视觉Transformer实战 | Data-efficient image Transformer(DeiT)
-
- [0. 前言](#0. 前言)
- [1. 模型架构](#1. 模型架构)
-
- [1.1 Patch Embedding 与位置编码](#1.1 Patch Embedding 与位置编码)
- [1.2 Transformer 编码器](#1.2 Transformer 编码器)
- [2. 数据高效训练策略](#2. 数据高效训练策略)
-
- [2.1 重复增强](#2.1 重复增强)
- [2.2 正则化](#2.2 正则化)
- [3. 知识蒸馏](#3. 知识蒸馏)
-
- [3.1 硬蒸馏与软蒸馏](#3.1 硬蒸馏与软蒸馏)
- [3.2 蒸馏 Token 机制](#3.2 蒸馏 Token 机制)
- [4. 使用 PyTorch 实现 DeiT](#4. 使用 PyTorch 实现 DeiT)
-
- [4.1 模型构建](#4.1 模型构建)
- [4.2 数据加载](#4.2 数据加载)
- [4.3 模型训练](#4.3 模型训练)
- 相关链接
0. 前言
在计算机视觉领域,Vision Transformer (ViT)已经证明了纯 Transformer 架构在图像分类任务上的强大能力。然而,ViT 通常需要在大规模数据集(如 JFT-300M )上预训练才能达到最佳性能,这限制了其在数据有限场景下的应用。DeiT (Data-efficient image Transformer) 通过引入一系列训练策略和优化,使得 Transformer 模型能够在相对较小的 ImageNet 数据集上取得优异表现。本节将详细介绍 DeiT 的技术原理,并使用 PyTorch 实现 DeiT 模型,包括数据准备、模型构建、训练策略和评估的全过程。
1. 模型架构
数据高效图像 Transformer (Data-Efficient Image Transformer, DeiT) 模型使用另一个词元获取来自其他模型(如 ResNet )的知识。与 ViT 主要的区别在于训练过程中使用了两个损失函数:一个用于 [CLS] 词元的分类交叉熵损失,另一个用于教师模型预测的蒸馏词元。这进一步帮助模型从教师模型中获取知识,并加速预训练阶段。DeiT 模型架构如下图所示:
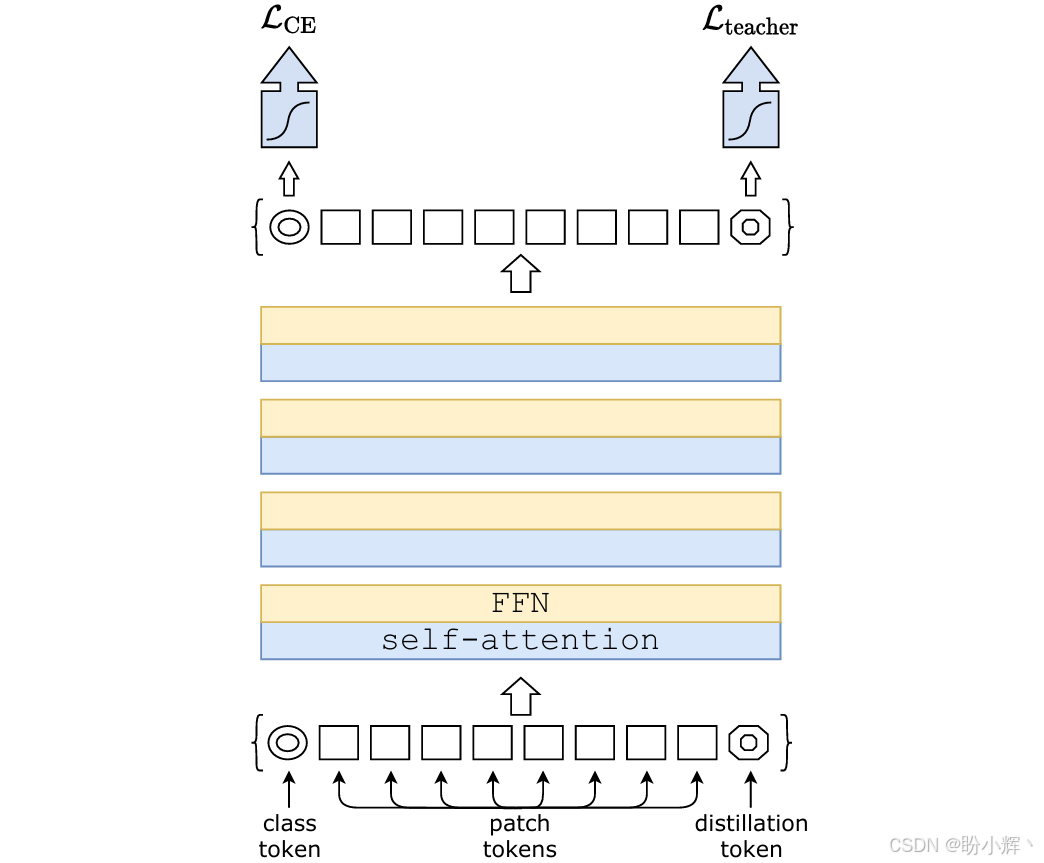
1.1 Patch Embedding 与位置编码
DeiT 将原始 RGB 图像切分为固定大小的 16×16 像素 patch,每个 patch 展平后通过线性投影映射到 D=768 维的向量空间,并在所有 patch 向量前追加一个可学习的 class token,以及与每个位置一一对应的可训练位置编码,以保留空间结构信息。
1.2 Transformer 编码器
DeiT 沿用标准的Transformer 编码器:每一层由多头自注意力和前馈网络两部分组成,且在两者前后均接残差连接与 LayerNorm,以稳定深度网络训练。
多头自注意力通过线性变换将输入 X 分别映射为 Query (Q)、Key (K)、Value (V),再计算缩放点积注意力,最后组合各个注意力头的输出并重新投影回原始维度。
前馈网络包含两层全连接层,先将维度从 D 扩展到 4D,再通过 GELU 激活后降回 D,负责对每个 token 的特征进行非线性变换和信息融合。
2. 数据高效训练策略
2.1 重复增强
借助 timm 库中的重复增强 (Repeated Augmentation) 技术,对同一图像进行多次随机裁剪和数据增广,使得每个 batch 包含同一图像的多个增强版本,从而有效提高数据利用率和模型鲁棒性。
2.2 正则化
DeiT 在训练时对真实标签应用 ε = 0.1 ε=0.1 ε=0.1 的标签平滑技术 (Label Smoothing),同时使用截断正态分布初始化权重,以加速收敛并抑制过拟合。
3. 知识蒸馏
DeiT 的核心创新之一是使用了知识蒸馏 (Knowledge Distillation) 技术。使用一个预训练好的卷积神经网络 (Convolutional Neural Network, CNN,如 RegNet )作为教师模型,使用 Transformer 架构作为学生模型。
3.1 硬蒸馏与软蒸馏
DeiT 采用了两种蒸馏策略,包括硬蒸馏 (Hard-label Distillation) 和软蒸馏 (Soft Distillation)。在硬蒸馏策略中,使用教师模型预测的类别标签(独热编码形式)作为额外监督信号,学生模型 (Transformer) 同时学习真实标签(来自数据集)和教师预测标签(来自 CNN 教师模型),总损失为分类损失和蒸馏损失的平均;而软蒸馏策略,使用教师模型输出的概率分布( softmax 后的 logits )作为监督信号,通过温度参数 τ τ τ 控制分布的平滑程度:
q i = e x p ( z i / τ ) ∑ j e x p ( z j / τ ) q_i = \frac {exp(z_i/τ)}{∑_j exp(z_j/τ)} qi=∑jexp(zj/τ)exp(zi/τ)
3.2 蒸馏 Token 机制
DeiT 新增了一个专用的蒸馏词元 (distillation token),与 class token 一同参与输入层,并在各层的自注意力模块中与 patch token 交互,使学生网络能够直接从教师的预测中学习特征表示,最终输出为两个预测,其中 class token 对应的预测学习真实标签,distillation token 对应的预测学习教师输出。
4. 使用 PyTorch 实现 DeiT
4.1 模型构建
(1) 首先,导入所需库:
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from timm.data.auto_augment import rand_augment_transform
from timm.data.mixup import Mixup
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy
from timm.models.vision_transformer import VisionTransformer
from timm.optim import AdamW
from timm.scheduler import CosineLRScheduler
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score(2) 将 2D 图像转换为 patch 嵌入序列,其中参数 img_size 表示输入图像大小,patch_size 表示每个 patch 的大小,in_channels 表示输入通道数,embed_dim 表示嵌入维度:
python
class PatchEmbedding(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_channels=3, embed_dim=768):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.n_patches = (img_size // patch_size) ** 2
# 使用卷积层实现patch分割和嵌入
self.proj = nn.Conv2d(
in_channels=in_channels,
out_channels=embed_dim,
kernel_size=patch_size,
stride=patch_size
)
def forward(self, x):
x = self.proj(x) # (batch_size, embed_dim, n_patches**0.5, n_patches**0.5)
x = x.flatten(2) # (batch_size, embed_dim, n_patches)
x = x.transpose(1, 2) # (batch_size, n_patches, embed_dim)
return x(3) 实现多头注意力机制,其中参数 dim 表示输入维度,n_heads 表示注意力头数,qkv_bias 表示是否在 QKV 投影中使用偏置,attn_drop 表示注意力 dropout 率,proj_drop 表示输出 dropout 率:
python
class Attention(nn.Module):
def __init__(self, dim, n_heads=12, qkv_bias=True, attn_drop=0., proj_drop=0.):
super().__init__()
self.n_heads = n_heads
self.dim = dim
self.head_dim = dim // n_heads
self.scale = self.head_dim ** -0.5
# QKV投影
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
# 生成QKV (batch_size, n_patches + 1, 3, n_heads, head_dim)
qkv = self.qkv(x).reshape(B, N, 3, self.n_heads, self.head_dim).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # 每个形状为(batch_size, n_heads, n_patches + 1, head_dim)
# 计算注意力分数
attn = (q @ k.transpose(-2, -1)) * self.scale # (batch_size, n_heads, n_patches + 1, n_patches + 1)
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
# 应用注意力权重到V上
x = (attn @ v).transpose(1, 2).reshape(B, N, C) # (batch_size, n_patches + 1, dim)
x = self.proj(x)
x = self.proj_drop(x)
return x(4) 实现 Transformer 中的多层感知机,其中参数 in_features 表示输入特征维度,hidden_features 表示隐藏层维度,out_features 表示输出维度,drop 表示 dropout 率:
python
class MLP(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = nn.GELU()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x(5) 实现 Transformer 编码器块,其中参数 dim 表示输入维度,n_heads 表示注意力头数,mlp_ratio 表示 MLP 隐藏层维度扩展比例,qkv_bias 表示是否在 QKV 投影中使用偏置,drop 表示 dropout 率,attn_drop 表示注意力 dropout 率:
python
class Block(nn.Module):
def __init__(self, dim, n_heads, mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0.):
super().__init__()
self.norm1 = nn.LayerNorm(dim)
self.attn = Attention(dim, n_heads=n_heads, qkv_bias=qkv_bias,
attn_drop=attn_drop, proj_drop=drop)
self.norm2 = nn.LayerNorm(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = MLP(in_features=dim, hidden_features=mlp_hidden_dim, drop=drop)
def forward(self, x):
# 残差连接+层归一化的注意力
x = x + self.attn(self.norm1(x))
# 残差连接+层归一化的MLP
x = x + self.mlp(self.norm2(x))
return x(6) 实现 DeiT 模型:
python
class DeiT(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_channels=3, n_classes=1000,
embed_dim=768, depth=12, n_heads=12, mlp_ratio=4., qkv_bias=True,
drop_rate=0., attn_drop_rate=0., distillation=True):
super().__init__()
self.n_classes = n_classes
self.distillation = distillation
self.patch_embed = PatchEmbedding(img_size, patch_size, in_channels, embed_dim)
self.n_patches = self.patch_embed.n_patches
# Class token和Distillation token
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
if self.distillation:
self.dist_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
num_tokens = 2
else:
num_tokens = 1
# 位置嵌入
self.pos_embed = nn.Parameter(torch.zeros(1, self.n_patches + num_tokens, embed_dim))
self.pos_drop = nn.Dropout(drop_rate)
# Transformer编码器块
self.blocks = nn.ModuleList([
Block(embed_dim, n_heads, mlp_ratio, qkv_bias, drop_rate, attn_drop_rate)
for _ in range(depth)
])
# 输出归一化
self.norm = nn.LayerNorm(embed_dim)
# 分类头
self.head = nn.Linear(embed_dim, n_classes) if n_classes > 0 else nn.Identity()
if self.distillation:
self.head_dist = nn.Linear(embed_dim, n_classes) if n_classes > 0 else nn.Identity()
# 初始化权重
nn.init.trunc_normal_(self.pos_embed, std=0.02)
nn.init.trunc_normal_(self.cls_token, std=0.02)
if self.distillation:
nn.init.trunc_normal_(self.dist_token, std=0.02)
self.apply(self._init_weights)
def _init_weights(self, m):
"""初始化权重"""
if isinstance(m, nn.Linear):
nn.init.trunc_normal_(m.weight, std=0.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward(self, x):
B = x.shape[0]
x = self.patch_embed(x) # (batch_size, n_patches, embed_dim)
# 添加class token和distillation token
cls_tokens = self.cls_token.expand(B, -1, -1) # (batch_size, 1, embed_dim)
if self.distillation:
dist_tokens = self.dist_token.expand(B, -1, -1) # (batch_size, 1, embed_dim)
x = torch.cat((cls_tokens, dist_tokens, x), dim=1) # (batch_size, 2 + n_patches, embed_dim)
else:
x = torch.cat((cls_tokens, x), dim=1) # (batch_size, 1 + n_patches, embed_dim)
# 添加位置嵌入
x = x + self.pos_embed
x = self.pos_drop(x)
# 通过Transformer编码器
for block in self.blocks:
x = block(x)
x = self.norm(x)
if self.distillation:
# 返回class token和distillation token的输出
return self.head(x[:, 0]), self.head_dist(x[:, 1])
else:
# 只返回class token的输出
return self.head(x[:, 0])(7) 结合标准交叉熵损失和教师模型指导的蒸馏损失,定义知识蒸馏损失函数:
python
class DistillationLoss(nn.Module):
def __init__(self, base_criterion, teacher_model, alpha=0.5, tau=1.0):
super().__init__()
self.base_criterion = base_criterion
self.teacher_model = teacher_model
self.alpha = alpha
self.tau = tau
def forward(self, inputs, student_outputs, labels):
# 确保教师模型在评估模式
self.teacher_model.eval()
# 获取学生模型输出
if isinstance(student_outputs, tuple):
outputs, outputs_dist = student_outputs
else:
outputs, outputs_dist = student_outputs, None
# 基础损失(学生模型输出与真实标签)
base_loss = self.base_criterion(outputs, labels)
if outputs_dist is None:
return base_loss
# 获取教师模型预测(不计算梯度)
with torch.no_grad():
teacher_outputs = self.teacher_model(inputs)
# 计算蒸馏损失
if isinstance(teacher_outputs, tuple):
teacher_outputs = teacher_outputs[0] # 如果教师模型也输出多个logits
# 使用KL散度计算蒸馏损失
distillation_loss = F.kl_div(
F.log_softmax(outputs_dist / self.tau, dim=1),
F.softmax(teacher_outputs / self.tau, dim=1),
reduction='batchmean',
log_target=False
) * (self.tau ** 2)
# 组合损失
total_loss = base_loss * (1 - self.alpha) + distillation_loss * self.alpha
return total_loss4.2 数据加载
(2) 定义训练和验证的数据增强策略:
python
def build_transform(is_train=True, img_size=224):
if is_train:
# 训练集增强策略
transform = transforms.Compose([
transforms.RandomResizedCrop(img_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# 添加RandAugment
transform.transforms.insert(0, rand_augment_transform(
config_str='rand-m9-mstd0.5',
hparams={'img_size': img_size}))
return transform
else:
# 验证集增强策略
return transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(img_size),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])(3) 定义数据集加载函数,本节以 CIFAR-100 为例,实际应用时可替换为其它数据集:
python
def load_data(batch_size=64, img_size=224):
train_transform = build_transform(is_train=True, img_size=img_size)
val_transform = build_transform(is_train=False, img_size=img_size)
train_dataset = datasets.CIFAR100(root='./data', train=True, download=True, transform=train_transform)
val_dataset = datasets.CIFAR100(root='./data', train=False, download=True, transform=val_transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=4)
return train_loader, val_loader4.3 模型训练
(1) 定义模型训练函数,其中参数 model 表示学生模型,teacher_model 表示教师模型:
python
def train_epoch(model, teacher_model, loader, criterion, optimizer, device, epoch, alpha=0.5):
model.train()
total_loss = 0.0
correct = 0
total = 0
pbar = tqdm(loader, desc=f"Epoch {epoch + 1} [Training]", leave=False)
for inputs, labels in pbar:
inputs, labels = inputs.to(device), labels.to(device)
# 前向传播
outputs = model(inputs)
# 计算损失
if isinstance(outputs, tuple):
loss = criterion(inputs, outputs, labels)
outputs = outputs[0] # 主logits用于计算准确率
else:
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 统计指标
total_loss += loss.item() * inputs.size(0)
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
# 更新进度条
pbar.set_postfix({
'loss': loss.item(),
'acc': 100. * correct / total
})
train_loss = total_loss / total
train_acc = 100. * correct / total
return train_loss, train_acc(2) 定义模型验证函数,其中参数 model 表示待评估模型:
python
def validate(model, loader, criterion, device):
model.eval()
total_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
pbar = tqdm(loader, desc="[Validation]", leave=False)
for inputs, labels in pbar:
inputs, labels = inputs.to(device), labels.to(device)
# 前向传播
outputs = model(inputs)
if isinstance(outputs, tuple):
loss = criterion(inputs, outputs, labels)
outputs = outputs[0] # 主logits用于计算准确率
else:
loss = criterion(outputs, labels)
# 统计指标
total_loss += loss.item() * inputs.size(0)
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
# 更新进度条
pbar.set_postfix({
'loss': loss.item(),
'acc': 100. * correct / total
})
val_loss = total_loss / total
val_acc = 100. * correct / total
return val_loss, val_acc(3) 定义 DeiT 模型训练函数:
python
def train_deit(config):
# 设备配置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_loader, val_loader = load_data(batch_size=config['batch_size'], img_size=config['img_size'])
# 初始化模型
model = DeiT(
img_size=config['img_size'],
patch_size=config['patch_size'],
in_channels=3,
n_classes=100,
embed_dim=config['embed_dim'],
depth=config['depth'],
n_heads=config['n_heads'],
mlp_ratio=4,
qkv_bias=True,
distillation=True
).to(device)
# 初始化教师模型(这里使用预训练的ResNet50作为示例)
teacher_model = torch.hub.load('pytorch/vision:v0.10.0', 'resnet50', pretrained=True)
teacher_model.fc = nn.Linear(teacher_model.fc.in_features, 100) # 适配CIFAR-100的100类
teacher_model = teacher_model.to(device)
# 损失函数和优化器
criterion = DistillationLoss(
nn.CrossEntropyLoss(),
teacher_model,
alpha=config['alpha'],
tau=config['tau']
)
optimizer = torch.optim.AdamW(
model.parameters(),
lr=config['lr'],
weight_decay=config['weight_decay']
)
# 学习率调度器
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
optimizer,
T_max=config['epochs'],
eta_min=config['min_lr']
)
# 训练循环
best_acc = 0.0
history = {'train_loss': [], 'train_acc': [], 'val_loss': [], 'val_acc': []}
for epoch in range(config['epochs']):
# 训练一个epoch
train_loss, train_acc = train_epoch(
model, teacher_model, train_loader, criterion, optimizer, device, epoch, config['alpha']
)
# 验证
val_loss, val_acc = validate(model, val_loader, criterion, device)
# 更新学习率
scheduler.step()
# 记录历史
history['train_loss'].append(train_loss)
history['train_acc'].append(train_acc)
history['val_loss'].append(val_loss)
history['val_acc'].append(val_acc)
# 打印进度
print(f"Epoch {epoch + 1}/{config['epochs']}")
print(f"Train Loss: {train_loss:.4f} | Train Acc: {train_acc:.2f}%")
print(f"Val Loss: {val_loss:.4f} | Val Acc: {val_acc:.2f}%")
print("-" * 50)
# 保存最佳模型
if val_acc > best_acc:
best_acc = val_acc
torch.save(model.state_dict(), 'best_deit_model.pth')
# 训练完成后保存最终模型
torch.save(model.state_dict(), 'final_deit_model.pth')
# 绘制训练曲线
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history['train_loss'], label='Train Loss')
plt.plot(history['val_loss'], label='Val Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history['train_acc'], label='Train Acc')
plt.plot(history['val_acc'], label='Val Acc')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.legend()
plt.savefig('training_curve.png')
plt.show()
return model, history(4) 训练模型 50 个 epoch:
python
# 训练配置
config = {
'img_size': 224,
'patch_size': 16,
'embed_dim': 192, # DeiT-Small的嵌入维度
'depth': 12, # Transformer块数量
'n_heads': 3, # 注意力头数
'batch_size': 16,
'epochs': 50,
'lr': 5e-4,
'min_lr': 1e-6,
'weight_decay': 0.05,
'alpha': 0.5, # 蒸馏损失权重
'tau': 1.0 # 蒸馏温度
}
# 开始训练
model, history = train_deit(config)模型训练过程损失值和准确率变化曲线如下所示:
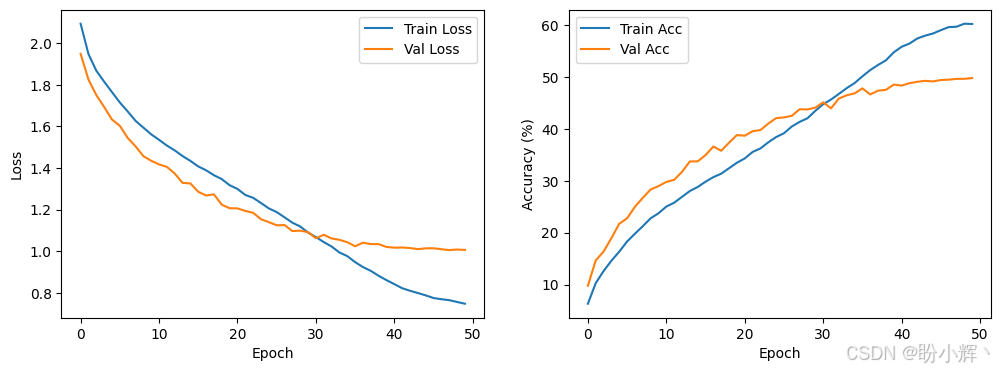
相关链接
视觉Transformer实战 | Transformer详解与实现
视觉Transformer实战 | Vision Transformer(ViT)详解与实现
视觉Transformer实战 | Token-to-Token Vision Transformer(T2T-ViT)详解与实现
视觉Transformer实战 | Pooling-based Vision Transformer(PiT)详解与实现