目录
- [1 为什么要进行实例探究?](#1 为什么要进行实例探究?)
- [2 经典网络](#2 经典网络)
- [3 残差网络](#3 残差网络)
- [4 残差网络为什么有用?](#4 残差网络为什么有用?)
- [5 网络中的网络以及1x1卷积](#5 网络中的网络以及1x1卷积)
- [6 谷歌Inception网络简介](#6 谷歌Inception网络简介)
- [7 Inception网络](#7 Inception网络)
- [8 使用开源的实现方案](#8 使用开源的实现方案)
- [9 迁移学习](#9 迁移学习)
- [10 数据扩充(增强)](#10 数据扩充(增强))
1 为什么要进行实例探究?
接下来我们来看一些卷积神经网络的实例分析,为什么要看这些实例分析呢?之前我们讲了卷积神经网络的基本构件,比如卷积层、池化层以及全连接层这些组件,事实上,过去几年,计算机视觉的大量研究都集中在如何把这些基本构件组合起来形成有效的卷积神经网络,找感觉的最好的方法之一就是去看一些案例,就像很多人通过看别人的代码来学习编程一样,通过研究别人构建的有效的组件的案例是一个不错的方法。
实际上,在计算机视觉任务中表现良好的神经网络框架往往也适用于其他任务,也就是说,如果有人已经训练或者计算出擅长识别猫、狗、人的神经网络或者神经网络框架,而你的任务是构建一个自动驾驶汽车,你完全可以借鉴别人的神经网络框架来解决自己的问题。
一下是一些很经典的视觉神经网络的实例,之后我们会一一去探讨学习,看看从这些网络中可以学习到什么东西或者受到哪些启发。

2 经典网络
下面我们来学习几个经典神经网络结构,包括LeNet-5网络、AlexNet和VGGNet。
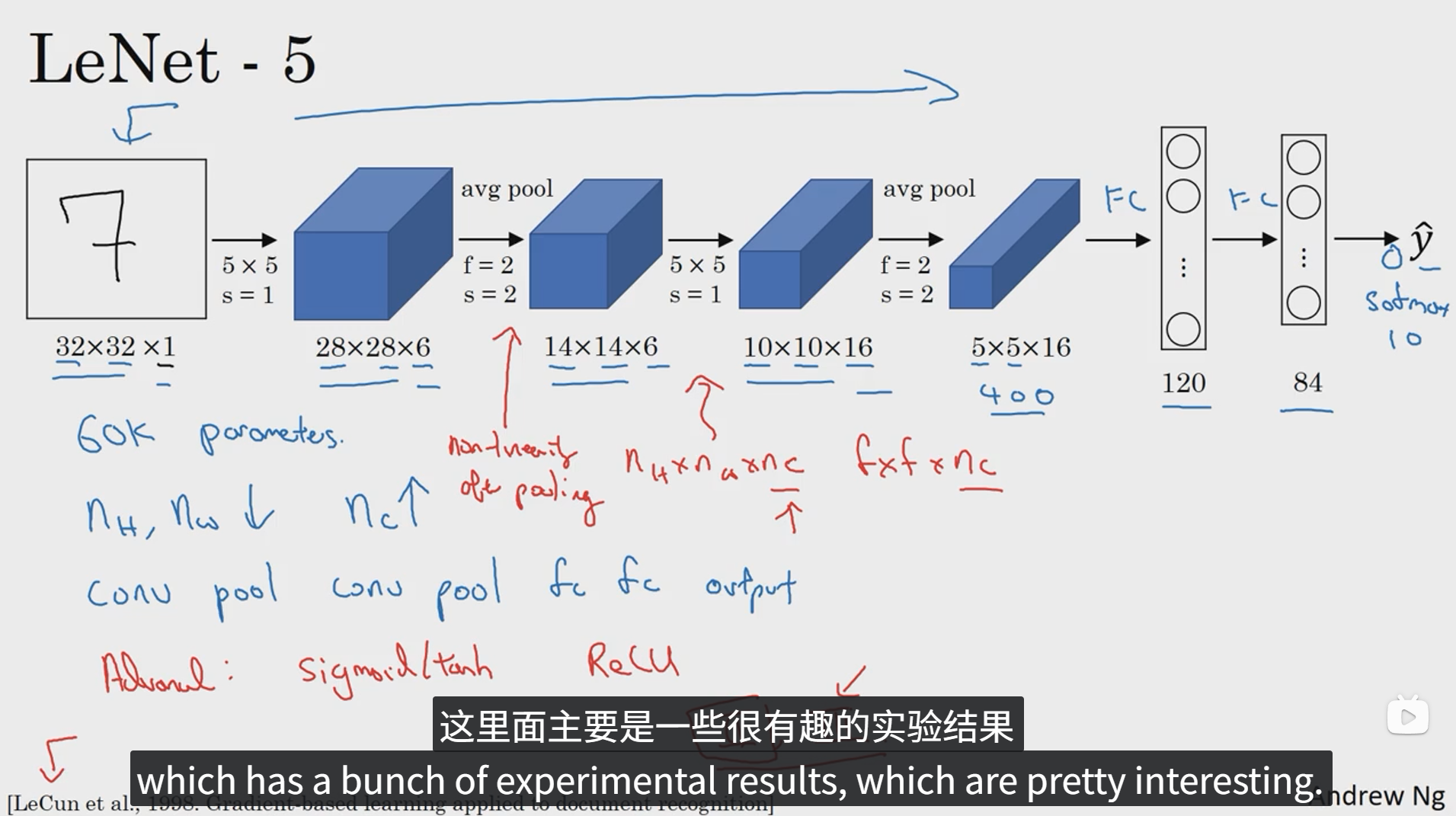
LeNet-5网络
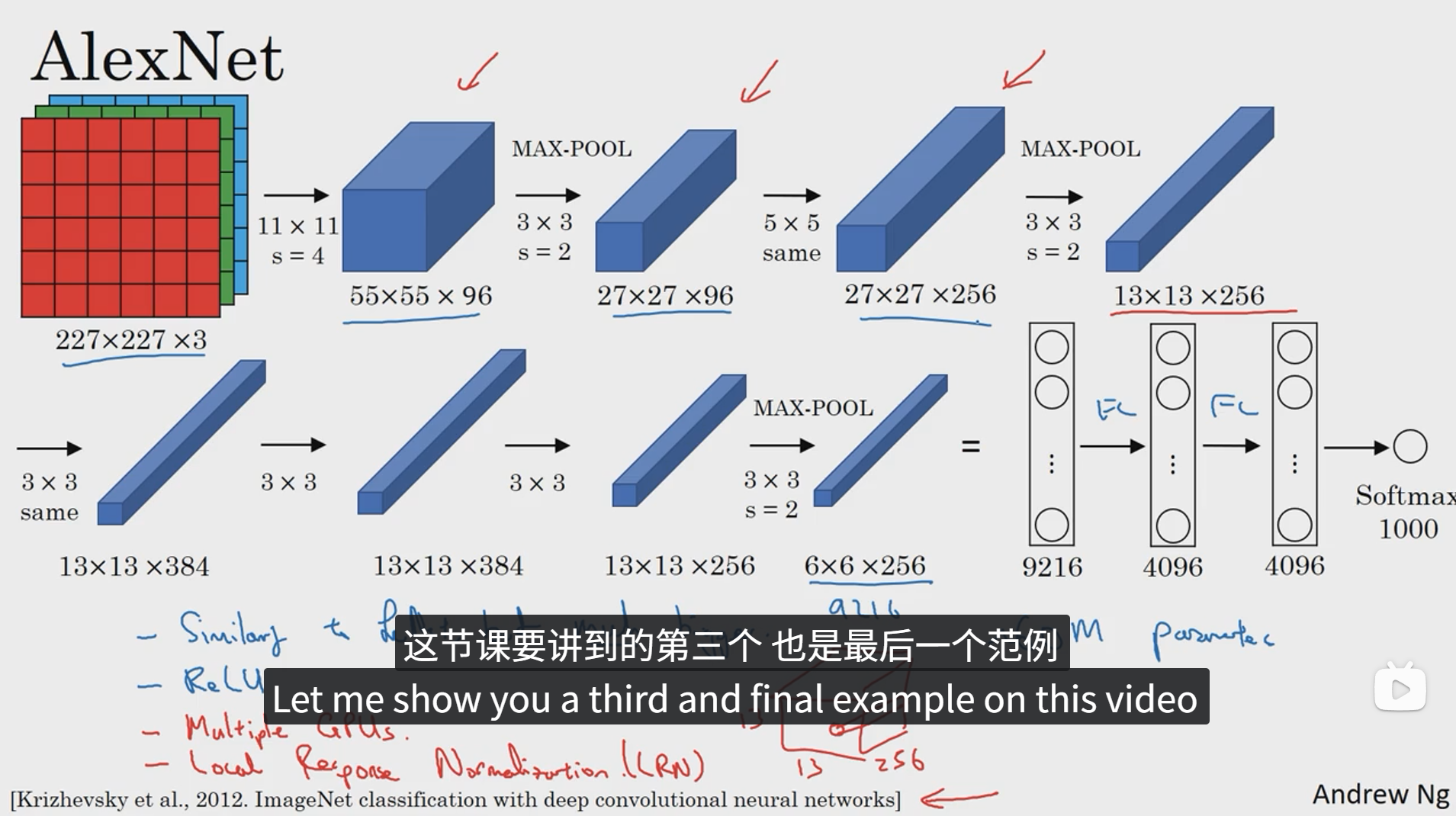
AlexNet
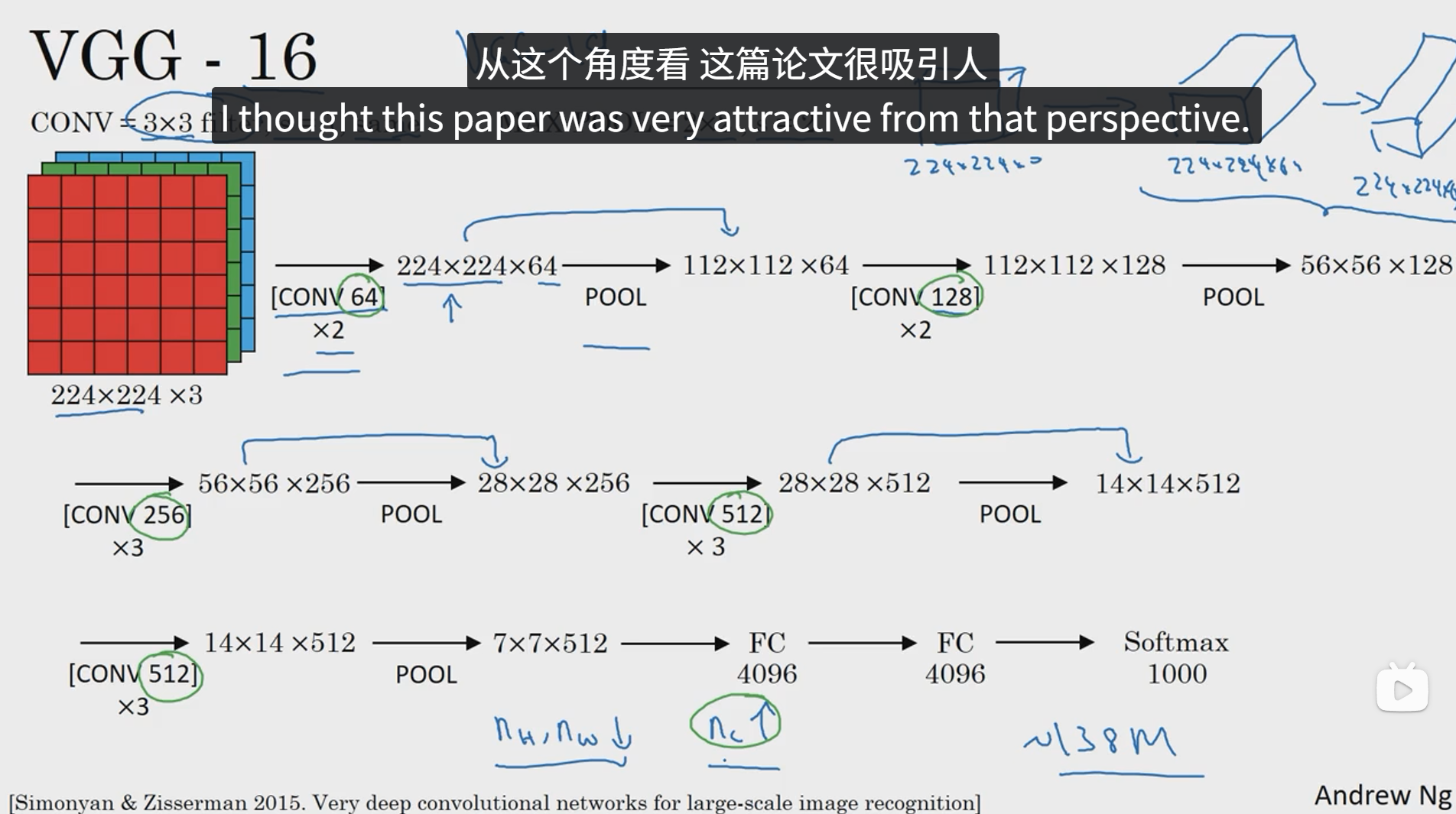
VGGNet
3 残差网络
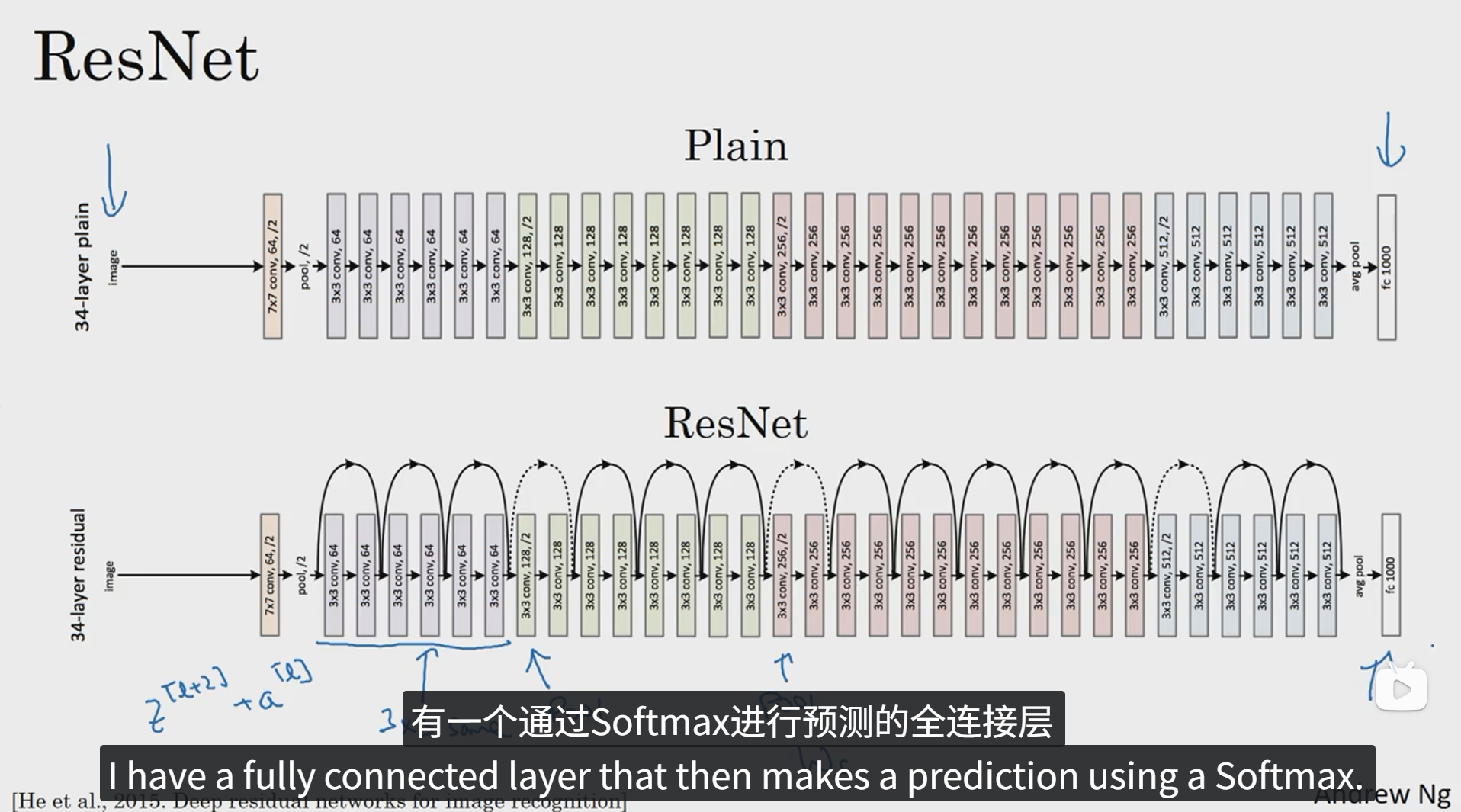
非常非常深的网络是很难训练的,因为存在梯度消失和梯度爆炸的问题,下面我们看一下远跳连接,它可以从某一网络层获取激活,然后迅速反馈给另外一层,甚至是神经网络的更深层,我们可以利用远跳连接构建能够训练深度网络的ResNets,有时候深度能超过100层。
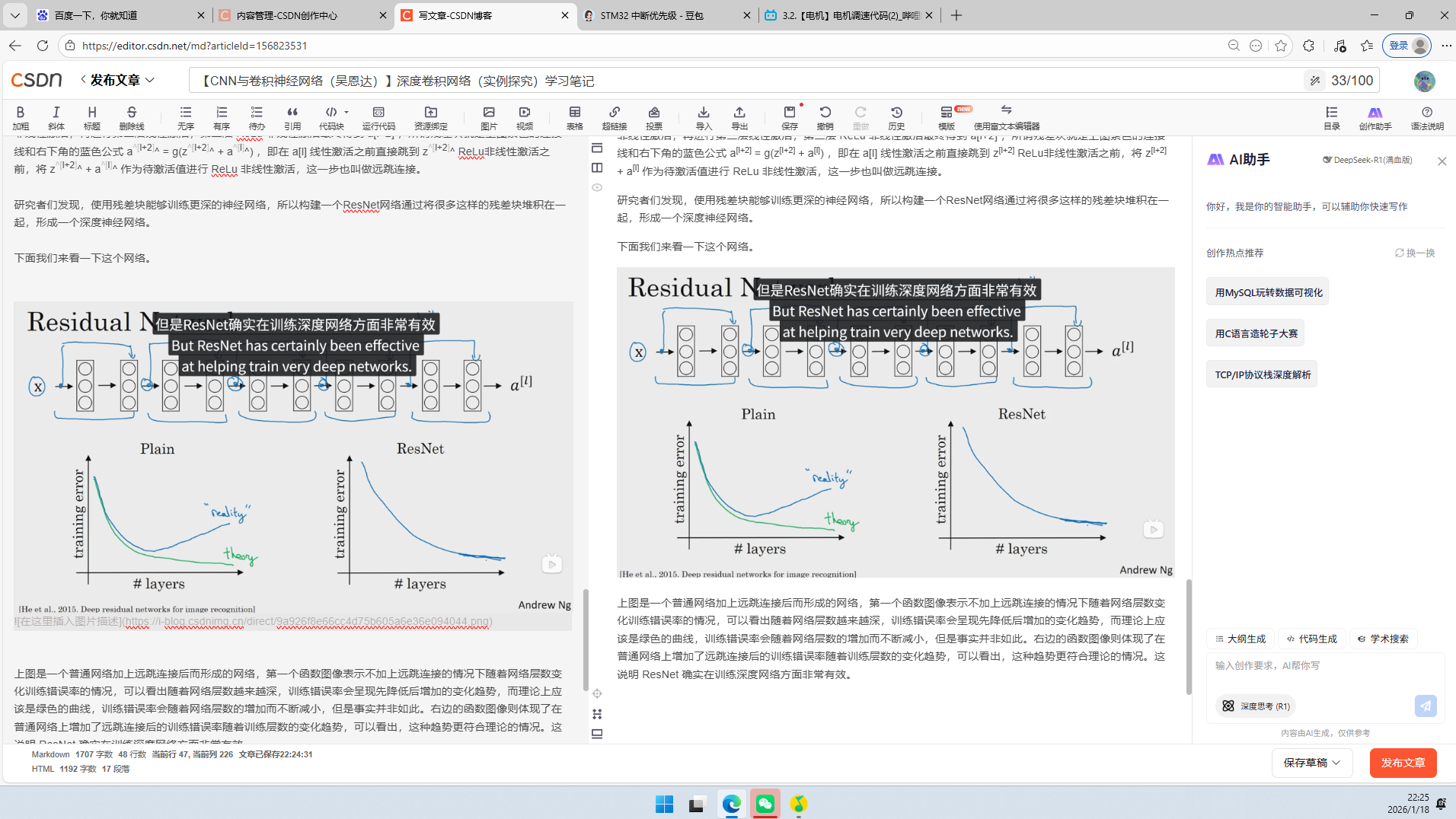
ResNets是由残差块构建的,首先解释一下什么是残差块。这是一个在 l 层激活的两层神经网络,得到 al+1 再次进行激活,两层之后得到al+2。
从上面途中可以看到,下边的黑色字体的公式是正常的前向传播的过程,即 al 通过第一层线性激活,第一层 ReLu 非线性激活,再进行第二层线性激活,第二层 ReLu 非线性激活最终得到 al+2 ,所谓残差块就是上图紫色的连接线和右下角的蓝色公式 a[l+2] = g(z[l+2] + a[l]) ,即在 al 线性激活之前直接跳到 z[l+2] ReLu非线性激活之前,将 z[l+2] + a[l] 作为待激活值进行 ReLu 非线性激活,这一步也叫做远跳连接。
研究者们发现,使用残差块能够训练更深的神经网络,所以构建一个ResNet网络通过将很多这样的残差块堆积在一起,形成一个深度神经网络。
下面我们来看一下这个网络。
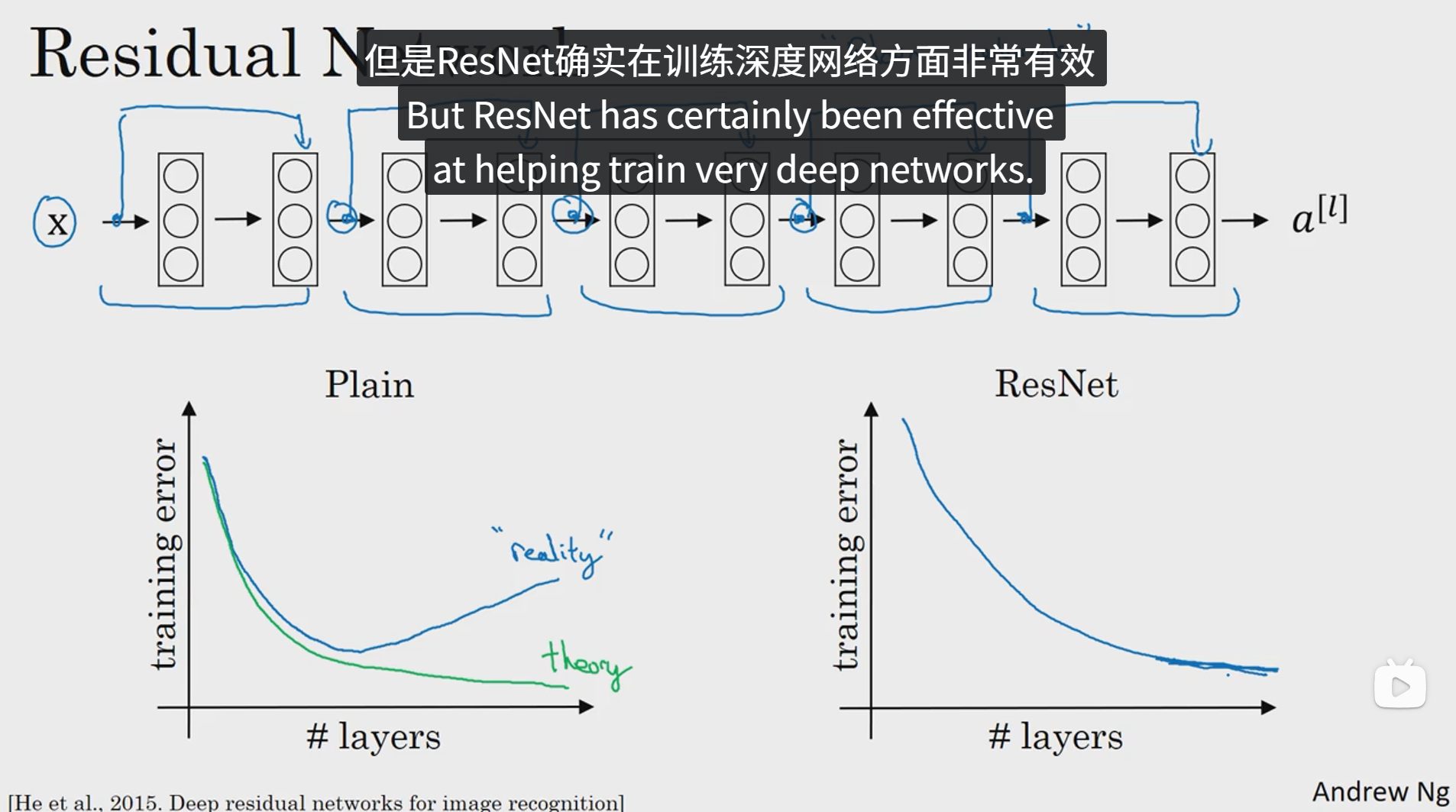
上图是一个普通网络加上远跳连接后而形成的网络,第一个函数图像表示不加上远跳连接的情况下随着网络层数变化训练错误率的情况,可以看出随着网络层数越来越深,训练错误率会呈现先降低后增加的变化趋势,而理论上应该是绿色的曲线,训练错误率会随着网络层数的增加而不断减小,但是事实并非如此。右边的函数图像则体现了在普通网络上增加了远跳连接后的训练错误率随着训练层数的变化趋势,可以看出,这种趋势更符合理论的情况。这说明 ResNet 确实在训练深度网络方面非常有效。
4 残差网络为什么有用?
为什么 ResNet 能够有如此好的表现呢?让我们来看一个例子,它解释了其中的原因,至少可以说明,如何在构建更深层次的ResNet网络的同时还不降低它们在训练集上的效率。
在之前我们讲到,一个网络越深,它在训练集上的训练网络的效率会有所减弱,这也是有时候我们不希望加深网络的原因,而事实并非如此,至少在训练ResNet网络时,并不完全如此。举个例子。
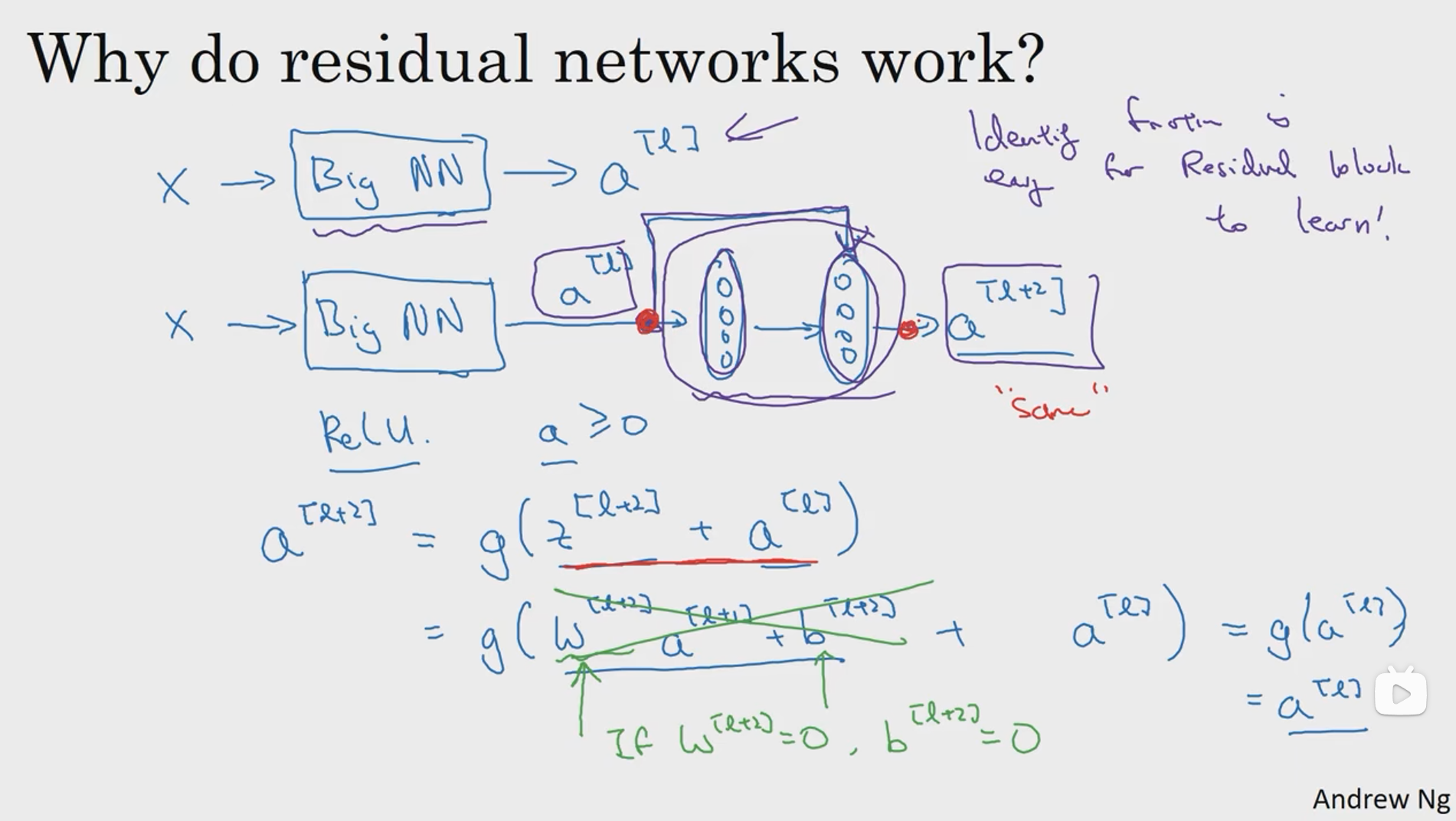
以上是一个普通的两层网络增加了一层远跳连接的例子,在这里我们将残差块的计算过程写出来并且展开可以得到 a[l+2] = g(z[l+2] + a[l]) = g(w[l+2]a[l+1] + b[l+2] + a[l]) ,在这里,我们如果设 w[l+1] = 0、b[l+2] = 0,我们就可以得到a[l+2] = g(a[l]) = a[l]。从以上计算过程可以看出,加上残差块,那么如果在某一层训练权值矩阵和偏置矩阵因为某些原因为0的时候,输出结果最差也会保留所加入的残差块的效果,并不会直接为0。由此可以得出,加上残差块,训练效果最差也是性能不增长,网络的训练成果并不会直接消失。因此就提升了整个网络的训练效率。
5 网络中的网络以及1x1卷积
1x1卷积所实现的功能是遍历这36个单元格,计算左图中32个数字和过滤器中32个数字的元素智能乘积,然后应用ReLU非线性函数。
我们以其中一个单元格为例,它是这个输入层上的某个切片,用这32个数字乘以这个输入层上1x1的切片得到一个实数。这个1x1x32过滤器中的32个数字可以这样理解,一个神经元的输入是32个数字乘以相同高度和宽度上某个切片上的32个数字,这32个数字具有不同信道,乘以32个权重 然后应用ReLU非线性函数,在这里输出相应的结果。
一般来说,如果过滤器不止一个,就好像有多个输入单元,其输入内容为一个切片上所有数字,输出结果是6x6x过滤器数量。


6 谷歌Inception网络简介
构建卷积层时,你要决定过滤器的大小究竟是1x3、3x3还是5x5,或者要不要添加池化层,而Inception网络的作用就是代替你来做决定,虽然网络架构因此变得更加复杂,但网络表现却非常好,下面我们来了解一下其中的原理。
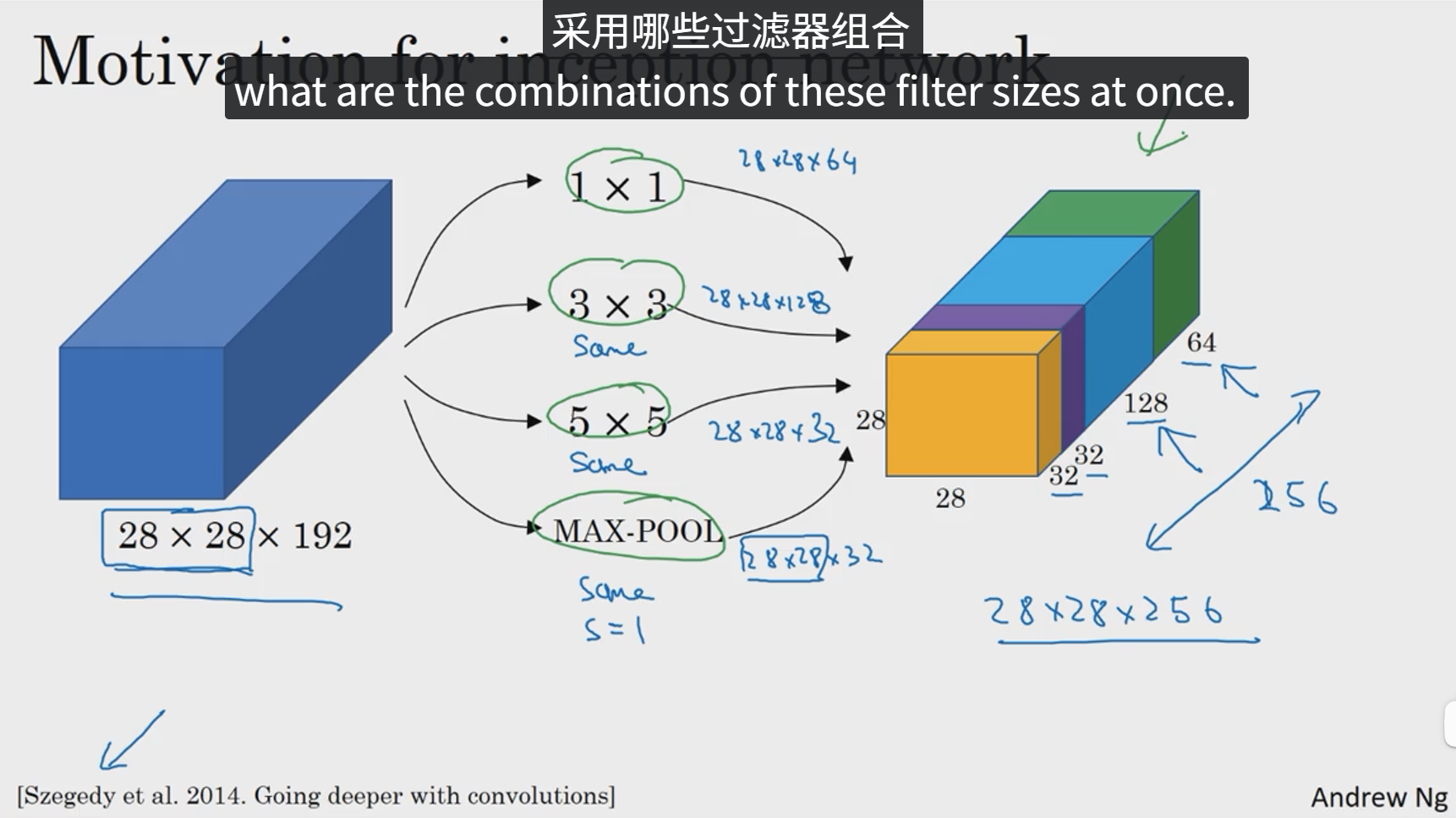
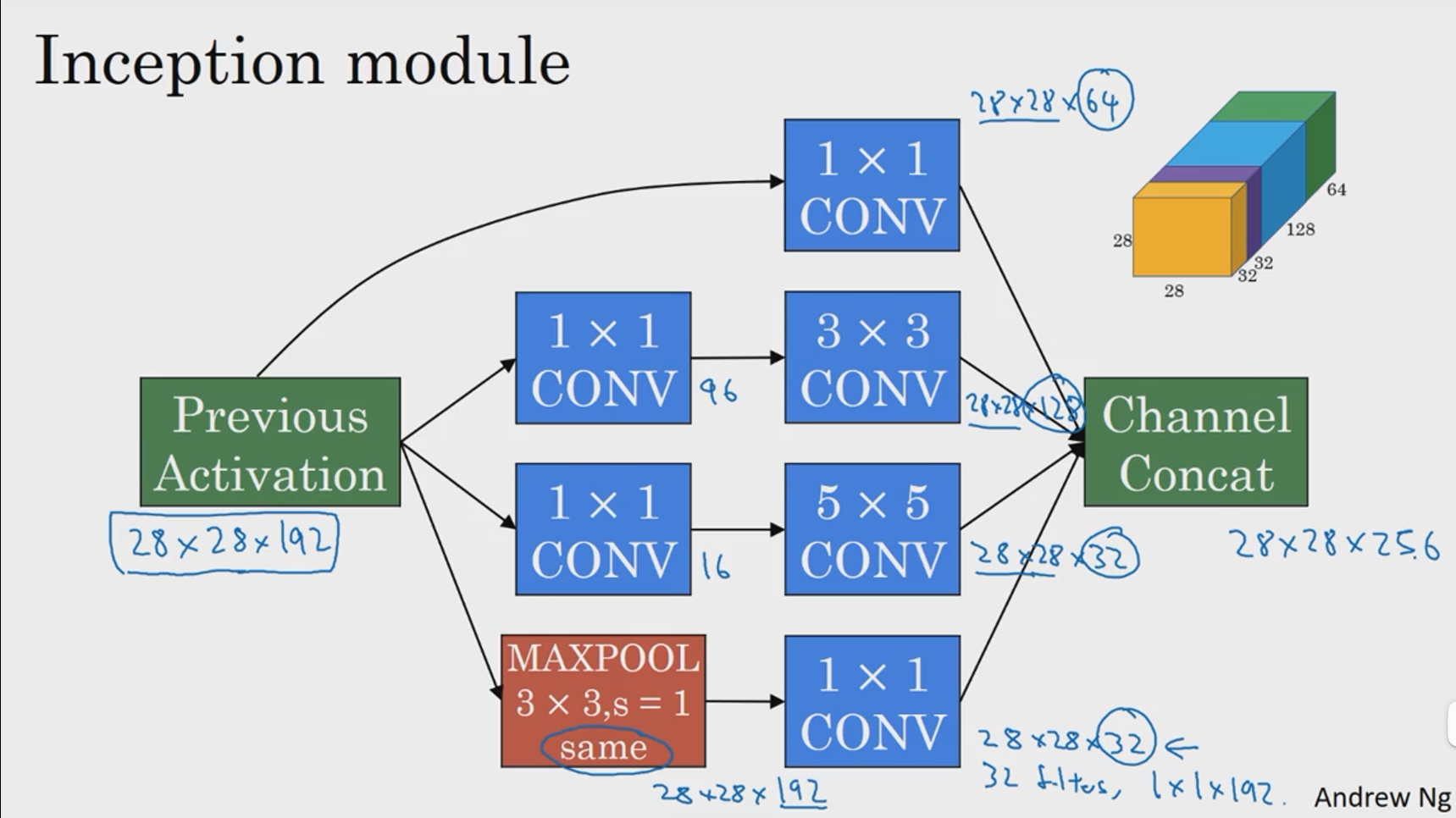
这是28x28x192维度的输入层,Inception网络或Inception层的作用就是代替人工来确定卷积层中的过滤器类型或者确定是否需要创建卷积层或池化层。
基本思想是Inception网络不需要人为决定使用哪个过滤器或是否需要池化,而是由网络自行确定这些参数,你可以给网络添加这些参数的所有可能值然后把这些输出连接起来,让网络自己学习它需要什么样的参数,采用哪些过滤器组合。
下面,我们就来计算这个5x5过滤器在该块中的计算成本。
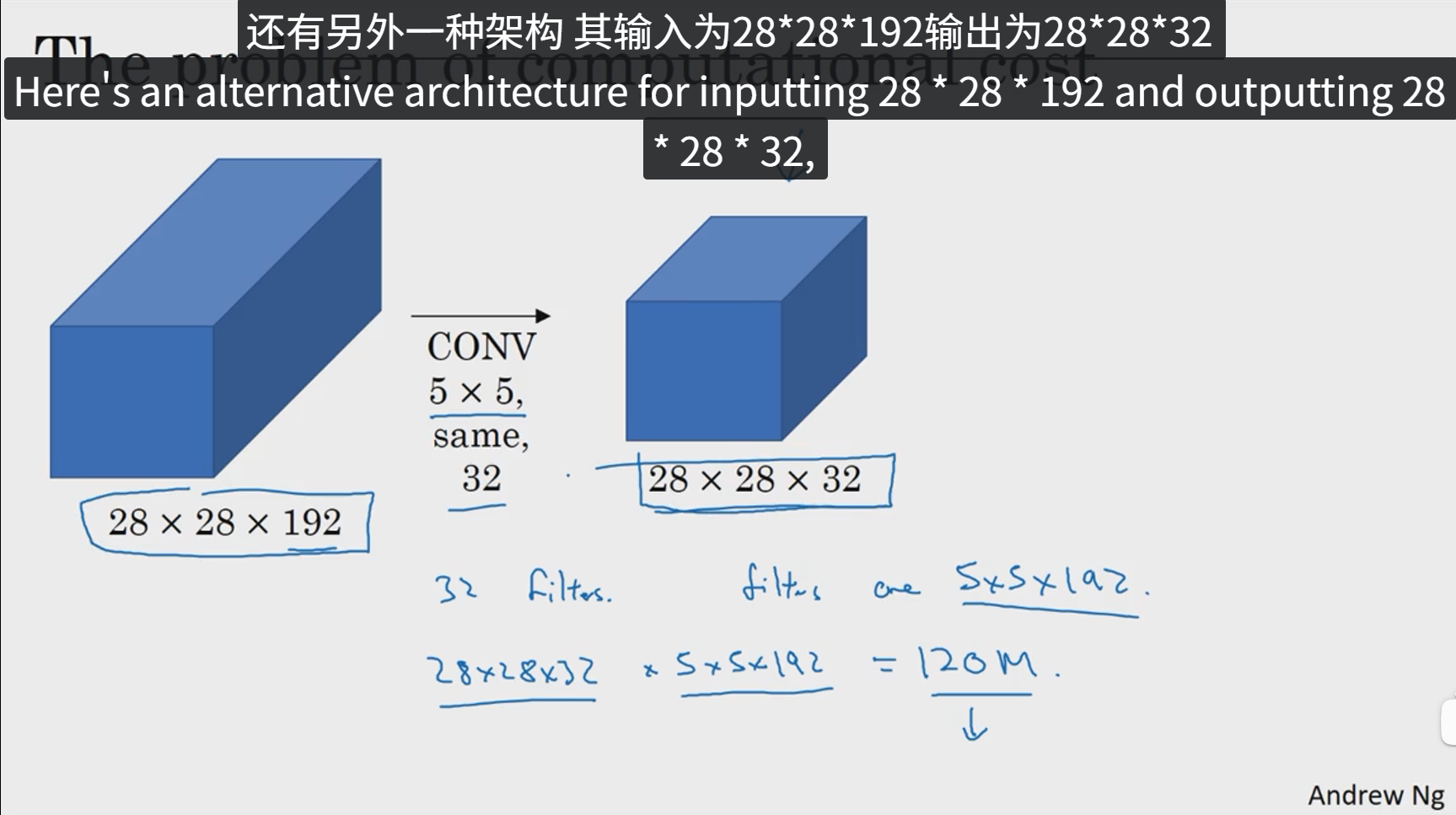
由上面计算过程可以得出,普通的5x5卷积核如果进行以上卷积操作的计算成本为120M次,然后我们采用1x1卷积试试。
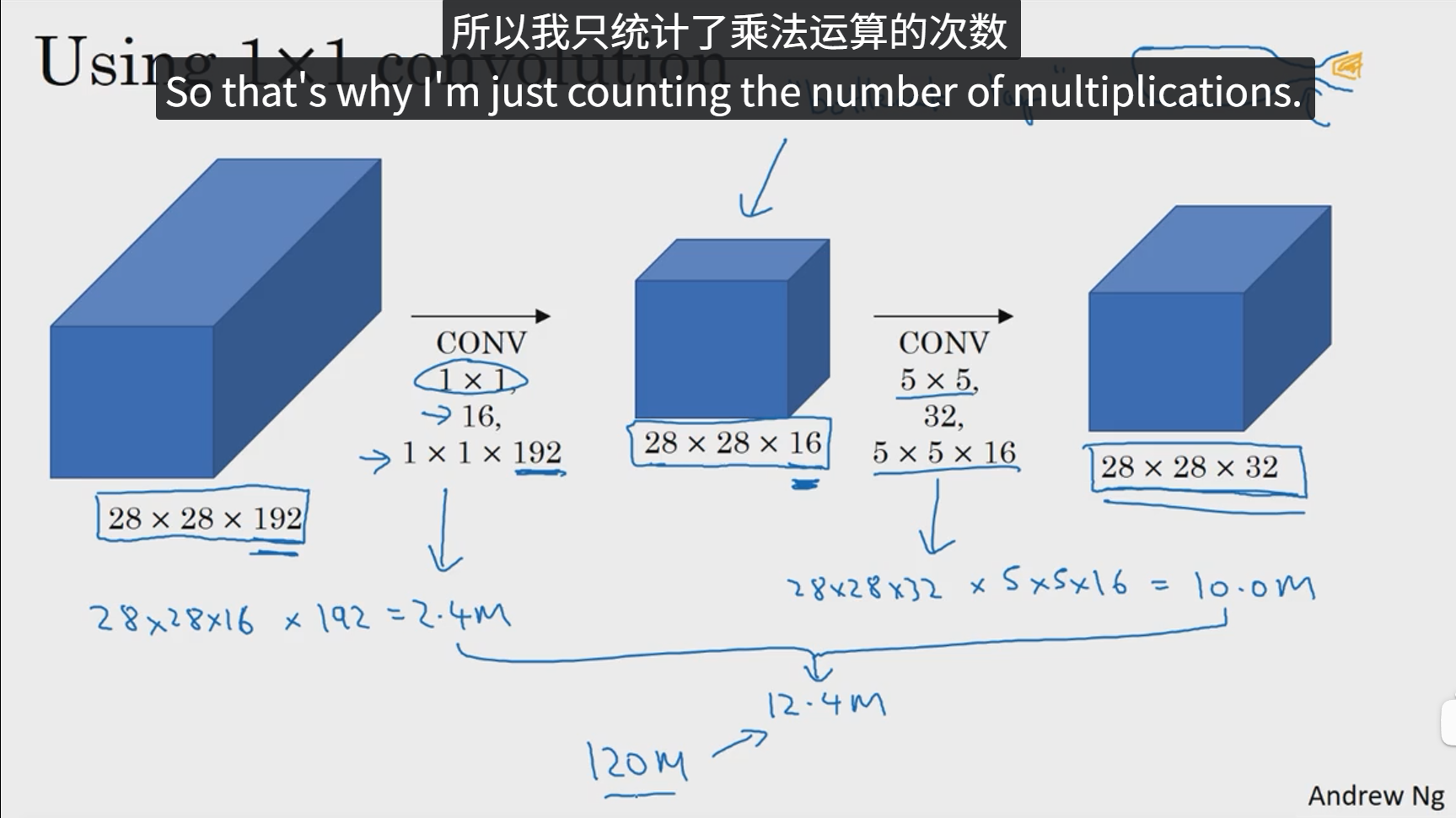
由此可以看出,1x1卷积把原来的图像通道进行了压缩,然后在压缩后的图像进行5x5卷积,这样我们把这两部分运算次数求出来并且加和,可以发现,最终的计算次数仅为12M,计算成本相比之前缩小了10倍,中间那层我们也称之为瓶颈层。
7 Inception网络
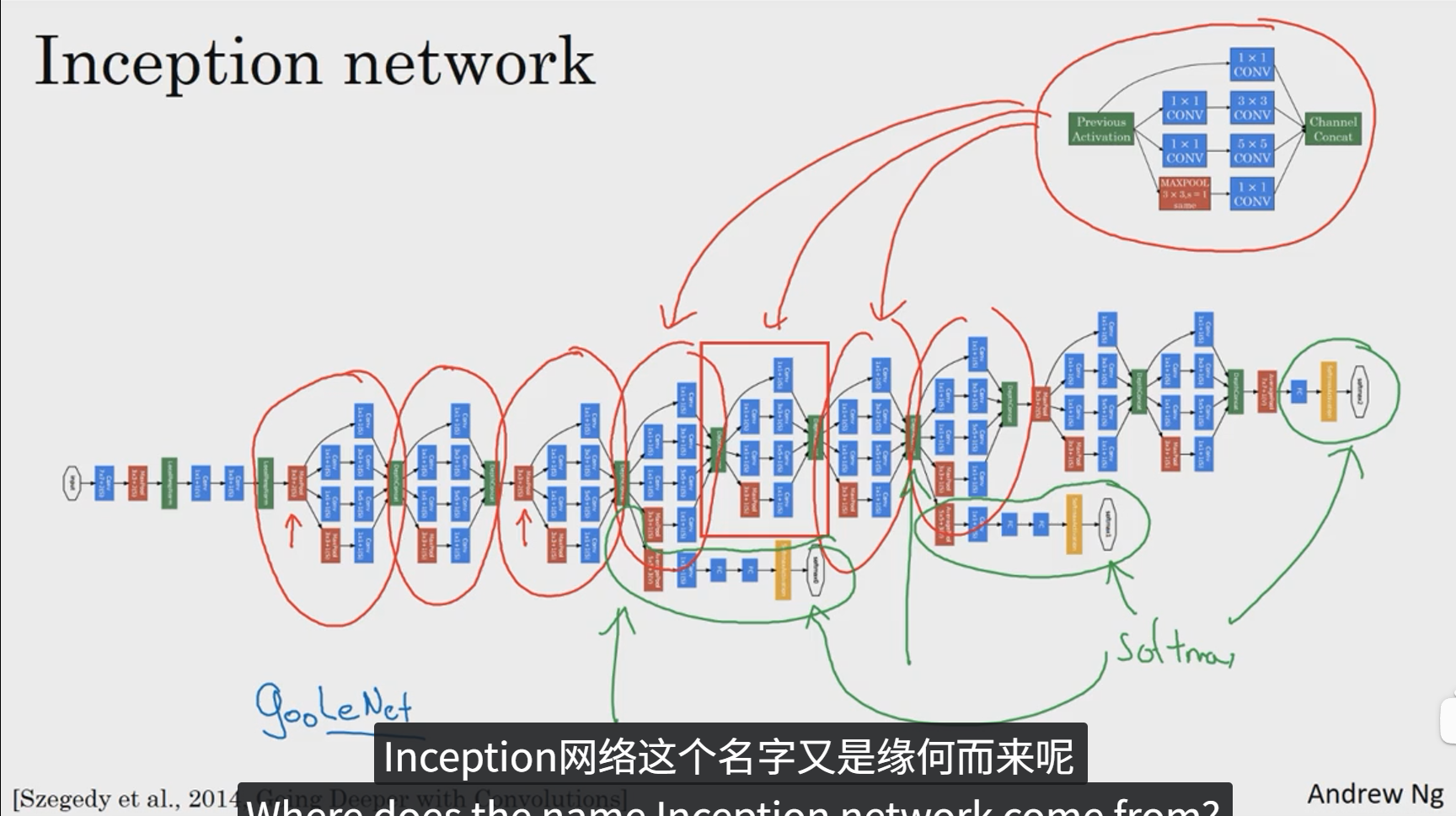
8 使用开源的实现方案
事实证明,很多神经网络复杂细致,因而难以复制,因为一些参数调整的细节问题,例如学习率衰减等等,会影响性能,所以我们发现有些时候,甚至在顶尖大学学习AI或者深度学习的博士生也很难通过阅读别人的研究论文来复制他人的成果,幸运的是有很多深度学习的研究者都习惯把自己的成果作为开发资源放在像GitHub之类的网站上,当我们自己编写代码的时候,我们应该考虑一下贡献给开源社区。如果你看到一篇研究论文,想要应用它的研究成果,你应该考虑一件事,在网络上寻找一个开源的实现,因为你如果能得到作者的实现,通常要比你从头开始实现的要快得多,虽然从零开始实现,肯定可以是一个很好的锻炼。
从开源社区上下载源码的好处是,有时候有些网络通常都需要很长的时间来训练,或许有人已经使用多个GPU通过庞大的数据集预先训练了这些网络,这样一来你就可以使用这些网络进行迁移学习。
9 迁移学习
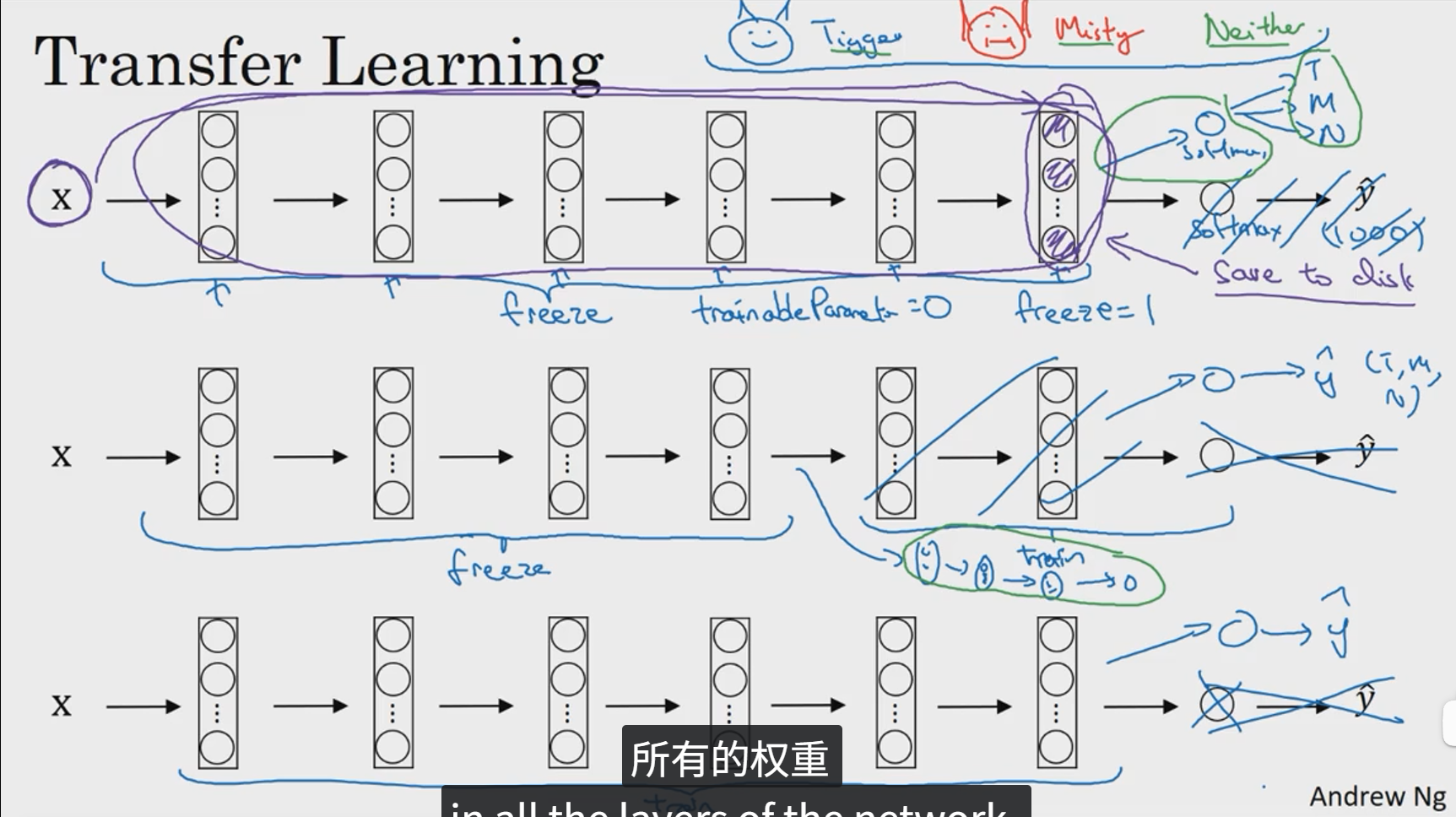
如果你想要做一个计算机视觉的应用,相比于从头训练权重,或者说从随机化权重开始,如果你下载别人已经训练好的权重,你通常能够进展的相当快,用这个作为预训练转换到你感兴趣的任务上。
如果你有一个更大的数据集,那么不要单单训练一个softmax单元,而是考虑训练中等大小的网络,包含你最终要用的网络的后面几层。如果你有大量数据,你应该做的就是用开源的网络和它的权重,把整个的当做初始化,然后训练整个网络。
10 数据扩充(增强)
大部分的计算机视觉任务使用很多的数据,所以数据增强是一种很好的方法用来提高计算机视觉系统的表现。
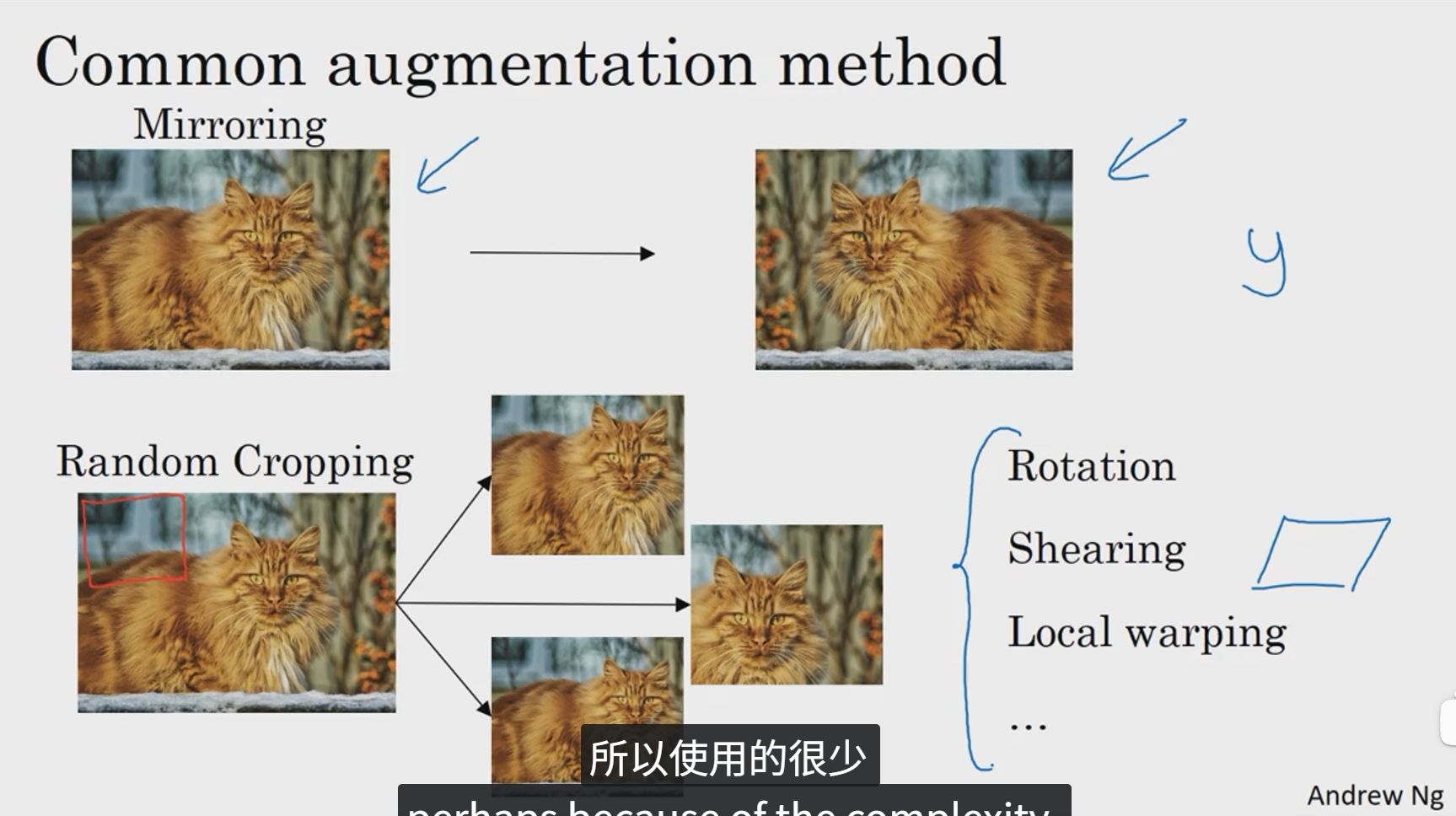
第一种数据增强方法就是垂直镜像对称。另一种数据增强操作是随即裁剪。理论上,也可以旋转、剪切图像,可以对图像进行各种各样的扭曲变换。
第二种经常使用的方法是色彩转换。
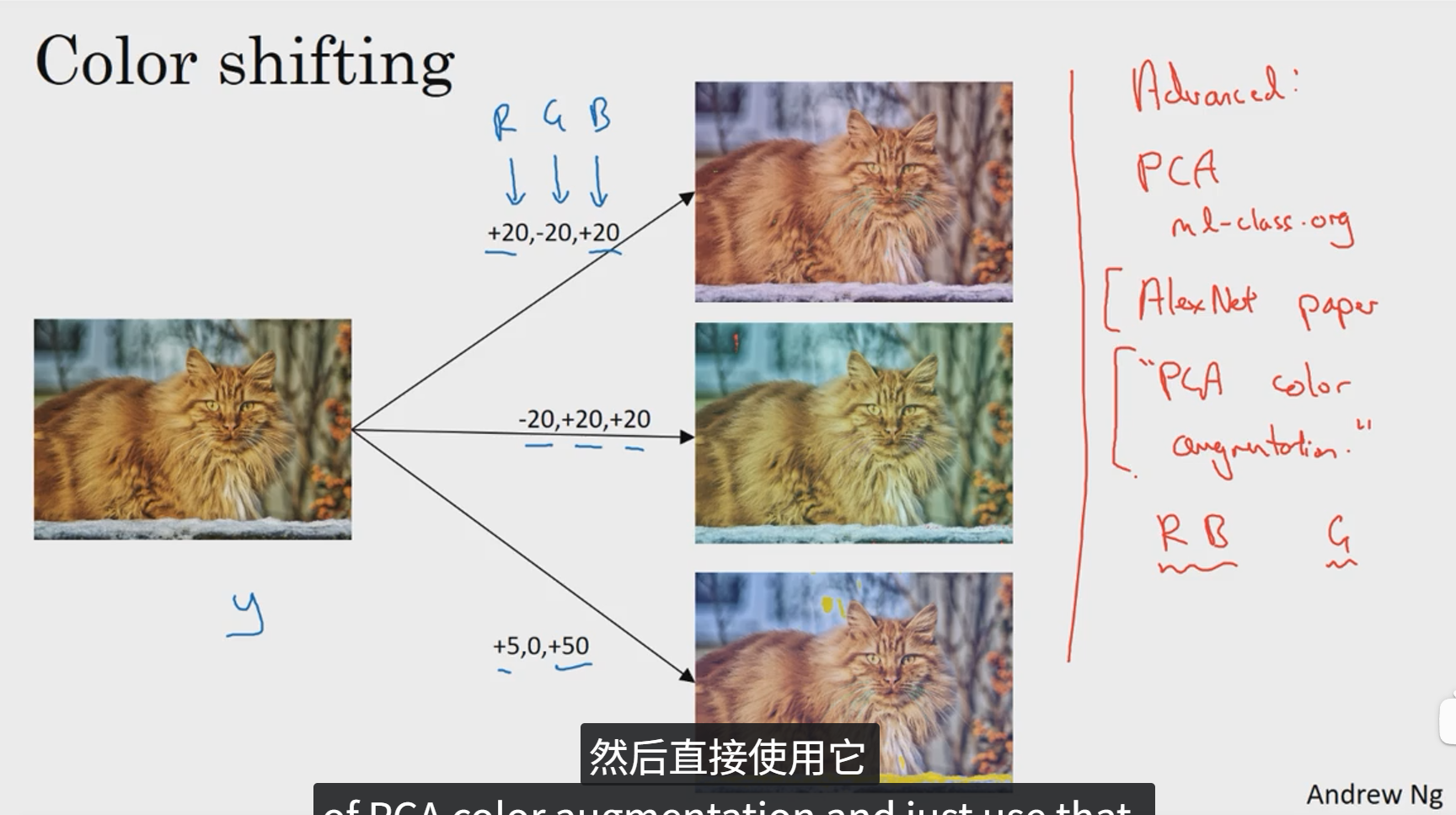
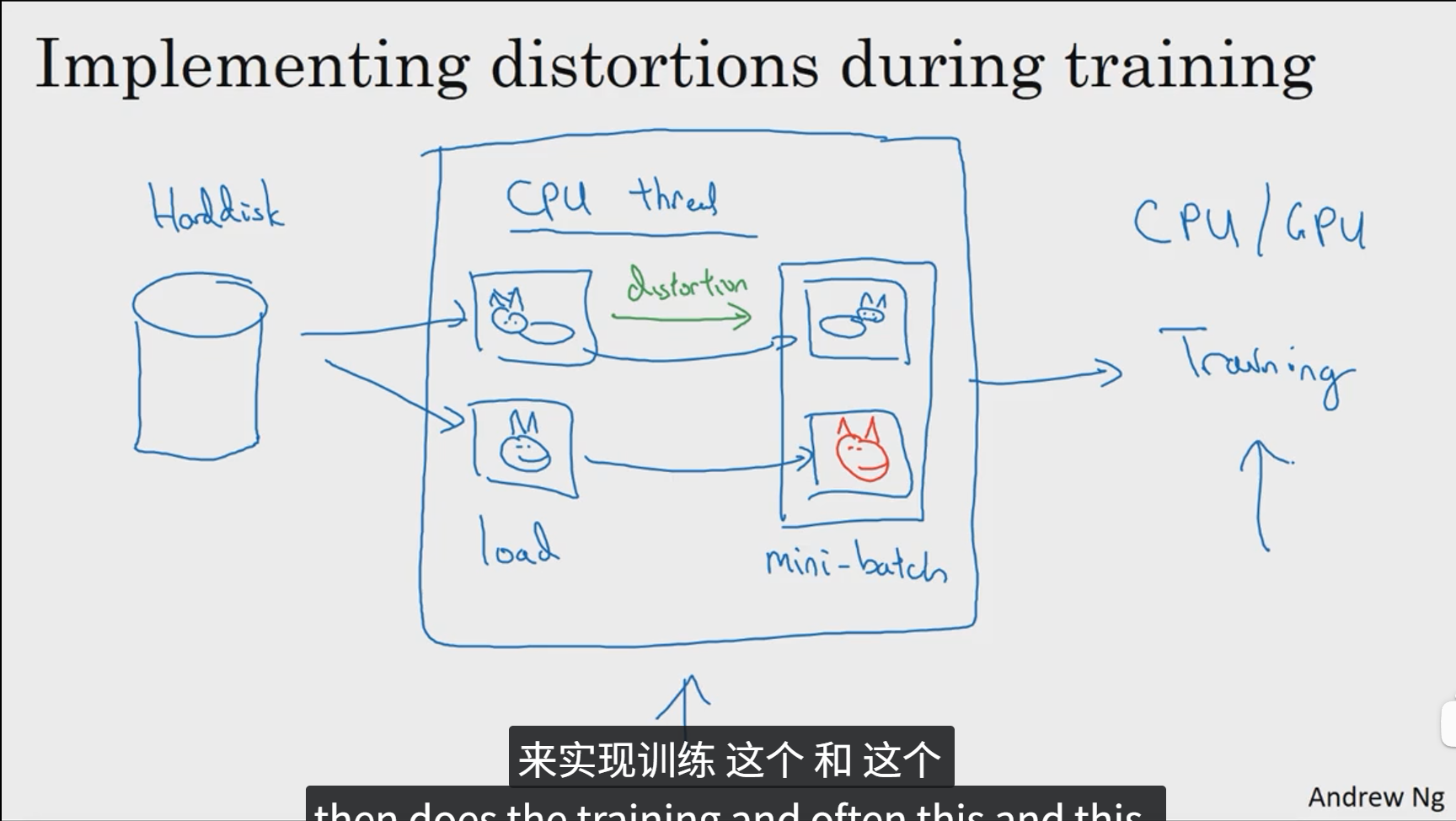
最后一种是边训练边采用一个CPU线程执行图片的各种扭曲变换。