
if (p == 1) printf("白方胜利");
else printf("黑方胜利");
return 0;
}
x += dx[k];
y += dy[k];
}
}
}
}
printf("胜负未分");
return 0;
}