目录
[3.新序列采样(Sampling novel sequences)](#3.新序列采样(Sampling novel sequences))
1.不同类型的RNN
- RNN按照输入与输出的大小关系,可以分成不同结构
- 以下图举例:
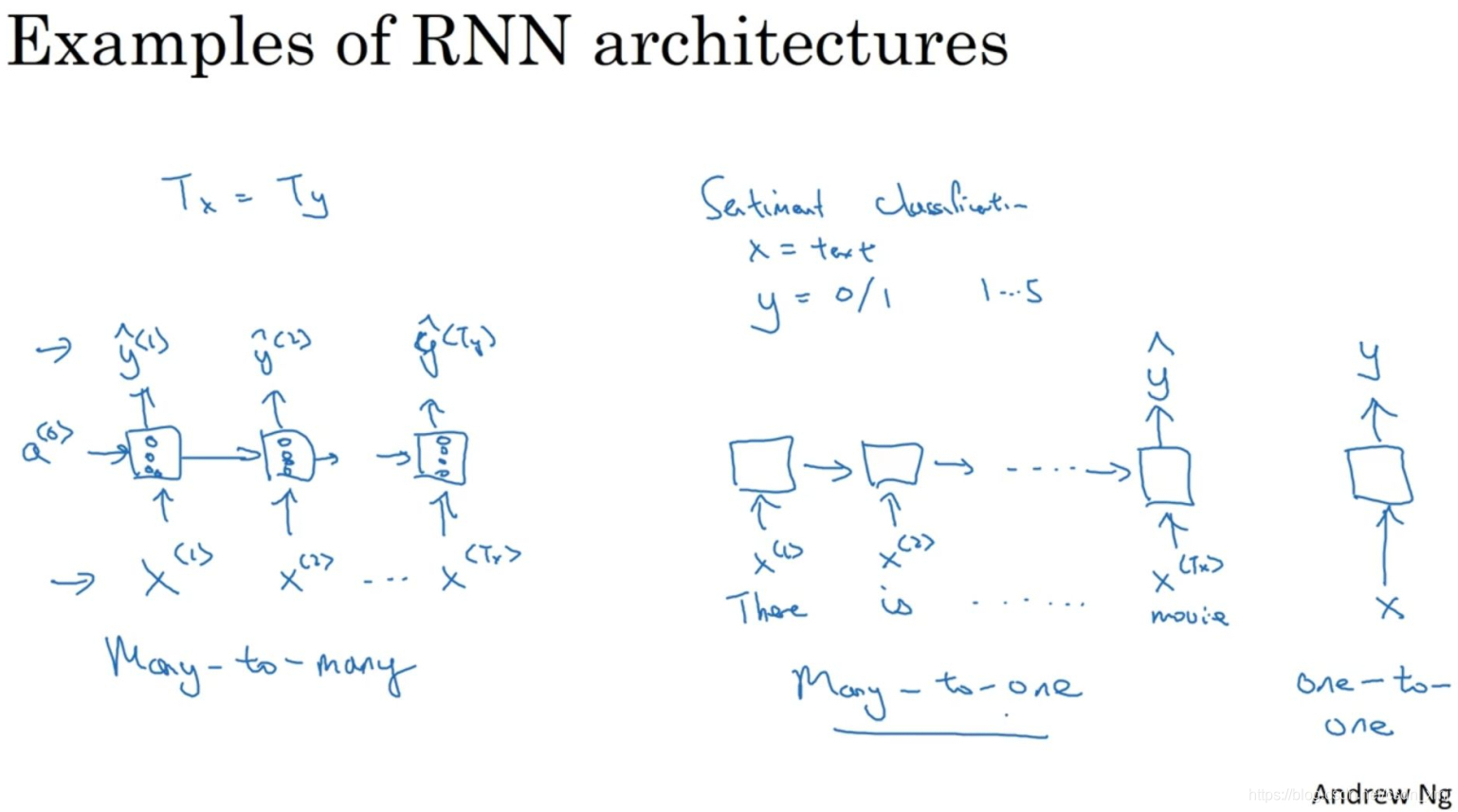
(1)多对多结构
- 输入序列有很多的输入,而输出序列也有很多输出
- 命名实体识别(Tx=Ty),机器翻译(Tx≠Ty)
(2)多对一结构
- 很多输入,输出一个数字
- 上图中间,处理情感分类问题时,x就是一个序列(可能是一段文本),而y可能是从1到5的一个数字,或者是0或1,这代表正面评价和负面评价。电影评价时,数字1到5代表电影是1星,2星,3星,4星还是5星。
(3)一对一
- 上图最右侧所示,这就是一个小型的标准的神经网络,输入x然后得到输出y
(4)一对多
- 音乐生成,x可以是空的输入,可设为0向量,而输出是一段音乐。
2.语言模型
(1)语言模型
- 语音识别系统中识别单词要用到语言模型,语言模型会告诉你某个特定的句子它出现的概率是多少
(2)训练语言模型
-
首先需要一个训练集(training set),包含一个很大的英文文本语料库或者其它的语言的语料库。语料库是自然语言处理的一个专有名词,意思是数量众多的英文句子组成的文本。
-
接下来需要将句子标记化,建立一个字典,然后将每个单词都转换成对应的one-hot向量。可能要定义句子的结尾,一般的做法就是增加一个额外的标记,叫做EOS(End Of Sentence),它表示句子的结尾(EOS标记可以被附加到训练集中每一个句子的结尾)
-
训练集中有一些词并不在你的字典里,比如人名Mau,可以把Mau替换成一个叫做UNK(unknown words)的代表未知词的标志,我们只针对UNK建立概率模型,而不是针对这个具体的词Mau。
-
下一步我们要构建一个RNN来构建这些序列的概率模型。
-
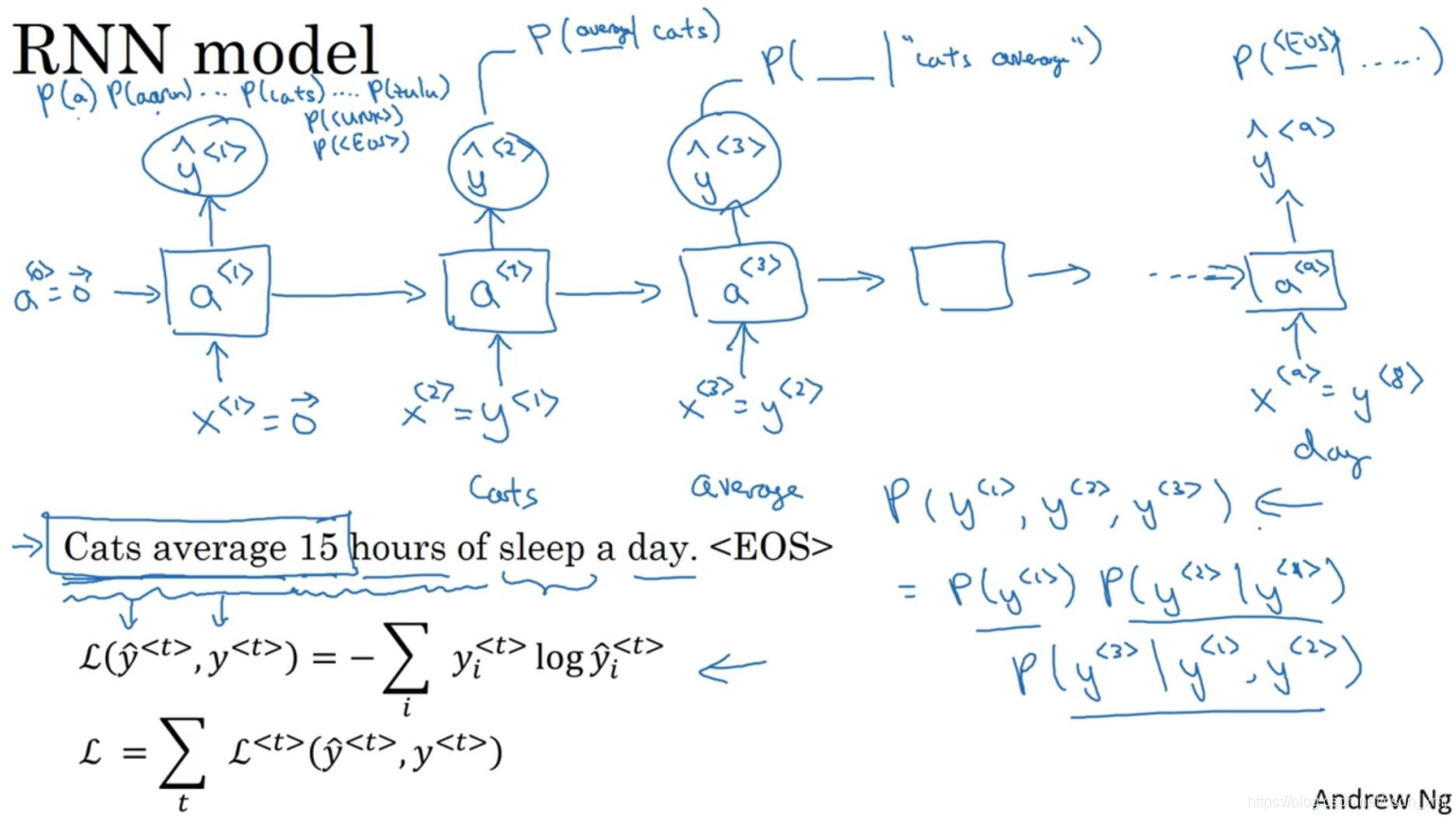
-
在第0个时间步,你要计算激活项a<1>,它是以x<1>作为输入的函数。a<1>通过softmax进行一些预测来计算出第一个词可能会是什么,比如说第一个词是a的概率有多少,第一个词是Aaron的概率有多少,第一个词是cats的概率又有多少,还有第一个词是UNK(未知词)的概率有多少,还有第一个词是句子结尾标志的概率有多少。它只是预测第一个词的概率,而不去管结果是什么。在这个例子中,最终会得到单词Cats。所以softmax层输出10,000种结果,因为你的字典中有10,000个词,或者会有10,002个结果,因为可能加上了未知词和句子结尾这两个额外的标志。
-
进入下个时间步,仍然使用激活项a<1>,这一步计算出第二个词会是什么。我们会告诉它第一个词就是Cats,这就是为什么y<1> = x<2>。同理x<3>= y<2>,以此类推。
-
最后定义损失函数,梯度下降
3.新序列采样(Sampling novel sequences)
(1)定义
- 基于模型学习到的概率分布,逐步生成新的序列样本(新句子)
(2)作用
- 当训练完一个序列模型后,我们可以通过新序列采样来了解它学到了什么
(3)过程
-
输入x<1>=0和a<0>=0,现在第一个时间步得到的输出是经过softmax层后得到的概率,然后根据这个softmax的分布进行随机采样。Softmax分布给你的信息就是第一个词a的概率是多少,第一个词是zulu的概率是多少,还有第一个词是UNK(未知标识)的概率是多少,然后对这个向量使用numpy命令为:np.random.choice(随机),来根据向量中这些概率的分布进行采样,然后继续下一个时间步。做的事情相当于下面的python程序做的事情:
import numpy as np
1. 模拟模型输出:候选元素(如词汇表:[你, 我, 他, 好, 吃])+ 对应概率分布(和为1)
candidates = np.array(["你", "我", "他", "好", "吃"])
probs = np.array([0.1, 0.5, 0.05, 0.2, 0.15]) # 模型计算的各元素概率2. 核心采样:按概率选1个下一个元素(序列采样的核心操作)
next_token = np.random.choice(candidates, size=1, p=probs)
print("采样得到的下一个元素:", next_token[0]