
Automated Knowledge Graph Construction using Large Language Models and Sentence Complexity Modelling
摘要
本文介绍了CoDe-KG,一个开源的端到端知识图谱构建管道,通过结合强大的共指消解和句法分解技术,实现句子级知识提取。该系统贡献了超过15万个知识三元组的数据集,并在关系抽取任务上达到了业界领先水平,在REBEL数据集上实现了65.8%的宏F1分数。
阅读原文或https://t.zsxq.com/8utDz获取原文pdf
一、研究背景与意义
1.1 知识图谱的重要性
知识图谱(Knowledge Graphs, KGs)已经彻底改变了数据组织的方式。通过利用复杂的网络链,研究人员能够探索不同领域中的复杂关系,特别是在因果关系分析等领域取得了重要进展。
随着自然语言处理(NLP)领域中大语言模型(LLMs)的快速发展,知识图谱变得越来越重要。它们不仅作为知识库发挥作用,还在这些大型模型的微调过程中扮演着关键角色。

1.2 知识图谱的应用价值
知识图谱的一个重要优势在于创建特定领域的本体,这与开发新的推理和推断方法密切相关。以往的研究已经建立了知识图谱的基础概念,包括创建这些图谱所使用的模型及其表示方法。
自动化知识图谱构建和表示学习已经定义了构建知识图谱的主要阶段:从知识获取和语义表解释,到实体提取------涵盖命名实体识别(NER)、命名实体消歧(NED)和命名实体链接(NEL)。这些研究提供了一个系统,能够将非结构化文本转换为有组织的相互关联实体语料库。
二、核心研究问题
研究团队提出了两个关键研究问题:
RQ1:句子建模能否有效地创建与其他方法相媲美的知识图谱?
通过英语语言的典型结构,可以通过动词使用和从句来提取关系。这为本研究提供了理论基础。
RQ2:使用句子语义方法的开源大语言模型能否可靠地从原始文本构建知识图谱?
研究团队将他们的方法与流行的闭源AI模型GPT-4系列进行了比较,后者以解析学术文献而闻名。他们设计了评估提示来将其性能与自己的方法进行基准测试。
三、主要贡献
3.1 创新性框架
本研究引入了一个新颖的句子语义框架,用于关系抽取(RE)和知识图谱构建,该框架借鉴了语言学理论和语义解析。虽然这个想法很常见,但据研究团队所知,在主流NLP信息提取管道中一直未得到充分探索。
该工作的创新之处在于整合了多个框架,而不仅仅是一个任务。该方法明确地将语义句子类型(例如,复杂句(CX)、复合句(CD)和复合-复杂句(CC)形式)建模为提取知识三元组的基础。每个三元组是一个简单的三部分结构(实体1,关系,实体2),用于在知识图谱中表示单个事实。
3.2 多样化提示策略
研究团队探索了整个管道中的多样化提示策略,包括:
-
思维链(Chain-of-Thought, CoT)推理
-
少样本上下文学习(Few-Shot In-Context Learning, FICL)
-
零样本通用指令提示(Zero-Shot General Instruction Prompting, GIP)
并通过实证研究展示了它们对结构分解的不同贡献。

3.3 开源资源套件
为支持这一架构,研究团队发布了一套开源资源:
1. 句子语义数据集(7,248行)
该数据集对多样化的句子语义进行分类和映射,与模型的分解策略保持一致(复杂句、复合句、复合-复杂句、简单句和不完整句)。
2. 共指消解黄金标准语料库(190个样本)
包含190篇来自PubMed的肺癌摘要,由四位领域专家标注。
3. 句子转换数据集(900个样本)
包含300个标注示例,分别用于将复杂句、复合句和复合-复杂句转换为简单、可提取的形式。
4. 机器生成的知识图谱语料库(超过150,000个三元组)
使用完整的端到端管道创建的结构化三元组。
四、句子语义建模理论基础
4.1 语法结构定义
句子语义建模涉及将句子组织成各种类型,这些类型构成了思想如何相互关联的结构。研究团队将语法结构定义为 G = (N, Σ, P, S),其中:
-
N 是有限的非终结符集合
-
Σ 是有限的终结符集合(语言中的实际单词或标记)
-
P 是有限的生产规则集合,描述非终结符如何扩展为非终结符和终结符的序列
-
S ∈ N 是起始符号,通常称为句子(Sentence)
4.2 英语句子类型
为了理解从句的相互作用以及它们如何构成句子,需要考虑英语语言中的句子类型:
简单句(Simple Sentences):只有一个独立从句,没有从属从句
- 形式表示:Ssimple = {(NP, VP) | NP ∈ N, VP ∈ V}
其中NP代表名词短语,VP代表动词短语。
五、CoDe-KG系统架构
5.1 系统概述
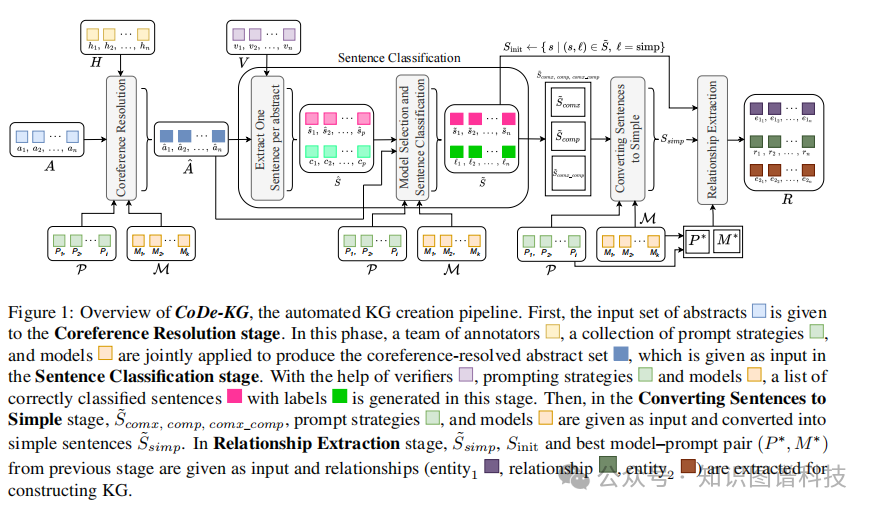
CoDe-KG是一个自动化知识图谱创建管道,用于从摘要中创建知识图谱。该方法包含四个关键阶段:
-
共指消解(Coreference Resolution)
-
句子分类(Sentence Classification)
-
句子转换(Converting Sentences to Simple)
-
关系抽取(Relationship Extraction)
5.2 阶段一:共指消解
在这个阶段,输入的摘要集合被提供给共指消解模块。标注团队、提示策略集合和模型共同应用,以生成共指消解后的摘要集合,作为句子分类阶段的输入。
共指消解是识别文本中指向同一实体的不同表达的过程。例如,在句子"研究人员开发了一个新系统。它表现出色。"中,"它"指的是"系统"。这个阶段确保了后续处理中实体引用的一致性。
5.3 阶段二:句子分类
在验证器、提示策略和模型的帮助下,该阶段生成带有标签的正确分类句子列表。系统能够识别句子的复杂度类型,包括简单句、复合句、复杂句和复合-复杂句。
5.4 阶段三:句子转换为简单句
在这个阶段,复杂句、复合句、复合-复杂句通过提示策略和模型被转换为简单句。这一步骤至关重要,因为简单句更容易进行准确的关系抽取。
5.5 阶段四:关系抽取
在关系抽取阶段,简单句、初始句子和从前一阶段获得的最佳模型-提示对作为输入,系统提取关系(实体1,关系,实体2)用于构建知识图谱。
六、评估数据集
研究团队在多个标准数据集上评估了CoDe-KG系统的性能:
6.1 REBEL数据集
研究团队采用了EDC模型中使用的相同的1,000个样本子集进行评估,这些样本最初来自REBEL测试分区的105,516个条目。REBEL是一个在EMNLP会议上发布的关系抽取基准数据集。
6.2 WebNLG+2020数据集
WebNLG+2020(v3.0版本)是一个包含文本-三元组对的语义解析基准。研究团队使用了其完整的测试集,包含1,165个样本,涵盖159种独特的关系类型。
6.3 Wiki-NRE数据集
Wiki-NRE是一个用于关系抽取的远程监督数据集。研究团队使用了EDC模型中相同的1,000对样本。该数据集包含29,619个条目,涵盖45种不同的关系类型。
6.4 CaRB数据集
CaRB数据集是开放信息抽取(OpenIE)的基准,通过改进人工判断重新标注原始OIE2016数据集创建而成。虽然论文中报告的是来自Amazon Mechanical Turk的1,282个句子的开发集,但在GitHub页面上发现了跨越172行的50个独特句子。
七、实验结果与性能表现
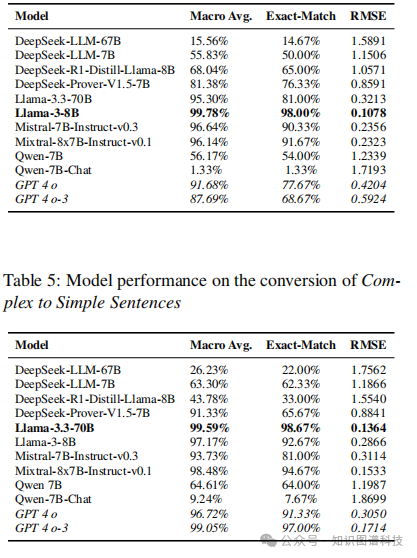
7.1 句子简化的准确性
系统性地选择了五个复杂度类别的最优提示-模型对,结果显示,混合思维链和少样本提示在句子简化任务上产生了高达99.8%的精确匹配准确率。
这一结果表明,通过适当的提示工程和模型选择,可以实现接近完美的句子简化性能,为后续的关系抽取奠定了坚实的基础。
7.2 关系抽取性能突破
在关系抽取任务上,CoDe-KG管道取得了显著的性能提升:
REBEL数据集
-
宏F1分数:65.8%
-
相比现有技术水平提升了8个百分点
WebNLG2数据集
-
微F1分数:75.7%
-
在保持或超越Wiki-NRE和CaRB性能的同时
7.3 消融研究结果
消融研究证明,整合共指消解和句子分解能够将稀有关系的召回率提高超过20%。这一发现凸显了系统各个组件协同工作的重要性。
八、技术优势与创新点
8.1 语言学理论驱动
CoDe-KG的核心创新在于将语言学理论深度整合到信息抽取管道中。通过明确建模句子的语义类型,系统能够更准确地理解和分解复杂的语言结构。
8.2 开源与可复现性
与许多依赖闭源模型的系统不同,CoDe-KG是完全开源的。所有代码和数据集都可以在GitHub上获取,这极大地促进了研究的可复现性和进一步发展。
项目地址:https://github.com/KaushikMahmud/CoDe-KG_EMNLP_2025
8.3 多层次的人工标注数据
研究团队不仅提供了机器生成的大规模数据集,还贡献了多个高质量的人工标注数据集,包括:
-
190个共指消解样本(由四位领域专家标注)
-
900个句子转换样本
-
398个黄金标准三元组
这些高质量的标注数据对于训练和评估未来的模型具有重要价值。
8.4 提示策略的系统性探索
研究团队系统性地探索了多种提示策略(CoT、FICL、GIP)及其组合,为不同任务找到了最优配置。这种方法论可以为其他NLP任务的提示工程提供参考。
九、应用场景与实际价值
9.1 学术研究支持
在生物医学领域,特别是肺癌研究中,CoDe-KG可以自动从大量PubMed文献中提取结构化知识,帮助研究人员快速发现疾病机制、治疗方法和药物相互作用等关键信息。
9.2 知识管理系统
企业和研究机构可以利用CoDe-KG构建特定领域的知识图谱,实现对非结构化文本数据的系统化管理和智能检索。这对于专利分析、竞争情报和技术监测等应用场景具有重要意义。
9.3 智能问答系统
基于CoDe-KG构建的知识图谱可以支持更准确的问答系统,特别是在需要理解复杂关系和进行多跳推理的场景中。
9.4 决策支持工具
对于投资人和决策者,从大量文档中自动提取的结构化知识可以帮助他们快速了解技术趋势、市场动态和风险因素,支持更明智的投资决策。
十、技术挑战与未来方向

10.1 跨语言扩展
当前的CoDe-KG主要针对英语文本设计。未来可以探索将该方法扩展到其他语言,特别是中文等形态学特征不同的语言,这将需要针对性的句法分析和分解策略。
10.2 实时处理能力
虽然系统在准确性上表现出色,但对于大规模实时应用场景,还需要进一步优化处理速度和计算效率。这可能涉及模型压缩、分布式计算等技术。
10.3 领域适应性
不同领域的文本具有不同的语言特点和知识结构。未来研究可以探索如何让CoDe-KG更好地适应不同领域,包括法律、金融、工程等专业领域。
10.4 知识图谱的动态更新
随着新信息的不断产生,如何高效地更新和维护知识图谱是一个重要挑战。未来可以研究增量学习和知识演化追踪方法。
十一、对研究界和产业界的启示
11.1 语言学理论的回归
CoDe-KG的成功表明,在深度学习时代,传统的语言学理论仍然具有重要价值。将语言学知识与现代机器学习方法相结合,可能是未来NLP发展的一个重要方向。
11.2 开源生态的重要性
通过开源代码和数据集,CoDe-KG为研究社区提供了宝贵的资源。这不仅促进了技术的快速传播,也为后续研究建立了坚实的基础。这种开放的研究范式值得更多研究团队借鉴。
11.3 系统工程的价值
CoDe-KG的成功不仅在于单个组件的性能,更在于整个系统的精心设计和各组件的协同工作。这提醒我们,在追求模型性能的同时,也要重视系统架构和工程实现。
11.4 评估方法的多样性
研究团队在多个不同的数据集上进行了全面评估,并进行了详细的消融研究。这种严谨的评估方法为AI系统的性能验证提供了良好的范例。
十二、结论
CoDe-KG代表了知识图谱自动构建领域的一个重要进展。通过将语言学理论、大语言模型和系统工程相结合,研究团队创建了一个高效、准确且完全开源的知识抽取管道。
系统在多个基准数据集上取得的卓越性能,特别是在REBEL数据集上相比现有技术8个百分点的提升,以及在稀有关系上超过20%的召回率提升,充分证明了该方法的有效性。
更重要的是,研究团队贡献的丰富开源资源------包括超过15万个知识三元组的数据集、7248行句子语义数据集、190个专家标注的共指消解样本、900个句子转换样本和398个黄金标准三元组------为研究社区提供了宝贵的资源,将推动该领域的进一步发展。
对于专业人士、企事业单位和科研院所而言,CoDe-KG不仅提供了一个可立即使用的工具,更重要的是展示了一种系统性的方法论,可以应用于各种领域特定的知识抽取任务。无论是用于学术研究、知识管理,还是决策支持,CoDe-KG都具有广阔的应用前景。