目录:
-
- [一、LlamaIndex 简介](#一、LlamaIndex 简介)
-
- [1.1 什么是 LlamaIndex](#1.1 什么是 LlamaIndex)
- [1.2 为什么需要 LlamaIndex](#1.2 为什么需要 LlamaIndex)
- [二、LlamaIndex 核心功能](#二、LlamaIndex 核心功能)
-
- [2.1 数据连接器(Data Connectors)](#2.1 数据连接器(Data Connectors))
- [2.2 数据索引(Data Indexes)](#2.2 数据索引(Data Indexes))
- [2.3 引擎(Engines)](#2.3 引擎(Engines))
- [2.4 数据代理(Data Agents)](#2.4 数据代理(Data Agents))
- [2.5 应用集成(Application Integrations)](#2.5 应用集成(Application Integrations))
- 三、部署安装
-
- [3.1 安装](#3.1 安装)
- [3.2 基本使用示例](#3.2 基本使用示例)
- 四、个性化配置
-
- [1. 自定义分块(Chunking)](#1. 自定义分块(Chunking))
- [2. 检索策略调整](#2. 检索策略调整)
- [3. 提示词模板定制](#3. 提示词模板定制)
- [五、数据抽象:Document 和 Nodes](#五、数据抽象:Document 和 Nodes)
-
- [1. Document](#1. Document)
- [2. Node](#2. Node)
- [3. Document 与 Nodes 的关系](#3. Document 与 Nodes 的关系)
一、LlamaIndex 简介
1.1 什么是 LlamaIndex
LlamaIndex 是一个用于 LLM(大型语言模型)应用程序的数据框架,用于注入、结构化并访问私有或特定领域数据。它提供了一套完整的工具链,帮助开发者构建基于 LLM 的应用。
1.2 为什么需要 LlamaIndex
在本质上,LLM(如 GPT)为人类和推断出的数据提供了基于自然语言的交互接口。广泛可用的大模型通常在大量公开可用的数据上进行预训练,包括来自维基百科、邮件列表、书籍和源代码等。
然而,构建在 LLM 模型之上的应用程序通常需要使用私有或特定领域数据来增强这些模型。不幸的是,这些数据可能分布在不同的应用程序和数据存储中:
-
存在于 API 之后
-
保存在 SQL 数据库中
-
存储在 PDF 文件中
-
分散在幻灯片和文档中
LlamaIndex 就是为了解决这些问题而设计的。
二、LlamaIndex 核心功能
LlamaIndex 提供五大核心工具:
2.1 数据连接器(Data Connectors)
数据连接器支持将各种数据源注入到 LlamaIndex 中:
-
API 接口:连接外部 API 获取数据
-
文档文件:PDF、Word、Markdown 等
-
数据库:SQL、NoSQL 数据库
-
网页内容:爬取网页数据
-
其他格式:CSV、JSON、XML 等
2.2 数据索引(Data Indexes)
用于将数据转换为 LLM 容易理解和消费的数据格式。支持多种索引类型:
- 向量索引(Vector Store Index):将文档转换为向量进行相似度检索
- 摘要索引(Summary Index):生成文档摘要
- 树形索引(Tree Index):构建层次化的文档结构
- 关键词索引(Keyword Table Index):基于关键词的快速检索
2.3 引擎(Engines)
提供查询、对话等主要功能:
- 查询引擎(Query Engine):执行自然语言查询
- 对话引擎(Chat Engine):支持多轮对话
- 数据增强:结合外部数据增强回答质量
2.4 数据代理(Data Agents)
智能代理可以自主决策和执行任务:
- 自动选择合适的工具
- 链式调用多个操作
- 处理复杂的多步骤任务
2.5 应用集成(Application Integrations)
对接生态中的其他框架和工具:
- LangChain:与 LangChain 无缝集成
- Flask/FastAPI:快速构建 Web 服务
- ChatGPT:与 OpenAI API 集成
- Streamlit:构建交互式应用界面
三、部署安装
使用 pip 安装 LlamaIndex:
3.1 安装
bash
pip install llama-index3.2 基本使用示例
RAG 工作流程:
- 数据索引:将文档(PDF、网页等)处理为可检索的结构化数据(Document → Nodes)。
- 检索:根据用户查询,从索引中检索最相关的文本片段(Nodes)。
- 生成:将检索结果作为上下文,输入到大模型中生成最终回答。
python
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# 加载文档
documents = SimpleDirectoryReader('data').load_data()
# 构建索引
index = VectorStoreIndex.from_documents(documents)
# 创建查询引擎
query_engine = index.as_query_engine()
# 执行查询
response = query_engine.query("文档的主要内容是什么?")
print(response)四、个性化配置
1. 自定义分块(Chunking)
通过 NodeParser 控制文档如何分割为 Nodes(如分块大小、重叠文本):
python
from llama_index.node_parser import SimpleNodeParser
parser = SimpleNodeParser.from_defaults(
chunk_size=512, # 每块 token 数
chunk_overlap=20 # 块间重叠文本
)
nodes = parser.get_nodes_from_documents(documents)
index = VectorStoreIndex(nodes)2. 检索策略调整
- 相似度阈值:过滤低相关性结果。
- 混合检索:结合关键词和向量检索。
python
from llama_index.retrievers import VectorIndexRetriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=3, # 返回 Top 3 结果
vector_store_query_mode="hybrid" # 混合检索
)3. 提示词模板定制
修改默认提示词以适应特定任务:
python
from llama_index.prompts import PromptTemplate
qa_prompt = PromptTemplate("""
请根据以下上下文回答:
{context_str}
问题:{query_str}
答案:
""")
query_engine.update_prompts({"response_synthesizer:text_qa_template": qa_prompt})五、数据抽象:Document 和 Nodes
1. Document
- 原始数据载体:表示一个完整文档(如 PDF、网页、数据库记录)。
- 关键属性:text(内容)、metadata(来源、作者等)。
python
from llama_index import Document
doc = Document(
text="LlamaIndex 是一个高效的 RAG 框架...",
metadata={"source": "知乎", "author": "张三"}
)2. Node
文档的语义分块:将 Document 分割为多个 Node,每个 Node 包含:
-
text:分段文本。
-
metadata:继承自 Document 或新增字段。
-
relationships:与其他 Nodes 的关系(如父子节点)。
python
from llama_index.schema import TextNode
node = TextNode(
text="RAG 结合了检索和生成技术...",
metadata={"section": "核心概念"},
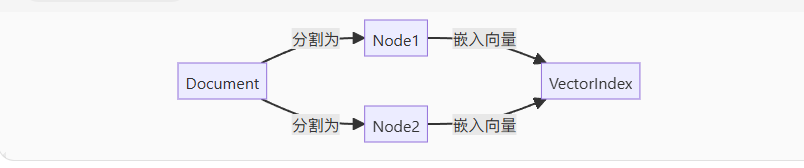
)3. Document 与 Nodes 的关系
- 一对多:一个 Document 可拆分为多个 Nodes。
- 索引构建:Nodes 是检索的最小单元,直接影响 RAG 效果。
官方网址:
https://developers.llamaindex.ai/python/framework/#getting-started