目录
[1. 什么是最好的决策边界?](#1. 什么是最好的决策边界?)
[2. 数学背后的逻辑](#2. 数学背后的逻辑)
[3. 一个简单的手算实例](#3. 一个简单的手算实例)
[4. 软间隔 (Soft Margin):容忍一点错误](#4. 软间隔 (Soft Margin):容忍一点错误)
[5. 核函数 (Kernel Trick):降维打击的逆向操作](#5. 核函数 (Kernel Trick):降维打击的逆向操作)
在机器学习的江湖里,支持向量机 (Support Vector Machine, SVM) 曾经是无可争议的"王者"。在深度学习爆发之前,它以坚实的数学基础和出色的分类效果统治着各种数据挖掘任务。
很多同学听到 SVM 会觉得它的数学推导很难,但其实它的核心思想非常简单直观。今天我们就剥开复杂的公式,看透 SVM 的本质。
1. 什么是最好的决策边界?
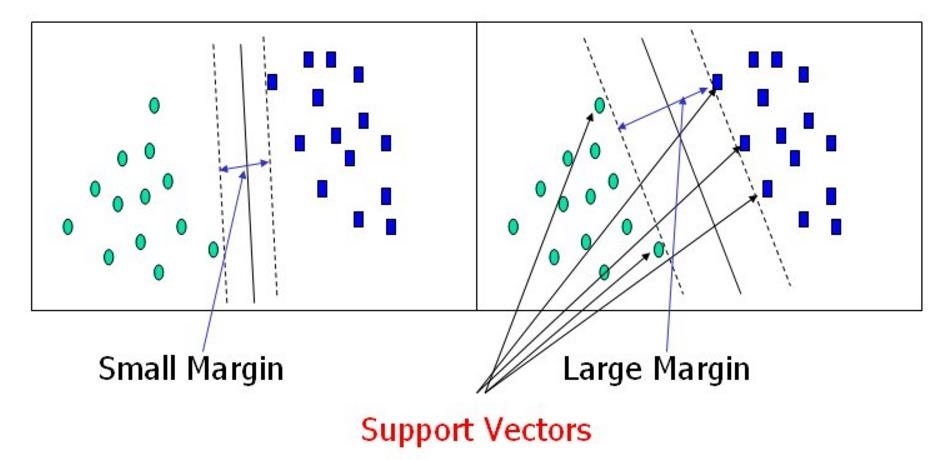
假设我们要把桌上的红豆和绿豆分开。我们当然可以画无数条线把它们隔开,但哪一条线才是最好的呢?
SVM 的答案是:离"雷区"最远的那条线。
-
决策边界:就是我们画的那条线。
-
雷区(Margin):边界两边的区域。
-
支持向量(Support Vectors) :那些离边界最近的点。它们就像是支撑起这个边界的柱子,只有这些点在真正决定边界的位置,其他的点(离得远的)其实并不重要。
我们希望这个"雷区"(Margin)越宽越好(Large Margin),因为路越宽,咱们的模型泛化能力越强,遇到新数据时越不容易出错。
2. 数学背后的逻辑
虽然我们不想深陷数学泥潭,但理解 SVM 是如何"算"出来的很有必要。
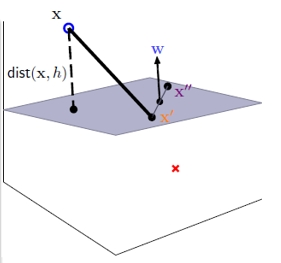
目标函数
我们的目标是找到一个平面(在二维是线,高维是超平面),由权重 和偏置
决定。
为了让 Margin 最大化,经过数学推导(距离公式的倒数),本质上我们是在求 的最小值。
约束条件
这不仅仅是求最小值,还得保证分得对。
对于每一个样本点,我们需要满足:
这就是说,所有的点都必须在"雷区"之外。
怎么解?拉格朗日乘子法
这是一个典型的"带约束的优化问题"。数学家们祭出了神器------拉格朗日乘子法。
通过引入拉格朗日乘子,我们将原始问题转化为对偶问题:
最终,我们只需要解出,就能得到最优的权重
和
。
3. 一个简单的手算实例
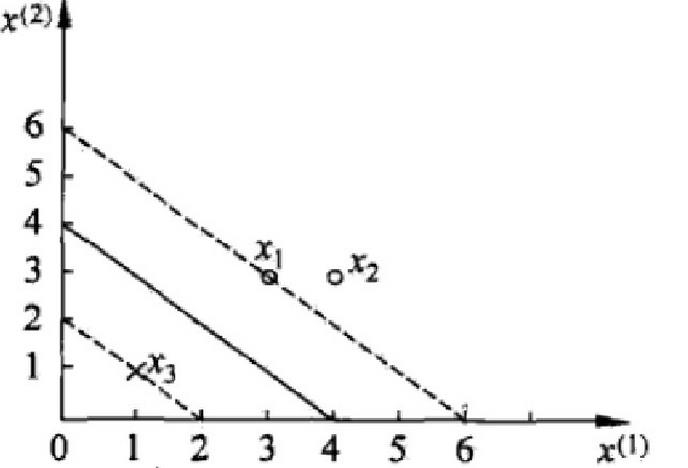
为了让你更具体地理解,我们来看一个只有3个点的案例:
-
正例 (+1) :
-
负例 (-1) :
我们把数据代入拉格朗日目标函数,最后解得:
-
-
(说明点
-
最终求得的决策边界方程为:
看,复杂的算法在小数据上其实就是解方程组。
4. 软间隔 (Soft Margin):容忍一点错误
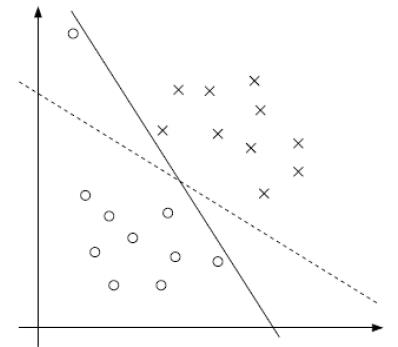
现实世界的数据往往是不完美的,可能混杂着噪声。如果非要画一条线把所有点都完美分开,这条线可能会变得非常奇怪(过拟合),甚至根本画不出来。
这时候,SVM 引入了"软间隔"的概念。
-
我们允许一些点跑进"雷区",甚至跑错阵营。
-
为此引入一个松弛因子
参数 C 的含义:
-
C 很大:意味着分类要求非常严格,容不得半点错误(容易过拟合)。
-
C 很小:意味着我们可以容忍更多的错误,追求更宽的边界(容易欠拟合)。
-
5. 核函数 (Kernel Trick):降维打击的逆向操作
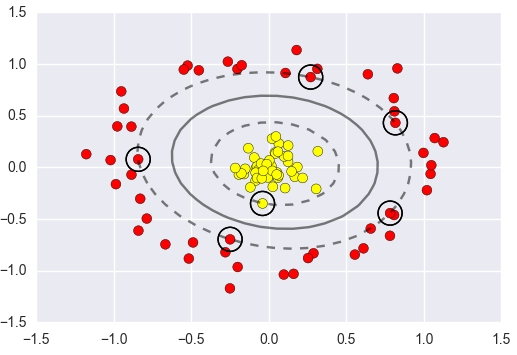
如果数据根本就不是线性的(比如一堆红豆围着一堆绿豆,呈同心圆状),画直线怎么分?
SVM 的绝招是:升维。
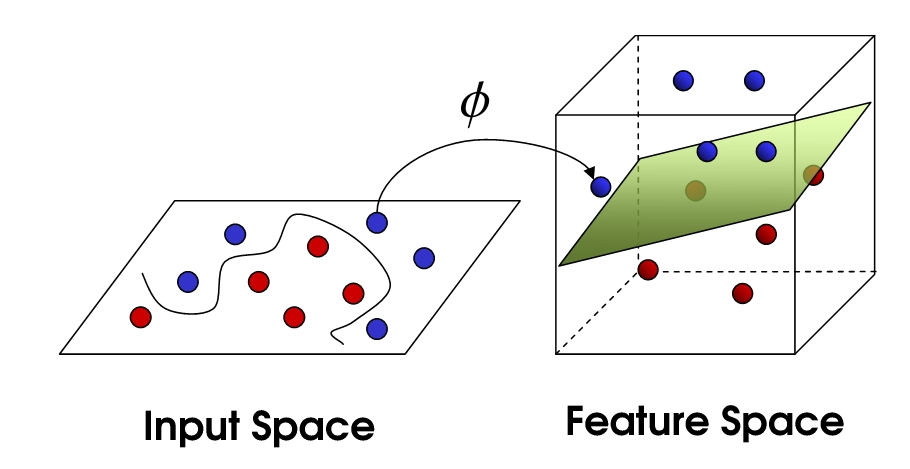
在二维平面分不开,我就把你映射到三维空间去!在更高维度,原来的非线性问题往往就变成了线性问题。但是,直接计算高维映射(比如把 3维 映射到 9维)计算量太大了,甚至会爆炸。
这时候核函数 (Kernel Function) 登场了。
核函数的魔力:它不需要真正把数据映射到高维去计算,而是通过一个公式,在低维空间就能直接算出高维空间里的内积。
-
效果:和映射到高维一样。
-
计算量:和低维一样快。
最常用的核函数是高斯核函数 (RBF),它非常强大,可以将数据映射到无限维空间。
总结
支持向量机 (SVM) 的核心魅力在于:
-
最大间隔:追求最稳健的分类边界。
-
支持向量:只有少数关键点决定结果,计算效率高(预测时)。
-
核技巧:巧妙解决非线性分类问题。
虽然现在深度学习很火,但在小样本、非线性分类任务中,SVM 依然是一把极其锋利的宝剑。