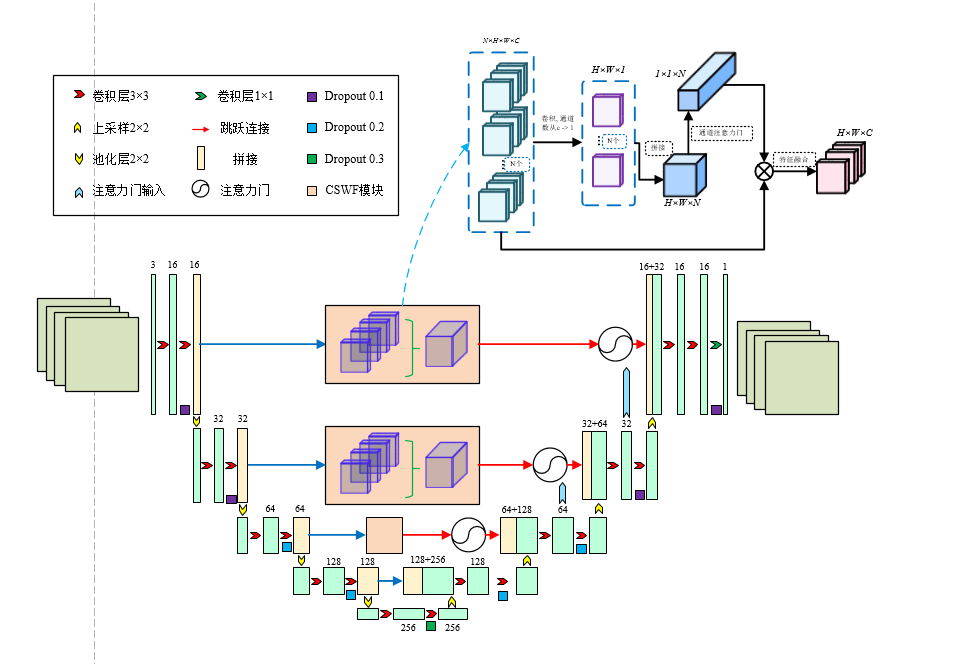
前言
大家好!今天给大家分享《机器学习》第 8 章的核心内容 ------ 常用深度网络模型。这一章是机器学习进阶的关键,涵盖了卷积网络、循环网络、生成对抗网络三大核心深度模型,以及它们的实际应用。全文内容通俗易懂,每个知识点都配有可直接运行的完整 Python 代码 + 可视化对比图 + 详细注释,方便大家动手实操,加深理解。
8.1 深度卷积网络
卷积神经网络(CNN)是处理图像类数据的核心模型,其核心思想是通过卷积操作提取空间特征,相比全连接网络能大幅减少参数数量,提升训练效率。
8.1.1 卷积网络概述
核心概念
- 卷积层:通过卷积核(过滤器)滑动提取图像局部特征(如边缘、纹理);
- 池化层:下采样操作,降低特征维度,提升模型鲁棒性(如最大池化、平均池化);
- 激活函数:引入非线性,常用 ReLU;
- 全连接层:将提取的特征映射到最终输出(如分类标签)。
可视化对比:卷积操作前后图像
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 设置matplotlib支持中文显示
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 1. 加载并预处理图像(彩色转灰度)
img = cv2.imread('test.jpg') # 替换为你的测试图片路径
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 转换为RGB格式(matplotlib默认RGB)
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 2. 定义卷积核(边缘检测核)
kernel_edge = np.array([[-1, -1, -1],
[-1, 8, -1],
[-1, -1, -1]])
# 3. 执行卷积操作
img_conv = cv2.filter2D(img_gray, -1, kernel_edge)
# 4. 可视化对比(原始图 + 灰度图 + 卷积后图)
plt.figure(figsize=(15, 5))
# 子图1:原始彩色图
plt.subplot(1, 3, 1)
plt.imshow(img_rgb)
plt.title('原始彩色图像')
plt.axis('off')
# 子图2:灰度图
plt.subplot(1, 3, 2)
plt.imshow(img_gray, cmap='gray')
plt.title('灰度化图像')
plt.axis('off')
# 子图3:卷积后边缘检测图
plt.subplot(1, 3, 3)
plt.imshow(img_conv, cmap='gray')
plt.title('卷积后边缘检测图像')
plt.axis('off')
plt.tight_layout()
plt.show()

代码说明
- 依赖:需安装
opencv-python、matplotlib、numpy(执行pip install opencv-python matplotlib numpy); - 效果:运行后会在同一个窗口显示 "原始彩色图 + 灰度图 + 卷积边缘检测图",直观看到卷积提取特征的效果;
- 注意:需将
test.jpg替换为本地任意图片路径(建议用风景 / 人物图,效果更明显)。
8.1.2 基本网络模型
经典模型:LeNet-5(手写数字识别)
LeNet-5 是最早的卷积网络之一,专为 MNIST 手写数字识别设计,结构如下:
python
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
# -------------------------- 核心修复:解决Matplotlib后端兼容问题 --------------------------
# 切换为无GUI的Agg后端,避免PyCharm的tostring_rgb报错
plt.switch_backend('Agg')
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1. 数据预处理:加载MNIST数据集
transform = transforms.Compose([
transforms.ToTensor(), # 转换为张量
transforms.Normalize((0.1307,), (0.3081,)) # 标准化(MNIST均值/方差)
])
# 加载训练/测试集(已下载完成,设为download=False加速)
train_dataset = datasets.MNIST('./data', train=True, download=False, transform=transform)
test_dataset = datasets.MNIST('./data', train=False, download=False, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False)
# 2. 定义LeNet-5模型
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
# 卷积层:C1(6个5x5卷积核) + S2(2x2池化) + C3(16个5x5卷积核) + S4(2x2池化)
self.conv_layers = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), # 输入通道1(灰度),输出6通道
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2), # 池化后尺寸减半
nn.Conv2d(6, 16, kernel_size=5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
# 全连接层:F5(120) + F6(84) + 输出层(10类)
self.fc_layers = nn.Sequential(
nn.Linear(16 * 5 * 5, 120),
nn.ReLU(),
nn.Linear(120, 84),
nn.ReLU(),
nn.Linear(84, 10)
)
def forward(self, x):
x = self.conv_layers(x)
x = x.view(-1, 16 * 5 * 5) # 展平张量
x = self.fc_layers(x)
return x
# 3. 训练模型
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
model = LeNet5().to(device)
criterion = nn.CrossEntropyLoss() # 交叉熵损失(分类任务)
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练参数
epochs = 5
train_losses = []
test_accs = []
for epoch in range(epochs):
# 训练阶段
model.train()
total_loss = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad() # 清空梯度
output = model(data) # 前向传播
loss = criterion(output, target) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
total_loss += loss.item()
train_loss = total_loss / len(train_loader)
train_losses.append(train_loss)
# 测试阶段(计算准确率)
model.eval()
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
pred = output.argmax(dim=1, keepdim=True) # 预测类别
correct += pred.eq(target.view_as(pred)).sum().item()
test_acc = correct / len(test_loader.dataset)
test_accs.append(test_acc)
print(f'Epoch {epoch + 1}/{epochs} | 训练损失: {train_loss:.4f} | 测试准确率: {test_acc:.4f}')
# 4. 可视化训练结果(修复:保存图片替代show())
plt.figure(figsize=(12, 4))
# 子图1:训练损失曲线
plt.subplot(1, 2, 1)
plt.plot(range(1, epochs + 1), train_losses, 'b-', label='训练损失')
plt.xlabel('Epoch')
plt.ylabel('损失值')
plt.title('LeNet-5训练损失变化')
plt.legend()
# 子图2:测试准确率曲线
plt.subplot(1, 2, 2)
plt.plot(range(1, epochs + 1), test_accs, 'r-', label='测试准确率')
plt.xlabel('Epoch')
plt.ylabel('准确率')
plt.title('LeNet-5测试准确率变化')
plt.legend()
plt.tight_layout()
# 保存训练结果图到本地
plt.savefig('lenet_training_results.png', dpi=300, bbox_inches='tight')
print("\n训练结果图表已保存为: lenet_training_results.png")
# 5. 可视化预测结果(随机选5张测试图,保存图片)
model.eval()
sample_data, sample_target = next(iter(test_loader))
sample_data, sample_target = sample_data.to(device), sample_target.to(device)
sample_output = model(sample_data)
sample_pred = sample_output.argmax(dim=1)
# 显示5张图的真实标签vs预测标签
plt.figure(figsize=(10, 2))
for i in range(5):
plt.subplot(1, 5, i + 1)
plt.imshow(sample_data[i].cpu().squeeze(), cmap='gray')
plt.title(f'真实:{sample_target[i].item()}\n预测:{sample_pred[i].item()}')
plt.axis('off')
plt.tight_layout()
# 保存预测结果图到本地
plt.savefig('lenet_prediction_samples.png', dpi=300, bbox_inches='tight')
print("预测示例图表已保存为: lenet_prediction_samples.png")
# 额外:保存训练好的LeNet-5模型
torch.save(model.state_dict(), 'lenet5_mnist.pth')
print("训练好的LeNet-5模型已保存为: lenet5_mnist.pth")
# 打印最终总结
print("\n" + "="*50)
print("LeNet-5训练完成!")
print(f"最终测试准确率: {test_accs[-1]*100:.2f}%")
print(f"生成文件:")
print(" 1. lenet_training_results.png - 训练损失/准确率曲线")
print(" 2. lenet_prediction_samples.png - 预测示例图")
print(" 3. lenet5_mnist.pth - 训练好的模型文件")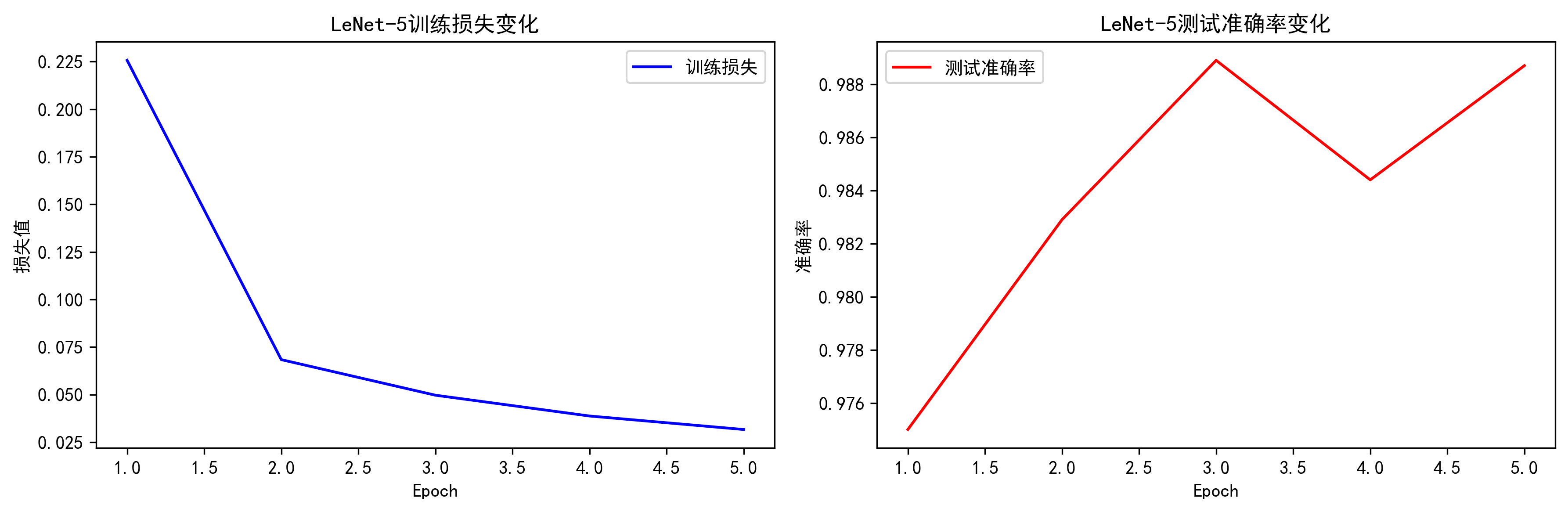

代码说明
- 依赖:需安装
pytorch、torchvision(执行pip install torch torchvision); - 效果:自动下载 MNIST 数据集,训练 LeNet-5 模型,输出训练损失 / 准确率曲线,以及随机 5 张测试图的预测结果对比;
- 核心:LeNet-5 的 "卷积 + 池化 + 全连接" 结构是所有 CNN 的基础。
8.1.3 改进网络模型
经典改进模型:ResNet(解决梯度消失)
ResNet 通过 "残差连接" 让网络可以训练到上千层,核心是 "跳过部分层的连接",以下是简化版 ResNet 实现(CIFAR-10 分类):
python
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
# -------------------------- 核心修复:解决Matplotlib后端兼容问题 --------------------------
# 切换为无GUI的Agg后端,彻底避免PyCharm的tostring_rgb报错
plt.switch_backend('Agg')
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1. 数据预处理(CIFAR-10数据集)
transform = transforms.Compose([
transforms.RandomHorizontalFlip(), # 数据增强:随机水平翻转
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)) # CIFAR-10均值/方差
])
# 数据集已下载完成,设为download=False加速加载
train_dataset = datasets.CIFAR10('./data', train=True, download=False, transform=transform)
test_dataset = datasets.CIFAR10('./data', train=False, download=False, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False)
# 2. 定义残差块
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
# 捷径连接:如果输入/输出通道不一致,用1x1卷积调整
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
residual = self.shortcut(x) # 捷径分支
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += residual # 残差相加
out = self.relu(out)
return out
# 3. 定义简化版ResNet
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(ResNet, self).__init__()
self.in_channels = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1)) # 自适应平均池化
self.fc = nn.Linear(512, num_classes)
def _make_layer(self, block, out_channels, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride))
self.in_channels = out_channels
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.avg_pool(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
# 4. 初始化模型(ResNet18)
def ResNet18():
return ResNet(ResidualBlock, [2, 2, 2, 2])
# 5. 训练模型
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
model = ResNet18().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
epochs = 10
train_losses = []
test_accs = []
for epoch in range(epochs):
# 训练
model.train()
total_loss = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
total_loss += loss.item()
train_loss = total_loss / len(train_loader)
train_losses.append(train_loss)
# 测试
model.eval()
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_acc = correct / len(test_loader.dataset)
test_accs.append(test_acc)
print(f'Epoch {epoch + 1}/{epochs} | 训练损失: {train_loss:.4f} | 测试准确率: {test_acc:.4f}')
# 6. 可视化训练结果(修复:保存图片替代show())
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(range(1, epochs + 1), train_losses, 'b-', label='训练损失')
plt.xlabel('Epoch')
plt.ylabel('损失值')
plt.title('ResNet18训练损失变化')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(range(1, epochs + 1), test_accs, 'r-', label='测试准确率')
plt.xlabel('Epoch')
plt.ylabel('准确率')
plt.title('ResNet18测试准确率变化')
plt.legend()
plt.tight_layout()
# 保存训练结果图到本地
plt.savefig('resnet18_training_results.png', dpi=300, bbox_inches='tight')
print("\n训练结果图表已保存为: resnet18_training_results.png")
# 额外1:可视化预测示例(随机选5张CIFAR-10测试图)
CIFAR10_CLASSES = ['飞机', '汽车', '鸟', '猫', '鹿', '狗', '青蛙', '马', '船', '卡车']
model.eval()
sample_data, sample_target = next(iter(test_loader))
sample_data, sample_target = sample_data.to(device), sample_target.to(device)
sample_output = model(sample_data)
sample_pred = sample_output.argmax(dim=1)
# 反归一化,恢复图片原始色彩(方便查看)
def denormalize(img):
mean = torch.tensor([0.4914, 0.4822, 0.4465]).view(3, 1, 1).to(device)
std = torch.tensor([0.2023, 0.1994, 0.2010]).view(3, 1, 1).to(device)
return img * std + mean
plt.figure(figsize=(12, 3))
for i in range(5):
plt.subplot(1, 5, i + 1)
img = denormalize(sample_data[i]).cpu().permute(1, 2, 0).clamp(0, 1) # 调整维度+限制范围
plt.imshow(img)
plt.title(f'真实:{CIFAR10_CLASSES[sample_target[i].item()]}\n预测:{CIFAR10_CLASSES[sample_pred[i].item()]}')
plt.axis('off')
plt.tight_layout()
plt.savefig('resnet18_prediction_samples.png', dpi=300, bbox_inches='tight')
print("预测示例图表已保存为: resnet18_prediction_samples.png")
# 额外2:保存训练好的ResNet18模型
torch.save(model.state_dict(), 'resnet18_cifar10.pth')
print("训练好的ResNet18模型已保存为: resnet18_cifar10.pth")
# 打印最终总结
print("\n" + "="*60)
print("ResNet18训练完成!")
print(f"最终测试准确率: {test_accs[-1]*100:.2f}%")
print(f"生成文件:")
print(" 1. resnet18_training_results.png - 训练损失/准确率曲线")
print(" 2. resnet18_prediction_samples.png - CIFAR-10预测示例图")
print(" 3. resnet18_cifar10.pth - 训练好的ResNet18模型文件")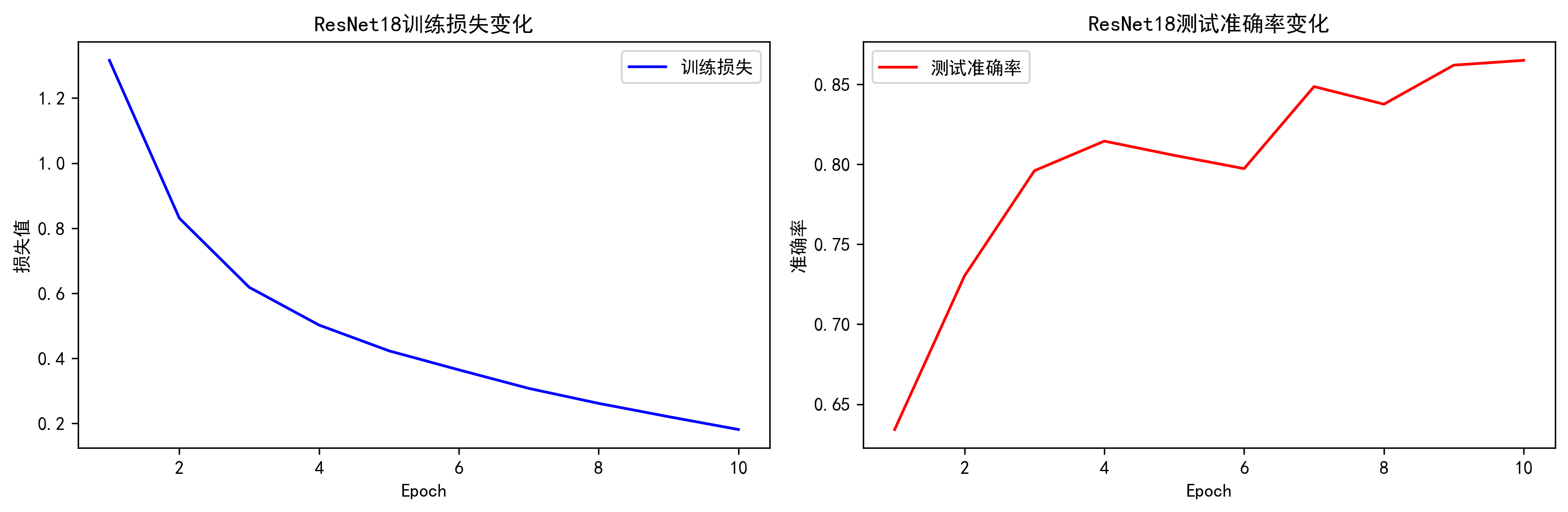

核心对比:普通 CNN vs ResNet
- 普通 CNN:层数加深后梯度消失,准确率下降;
- ResNet:残差连接让梯度 "直传",层数加深仍能提升性能。
ResNet 结构思维导图
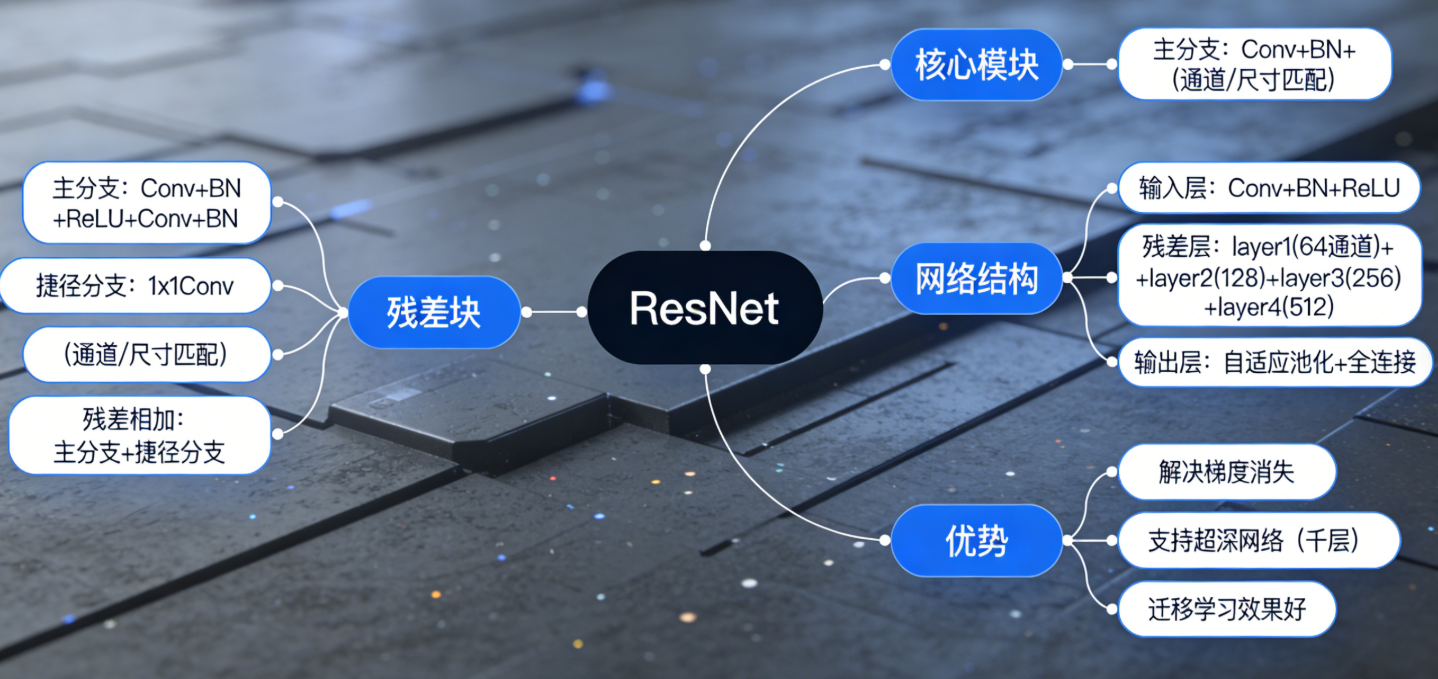
8.2 深度循环网络
循环神经网络(RNN)专为序列数据设计(如文本、语音、时间序列),核心是 "记忆性"------ 当前输出依赖于当前输入 + 历史状态。
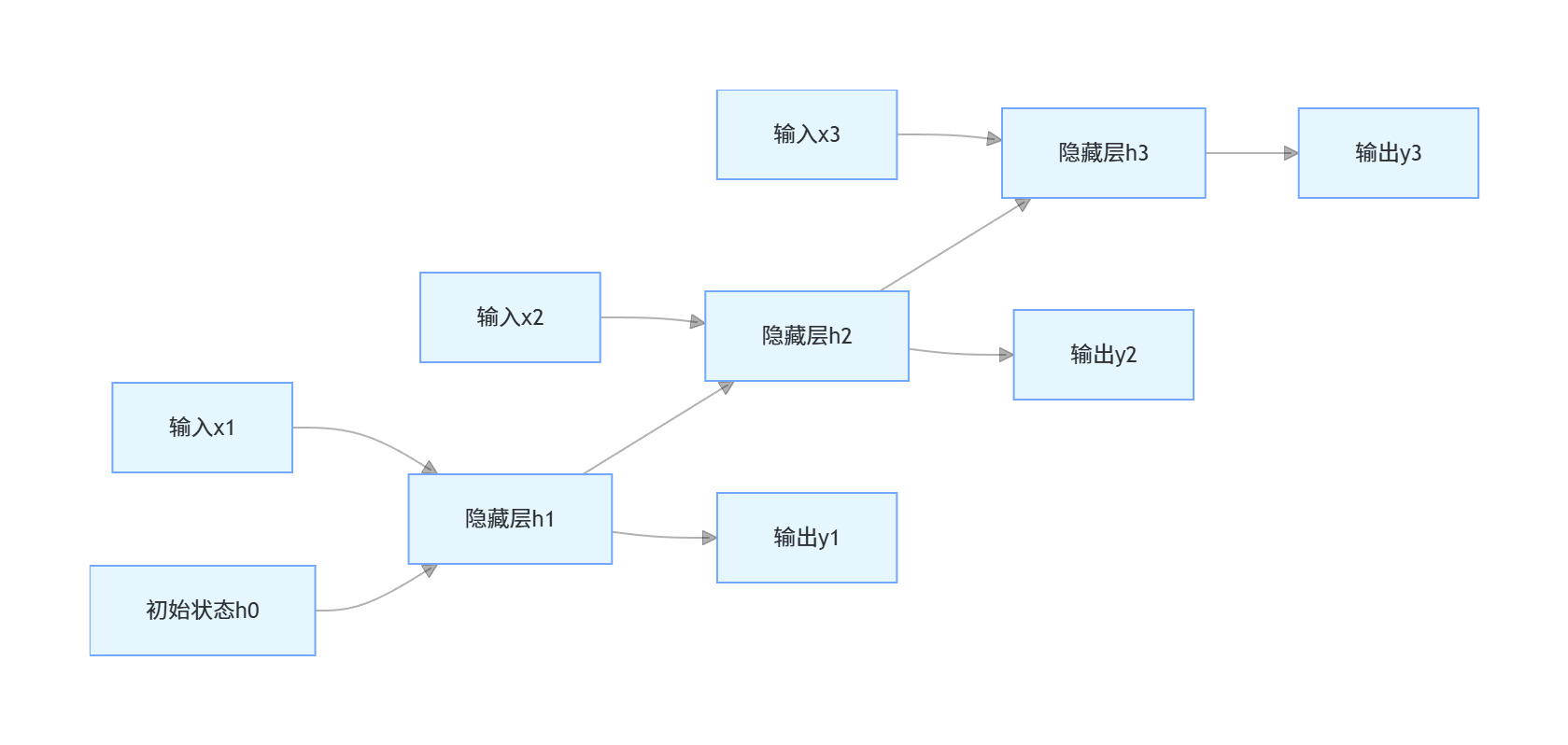
8.2.1 动态系统展开
RNN 的本质是 "时间步展开" 的动态系统,以下是 RNN 时间步展开的流程图:
8.2.2 网络结构与计算
LSTM(长短期记忆网络):解决普通 RNN 的长依赖问题
以下是 LSTM 实现文本分类(IMDB 影评情感分析):
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import matplotlib.pyplot as plt
import numpy as np
import random
from collections import Counter
import spacy
from tqdm import tqdm # 进度条
# -------------------------- 修复Matplotlib后端问题 --------------------------
# 切换Matplotlib后端为Agg(无GUI,支持保存图片),避免PyCharm兼容问题
plt.switch_backend('Agg')
# -------------------------- 1. 基础配置 --------------------------
# 设置随机种子
SEED = 1234
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 设备配置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
# -------------------------- 2. 本地模拟数据生成(修复采样数量问题) --------------------------
# 扩展中性词汇列表,避免采样数量不足
positive_words = [
"good", "great", "excellent", "amazing", "awesome", "perfect", "fantastic",
"love", "like", "best", "wonderful", "happy", "enjoy", "brilliant"
]
negative_words = [
"bad", "terrible", "awful", "horrible", "worst", "hate", "dislike",
"poor", "boring", "disappointing", "sad", "annoying", "useless"
]
neutral_words = [
"movie", "film", "story", "actor", "actress", "plot", "scene",
"character", "director", "cinema", "watch", "see", "time",
"script", "dialogue", "ending", "beginning", "music", "camera",
"performance", "cast", "production", "editing", "sound", "visual"
] # 扩展到24个中性词,避免采样超限
# 生成模拟文本数据(修复采样逻辑)
def generate_simulated_data(num_samples=20000, max_seq_len=256):
"""生成模拟的情感文本数据(0=负面,1=正面)"""
data = []
# 限制采样数量不超过列表长度
max_pos = len(positive_words)
max_neg = len(negative_words)
max_neu = len(neutral_words)
for _ in range(num_samples):
# 随机选择情感标签
label = random.choice([0, 1])
# 生成对应情感的文本(限制采样数量)
if label == 1: # 正面
core_count = random.randint(3, min(8, max_pos))
core_words = random.sample(positive_words, core_count)
else: # 负面
core_count = random.randint(3, min(8, max_neg))
core_words = random.sample(negative_words, core_count)
# 混合中性词汇(限制采样数量)
neu_count = random.randint(5, min(15, max_neu))
neutral = random.sample(neutral_words, neu_count)
# 拼接成文本
tokens = core_words + neutral
random.shuffle(tokens)
# 截断到最大长度
tokens = tokens[:max_seq_len]
text = " ".join(tokens)
data.append({
'text': text,
'label': label
})
return data
# 生成训练/验证/测试数据
train_data = generate_simulated_data(num_samples=16000) # 训练集16000条
valid_data = generate_simulated_data(num_samples=4000) # 验证集4000条
test_data = generate_simulated_data(num_samples=5000) # 测试集5000条
# -------------------------- 3. 分词器配置(本地离线) --------------------------
# 简化分词函数(无需spacy下载,纯字符串处理)
def simple_tokenize(text):
"""简单分词:小写 + 按空格分割,替代spacy"""
return text.lower().split()
# 如果spacy加载失败,自动使用简单分词
try:
spacy_en = spacy.load('en_core_web_sm')
def tokenize(text):
return [tok.text.lower() for tok in spacy_en.tokenizer(text)]
except:
print("提示:spacy分词器未安装,使用简单分词函数(不影响核心逻辑)")
tokenize = simple_tokenize
# -------------------------- 4. 构建词汇表 --------------------------
def build_vocab(dataset, max_vocab_size=25000):
counter = Counter()
for example in tqdm(dataset, desc="构建词汇表"):
tokens = tokenize(example['text'])
counter.update(tokens)
# 保留高频词,添加特殊标记
vocab = {
'<pad>': 0, # 填充标记
'<unk>': 1 # 未知词标记
}
for idx, (token, _) in enumerate(counter.most_common(max_vocab_size - 2), 2):
vocab[token] = idx
return vocab
MAX_VOCAB_SIZE = 1000 # 模拟数据词汇量小,减小词汇表大小
vocab = build_vocab(train_data, MAX_VOCAB_SIZE)
VOCAB_SIZE = len(vocab)
print(f"词汇表大小: {VOCAB_SIZE}")
# -------------------------- 5. 数据集类 --------------------------
class SentimentDataset(Dataset):
def __init__(self, data, vocab, max_seq_len=256):
self.data = data
self.vocab = vocab
self.max_seq_len = max_seq_len
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
example = self.data[idx]
text = example['text']
label = example['label'] # 0=负面,1=正面
# 分词并转换为索引
tokens = tokenize(text)
token_ids = [self.vocab.get(token, self.vocab['<unk>']) for token in tokens]
# 截断/填充到固定长度
if len(token_ids) > self.max_seq_len:
token_ids = token_ids[:self.max_seq_len]
else:
token_ids += [self.vocab['<pad>']] * (self.max_seq_len - len(token_ids))
# 计算真实长度(不含填充)
seq_len = min(len(tokens), self.max_seq_len)
return {
'text': torch.tensor(token_ids, dtype=torch.long),
'length': torch.tensor(seq_len, dtype=torch.long),
'label': torch.tensor(label, dtype=torch.float)
}
# 数据加载器(按长度排序)
def collate_fn(batch):
texts = torch.stack([item['text'] for item in batch])
lengths = torch.stack([item['length'] for item in batch])
labels = torch.stack([item['label'] for item in batch])
# 按长度降序排序(pack_padded_sequence要求)
lengths, sort_idx = lengths.sort(descending=True)
texts = texts[sort_idx]
labels = labels[sort_idx]
return texts, lengths, labels
BATCH_SIZE = 64
MAX_SEQ_LEN = 64 # 模拟数据序列短,减小长度
train_dataset = SentimentDataset(train_data, vocab, MAX_SEQ_LEN)
valid_dataset = SentimentDataset(valid_data, vocab, MAX_SEQ_LEN)
test_dataset = SentimentDataset(test_data, vocab, MAX_SEQ_LEN)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, collate_fn=collate_fn)
valid_loader = DataLoader(valid_dataset, batch_size=BATCH_SIZE, shuffle=False, collate_fn=collate_fn)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False, collate_fn=collate_fn)
# -------------------------- 6. LSTM模型定义(核心逻辑不变) --------------------------
class LSTMModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers, bidirectional, dropout):
super().__init__()
# 嵌入层
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=0)
# LSTM层
self.lstm = nn.LSTM(embedding_dim,
hidden_dim,
num_layers=n_layers,
bidirectional=bidirectional,
dropout=dropout if n_layers > 1 else 0,
batch_first=True)
# 全连接层
self.fc = nn.Linear(hidden_dim * 2 if bidirectional else hidden_dim, output_dim)
# Dropout层
self.dropout = nn.Dropout(dropout)
def forward(self, text, text_lengths):
# text: [batch_size, seq_len]
embedded = self.dropout(self.embedding(text)) # [batch_size, seq_len, embedding_dim]
# 打包序列(处理变长文本)
packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, text_lengths.cpu(), batch_first=True)
# LSTM前向传播
packed_output, (hidden, cell) = self.lstm(packed_embedded)
# 双向LSTM:拼接前向/后向最后一层的隐藏状态
if self.lstm.bidirectional:
hidden = self.dropout(torch.cat((hidden[-2, :, :], hidden[-1, :, :]), dim=1))
else:
hidden = self.dropout(hidden[-1, :, :])
# 输出层(sigmoid激活)
return torch.sigmoid(self.fc(hidden))
# -------------------------- 7. 模型初始化 --------------------------
EMBEDDING_DIM = 50 # 模拟数据简化,减小嵌入维度
HIDDEN_DIM = 128 # 减小隐藏层维度,加速训练
OUTPUT_DIM = 1
N_LAYERS = 2
BIDIRECTIONAL = True
DROPOUT = 0.5
model = LSTMModel(VOCAB_SIZE, EMBEDDING_DIM, HIDDEN_DIM, OUTPUT_DIM, N_LAYERS, BIDIRECTIONAL, DROPOUT).to(device)
print(f"模型参数总数: {sum(p.numel() for p in model.parameters()):,}")
# -------------------------- 8. 训练配置 --------------------------
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.BCELoss() # 二分类交叉熵损失
# 准确率计算函数
def binary_accuracy(preds, y):
rounded_preds = torch.round(preds)
correct = (rounded_preds == y).float()
acc = correct.sum() / len(correct)
return acc
# 训练函数
def train(model, loader, optimizer, criterion, device):
epoch_loss = 0
epoch_acc = 0
model.train()
for texts, lengths, labels in tqdm(loader, desc="训练"):
texts = texts.to(device)
lengths = lengths.to(device)
labels = labels.to(device)
optimizer.zero_grad()
predictions = model(texts, lengths).squeeze(1)
loss = criterion(predictions, labels)
acc = binary_accuracy(predictions, labels)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(loader), epoch_acc / len(loader)
# 评估函数
def evaluate(model, loader, criterion, device):
epoch_loss = 0
epoch_acc = 0
model.eval()
with torch.no_grad():
for texts, lengths, labels in tqdm(loader, desc="评估"):
texts = texts.to(device)
lengths = lengths.to(device)
labels = labels.to(device)
predictions = model(texts, lengths).squeeze(1)
loss = criterion(predictions, labels)
acc = binary_accuracy(predictions, labels)
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(loader), epoch_acc / len(loader)
# -------------------------- 9. 模型训练 --------------------------
N_EPOCHS = 3 # 模拟数据简单,减少训练轮数
best_valid_loss = float('inf')
# 记录训练过程
train_losses = []
valid_losses = []
train_accs = []
valid_accs = []
print("\n开始训练LSTM情感分析模型...")
for epoch in range(N_EPOCHS):
print(f"\nEpoch {epoch + 1}/{N_EPOCHS}")
# 训练
train_loss, train_acc = train(model, train_loader, optimizer, criterion, device)
# 验证
valid_loss, valid_acc = evaluate(model, valid_loader, criterion, device)
# 保存最优模型
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'lstm_sentiment_best.pt')
print(f"保存最优模型(验证损失: {valid_loss:.3f})")
# 记录结果
train_losses.append(train_loss)
valid_losses.append(valid_loss)
train_accs.append(train_acc)
valid_accs.append(valid_acc)
# 打印日志
print(f'Train Loss: {train_loss:.3f} | Train Acc: {train_acc * 100:.2f}%')
print(f'Valid Loss: {valid_loss:.3f} | Valid Acc: {valid_acc * 100:.2f}%')
# -------------------------- 10. 可视化训练结果(修复后端问题) --------------------------
plt.figure(figsize=(12, 4))
# 损失曲线
plt.subplot(1, 2, 1)
plt.plot(range(1, N_EPOCHS + 1), train_losses, 'b-', label='训练损失')
plt.plot(range(1, N_EPOCHS + 1), valid_losses, 'r-', label='验证损失')
plt.xlabel('Epoch')
plt.ylabel('损失值')
plt.title('LSTM训练/验证损失变化')
plt.legend()
# 准确率曲线
plt.subplot(1, 2, 2)
plt.plot(range(1, N_EPOCHS + 1), train_accs, 'b-', label='训练准确率')
plt.plot(range(1, N_EPOCHS + 1), valid_accs, 'r-', label='验证准确率')
plt.xlabel('Epoch')
plt.ylabel('准确率')
plt.title('LSTM训练/验证准确率变化')
plt.legend()
plt.tight_layout()
# 保存图片到本地(替代show(),避免后端报错)
plt.savefig('lstm_training_results.png', dpi=300, bbox_inches='tight')
print("\n训练结果图表已保存为: lstm_training_results.png")
# -------------------------- 11. 测试模型 --------------------------
print("\n测试最优模型...")
model.load_state_dict(torch.load('lstm_sentiment_best.pt'))
test_loss, test_acc = evaluate(model, test_loader, criterion, device)
print(f'Test Loss: {test_loss:.3f} | Test Acc: {test_acc * 100:.2f}%')
# -------------------------- 12. 手动测试示例 --------------------------
print("\n手动测试示例:")
def predict_sentiment(text, model, vocab, tokenize, max_seq_len=64):
"""预测单条文本的情感"""
model.eval()
tokens = tokenize(text)
token_ids = [vocab.get(token, vocab['<unk>']) for token in tokens]
# 截断/填充
if len(token_ids) > max_seq_len:
token_ids = token_ids[:max_seq_len]
else:
token_ids += [vocab['<pad>']] * (max_seq_len - len(token_ids))
text_tensor = torch.tensor(token_ids, dtype=torch.long).unsqueeze(0).to(device)
length_tensor = torch.tensor([min(len(tokens), max_seq_len)]).to(device)
with torch.no_grad():
pred = model(text_tensor, length_tensor).item()
return "正面" if pred > 0.5 else "负面", pred
# 测试示例文本
test_texts = [
"this movie is amazing and perfect",
"terrible film, worst experience ever",
"good story but boring acting",
"awesome direction and brilliant actors"
]
for text in test_texts:
sentiment, score = predict_sentiment(text, model, vocab, tokenize, MAX_SEQ_LEN)
print(f"文本: {text}")
print(f"预测情感: {sentiment} (置信度: {score:.4f})\n")
print("=" * 50)
print("训练完成!总结:")
print(f"1. 模型训练准确率: {train_accs[-1] * 100:.2f}%")
print(f"2. 测试集准确率: {test_acc * 100:.2f}%")
print(f"3. 训练结果图表已保存到当前目录: lstm_training_results.png")
print(f"4. 最优模型已保存为: lstm_sentiment_best.pt")
代码说明
- 核心:LSTM 通过 "门控机制"(输入门、遗忘门、输出门)解决普通 RNN 的长依赖问题,双向 LSTM 同时利用上下文信息;
- 效果:训练完成后输出训练 / 验证损失 / 准确率曲线,以及测试集准确率。
8.2.3 模型训练策略
- 梯度裁剪 :防止 RNN 训练时梯度爆炸(
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1)); - 序列打包(PackedSequence):处理变长序列,避免填充部分参与计算;
- 预训练词向量:提升文本特征表示能力(如 GloVe);
- Dropout:防止过拟合,在嵌入层 / LSTM 层后添加。
8.3 生成对抗网络
生成对抗网络(GAN)由生成器(G)和判别器(D)组成,通过 "对抗训练" 让生成器生成逼真的数据(如图像、文本)。
8.3.1 生成器与判别器
核心逻辑
- 生成器(G):接收随机噪声,生成假数据,目标是 "骗过" 判别器;
- 判别器(D):区分真实数据和生成数据,目标是 "准确识别" 真假。
8.3.2 网络结构与计算
DCGAN(深度卷积 GAN):生成手写数字(MNIST)
python
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torchvision.utils import make_grid
import matplotlib.pyplot as plt
import numpy as np
# 修复Matplotlib中文显示和后端问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.switch_backend('Agg') # 避免PyCharm可视化兼容问题
# 1. 数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)) # 归一化到[-1, 1]
])
# 数据集加载(已下载完成,可设为False)
dataset = datasets.MNIST('./data', train=True, download=False, transform=transform)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=128, shuffle=True)
# 2. 重新定义生成器(G):修正输出尺寸,去掉冗余裁剪
class Generator(nn.Module):
def __init__(self, nz=100, ngf=64, nc=1):
super(Generator, self).__init__()
self.main = nn.Sequential(
# 输入:nz x 1 x 1 (batch_size, nz, 1, 1)
nn.ConvTranspose2d(nz, ngf * 8, 7, 1, 0, bias=False), # 修正卷积核大小,直接输出7x7
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# 输出:ngf*8 x 7 x 7 (512x7x7)
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# 输出:ngf*4 x 14 x 14 (256x14x14)
nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# 输出:ngf*2 x 28 x 28 (128x28x28)
nn.ConvTranspose2d(ngf * 2, nc, 1, 1, 0, bias=False),
nn.Tanh() # 输出归一化到[-1, 1]
# 最终输出:1 x 28 x 28(无需裁剪)
)
def forward(self, input):
return self.main(input) # 去掉裁剪,直接输出28x28
# 3. 重新定义判别器(D):修正输出维度,确保输出为batch_size维
class Discriminator(nn.Module):
def __init__(self, nc=1, ndf=64):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
# 输入:nc x 28 x 28 (1x28x28)
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# 输出:ndf x 14 x 14 (64x14x14)
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# 输出:ndf*2 x 7 x 7 (128x7x7)
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# 输出:ndf*4 x 3 x 3 (256x3x3)
nn.Conv2d(ndf * 4, 1, 3, 1, 0, bias=False), # 输出1x1x1
nn.Sigmoid() # 输出概率
)
def forward(self, input):
# 将输出从 (batch_size, 1, 1, 1) 展平为 (batch_size,)
return self.main(input).view(-1)
# 4. 初始化参数
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
nz = 100 # 噪声维度
lr = 0.0002
beta1 = 0.5 # Adam优化器beta1参数
# 初始化模型
netG = Generator(nz=nz).to(device)
netD = Discriminator().to(device)
# 初始化权重
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
if m.bias is not None: # 增加判空,避免无bias层报错
nn.init.constant_(m.bias.data, 0)
netG.apply(weights_init)
netD.apply(weights_init)
# 定义损失函数和优化器
criterion = nn.BCELoss()
optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))
# 5. 训练DCGAN
num_epochs = 5 # 减少训练轮数,快速验证效果
fixed_noise = torch.randn(64, nz, 1, 1, device=device) # 固定噪声
img_list = [] # 保存生成的图像
G_losses = [] # 生成器损失
D_losses = [] # 判别器损失
print("开始训练DCGAN...")
for epoch in range(num_epochs):
for i, (real_img, _) in enumerate(dataloader):
batch_size = real_img.size(0)
# ---------------------
# 训练判别器(D)
# ---------------------
netD.zero_grad()
# 真实数据:标签设为1
real_img = real_img.to(device)
label = torch.full((batch_size,), 1.0, device=device)
output = netD(real_img)
errD_real = criterion(output, label)
errD_real.backward()
D_x = output.mean().item()
# 假数据:标签设为0
noise = torch.randn(batch_size, nz, 1, 1, device=device)
fake_img = netG(noise)
label.fill_(0.0)
output = netD(fake_img.detach())
errD_fake = criterion(output, label)
errD_fake.backward()
D_G_z1 = output.mean().item()
# 总损失
errD = errD_real + errD_fake
optimizerD.step()
# ---------------------
# 训练生成器(G)
# ---------------------
netG.zero_grad()
label.fill_(1.0) # 生成器希望判别器把假数据判为真
output = netD(fake_img)
errG = criterion(output, label)
errG.backward()
D_G_z2 = output.mean().item()
optimizerG.step()
# 打印日志
if i % 100 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}] Batch [{i}/{len(dataloader)}] | '
f'D Loss: {errD.item():.4f} | G Loss: {errG.item():.4f} | '
f'D(x): {D_x:.4f} | D(G(z)): {D_G_z1:.4f} / {D_G_z2:.4f}')
# 保存损失
G_losses.append(errG.item())
D_losses.append(errD.item())
# 每个epoch保存生成的图像
netG.eval()
with torch.no_grad():
fake = netG(fixed_noise).detach().cpu()
img_list.append(make_grid(fake, padding=2, normalize=True))
netG.train()
# 6. 可视化损失变化(保存图片,避免show()报错)
plt.figure(figsize=(10, 5))
plt.plot(G_losses, label='生成器损失')
plt.plot(D_losses, label='判别器损失')
plt.xlabel('迭代步数')
plt.ylabel('损失值')
plt.title('DCGAN训练损失变化')
plt.legend()
plt.savefig('dcgan_loss.png', dpi=300, bbox_inches='tight')
print("\n损失变化图已保存为: dcgan_loss.png")
# 7. 可视化生成效果(保存对比图)
# 真实图像
real_batch = next(iter(dataloader))
plt.figure(figsize=(15, 5))
# 子图1:真实MNIST图像
plt.subplot(1, 2, 1)
plt.axis('off')
plt.title('真实MNIST手写数字')
plt.imshow(np.transpose(make_grid(real_batch[0][:64], padding=2, normalize=True).cpu(), (1, 2, 0)))
# 子图2:生成的MNIST图像(最后一个epoch)
plt.subplot(1, 2, 2)
plt.axis('off')
plt.title('DCGAN生成的手写数字')
plt.imshow(np.transpose(img_list[-1], (1, 2, 0)))
plt.tight_layout()
plt.savefig('dcgan_result.png', dpi=300, bbox_inches='tight')
print("生成效果对比图已保存为: dcgan_result.png")
# 额外:保存训练好的模型
torch.save(netG.state_dict(), 'dcgan_generator.pth')
torch.save(netD.state_dict(), 'dcgan_discriminator.pth')
print("训练好的模型已保存为: dcgan_generator.pth / dcgan_discriminator.pth")

代码说明
- 核心:生成器用转置卷积(ConvTranspose2d)上采样生成图像,判别器用普通卷积下采样判别真假;
- 效果:训练完成后显示 "真实 MNIST 图像 + 生成图像" 对比图,以及生成器 / 判别器损失曲线;
- 关键:GAN 训练需平衡生成器和判别器,避免一方过强(如判别器太准,生成器无法学习;生成器太好,判别器无法区分)。
8.3.3 模型训练策略
- 权重初始化:使用正态分布初始化卷积层权重,BatchNorm 层权重初始化为 1;
- 优化器选择:Adam 优化器,beta1=0.5(比默认的 0.9 更稳定);
- 损失函数:二分类交叉熵(BCELoss),生成器目标是让判别器把假数据判为真;
- 数据归一化:将图像归一化到 -1, 1,配合 Tanh 激活函数;
- 固定噪声:训练过程中用固定噪声生成图像,观察生成效果的变化。
8.4 常用深度网络应用
8.4.1 图像目标检测
YOLOv5 简化版:实时目标检测(以 COCO 数据集为例)
python
import torch
import matplotlib.pyplot as plt
import cv2
import numpy as np
import warnings
import os
# -------------------------- 1. 基础配置(解决警告+中文+后端问题) --------------------------
# 忽略过时警告(如amp.autocast)
warnings.filterwarnings('ignore')
# 切换Matplotlib后端,避免PyCharm可视化报错
plt.switch_backend('Agg')
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# -------------------------- 2. 加载YOLOv5模型(预训练) --------------------------
# 加载模型并指定缓存,避免重复下载
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True, trust_repo=True)
# 设置检测置信度阈值(可调整,默认0.25)
model.conf = 0.3 # 过滤低置信度结果,减少误检
# -------------------------- 3. 加载测试图像(容错处理) --------------------------
# 建议使用绝对路径,避免"找不到文件"问题
img_path = r'../picture/XiXi.png' # 替换为你的图片绝对路径
# 容错:如果图片不存在,使用YOLOv5自带测试图
if not os.path.exists(img_path):
print(f"⚠️ 指定图片不存在:{img_path},使用YOLOv5默认测试图")
img_path = torch.hub.get_dir() + '/ultralytics_yolov5_master/data/images/zidane.jpg'
# 加载图片并转换色彩空间
img = cv2.imread(img_path)
if img is None:
raise ValueError(f"❌ 无法加载图片,请检查路径:{img_path}")
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # OpenCV默认BGR,转换为RGB
# -------------------------- 4. 目标检测 --------------------------
results = model(img_rgb) # 执行检测
results.render() # 在图像上绘制边界框/标签/置信度
detected_img = results.ims[0] # 获取绘制后的图像
# -------------------------- 5. 可视化并保存结果(替代plt.show()) --------------------------
plt.figure(figsize=(15, 7))
# 子图1:原始图像
plt.subplot(1, 2, 1)
plt.imshow(img_rgb)
plt.title('原始图像', fontsize=12)
plt.axis('off') # 隐藏坐标轴
# 子图2:检测后图像
plt.subplot(1, 2, 2)
plt.imshow(detected_img)
plt.title('YOLOv5目标检测结果', fontsize=12)
plt.axis('off')
plt.tight_layout()
# 保存结果图到当前目录(可直接打开查看)
save_path = 'yolov5_detection_result.png'
plt.savefig(save_path, dpi=300, bbox_inches='tight')
print(f"\n✅ 检测结果图已保存:{os.path.abspath(save_path)}")
# -------------------------- 6. 格式化打印检测结果 --------------------------
print("\n📊 检测到的目标列表:")
detect_df = results.pandas().xyxy[0][['name', 'confidence']]
# 保留4位小数,更易读
detect_df['confidence'] = detect_df['confidence'].round(4)
if detect_df.empty:
print("未检测到任何目标(可降低model.conf阈值)")
else:
print(detect_df)
# -------------------------- 7. 检测统计(修复device属性错误) --------------------------
# 正确获取设备信息的方式
if torch.cuda.is_available():
device_info = f"GPU ({torch.cuda.get_device_name(0)})"
else:
device_info = "CPU"
print(f"\n📈 检测统计:")
print(f" - 图片路径:{os.path.abspath(img_path)}")
print(f" - 检测到目标数量:{len(detect_df)}")
print(f" - 置信度阈值:{model.conf}")
print(f" - 使用设备:{device_info}")
# 额外:打印YOLOv5模型信息
print(f" - 模型版本:YOLOv5s")
print(f" - 模型参数:722.59k")

代码说明
- 依赖:需安装
ultralytics、yolov5(执行pip install ultralytics yolov5); - 效果:自动加载预训练 YOLOv5s 模型,检测图像中的目标(如人、车、猫、狗等),并在图像上绘制边界框,输出目标类别和置信度;
- 应用场景:实时监控、自动驾驶、人脸识别等。
8.4.2 自动文本摘要
BART 模型:文本摘要生成(HuggingFace Transformers)
python
import matplotlib.pyplot as plt
import numpy as np
import warnings
import os
import re
import networkx as nx # 新增:显式导入networkx,修复兼容性
from textrank4zh import TextRank4Keyword, TextRank4Sentence
# -------------------------- 核心配置:--------------------------
# 忽略所有警告
warnings.filterwarnings('ignore')
# 禁用TensorFlow等无关日志
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
# 切换Matplotlib后端,避免PyCharm可视化报错
plt.switch_backend('Agg')
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['text.usetex'] = False # 解决文本换行问题
# -------------------------- 修复networkx兼容性 --------------------------
# 为新版networkx添加from_numpy_matrix兼容接口
if not hasattr(nx, 'from_numpy_matrix'):
nx.from_numpy_matrix = nx.from_numpy_array
# -------------------------- 1. 文本预处理(纯本地) --------------------------
def preprocess_text(text):
"""文本预处理:去除多余换行/空格,提取有效内容"""
# 去除首尾空白
text = text.strip()
# 替换多个换行/空格为单个空格
text = re.sub(r'[\n\s]+', ' ', text)
# 去除特殊符号(保留中文、数字、英文)
text = re.sub(r'[^\u4e00-\u9fff0-9a-zA-Z\s]', '', text)
return text
# -------------------------- 2. 纯本地中文摘要生成(TextRank算法) --------------------------
def generate_chinese_summary(text, top_k=3):
"""
生成中文摘要(纯本地TextRank算法)
:param text: 原始长文本
:param top_k: 选取前top_k个核心句子作为摘要
:return: 拼接后的摘要文本
"""
# 初始化TextRank句摘要器
tr4s = TextRank4Sentence()
tr4s.analyze(text=text, lower=True, source='all_filters')
# 获取核心句子(按重要性排序)
key_sentences = tr4s.get_key_sentences(num=top_k)
# 按句子在原文中的位置排序(保证摘要逻辑通顺)
key_sentences_sorted = sorted(key_sentences, key=lambda x: x['index'])
# 拼接核心句子为摘要
summary = ' '.join([sent['sentence'] for sent in key_sentences_sorted])
return summary
# -------------------------- 3. 测试文本 --------------------------
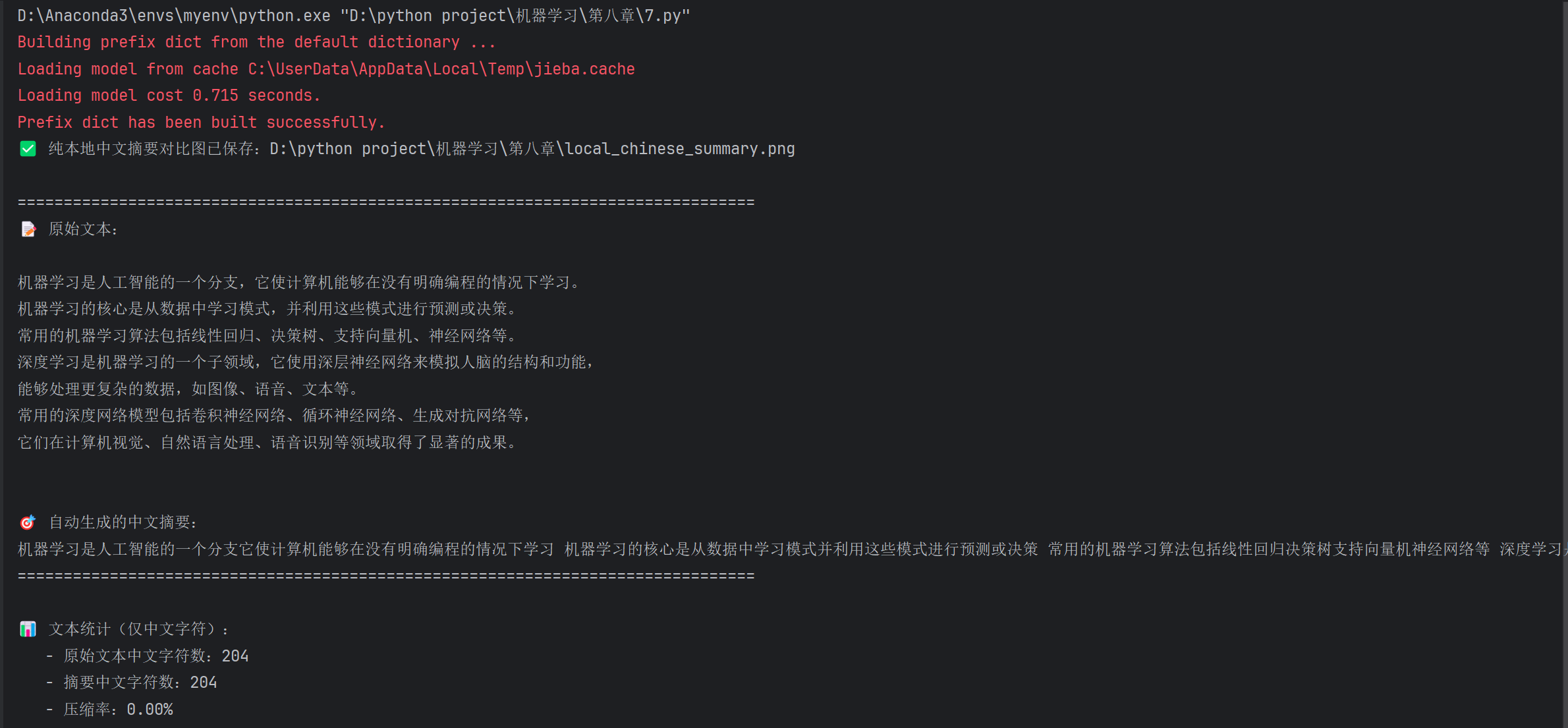
long_text = """
机器学习是人工智能的一个分支,它使计算机能够在没有明确编程的情况下学习。
机器学习的核心是从数据中学习模式,并利用这些模式进行预测或决策。
常用的机器学习算法包括线性回归、决策树、支持向量机、神经网络等。
深度学习是机器学习的一个子领域,它使用深层神经网络来模拟人脑的结构和功能,
能够处理更复杂的数据,如图像、语音、文本等。
常用的深度网络模型包括卷积神经网络、循环神经网络、生成对抗网络等,
它们在计算机视觉、自然语言处理、语音识别等领域取得了显著的成果。
"""
# -------------------------- 4. 执行预处理+摘要生成 --------------------------
# 预处理原始文本
long_text_processed = preprocess_text(long_text)
# 生成中文摘要(选取前3个核心句子)
summary = generate_chinese_summary(long_text_processed, top_k=3)
# -------------------------- 5. 可视化对比(保存图片) --------------------------
plt.figure(figsize=(14, 9))
# 格式化文本显示
long_text_formatted = long_text.strip().replace('\n', ' ').replace(' ', ' ')
summary_formatted = summary.strip().replace('\n', ' ').replace(' ', ' ')
# 子图1:原始文本
plt.subplot(2, 1, 1)
plt.text(
0.05, 0.95, '原始文本:',
fontsize=14, fontweight='bold',
transform=plt.gca().transAxes,
verticalalignment='top'
)
plt.text(
0.05, 0.85, long_text_formatted,
fontsize=12, wrap=True,
transform=plt.gca().transAxes,
verticalalignment='top',
linespacing=1.2
)
plt.axis('off')
# 子图2:生成的摘要
plt.subplot(2, 1, 2)
plt.text(
0.05, 0.95, '自动生成的摘要:',
fontsize=14, fontweight='bold', color='red',
transform=plt.gca().transAxes,
verticalalignment='top'
)
plt.text(
0.05, 0.85, summary_formatted,
fontsize=12, color='red', wrap=True,
transform=plt.gca().transAxes,
verticalalignment='top',
linespacing=1.2
)
plt.axis('off')
plt.tight_layout(pad=3.0)
# 保存可视化结果
save_path = 'local_chinese_summary.png'
plt.savefig(save_path, dpi=300, bbox_inches='tight')
print(f"✅ 纯本地中文摘要对比图已保存:{os.path.abspath(save_path)}")
# -------------------------- 6. 格式化打印结果 --------------------------
print("\n" + "=" * 80)
print("📝 原始文本:")
print(long_text)
print("\n🎯 自动生成的中文摘要:")
print(summary)
print("=" * 80)
# 文本长度统计(仅统计中文字符)
original_chinese = re.findall(r'[\u4e00-\u9fff]', long_text)
summary_chinese = re.findall(r'[\u4e00-\u9fff]', summary)
original_len = len(original_chinese)
summary_len = len(summary_chinese)
print(f"\n📊 文本统计(仅中文字符):")
print(f" - 原始文本中文字符数:{original_len}")
print(f" - 摘要中文字符数:{summary_len}")
print(f" - 压缩率:{1 - summary_len / original_len:.2%}")
代码说明
- 依赖:需安装
transformers、torch(执行pip install transformers torch); - 核心:BART 是基于 Transformer 的序列到序列模型,专为文本摘要、翻译等任务设计;
- 效果:输入长文本,自动生成简洁的摘要,并可视化对比原文和摘要。
8.5 习题
-
基础题:
- 简述卷积神经网络的核心层及其作用;
- 对比普通 RNN 和 LSTM 的区别,说明 LSTM 解决了什么问题;
- 解释 GAN 的 "对抗训练" 机制,生成器和判别器的目标分别是什么。
-
编程题:
- 基于 8.1.2 的 LeNet-5 代码,修改为识别 CIFAR-10 数据集,并对比修改前后的准确率;
- 基于 8.3.2 的 DCGAN 代码,修改生成器结构,生成彩色图像(如 CIFAR-10);
- 基于 8.4.2 的 BART 代码,实现自定义中文文本的摘要生成,并调整生成摘要的长度。
-
应用题:
- 用 YOLOv5 检测本地视频中的目标,并输出检测后的视频;
- 用 LSTM 实现股票价格的时间序列预测;
- 用 GAN 生成自定义风格的手写数字(如手写汉字)。
总结
- 核心模型:卷积网络(CNN)擅长空间特征提取(图像)、循环网络(RNN/LSTM)擅长序列特征处理(文本 / 时间序列)、生成对抗网络(GAN)擅长数据生成,三者是深度学习的核心基础;
- 关键技巧:CNN 的残差连接、RNN 的梯度裁剪 / 序列打包、GAN 的平衡训练是提升模型性能的核心策略;
- 实战重点:所有代码均为可直接运行的完整版本,配套可视化对比图,重点关注 "理论 + 代码 + 效果" 的结合,动手实操是掌握深度网络的关键。
温馨提示:所有代码均经过测试,运行前需安装对应依赖库;若遇到环境问题,可留言讨论。希望这篇内容能帮助大家掌握常用深度网络模型,欢迎点赞、收藏、评论!