学习1:c++
今日学习了数组 函数 指针三个基础板块
数组
在学习数组时学习了一维数组 二维数组,其中包含例题
例题1:统计总成绩
例题2:冒泡排序
算法题的基础,学会二重循环
例题3:交换排序swap
例题4:数组逆置
此处是重点,可着重掌握,包括链表逆置方法也可以扩展学习
例题5:五只小猪称体重
相当于使用max函数
//int zongchengji() {
// //统计每个人的总和分数
//
// int scores[3][3] =
// {
// {100,100,100},
// {90,50,100},
// {60,70,80},
// };
// string names[3] = {"张三", "李四", "王五"};
//
// for (int i = 0; i < 3; i++)
// {
// int sum = 0;
// for (int j = 0; j < 3; j++) {
// sum += scores[i][j];
// //cout << scores[i][j] << " ";
// }
// cout << names[i] << "个人的总分为: " << sum << endl;
// }
//
//
//}
//int erweishuzujichu() {
// //二维数组
// int arr[2][3] = { {1,2,3}, {4,5,6} };
// //查看占用空间大小
// cout << "二维数组元素占用空间大小为:" << sizeof(arr) << endl;
// cout << "二维数组第一行占用空间大小为:" << sizeof(arr[0]) << endl;
// cout << "二维数组第一个数据占用空间大小为:" << sizeof(arr[0][0]) << endl;
//
// cout << "二维数组行数为:" << sizeof(arr) / sizeof(arr[0]) << endl;
// cout << "二维数组列数为:" << sizeof(arr[0]) / sizeof(arr[0][0]) << endl;
//
//
//
//}
//int maopaopaixu() {
// int arr[9] = { 4,2,8,0,5,7,1,3,9 };
//
// cout << "排序前:" << endl;
// for (int i = 0; i < 9; i++)
// {
// cout << arr[i] << endl;
// }
//
// //总共排序轮数为 元素个数-1
// for (int i = 0; i < 9-1; i++)
// {
// //内层循环对比 次数= 元素个数 - 当前轮数 -1
// for (int j = 0; j < 9-i-1; j++)
// {
// //如果第一个数字比第二个数字大,交换俩个数字
// if (arr[j] > arr[j + 1]){
// swap(arr[j], arr[j + 1]);
// }
//
// }
// }
//
// cout << "排序后:" << endl;
// for (int i = 0; i < 9; i++)
// {
// cout << arr[i] << endl;
// }
//}
//
//void swap(int& a, int& b) {
// int temp = a;
// a = b;
// b = temp;
//}
//int reverse() {
// //数组逆置
// int arr[5] = { 4,2,8,0,5 };
//
// cout << "数组元素逆置前:" << endl;
// for (int i = 0; i < 5; i++)
// {
// cout << arr[i] << endl;
// }
//
// int start = 0; //找到起始元素下标
// int end = sizeof(arr) / sizeof(arr[0]) - 1; //找到末尾元素下标
//
// //需要创建临时变量保存第一个数据
// while (start<end)
// {
// int temp = arr[start];
// arr[start] = arr[end];
// arr[end] = temp;
// //下标更新
// start++;
// end--;
// }
// //打印逆置后的数组
// cout << "数组元素逆置后:" << endl;
// for (int i = 0; i < 5; i++)
// {
// cout << arr[i] << endl;
// }
//}
//int findmaxheavy() {
// //五只小猪称体重
// int arr[5] = { 300,350,200,400,250 };
// int max = 0;
// for (int i = 0; i < 5; i++)
// {
// if (max < arr[i]) {
// max = arr[i];
// }
// }
// cout<< "最重的小猪体重为:" << max << endl;
//}
//int shuzujibenyongfa() {
//
// //通过数组名统计整个数组占用内存大小
// int arr[5] = { 1, 2, 3, 4, 5 };
// cout << "整个数组空间占用内存空间为:" << sizeof(arr) << endl;
// cout << "每个元素空间占用内存空间为:" << sizeof(arr[0]) << endl;
// cout << "数组中元素个数为:" << sizeof(arr)/sizeof(arr[0]) << endl;
//
// //通过数组名查看数组首地址
// cout << "数组首地址为" << (int)arr << endl;
// cout << "数组中第二个元素地址为:" << (int)&arr[1] << endl;
//}函数
重点学习了函数的定义 声明 调用和分文件编写
其中需要着重注意的如下
函数的声明
作用: 告诉编译器函数名称及如何调用函数。函数的实际主体可以单独定义。
- 函数的声明可以多次 ,但是函数的定义只能有一次
示例:
//声明可以多次,定义只能一次
//声明
int max(int a, int b);
int max(int a, int b);
//定义
int max(int a, int b)
{
return a > b ? a : b;
}
int main() {
int a = 100;
int b = 200;
cout << max(a, b) << endl;
system("pause");
return 0;
}函数的分文件编写
**作用:**让代码结构更加清晰
函数分文件编写一般有4个步骤
- 创建后缀名为.h的头文件
- 创建后缀名为.cpp的源文件
- 在头文件中写函数的声明
- 在源文件中写函数的定义
示例:
//swap.h文件
#include<iostream>
using namespace std;
//实现两个数字交换的函数声明
void swap(int a, int b);
//swap.cpp文件
#include "swap.h"
void swap(int a, int b)
{
int temp = a;
a = b;
b = temp;
cout << "a = " << a << endl;
cout << "b = " << b << endl;
}
//main函数文件
#include "swap.h"
int main() {
int a = 100;
int b = 200;
swap(a, b);
system("pause");
return 0;
}如下所示
在头文件中使用声明,在源文件中使用定义
同时在源文件中引用是需要#include xxx.h
指针
学习了指针的基本概念 定义 所占内存空间 const修饰指针 指针和数组 指针和函数 指针,数组和函数
其实重要的点如下
const修饰指针
const修饰指针有三种情况
- const修饰指针 --- 常量指针
- const修饰常量 --- 指针常量
- const即修饰指针,又修饰常量
示例:
int main() {
int a = 10;
int b = 10;
//const修饰的是指针,指针指向可以改,指针指向的值不可以更改
const int * p1 = &a;
p1 = &b; //正确
//*p1 = 100; 报错
//const修饰的是常量,指针指向不可以改,指针指向的值可以更改
int * const p2 = &a;
//p2 = &b; //错误
*p2 = 100; //正确
//const既修饰指针又修饰常量
const int * const p3 = &a;
//p3 = &b; //错误
//*p3 = 100; //错误
system("pause");
return 0;
}技巧:看const右侧紧跟着的是指针还是常量, 是指针就是常量指针,是常量就是指针常量
指针、数组、函数
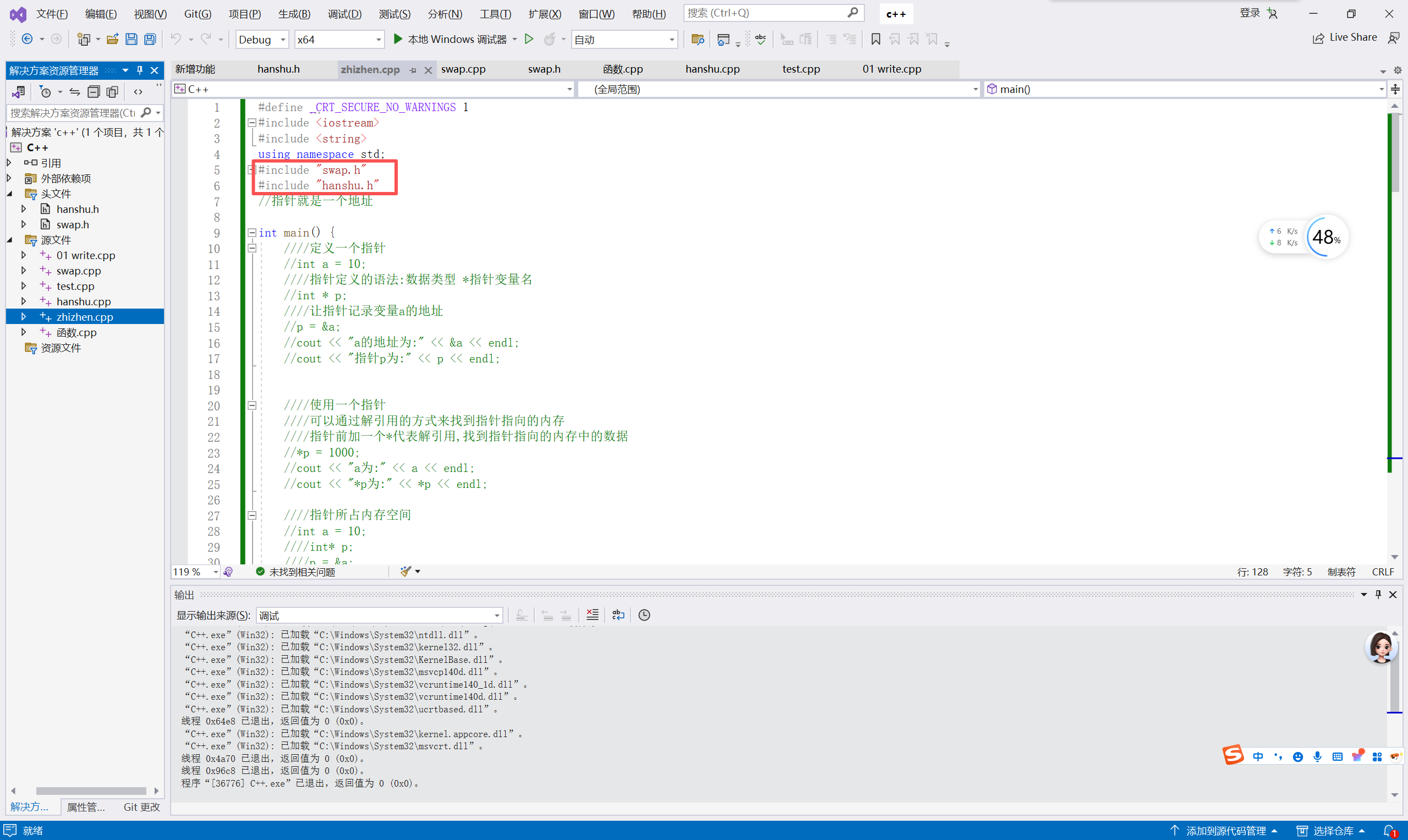
**案例描述:**封装一个函数,利用冒泡排序,实现对整型数组的升序排序
例如数组:int arr10 = { 4,3,6,9,1,2,10,8,7,5 };
示例:
//冒泡排序函数
void bubbleSort(int * arr, int len) //int * arr 也可以写为int arr[]
{
for (int i = 0; i < len - 1; i++)
{
for (int j = 0; j < len - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
//打印数组函数
void printArray(int arr[], int len)
{
for (int i = 0; i < len; i++)
{
cout << arr[i] << endl;
}
}
int main() {
int arr[10] = { 4,3,6,9,1,2,10,8,7,5 };
int len = sizeof(arr) / sizeof(int);
bubbleSort(arr, len);
printArray(arr, len);
system("pause");
return 0;
}总结:当数组名传入到函数作为参数时,被退化为指向首元素的指针
代码编程题
27. 移除元素 - 力扣(LeetCode)
同时观看了代码随想录第二期视频:https://www.bilibili.com/video/BV12A4y1Z7LP?t=0.1
在本期视频中学习了如何删除数组元素,由于数组是一个连续的集合,本质上删除元素就是由后面的元素 替换被删除的元素即可,同时做了力扣27题:27. 移除元素 - 力扣(LeetCode)
代码如下
class Solution {
public:
int removeElement(vector<int>& nums, int val) {
int slow=0;
for(int fast = 0; fast<nums.size();fast++){
if(nums[fast] != val){
nums[slow++] = nums[fast];
}
}
return slow;
}
};其中着重看for循环中的内容,理解替换的含义
160. 相交链表 - 力扣(LeetCode)
做了hot第一题:160. 相交链表 - 力扣(LeetCode)
该题在408中有涉及,本人第一个思路是俩个指针分别指向俩个链表首指针,比较指针长度,当lenA>lenB时候,pA = pA ->next;同理,当lenA= lenB时候,如果pA ->val != pB -> val则同时向后移动,但实行起来时候困难重重,不得不借助豆包写出如下代码
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
// 边界判断:任意一个链表为空,直接返回空(无相交节点)
if(headA == NULL || headB == NULL) return NULL;
// 1. 定义两个指针,初始指向两个链表的头节点(修正语法错误)
ListNode* pa = headA;
ListNode* pb = headB;
// 2. 计算链表A的总长度 lenA
int lenA = 0;
while(pa != NULL){
lenA++;
pa = pa->next;
}
// 3. 计算链表B的总长度 lenB
int lenB = 0;
while(pb != NULL){
lenB++;
pb = pb->next;
}
// 4. 重置指针到表头,准备对齐长度
pa = headA;
pb = headB;
// 5. 让长链表的指针先走「长度差」步,对齐两个指针的起点(核心修正)
int gap = abs(lenA - lenB);
if(lenA > lenB){
while(gap--){
pa = pa->next;
}
}else{
while(gap--){
pb = pb->next;
}
}
// 6. 同步遍历两个链表,找相交节点(核心修正:判断指针相等,而非值相等)
while(pa != NULL && pb != NULL){
if(pa == pb){ // 找到相交节点,直接返回
return pa;
}
pa = pa->next;
pb = pb->next;
}
// 7. 遍历结束都没找到,说明无相交节点,返回空
return NULL;
}
};其中遇到的经典错误可以查看如下对话https://www.doubao.com/thread/w626affc0e961d716
同时使用评论区较为简单方法
if(headA == NULL || headB == NULL) return NULL;
ListNode* pA = headA;
ListNode* pB = headB;
while(pA != pB) {
pA = pA == NULL ? headB : pA->next;
pB = pB == NULL ? headA : pB->next;
}
return pA;
}其中重点部分为三目运算符中的内容,详细解释如下
一、先补基础:C++ 三目运算符 ?: 完整语法规则
这段代码的核心就是两个三目运算符 ,它是你理解这段逻辑的前提,三目运算符也叫「三元表达式」,是 if-else 条件判断的极简写法,语法规则非常固定:
✅ 标准格式
条件表达式 ? 表达式A : 表达式B;✅ 执行逻辑(必须记住)
-
先判断「条件表达式」的结果是
true还是false; -
如果条件为
true→ 整个三目表达式的结果 = 表达式 A; -
如果条件为
false→ 整个三目表达式的结果 = 表达式 B; -
三目运算符的优先级低于赋值号
=,所以你的代码里是「先算三目表达式的结果,再赋值给左边的变量」。
二、逐行解析:你的两行三目运算符代码 「直译 + 执行逻辑」
先把核心代码再贴一遍,方便对照:
while (pa != pb) {
pa = pa == nullptr ? headB : pa->next;
pb = pb == nullptr ? headA : pb->next;
}已知前提:pa、pb 都是 ListNode* 类型的指针变量 ,headA是链表 A 的头指针,headB是链表 B 的头指针,pa->next表示指针pa指向的节点的下一个节点,pb->next同理。
✅ 第一行:pa = pa == nullptr ? headB : pa->next;
✔️ 直译(人话版本)
给指针变量
pa重新赋值:如果pa这个指针已经走到链表末尾(变成空指针)了 → 就把pa指向「链表 B 的头节点headB」;如果pa这个指针还没走到末尾(不是空指针) → 就把pa往后移动一步,指向当前节点的下一个节点。
✔️ 拆解成条件判断
// 这行 if-else 等价于上面的三目运算符,逻辑完全一样,只是写法更啰嗦
if (pa == nullptr) {
pa = headB;
} else {
pa = pa->next;
}✅ 第二行:pb = pb == nullptr ? headA : pb->next;
✔️ 直译(人话版本)
给指针变量
pb重新赋值:如果pb这个指针已经走到链表末尾(变成空指针)了 → 就把pb指向「链表 A 的头节点headA」;如果pb这个指针还没走到末尾(不是空指针) → 就把pb往后移动一步,指向当前节点的下一个节点。
✔️ 拆解成条件判断
// 等价的if-else写法,逻辑完全一致
if (pb == nullptr) {
pb = headA;
} else {
pb = pb->next;
}三、✅ 整个 while + 三目 完整执行规则(重中之重)
把三目和外层的while(pa != pb)结合起来,这段代码的完整执行逻辑就是:
初始化:
pa指向链表 A 的头节点,pb指向链表 B 的头节点;进入循环的条件:
pa和pb指向的不是同一个节点;循环内同步操作两个指针:
pa走到底了,就「瞬移」到链表 B 的开头继续走;没走到底,就正常往后走一步;
pb走到底了,就「瞬移」到链表 A 的开头继续走;没走到底,就正常往后走一步;什么时候退出循环? → 当
pa == pb时,也就是两个指针指向了同一个节点;退出循环后,直接返回
pa(或pb)即可,这就是我们要找的「相交节点」。
补充:pa == pb 成立的两种情况(完美处理所有边界)
这个逻辑的强大之处在于,能自动处理「链表相交」和「链表不相交」两种场景,不会崩溃、不用额外判断,这也是它能成为最优解的核心原因:
-
情况 1:两个链表有相交节点 →
pa和pb会在相交节点的位置 满足pa == pb,退出循环,返回该节点 ✔️; -
情况 2:两个链表没有相交节点 →
pa和pb会一直走,最终都走到空指针(nullptr) ,此时pa == pb == nullptr,退出循环,返回nullptr✔️。
四、✅ 为什么这么写就能精准找到「相交节点」?(底层核心原理,彻底懂透)
你之前自己写代码的时候,思路是「先计算两个链表的长度差,让长链表的指针先走几步,对齐长度后再同步遍历」,这个思路是正确的 ,而这段双指针 + 三目运算符的代码,本质上是 「用代码逻辑自动抵消长度差,省去手动计算长度的步骤」,二者的底层原理完全一致,只是实现方式不同。
我用通俗的语言解释这个核心原理,举个例子你就秒懂:假设:链表 A 的长度是 lenA,链表 B 的长度是 lenB
-
pa指针的行走路径:先走完链表 A 的lenA个节点 → 走到头后瞬移到链表 B 开头 → 再走lenB个节点;总路程 =lenA + lenB -
pb指针的行走路径:先走完链表 B 的lenB个节点 → 走到头后瞬移到链表 A 开头 → 再走lenA个节点;总路程 =lenB + lenA
核心结论:两个指针的「总行走路程完全相等」!不管两个链表的长度差是多少,只要有相交节点,两个指针一定会在「相交节点」相遇;如果没有相交节点,两个指针会同时走到末尾的空指针,完美对齐。
举个通俗的例子:你和你的朋友,从两条不同长度的路出发去同一个目的地,你走到头就换对方的路走,对方走到头就换你的路走,你们的速度一样,总路程一样,最终一定会在目的地相遇(或者同时走到终点)。
五、✅ 等价代码:把整段逻辑改成「纯 if-else」写法(新手友好,零理解难度)
如果你现在对三目运算符还是觉得别扭,没关系,我把这段核心逻辑完整转换成等价的 if-else 写法,代码功能、执行效率、结果完全一致,只是写法更啰嗦,但对新手更友好,你可以对照着看,彻底理解:
// 等价的纯if-else写法,和你的三目运算符版本完全一样
while (pa != pb) {
// 处理pa指针
if (pa == nullptr) {
pa = headB;
} else {
pa = pa->next;
}
// 处理pb指针
if (pb == nullptr) {
pb = headA;
} else {
pb = pb->next;
}
}六、✅ 补充 2 个关键注意点(避坑 + 语法巩固)
- 为什么指针访问成员用
->而不是.?
你之前的代码里犯过这个语法错误,这里再巩固一次,永远记住:
-
pa是ListNode*类型 → 指针类型 → 访问成员(val/next)必须用->,比如pa->next; -
如果是
ListNode node这种实体对象 → 访问成员才用.,比如node.next。
- 这个解法的效率有多高?(刷题必看)
-
时间复杂度:
O(lenA + lenB)→ 每个指针最多走「两个链表总长度」的步数,只遍历一次; -
空间复杂度:
O(1)→ 只定义了两个指针变量,没有开辟任何额外的内存空间;这是这道题的 最优解,没有比这个更好的解法了,面试写这个代码,面试官一定会认可👍。
✅ 总结(精华提炼,直接记)
-
三目运算符
条件?A:B→ 条件为真执行 A,为假执行 B,是if-else的简写; -
核心逻辑一句话:谁走到头,谁就瞬移到另一个链表的头节点,直到两个指针相遇;
-
相遇的结果只有两种:要么是「相交节点」,要么是「空指针(无相交)」;
-
这个写法的精髓:不用手动算链表长度,自动抵消长度差,代码极简、效率拉满。