目录
一,认识模型
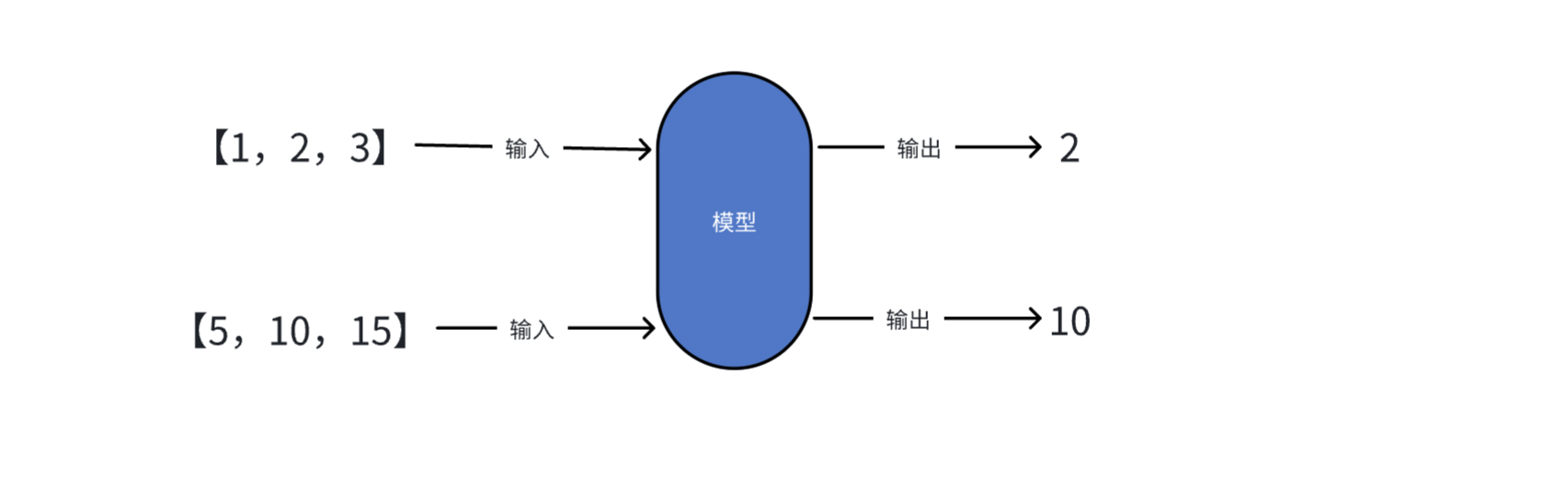
模型是一个从数据中学习规律的"数学函数"或"程序"。
从数学角度看,模型本质上是一个函数:
y = f(x)-
x:输入(特征、数据)
-
f:模型(学到的规律)
-
y:输出(预测、分类)
核心思想:从已知的 (x, y) 对中学习函数 f,然后用它预测新的 x 对应的 y。
也可以将模型理解为一个"超级加工厂",这个工厂是经过特殊训练的,训练师给它看了海量的例子(数据),并告诉它该怎么做。通过看这些例子,它自己摸索出了一套规则,学会了完成某个"特定任务"。模型就是一套学到的"规则"或者"模式",它能根据你给的东西,产生你想要的东西。
模型的关键点在于:
-
特定任务:一个模型通常只擅长一件事。比如:
-
⼀个模型专门识别图片里是不是猫。
-
一个模型专门预测明天会不会下雨。
-
⼀个模型专门判断一条评论是好评还是差评。
-
-
需要"标注数据":训练这种模型需要大量"标准答案"。(比如:成千上万张已经标注好"是
猫"或"不是猫"的图片)。
- 参数较少:参数是模型从数据中学到的"知识要点"或"内部规则"(比如:上述示例中的规则仅
是"中间数")。参数较少说明模型的复杂度和能力相对有限。
二,认识大语言模型
1.什么是大语言模型
大语言模型,也叫大模型(Large Language Model,LLMS),是指基于大规模神经网络,参数规模巨大,通过自监督或半监督的方式,对海量文本数据进行训练的语言模型。
名词解释:
1. 神经网络 :一个极其高效的"团队工作流程"或"条件反射链"。
例如教一个小朋友识别猫:
不会只给一条规则(比如"有胡子就是猫"),因为兔子也有胡子。我们会让他看很多猫的图片,他大脑里的视觉神经会协同工作:
有的神经元负责识别"尖耳朵",
有的负责识别"胡须",
有的负责识别"毛茸茸的尾巴"。
这些神经元一层层地传递和组合信息,最后大脑综合判断:"这是猫!"
神经网路就是模仿人脑的这种工作方式。
它由大量虚拟的"神经元"(也就是参数)和连接组成。
每个神经元都像一个小处理单元,负责处理一点点信息。无数个神经元分成很多层,前一层的输出作为后一层的输入。
通过海量数据的训练,这个网络会自己调整每个"神经元"的重要性(即参数的值),最终形成一个非常复杂的"判断流水线"。比如,一个识别猫的神经网络,某些参数可能专门负责识别猫的眼睛,另⼀些参数专门负责识别猫的轮廓。简单说:神经网络就是一个通过数据训练出来的、由大量参数组成的复杂 决策系统 。
2. 自监督学习 :"完型填空大师"
例如我们想学会一门外语,但没有老师给出题和批改。怎么办?
我们可以拿一本该语言的小说,自己玩"完形填空":随机盖住一个词,然后根据上下文猜测这个词是什么。一开始猜得乱七八糟。
但不断地重复这个过程,看了成千上万本书后,对这个语言的语法、词汇搭配、上下文逻辑了如指掌。现在不仅能轻松猜对被盖住的词,甚至能自己写出流畅的文章。
自监督学习就是这个过程。
模型面对海量的、没有标签的原始文本(比如互联网上的所有文章、网页)。
它自己给自己创造任务:把一句话中间的某个词遮住,然后尝试根据前后的词来预测这个被遮住的词。
通过亿万次这样的练习,模型就深刻地学会了语言的规律。它不需要人类手动去给每句话标注"这是主语"、"这是谓语"。
简单说:自监督就是让模型从数据本身找规律,自己给自己当老师。
3. 半监督学习 :"师父领进门,修行靠个人"
例如你想学做菜:
师傅先教你几道招牌菜(比如磨破豆腐、宫保鸡丁)⸺这相当于给了你一些 "有标注的数据"(菜谱和成品)。
然后,师傅让你去尝遍天下各种美食,自己研究其中的门道⸺这相当于接触海量的 "无标注数据" (各种未知的食材和味道)。
你结合师傅教的基本功和自己尝遍天下美食的经验,最终不仅能完美复刻招牌菜,还能创新出新的菜式。这就是"半监督"。
先用少量带标签的数据让模型"入门",掌握一些基本规则,然后再让它去海量的无标签数据中自我学习和提升。这对于大语言模型来说也是一种常用的训练方式。
简单说:半监督就是"少量指导+大量自学"的结合模式。
4.语言模型:一个"超级自动补全"或"语言预测器"。
例如你在用手机打字,输入"今天天气真",输入法会自动提示"好"、"不错"、"冷"等。这个输入法之所以能提示,就是因为它内部有一个小型的"语言模型",它根据你输入的前文,计算下一个词最可能是什么。
语言模型的核心任务就是预测下一个词。一个强大的语言模型,能够根据一段话,预测出最合理、最通顺的下一个词是什么,这样一个个词接下去,就能生成一整段话、一篇文章。
简单说:语言模型就是一个计算"接下来最可能说什么"的模型。
2.主流大语言模型
GPT-5 (OpenAI):支持400k 背景信息长度,128k 最大输出标记,在多轮复杂推理、创意写作中表现突出。
DeepSeek R1 (深度求索):开源,专注于逻辑推理与数学求解,支持128K长上下文和多语言(20+语言) ,在科技领域表现突出。
Qwen2.5-72B-Instruct (阿⾥巴巴) :通义千问开源模型家族重要成员,擅长代码生成结构化数据(如 JSON)处理角色扮演对话等,尤其适合企业级复杂任务,支持包括中文英文法语等 29 种语言。
Gemini 2.5 Pro (Google) :多模态融合标杆,支持图像/代码/文本混合输入,适合跨模态任务 (如图文你生成、技术文档解析)。
3.LLM的接入方式
问题:当我们自己构建AI应用时,无法直接使用其客户端。就需要通过代码的方式,接入原生LLM的能力。
各大厂商提供接入LLM的方式:【API接入】、【开源模型本地部署】、【SDK接入】。
API接入
通过 HTTP 请求(通常是 RESTful API)直接调用模型提供商部署在云端的模型服务。代表厂商:OpenAI (GPT-4o),Anthropic (Claude),Google (Gemini),百度文心一言,阿里通义千问,智谱 AI等。
典型流程就是:
-
注册账号并获取 API Key:在模型提供商的平台上注册,获得用于身份验证的密钥。
-
查阅 API 文档:了解请求的端点、参数(如模型名称、提⽰词、温度、最大生成长度等)和返回的数据格式。
-
构建 HTTP 请求:在你的代码中,使用 HTTP 客户端库(如 Python 的 requests )构建一个包含 API Key(通常在 Header 中)和请求体(JSON 格式,包含你的提示和参数)的请求。
-
发送请求并处理响应:将请求发送到提供商指定的 API 地址,然后解析返回的 JSON 数据,提取生成的文本。
以 OpenAI 为例,官网地址:https://platform.openai.com/
调用:
curl "https://api.openai.com/v1/responses" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-5",
"input": "Write a one-sentence bedtime story about a unicorn."
}'开源模型本地部署
大模型本地部署,这种方式就是将开源的大型语言模型(如 Llama、ChatGLM、Qwen 等)部署在你自己的硬件环境(本地服务器或私有云)中。核心概念就是,将下载模型的文件(权重和配置文件),使用转呢吧的推理框架在本地服务器或 GPU 上加载并运行模型,然后通过类似 API 的方式进行交互。
典型流程是:
-
获取模型:从 Hugging Face(国外)、魔搭社区(国内)等平台下载开源模型的权重。
-
准备环境:配置具有足够显存(如 NVIDIA GPU)的服务器,安装必要的驱动和推理框架。
-
选择推理框架:使用专为生产环境设计的框架来部署模型,例如:
-
vLLM:特别注重高吞吐量的推理服务,性能极佳。
-
TGI:Hugging Face 推出的推理框架,功能全面。
-
Ollama:非常用户友好,可以一键拉取和运行模型,适合快速入门和本地开发。
-
LM Studio:提供图形化界面,让本地运行模型像使用软件一样简单。
- 启动服务并调用:框架会启动一个本地 API 服务器(如 http://localhost:8000 ),你可以像调用云端 API 一样向这个本地地址发送请求。
以 Ollama 为例,下面是具体过程:
1.下载 Ollama
Ollama 官网: ollama.com
2.安装 Ollama
下载完成之后,一步一步安装即可。
3.验证
安装完成后,Ollama默认会启动

4.拉取模型
Ollama 可以管理和部署模型,我们使用之前,需要先拉取模型。
修改模型存储路径:模型默认安装在 C 盘个人目录下 C:\Users\XXX\.ollama ,可以修改 ollama 的模型存储路径,
使得每次下载的模型都在指定的目录下。有以下两种方式:
配置系统 环境变量
变量名: OLLAMA_MODELS
变量值: ${⾃定义路径}通过 Ollama 界面来进行设置
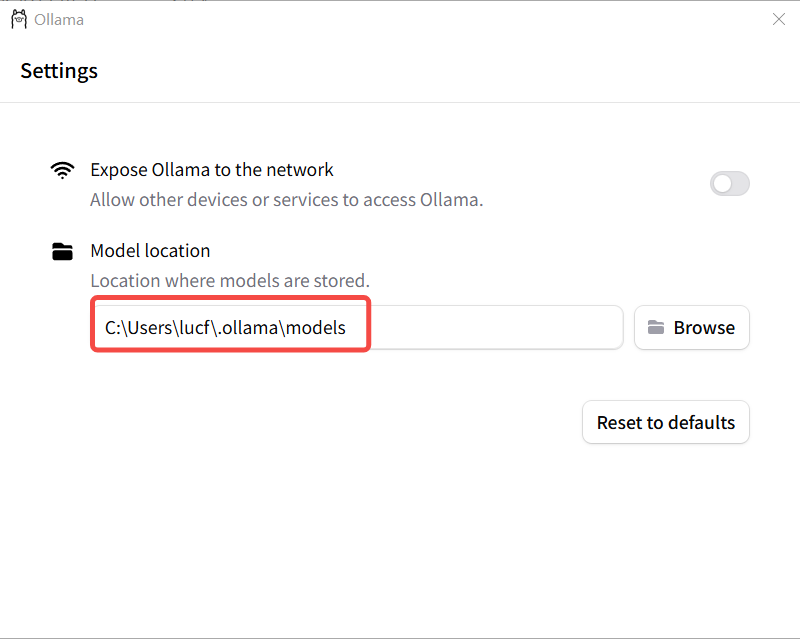
设置完成后,重启 Ollama 。
5.拉取模型
查找模型: https://ollama.com/search
以 DeepSeek-R1 为例, DeepSeek-R1 是一系列开放推理模型,其性能接近 O3 和 Gemini 2.5Pro 等领先模型。 DeepSeek-R1 有不同的版本,我们需要根据自己机器的配置及需求来选择相应的版本。
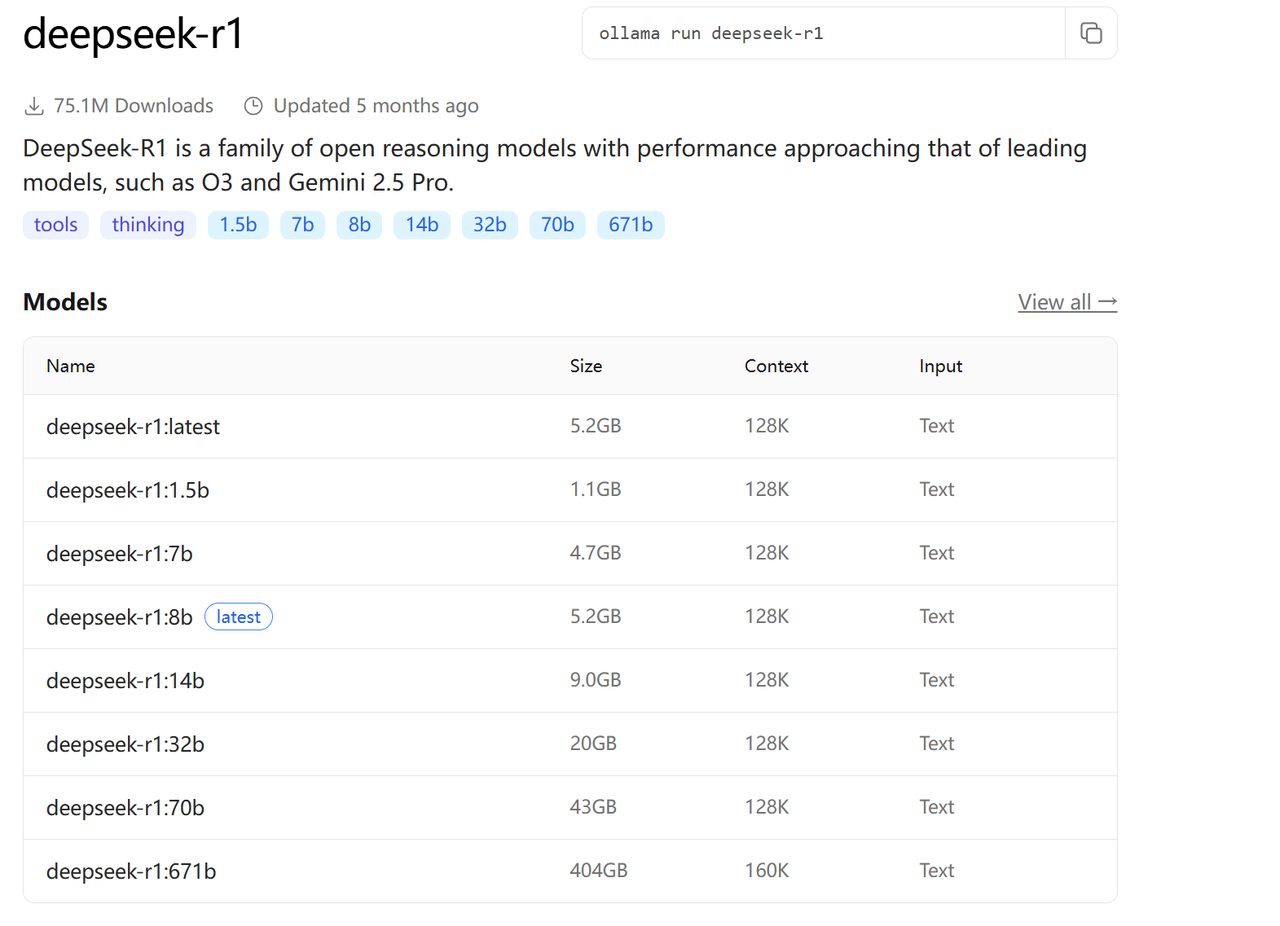
分为 1.5b , 7b , 8b 等,"b" 是 "Billion" (十亿) 的缩写,代表模型的参数量级。 671b表示"满血"版本,其他版本称为"蒸馏"版本。
参数越多 → 模型"知识量"越大 → 处理复杂任务的能力越强,硬件需求也越高。
根据需求及电脑配置,选择合适的模型版本,以 1.5b 为例:
ollama run deepseek-r1:1.5b
SDK接入
SDK接入的方式,本质是对API的封装,以类的形式提供给我们使用。
安装库
pip install openai示例代码
#SDK接入大模型
from openai import OpenAI
client=OpenAI(api_key="your-api-key")
response=client.responses.create(
model="gpt-4o-mini",
input="介绍一下你自己"
)
print(response.output_text)三,认识嵌入模型
1.什么是嵌入式模型
大语言模型是生成式模型。它理解输入并生成新的文本(回答问题、写文章)。它内部实际上也使用嵌入技术来理解输入,但最终目标是"创造"。
而嵌入模型(Embedding Model)是表示型模型。它的目标不是生成文本,而是为输入的文本创建一个最佳的、富含语义的数值表示(向量)。
由于计算机天生擅长处理数字,但不理解文字、图片的含义。嵌入(Embedding)的核心思想就是将人类世界的符号(如单词、句子、产品、用户、图片)转换为计算机能够理解的数值形式(即向量,本质上是⼀个数字列表),并且要求这种转换能够保留原始符号的语义和关系。
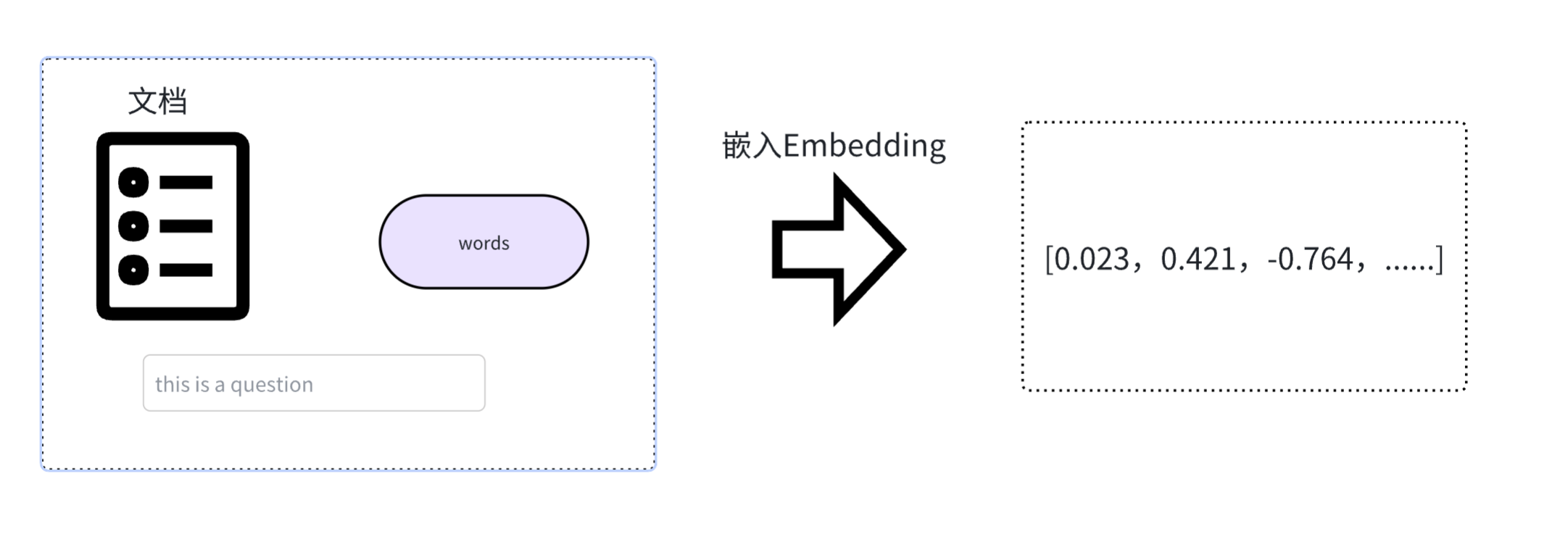
我们可以把它想象成一个翻译过程,把人类语言"翻译"成计算机的"数学语言"。
结论:既然是"数学语言 ",那么我们可以用数学的方式来比较向量,从而达到【度量语义】的目的!
2.嵌入式模型应用场景
根据嵌入的特性,由此延伸出了许多嵌入模型在 AI 应用的使用场景:
- 语义搜索(Semantic Search)
传统搜索:依赖关键词匹配(搜 "苹果" ,只能找到包含 "苹果" 这个词的文档)。
语义搜索:则能将查询和文档都转换为向量,通过计算向量间的相似度来找到相关内容,即使文档中没有查询的确切词汇也能被检索到。
- 检索增强生成(Retrieval-Augmented Generation, RAG)
这是当前大预言模型应用的核心模式。当用户向 LLM 提问时,系统首先使用嵌入模型在知识库(如公司内部文档)中进行语义搜索,找到最相关的内容,然后将这些内容和问题一起交给 LLM 来生成答案。这极大地提高了答案的准确性和时效性。
例如:一家公司的内部客服机器人接到员工提问: "我们今年新增加的带薪育儿假政策具体是怎样的?" 系统会首先使用嵌入模型在公司的最新人事制度文档、福利更新备忘录等资料中进行语义搜索,找到关于 "今年育儿假规定" 的具体条款,然后将这些【条款】和【问题】一起提交给 LLM,LLM 便能生成一个准确、具体的摘要回答,而非仅凭其内部训练数据可能产生的过时或泛泛的答案
- 推荐系统(Recommendation Systems)
将用户(根据其历史行为、偏好)和物品(商品、电影、新闻)都转换为向量。喜欢相似物品的用户,其向量会接近;相似的物品,其向量也会接近。通过计算用户和物品向量的相似度,就可以进行精准推荐。
例如:⼀个流媒体平台将用户 A(喜欢观看《盗梦空间》和《⿊镜》)和所有电影都表示为向量。系统发现用户 A 的向量与那些也喜欢《盗梦空间》和《⿊镜》的用户向量很接近,而这些用户普遍还喜欢《星际穿越》。尽管用户A从未看过《星际穿越》,但通过计算用户向量与电影向量的相似度,系统会将这部电影推荐给用户 A。
- 异常检测(Anomaly Detection)
正常数据的向量通常会聚集在一起。如果一个新数据的向量远离大多数向量的聚集区,它就可能是一个异常点(如垃圾邮件、欺诈交易)。
例如:一个信用卡交易反欺诈系统,通过学习海量正常交易记录(如金额、地点、时间、商户类型等特征的向量)
形成了"正常交易"的向量聚集区。当一笔新的交易发生时,系统将其转换为向量。如果该向量出现在"正常聚集区"
之外(例如,一笔发生在通常消费地之外的高额交易),系统则会将其标记为潜在的欺诈交易并进行警报。