一、研究背景
大型语言模型(LLMs)处理长文本时面临计算量随序列长度二次增长 的难题,而视觉模态可作为文本信息的高效压缩载体------单张含文本图像能以远少于数字文本的令牌承载丰富信息 。现有视觉语言模型(VLMs)的视觉编码器存在令牌过多、激活内存大、部署复杂等缺陷,且现有端到端OCR模型未解决"解码特定文本所需最少视觉令牌"这一关键问题,缺乏对视觉-文本压缩比的系统探索。
二、核心工作
- 提出DeepSeek-OCR模型,验证通过光学二维映射实现长上下文压缩的可行性,为LLM长上下文处理和记忆遗忘机制研究提供新方向。
- 设计核心组件DeepEncoder ,实现高分辨率输入下的低激活内存 与高压缩比,解决现有编码器的性能痛点。
- 基于 DeepEncoder 和 DeepSeek3B-MoE解码器,构建兼具高压缩效率与实用性能的端到端OCR系统,支持图表、化学式等复杂内容解析及多语言识别。
ps: 压缩比 = 真实文本对应的令牌数(Ground-truth Text Tokens) / 模型使用的视觉令牌数(Vision Tokens)
三、研究方法
3.1 模型架构
3.1.1 整体架构
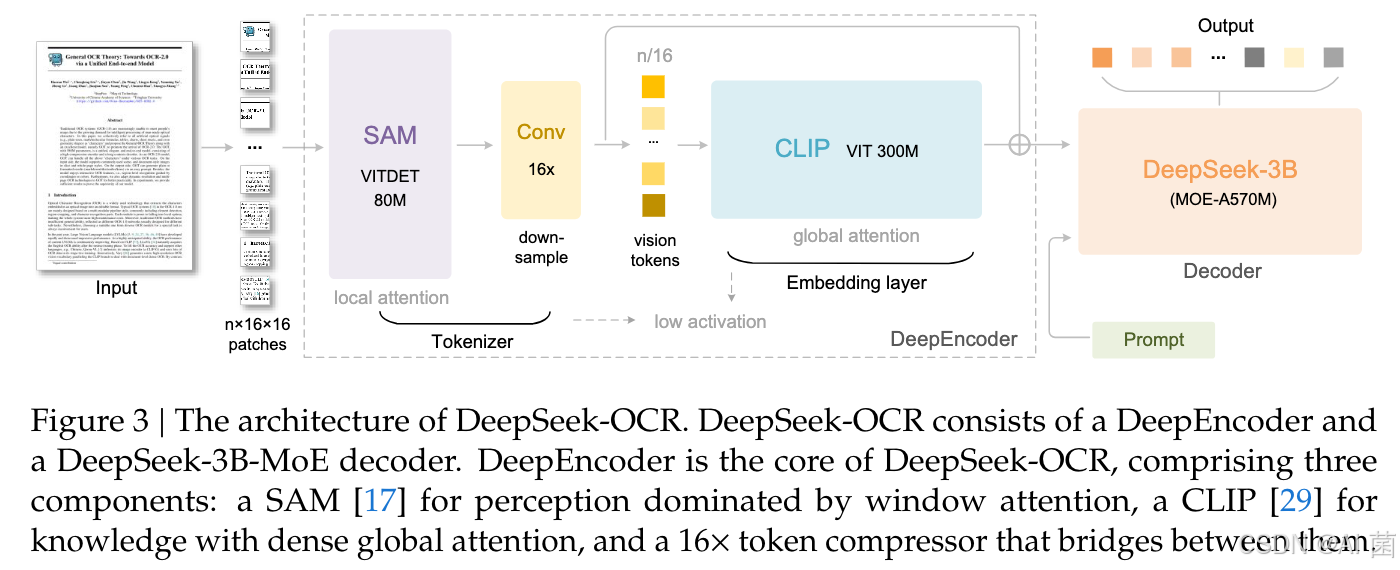
DeepSeek-OCR 采用统一的端到端视觉语言模型架构,由编码器和解码器组成。编码器(即 DeepEncoder)负责提取图像特征、将视觉表征令牌化并压缩;解码器基于图像令牌和提示词(prompts)生成所需结果。DeepEncoder 的参数约为 3.8 亿,主要由 8000 万参数的 SAM-base 和 3 亿参数的 CLIP-large串联构成。解码器采用 30 亿参数的混合专家(MoE)架构,激活参数约为 5.7 亿。
3.1.2 DeepEncoder
DeepEncoder:由SAM-base(80M参数,窗口注意力主导感知)、16×卷积压缩器、CLIP-large(300M参数,密集全局注意力主导知识提取)串联而成,通过动态插值位置编码支持多分辨率输入。
DeepEncoder 主要由两部分组成:
- 以窗口注意力为主导的视觉感知特征提取组件( SAM-base)。
- 以及具备密集全局注意力的视觉知识特征提取组件(CLIP-large),对于 CLIP 模块,由于其输入不再是图像而是前一模块的输出令牌,移除了其第一个块嵌入层。
在两个组件之间,借鉴 Vary 的设计,采用一个 2 层卷积模块对视觉令牌进行 16 倍下采样。每个卷积层的核大小为 3、步长为 2、填充为 1,通道数从 256 增加至 1024。
假设输入一张 1024×1024 的图像,DeepEncoder 会将其分割为 1024/16×1024/16=4096 个块令牌。由于编码器前半部分以窗口注意力为主导且仅含 8000 万参数,其激活内存处于可接受范围。在进入全局注意力之前,4096 个令牌经过压缩模块后,数量变为 4096/16=256,从而使整体激活内存可控。
3.1.3 MoE解码器
采用DeepSeek-3B-MoE架构,推理时,模型从64个路由专家中激活6个,并激活2个共享专家,激活参数0.57B,平衡表达能力与推理效率。
30 亿参数的 DeepSeek-3B-MoE 非常适合面向特定领域(本文为 OCR)的视觉语言模型研究 ------ 它既具备 30 亿参数模型的表达能力,又拥有 5 亿参数小型模型的推理效率。
3.2 数据与训练
- 构建多类型训练数据:包含OCR 1.0(传统文档/场景OCR)、OCR 2.0(图表、化学式等复杂解析)、通用视觉数据及纯文本数据,占比分别为70%、20%、10%。
- 两阶段训练:先独立训练DeepEncoder(下一个令牌预测框架),再通过流水线并行训练整个DeepSeek-OCR模型。
OCR1.0数据:

OCR2.0数据:
3.3 多分辨率支持
设计原生分辨率(Tiny/Small/Base/Large,令牌数64-400)和动态分辨率(Gundam/Gundam-M,支持分块处理超高分辨率图像)模式,适配不同压缩比需求。
四、实验设计
1. 基准测试
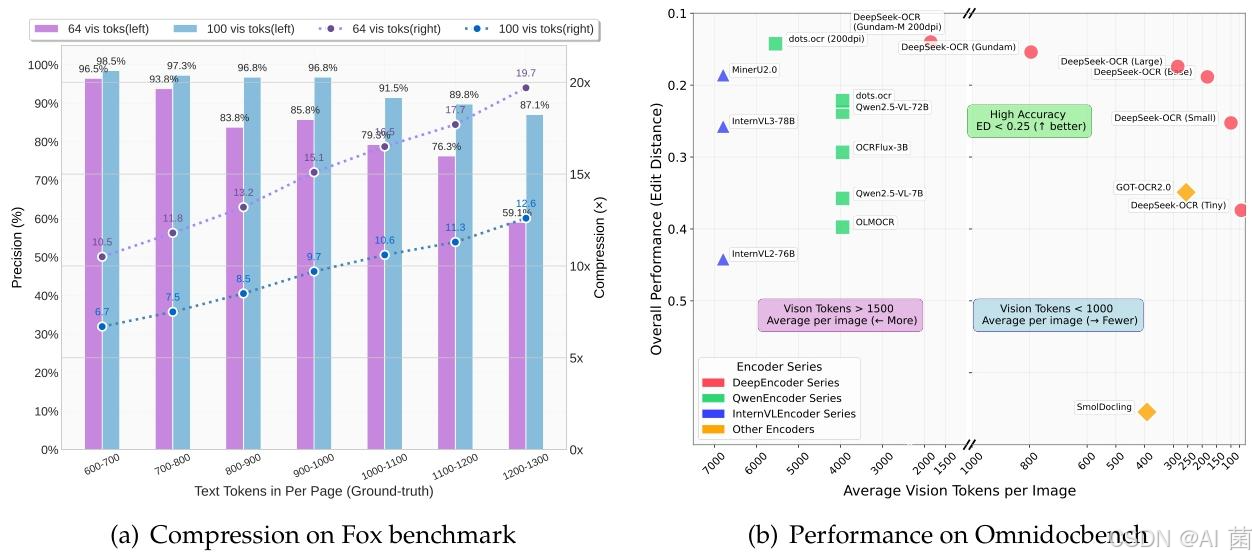
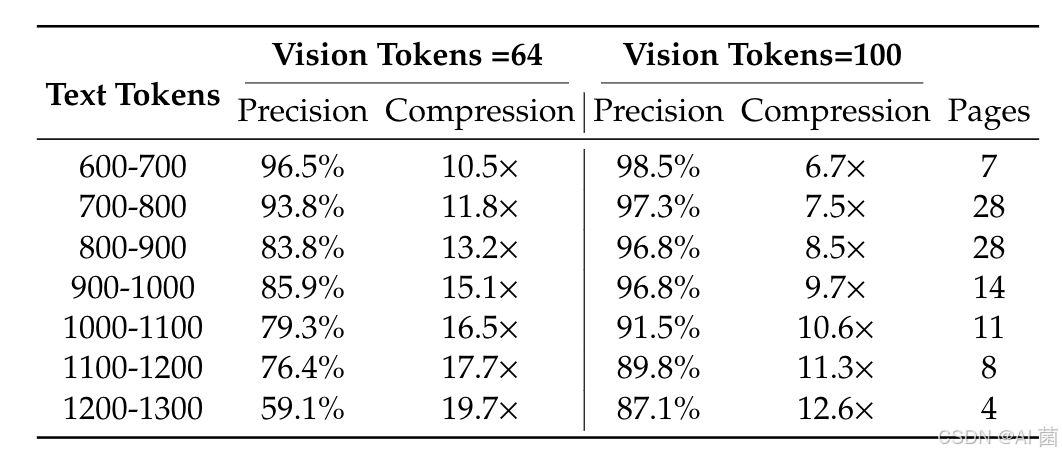
- 压缩性能:在Fox基准测试(英文文档,600-1300令牌)中,测试不同视觉令牌数下的OCR精度与压缩比。
- 实用性能:在OmniDocBench基准测试中,与主流端到端OCR模型对比,评估编辑距离(越小性能越好)。
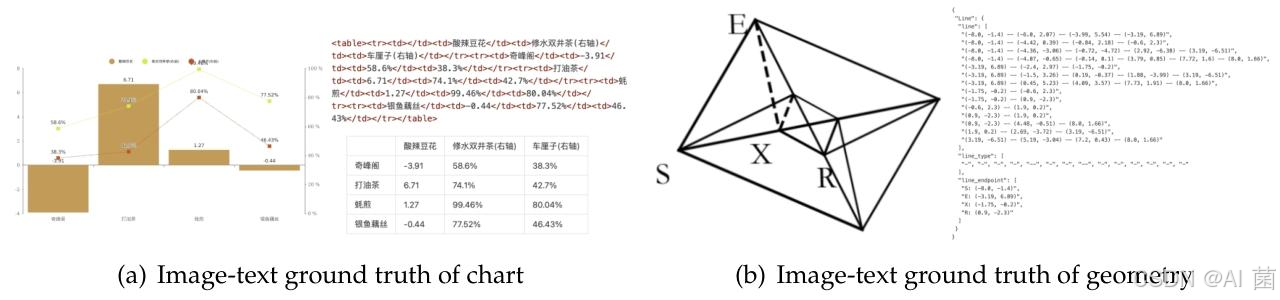
- 定性分析:测试模型对图表、化学式、几何图形的深度解析能力,以及多语言识别、通用视觉理解能力。
2. 实验变量
- 视觉令牌数:64、100、256、400等不同配置。
- 压缩比:5×、10×、15×、20×等梯度。(压缩比=真实文本对应的令牌数 / 模型使用的视觉令牌数)
- 文档类型:书籍、幻灯片、报纸、财务报告等多类别。
五、实验分析
1. 压缩性能
- 压缩比<10×时,OCR精度达97%;20×压缩比下仍保持60%精度,验证了视觉-文本压缩的有效性。
- 文本令牌数越多,压缩比越高,但精度呈下降趋势 ,主要受长文档布局复杂度和低分辨率下文本模糊影响。
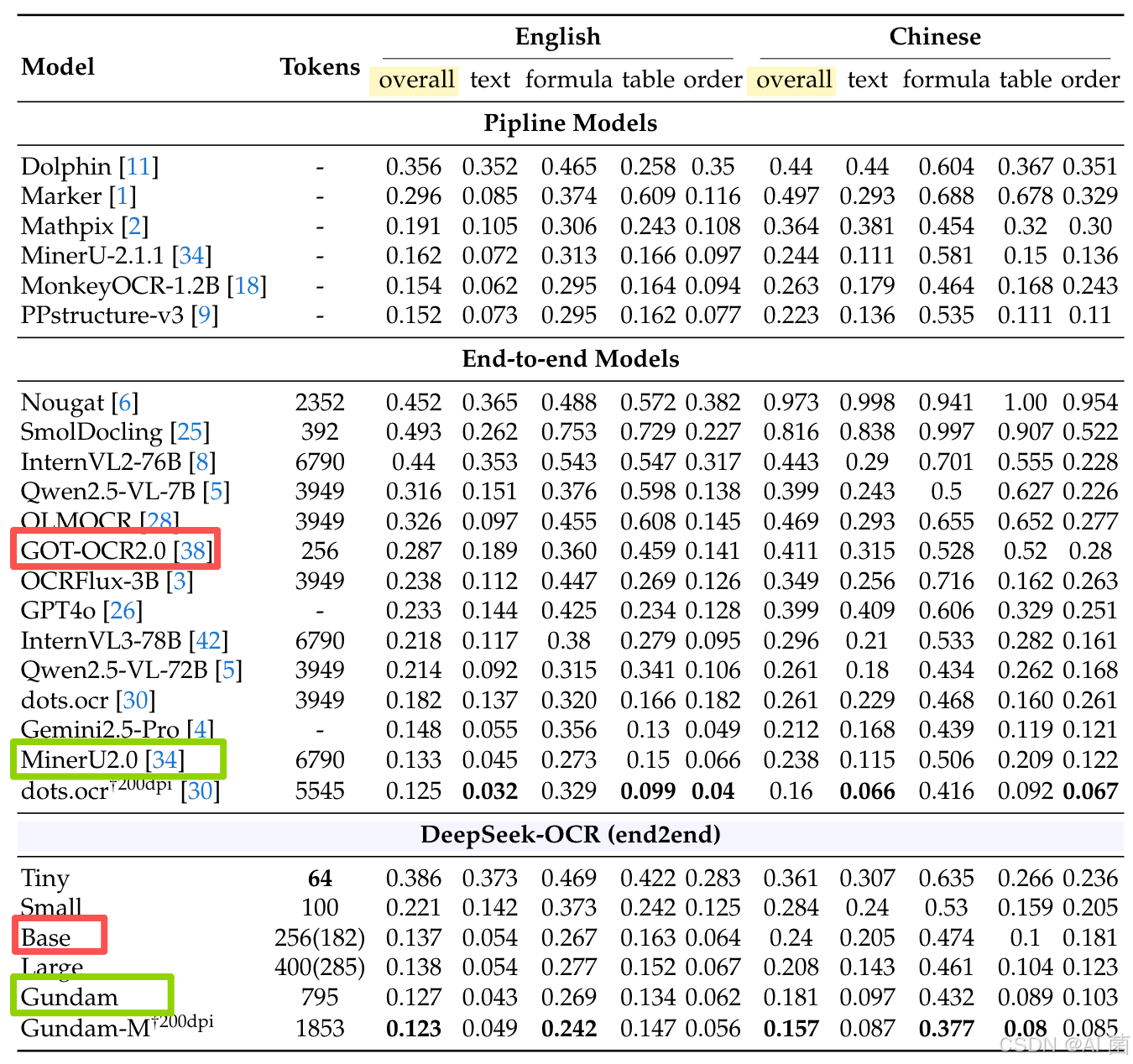
2. 实用性能
- 仅用100视觉令牌即超越需256令牌的GOT-OCR2.0;不足800令牌时性能优于需6000+令牌的MinerU2.0,令牌效率显著领先。
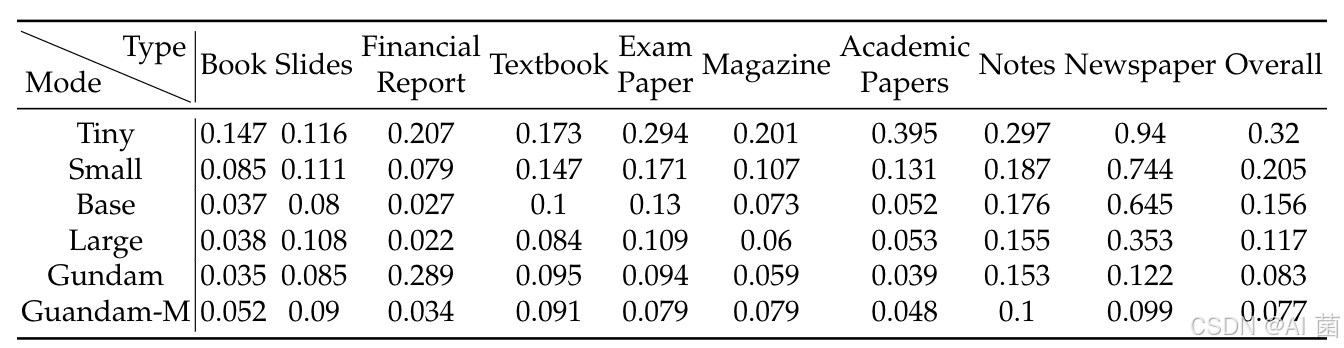
- 不同文档类型适配性:幻灯片仅需64令牌即可达标,报纸需Gundam模式(约800令牌),契合不同文档的文本密度差异。
3. 拓展能力
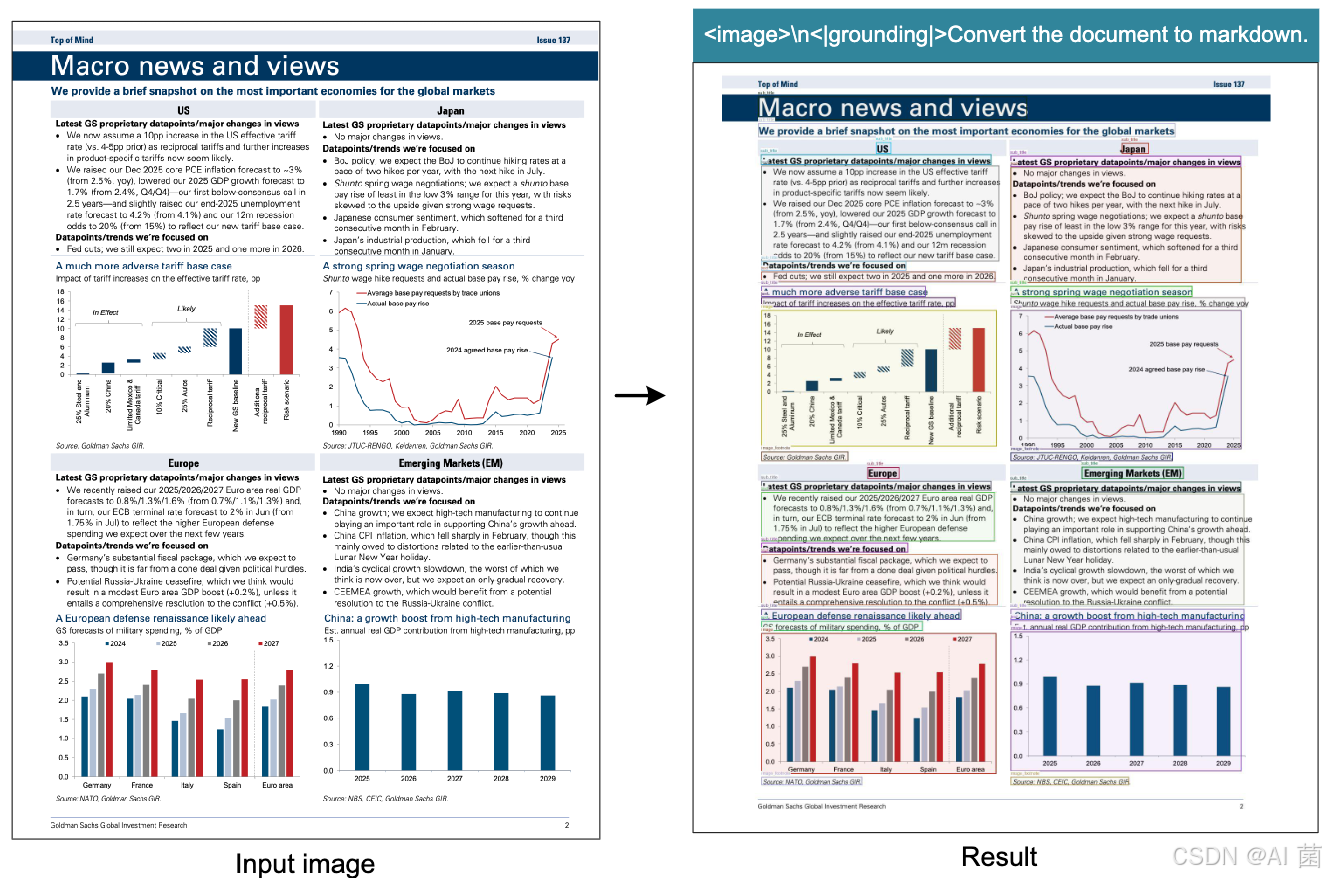
- 成功解析图表(转HTML表格)、化学式(转SMILES格式)、简单几何图形,支持近100种语言识别及图像描述、目标检测等通用视觉任务。
六、总结
该研究通过DeepSeek-OCR模型,首次系统验证了上下文光学压缩的可行性,提出的DeepEncoder解决了高分辨率输入下的令牌压缩与内存控制难题。模型在保持高压缩比(7-20×)的同时,兼具优异的OCR实用性能和拓展能力,为LLM长上下文处理提供了新范式。此外,模型可大规模生成LLM/VLM训练数据(单A100-40G日生成20万+页),具备极高的工业价值。未来可通过数字-光学文本交织预训练、大海捞针测试等进一步完善上下文压缩的有效性验证。