一、研究动机:传统微调的根本困境
1.1 问题的本质
大语言模型(LLM)在完成预训练后,通常需要通过监督微调(SFT)来适配特定的下游任务。然而,传统SFT存在一个被长期忽视的根本性问题:语言的 "一对多"特性 与训练目标的 "一对一"强制对齐之间的矛盾。
什么是"一对多"特性?简单来说,同一个意图可以用多种不同的方式表达。比如:
- "请计算3加5的结果"
- "3+5等于多少?"
- "把3和5相加得到什么?"
这三句话表达的是完全相同的意图,但传统SFT会强制模型只学习其中一种表达方式。如果训练数据中只有第一种表达,模型就会被"惩罚"为没有生成"请计算"这样的特定词汇------即使它给出了正确答案。
1.2 直觉解法的困境
既然单一参考答案有问题,那提供多个参考答案不就解决了吗?研究团队对此进行了实验验证,发现这条路走不通:
- 成本问题:每条指令收集K个高质量答案,标注成本线性增长
- 优化冲突:多个参考答案之间可能存在分布冲突,导致梯度方向相互干扰
- 效果不稳定:在GPQA-Diamond等复杂基准上,多答案训练甚至出现性能下降(从34.1%降至33.5%)
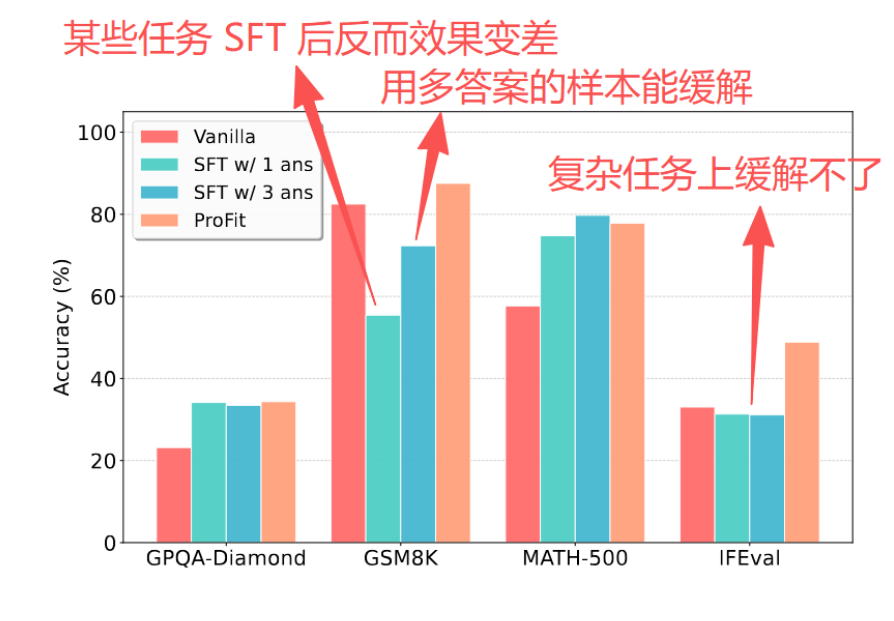
这就引出了本文的核心思路:与其追求多答案的全面覆盖,不如避免对单一答案的过拟合。
论文标题:ProFit: Utilizing High-Value Signals in SFT via Probability-Guided Token Selection
研究团队:清华大学 & 香港大学
项目地址 :https://github.com/Utaotao/ProFit
二、核心发现:Token概率与语义重要性的内在联系
2.1 关键洞察
既然我们知道了 SFT 普遍存在上述过拟合问题,那么很自然地想到:如果只挑样本中的重要信息做拟合,忽略那些不重要、可被替换的其他表述,似乎就能更精准地学习样本所蕴含的知识、忽略表面模式,从而解决这一问题
那我们又该如何区分重要信息与可替换信息呢?简单,可以用大模型来判断(Gemini-3-pro)
但总不能把每条样本都拿 Gemini 来过一遍吧?我们可以运用归纳法:在一批被 Gemini 标注好的样本上,观察重要信息、可替换信息之间的差异,寻找更轻量的通用判别条件:
- 数据准备:收集同一问题的多个正确答案
- 语义标注 :使用Gemini-3-Pro将token分为两类:
- 核心token(Core Tokens):承载关键推理逻辑的token
- 琐碎token(Trivial Tokens):可互换的风格性表达
- 概率计算:使用Qwen3-4B-Base计算每个token的预测概率
- 分布分析:对比两类 token 的概率分布
对比结果非常显著:
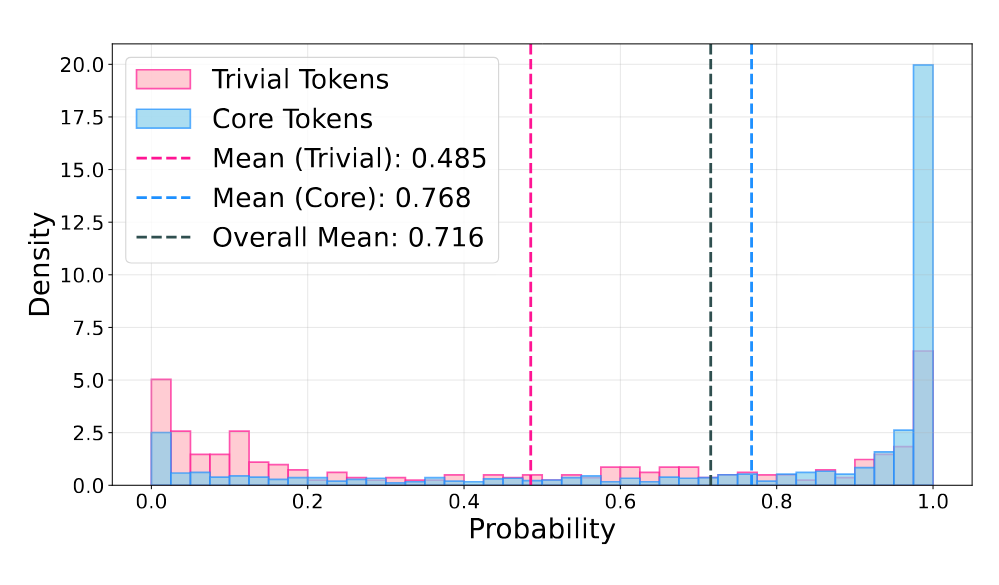
- 核心token:高度集中在高概率区域,表现出强确定性
- 琐碎token :呈现明显的长尾分布,在低概率区域占据主导
经过更严谨的统计检验,作者得出了结论:【低预测概率 】是【语义非必要性】的强指标。
2.2 直观理解
为什么会出现这种规律?可以这样理解:
当模型预测下一个token时:
- 高概率token:通常是由前文逻辑"确定性"导出的,比如数学推理中的关键步骤、因果关系的连接词
- 低概率token:往往是多种选择都可以的情况,比如"首先/第一步/开始时"这类可互换的表达
核心推理逻辑是确定性的,而表面表达是灵活的------这正是概率分布差异的根源。更要命的是,一旦模型较为自信地使用了可替换表达,SFT 会产生更强的学习信号,相当于总是在一些不重要的地方狠狠拽模型一把,进而导致训练效果的下限更低

三、ProFit 方法
于是作者提出了 ProFit,其设计理念非常简洁:只训练高价值的 token,忽略那些可能导致过拟合的低价值 token。
具体地,ProFit 使用模型当前的预测概率作为动态指标,对概率低于阈值的 token 进行掩码,使其不参与梯度更新
四、实验结果
4.1 实验设置
训练数据:从BAAI-InfinityInstruct数据集筛选2,000个高质量样本
评估模型:
- Qwen3系列(0.6B、4B、14B)
- Llama 3.1-8B
- OLMo-2-7B
评估基准:
| 基准 | 评估能力 |
|---|---|
| GPQA-Diamond | 通用推理 |
| MATH-500 | 数学推理 |
| GSM8K | 基础数学 |
| AIME'24 | 竞赛数学 |
| IFEval | 指令遵循 |
对比方法:
- 标准SFT
- DFT(动态微调):根据每个 token 的置信度为其损失分配动态权重
- 基于熵的调优:仅对熵值较高位置的 token 更新参数
4.2 主要结果
实验结果全面验证了ProFit的有效性:
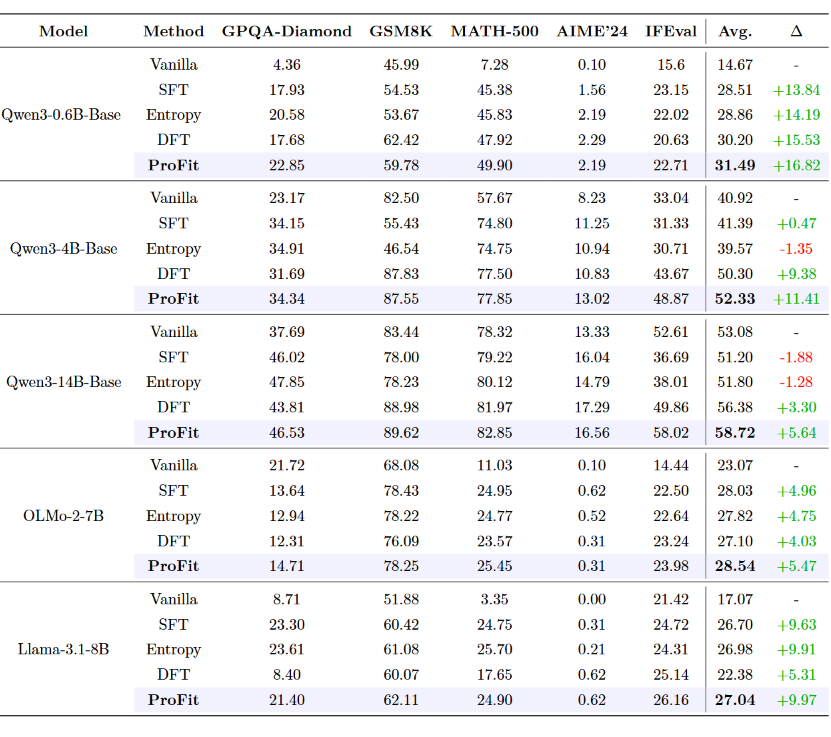
关键发现:
- 一致性提升:ProFit在所有模型和所有基准上均优于标准SFT
- 规模效应:在4B和14B模型上提升最为显著
- 负迁移修复:标准SFT在Qwen3-14B上出现性能下降(-1.88%),ProFit成功逆转并实现+5.64%提升
4.3 消融实验
阈值影响:
研究团队对比了两种策略:
- 保留高概率token:在所有阈值下均优于基准
- 保留低概率token:性能灾难性下降

这有力地证明了:高概率token是推理的"骨架",低概率token仅是"装饰"。
LoRA秩的影响:
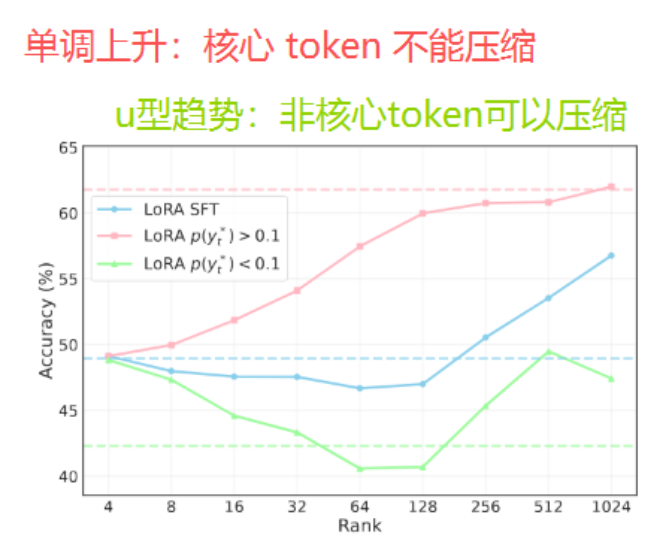
实验揭示了有趣的现象:
- 核心token:随秩增加单调受益(依赖模型容量)
- 非核心token:呈U型趋势(中等秩时优化干扰最严重)
训练效率 :
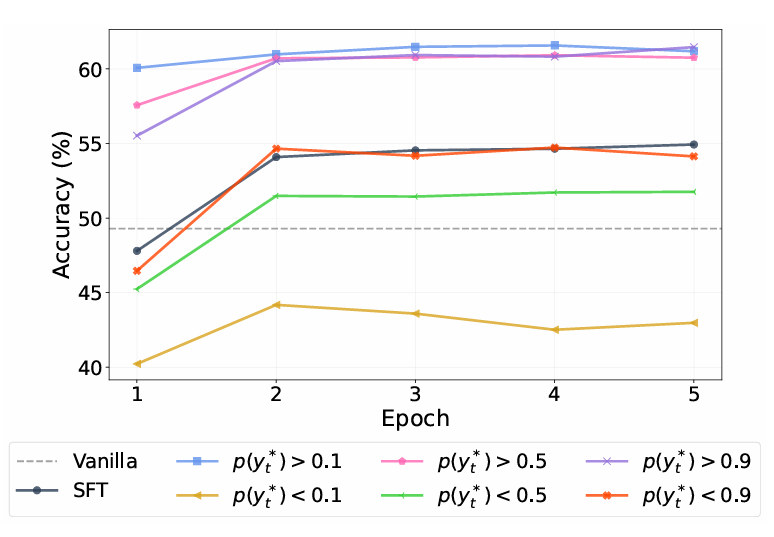
ProFit展现出卓越的收敛效率:
- 第一轮即达到60.1%准确率,超越SFT的峰值性能(54.9%)
- 训练更稳定,无明显震荡
4.4 作为RL初始化
ProFit还被验证为优秀的强化学习初始化方案:
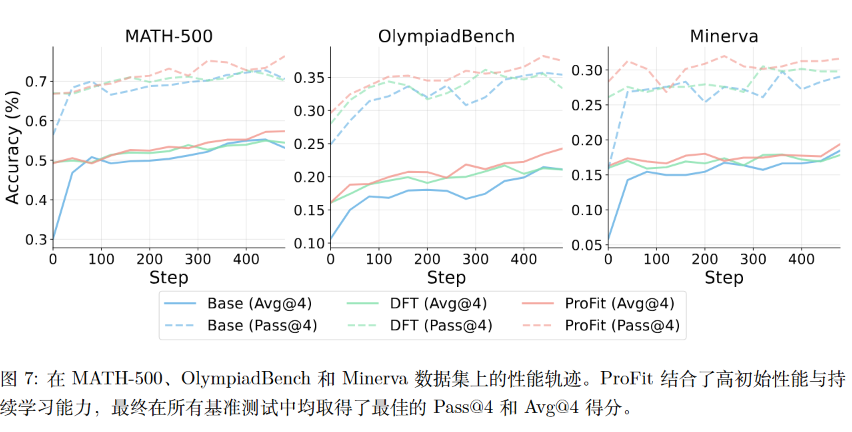
在GRPO训练中:
- MATH-500:最终Avg@4达到57.3%(vs 基准53.1%)
- OlympiadBench:Avg@4达到24.3%(vs 其他方法21.1%)
- 训练稳定性:避免了"冷启动"现象,全程保持性能提升
五、讨论
5.1 当前局限
-
任务适用性:ProFit的核心假设主要适用于逻辑密集型任务(推理、数学)。对于创意生成任务,低概率token可能对风格多样性有积极作用
-
固定阈值:当前使用静态阈值 tau=0.1,未考虑样本难度的差异
-
强基线假设 :尽管实验效果较好,但在方法设计上可能存在以下逻辑漏洞:
低概率可能有两种原因:该 token 不重要,或者模型能力不足或任务太难。如果是后一种情况,屏蔽低概率 token 等于是在"阻止模型学习它不会的东西"。不过作者在实验中使用了预训练后的 Base 模型(如Qwen3-4B-Base),已具备较强的语言建模能力
5.2 与"Beyond the 80/20 Rule"论文的对比
之前介绍过一篇阿里Qwen团队的论文:
其结论是:在 RL 训练中,大模型推理能力的提高仅由少数高熵 token 贡献
"高熵"不就意味着低概率吗?两项工作一个让只学低概率 token,一个让只学高概率 token?
实际上这两项工作并不矛盾,原因在于:
1. 测量对象不同
- ProFit的"概率":模型对正确答案token的预测概率
- Beyond 80/20的"熵":模型在该位置整体输出分布的熵
两者并非简单对应。低概率可能对应高熵(多种选择),也可能对应低熵(模型确信但选错了)。
2. 关注的token类型不同
- Beyond 80/20的高熵token :"wait", "however", "thus", "since"等------推理方向的分叉点
- ProFit的高概率token :核心推理步骤、数学运算------推理内容的骨架
两者关注的是不同维度的"重要性"
3. 训练目标的本质差异
| 阶段 | 目标 | 问题 | 策略 |
|---|---|---|---|
| SFT | 模仿参考答案 | 过拟合到非核心表达 | 不要在"有多种正确选择"的位置强制对齐 |
| RL | 探索更好路径 | 如何有效探索 | 把优化集中在推理分叉点 |
4. 底层洞察的一致性
两篇论文的共同发现是:并非所有token都同等重要。
- ProFit:低概率token的大梯度会"淹没"核心token的优化 → 需要屏蔽
- Beyond 80/20:低熵token对探索没有贡献 → 需要屏蔽
只是"重要性"的定义随训练阶段和目标而变化。