目录
第二部分:协同过滤 (Collaborative Filtering)
[1. 基于用户 (UserCF): "你的邻居喜欢啥,我就推给你啥"](#1. 基于用户 (UserCF): “你的邻居喜欢啥,我就推给你啥”)
[2. 基于物品 (ItemCF): "你买了 X,通常大家也会买 Y"](#2. 基于物品 (ItemCF): “你买了 X,通常大家也会买 Y”)
[UserCF vs ItemCF 一图胜千言](#UserCF vs ItemCF 一图胜千言)
[第三部分:隐语义模型 (LFM) ------ 挖掘潜规则](#第三部分:隐语义模型 (LFM) —— 挖掘潜规则)
[进阶:考虑偏差 (Bias) 的推荐](#进阶:考虑偏差 (Bias) 的推荐)
你的手机比你更懂你?揭秘推荐系统背后的算法逻辑
在这个信息爆炸的时代,互联网每分钟都在产生海量的数据:数百万条搜索、几十万条推文、海量的订单 。我们面临的问题不再是"找不到信息",而是"信息太多,找不到我感兴趣的"。

这就是推荐系统(Recommendation System)存在的意义。从今日头条的新闻,到京东的商品,再到豆瓣的电影,推荐系统无处不在,它占据了亚马逊35%的销售额,贡献了巨额的转化率。
今天,我们就来扒一扒推荐系统背后的核心算法:协同过滤 与隐语义模型。
第一部分:我们如何了解用户?(数据基础)
推荐系统不是算命,它需要依据。我们通常通过收集用户的行为来构建用户画像(User Profile)。这些行为分为两类:
-
显式反馈(Explicit):用户明确表达喜好。例如给电影打5星(评分)、点赞(投票)。这种数据最精确,但很难获取。
-
隐式反馈(Implicit):用户没有明确说"喜欢",但通过行为表现出来了。例如购买、转发、甚至只是保存书签。虽然不如评分精确,但数据量巨大。
第二部分:协同过滤 (Collaborative Filtering)
这是推荐系统中最经典、应用最广泛的算法。它的核心思想很简单:物以类聚,人以群分。
在进行协同过滤前,我们首先要解决数学问题:如何计算相似度?
-
欧几里得距离:计算空间中两点的距离,距离越近越相似。
-
皮尔逊相关系数 (Pearson):衡量两个变量变化趋势的相关性,适合处理评分偏差(比如有人习惯都打高分,有人习惯都打低分)。
-
余弦相似度 (Cosine):衡量向量方向的差异。
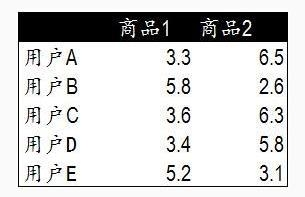
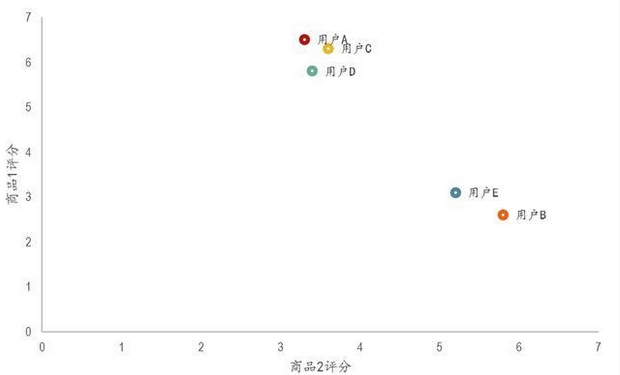
协同过滤主要分为两大流派:
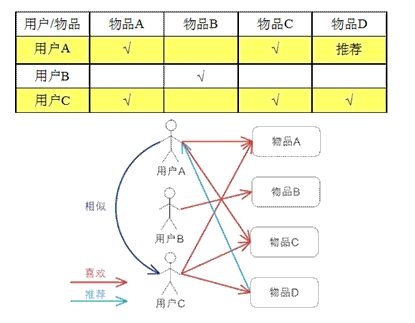
1. 基于用户 (UserCF): "你的邻居喜欢啥,我就推给你啥"
假设用户 A 和用户 C 的口味很像(都买了物品 A 和 C),那么用户 C 买了物品 D,我们猜测用户 A 也会喜欢物品 D。
-
适用场景:实时新闻、社交网络(如今日头条)。
-
原因:用户的兴趣变化快,但群体的兴趣相对稳定;而且新闻等物品更新太快,难以维护物品相似度矩阵。
-
缺点:新用户很难推荐(冷启动),且用户量过大时计算困难。
2. 基于物品 (ItemCF): "你买了 X,通常大家也会买 Y"
这不是看用户像不像,而是看物品像不像。如果很多人在买啤酒的同时都买了尿布,那这两个物品就是"相似"的。当你买了啤酒,系统就推荐尿布。
-
适用场景:电商(亚马逊、京东)、电影。
-
原因:物品的数量通常远少于用户数量,且物品之间的关系比较稳定(买了手机通常会买手机壳,这个规律很久不变),适合预先计算。
-
优势:由于是基于你自己的历史行为推荐,理由更容易解释("因为你购买了...")。
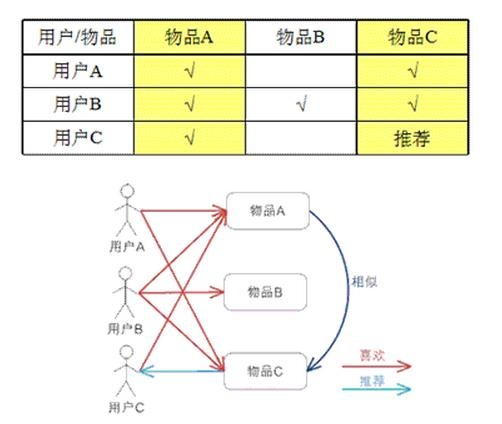
UserCF vs ItemCF 一图胜千言
| 特性 | UserCF (基于用户) | ItemCF (基于物品) |
|---|---|---|
| 性能 | 适合用户较少的场合 | 适合物品数少于用户数的场合 |
| 领域 | 时效性高(新闻) | 长尾物品丰富(电商) |
| 冷启动 | 新物品上线容易推荐给老用户 | 新用户只要有一个行为就能推荐 |
| 推荐理由 | 难解释 | 易解释 |
第三部分:隐语义模型 (LFM) ------ 挖掘潜规则
协同过滤虽然好用,但面对海量且稀疏的数据(比如几亿用户,几亿商品,绝大多数用户没买过绝大多数商品),矩阵会空得可怕。
这时,我们需要隐语义模型 (Latent Factor Model)。
核心思想:矩阵分解
我们不需要强行找用户和物品的直接对应,而是通过一个"中介"------隐含因子 (Latent Factor)。
假设我们把评分矩阵 分解为两个矩阵的乘积:
-
:用户-隐含因子矩阵(代表用户对各隐类别的喜好)。
-
比如,我们设定 个隐含因子(可能是动作、爱情、科幻,虽然机器计算时并不知道具体名字,只知道是某种特征)。LFM 会自动学习出:用户 A 喜欢"因子 1",而电影 B 刚好"因子 1"的权重很高,所以推荐电影 B。


怎么算出来的?
主要通过梯度下降 (Gradient Descent) 来迭代求解。我们要最小化预测分与真实分之间的误差平方和,同时为了防止过拟合,会加入正则化项 。
进阶:考虑偏差 (Bias) 的推荐
现实中,有些用户就是爱打低分(User Bias),有些电影本身就是高分神作(Item Bias)。一个成熟的预测公式不仅仅看匹配度,还要考虑这些偏差:
-
-
-
-

第四部分:如何评价推荐系统好不好?
做好了推荐系统,怎么知道它准不准?我们有几个核心指标:
-
准确度 (RMSE):预测评分和真实评分差多少?越小越好。
-
召回率 (Recall):用户喜欢的东西,你推荐出来了多少?
-
覆盖率 (Coverage):能不能挖掘出长尾商品?如果只推荐热门商品,覆盖率就很低。
-
多样性 (Diversity):推荐列表里的东西是不是太单一了?
总结
推荐系统本质上是在解决连接问题。
-
如果你有社交关系链,UserCF 是好选择;
-
如果你是卖货的,关注商品关联,ItemCF 更稳健;
-
如果你数据量巨大且稀疏,想要挖掘深层兴趣,隐语义模型 值得尝试。