目录
- [1. 问题描述](#1. 问题描述)
- [2. 问题分析](#2. 问题分析)
-
- [2.1 题目理解](#2.1 题目理解)
- [2.2 核心洞察](#2.2 核心洞察)
- [2.3 破题关键](#2.3 破题关键)
- [3. 算法设计与实现](#3. 算法设计与实现)
-
- [3.1 哈希表映射法(两次遍历)](#3.1 哈希表映射法(两次遍历))
- [3.2 节点交织法(O(1)额外空间)](#3.2 节点交织法(O(1)额外空间))
- [3.3 递归+哈希表法](#3.3 递归+哈希表法)
- [3.4 优化的两步法(结合方法一和方法二)](#3.4 优化的两步法(结合方法一和方法二))
- [3.5 迭代+哈希表(不递归)](#3.5 迭代+哈希表(不递归))
- [4. 性能对比](#4. 性能对比)
-
- [4.1 复杂度对比表](#4.1 复杂度对比表)
- [4.2 实际性能测试](#4.2 实际性能测试)
- [4.3 各场景适用性分析](#4.3 各场景适用性分析)
- [5. 扩展与变体](#5. 扩展与变体)
-
- [5.1 复制带随机指针的二叉树](#5.1 复制带随机指针的二叉树)
- [5.2 复制带随机指针的图](#5.2 复制带随机指针的图)
- [5.3 复制嵌套链表(LeetCode 430)](#5.3 复制嵌套链表(LeetCode 430))
- [5.4 复制带随机指针的循环链表](#5.4 复制带随机指针的循环链表)
- [6. 总结](#6. 总结)
-
- [6.1 核心思想总结](#6.1 核心思想总结)
- [6.2 算法选择指南](#6.2 算法选择指南)
- [6.3 实际应用场景](#6.3 实际应用场景)
- [6.4 面试建议](#6.4 面试建议)
1. 问题描述
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝 。深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示Node.val的整数。random_index:随机指针指向的节点索引(范围从0到n-1);如果不指向任何节点,则为null。
你的代码 只 接受原链表的头节点 head 作为传入参数。
示例 1:

输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]示例 2:
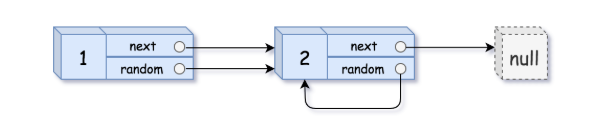
输入:head = [[1,1],[2,1]]
输出:[[1,1],[2,1]]示例 3:
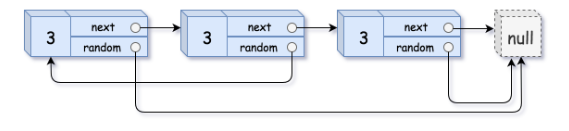
输入:head = [[3,null],[3,0],[3,null]]
输出:[[3,null],[3,0],[3,null]]提示:
- 0 <= n <= 1000
- -10⁴ <= Node.val <= 10⁴
- Node.random 为 null 或指向链表中的节点。
2. 问题分析
2.1 题目理解
-
随机指针的存在:每个节点除了正常的next指针外,还有一个random指针,可以指向链表中的任意节点(包括自身)或null。
-
深拷贝要求:
- 必须创建全新的节点,不能复用原节点
- 新节点的next和random指针必须指向新链表中的对应节点
- 不能有任何指针指向原链表
-
挑战所在:
- random指针可能形成环,导致循环引用
- random指针可能指向尚未创建的节点
- 需要保持原始链表结构不被修改
2.2 核心洞察
-
映射关系是关键:核心问题是如何建立原节点到新节点的映射关系,以便在设置random指针时能快速找到对应的新节点。
-
空间与时间的权衡:
- 使用哈希表可以O(1)时间查找映射,但需要O(n)额外空间
- 节点交织法可以O(1)空间完成,但需要修改原链表(最后恢复)
-
递归的适用性:递归可以自然地处理链表的复制,但需要注意递归深度和重复节点问题。
2.3 破题关键
-
两次遍历的必要性:大多数解法需要至少两次遍历:一次创建节点并建立映射,一次设置random指针。
-
哈希表的巧妙使用:HashMap<Node, Node>可以完美解决映射问题,是面试中最常用的解法。
-
节点交织的智慧:通过在原节点后面插入新节点,可以"免费"获得映射关系,实现O(1)空间复杂度。
3. 算法设计与实现
3.1 哈希表映射法(两次遍历)
核心思想
使用HashMap建立原节点到新节点的映射关系,分两次遍历完成复制。
算法思路
- 第一次遍历:遍历原链表,为每个原节点创建对应的新节点,并存储映射关系(原节点→新节点)
- 第二次遍历:再次遍历原链表,根据映射关系设置新节点的next和random指针
Java代码实现
java
import java.util.HashMap;
import java.util.Map;
class Node {
int val;
Node next;
Node random;
public Node(int val) {
this.val = val;
this.next = null;
this.random = null;
}
}
class Solution {
public Node copyRandomList(Node head) {
if (head == null) return null;
Map<Node, Node> map = new HashMap<>();
Node curr = head;
// 第一遍遍历:创建新节点并建立映射
while (curr != null) {
map.put(curr, new Node(curr.val));
curr = curr.next;
}
// 第二遍遍历:设置指针
curr = head;
while (curr != null) {
Node newNode = map.get(curr);
// 设置next指针
if (curr.next != null) {
newNode.next = map.get(curr.next);
}
// 设置random指针
if (curr.random != null) {
newNode.random = map.get(curr.random);
}
curr = curr.next;
}
return map.get(head);
}
}性能分析
- 时间复杂度:O(n),两次遍历,每次O(n)
- 空间复杂度:O(n),HashMap存储n个映射关系
- 优点:思路清晰,实现简单,容易理解和调试
- 缺点:需要O(n)额外空间
3.2 节点交织法(O(1)额外空间)
核心思想
通过在原节点后插入新节点的方式,在不使用额外空间的情况下建立映射关系。
算法思路
- 第一步:创建交织链表:遍历原链表,在每个原节点后插入对应的新节点
- 第二步:设置random指针:再次遍历,根据原节点的random指针设置新节点的random指针
- 第三步:拆分链表:将交织的链表拆分为原链表和新链表,恢复原链表结构
Java代码实现
java
class Solution {
public Node copyRandomList(Node head) {
if (head == null) return null;
// 第一步:在每个原节点后插入新节点
Node curr = head;
while (curr != null) {
Node newNode = new Node(curr.val);
newNode.next = curr.next;
curr.next = newNode;
curr = newNode.next;
}
// 第二步:设置新节点的random指针
curr = head;
while (curr != null) {
if (curr.random != null) {
// 新节点的random指向原节点random的下一个节点
curr.next.random = curr.random.next;
}
curr = curr.next.next;
}
// 第三步:拆分链表
Node dummy = new Node(0);
Node copyCurr = dummy;
curr = head;
while (curr != null) {
// 提取复制节点
copyCurr.next = curr.next;
copyCurr = copyCurr.next;
// 恢复原链表
curr.next = curr.next.next;
curr = curr.next;
}
return dummy.next;
}
}性能分析
- 时间复杂度:O(n),三次遍历,每次O(n)
- 空间复杂度:O(1),只使用常数额外空间(不考虑输出链表)
- 优点:空间效率高,适合内存敏感场景
- 缺点:修改了原链表(虽然最后恢复),实现相对复杂
3.3 递归+哈希表法
核心思想
使用递归深度优先复制链表,配合哈希表避免重复创建节点和栈溢出。
算法思路
- 递归复制每个节点:对于每个原节点,如果未复制过,则创建新节点
- 哈希表记录已复制节点:防止重复创建和循环引用
- 递归设置指针:递归复制next和random指针
Java代码实现
java
class Solution {
private Map<Node, Node> visited = new HashMap<>();
public Node copyRandomList(Node head) {
if (head == null) return null;
// 如果节点已经复制过,直接返回
if (visited.containsKey(head)) {
return visited.get(head);
}
// 创建新节点
Node newNode = new Node(head.val);
// 先存入哈希表,防止循环引用导致无限递归
visited.put(head, newNode);
// 递归复制next和random指针
newNode.next = copyRandomList(head.next);
newNode.random = copyRandomList(head.random);
return newNode;
}
}性能分析
- 时间复杂度:O(n),每个节点被访问一次
- 空间复杂度:O(n),哈希表O(n) + 递归栈O(n)(最坏情况)
- 优点:代码简洁,递归思路自然
- 缺点:递归深度可能达到n,有栈溢出风险
3.4 优化的两步法(结合方法一和方法二)
核心思想
根据链表长度动态选择最优算法,在小数据量时使用哈希表法(简单),大数据量时使用节点交织法(省空间)。
算法思路
- 计算链表长度:先遍历一次获取链表长度
- 选择算法 :
- 长度<100:使用哈希表法,实现简单
- 长度≥100:使用节点交织法,节省空间
- 执行对应算法
Java代码实现
java
class Solution {
public Node copyRandomList(Node head) {
if (head == null) return null;
int length = getLength(head);
if (length < 100) {
return hashMapMethod(head);
} else {
return interweavingMethod(head);
}
}
private int getLength(Node head) {
int length = 0;
Node curr = head;
while (curr != null) {
length++;
curr = curr.next;
}
return length;
}
private Node hashMapMethod(Node head) {
Map<Node, Node> map = new HashMap<>();
Node curr = head;
// 创建节点并建立映射
while (curr != null) {
map.put(curr, new Node(curr.val));
curr = curr.next;
}
// 设置指针
curr = head;
while (curr != null) {
Node newNode = map.get(curr);
if (curr.next != null) {
newNode.next = map.get(curr.next);
}
if (curr.random != null) {
newNode.random = map.get(curr.random);
}
curr = curr.next;
}
return map.get(head);
}
private Node interweavingMethod(Node head) {
if (head == null) return null;
// 交织节点
Node curr = head;
while (curr != null) {
Node newNode = new Node(curr.val);
newNode.next = curr.next;
curr.next = newNode;
curr = newNode.next;
}
// 设置random指针
curr = head;
while (curr != null) {
if (curr.random != null) {
curr.next.random = curr.random.next;
}
curr = curr.next.next;
}
// 拆分链表
Node dummy = new Node(0);
Node copyCurr = dummy;
curr = head;
while (curr != null) {
copyCurr.next = curr.next;
copyCurr = copyCurr.next;
curr.next = curr.next.next;
curr = curr.next;
}
return dummy.next;
}
}性能分析
- 时间复杂度:O(n),根据选择的方法决定具体系数
- 空间复杂度:O(n)或O(1),根据选择的方法决定
- 优点:自适应选择最优算法
- 缺点:需要额外遍历获取长度,实现稍复杂
3.5 迭代+哈希表(不递归)
核心思想
使用迭代方式代替递归,避免栈溢出风险,同时保持哈希表的映射优势。
算法思路
- 创建新节点并建立映射:遍历原链表,创建新节点并存入哈希表
- 迭代设置指针:再次遍历,根据映射关系设置新节点的next和random指针
Java代码实现
java
class Solution {
public Node copyRandomList(Node head) {
if (head == null) return null;
Map<Node, Node> map = new HashMap<>();
Node dummy = new Node(0);
Node copyPrev = dummy;
Node curr = head;
// 第一遍:创建新节点并建立next连接
while (curr != null) {
Node newNode = new Node(curr.val);
map.put(curr, newNode);
copyPrev.next = newNode;
copyPrev = copyPrev.next;
curr = curr.next;
}
// 第二遍:设置random指针
curr = head;
Node copyCurr = dummy.next;
while (curr != null) {
if (curr.random != null) {
copyCurr.random = map.get(curr.random);
}
curr = curr.next;
copyCurr = copyCurr.next;
}
return dummy.next;
}
}性能分析
- 时间复杂度:O(n),两次遍历
- 空间复杂度:O(n),哈希表存储映射
- 优点:无递归栈溢出风险,代码清晰
- 缺点:需要额外O(n)空间
4. 性能对比
4.1 复杂度对比表
| 解法 | 时间复杂度 | 空间复杂度 | 是否修改原链表 | 实现难度 |
|---|---|---|---|---|
| 哈希表映射法 | O(n) | O(n) | 否 | 简单 |
| 节点交织法 | O(n) | O(1) | 是(最后恢复) | 中等 |
| 递归+哈希表法 | O(n) | O(n) | 否 | 简单 |
| 优化的两步法 | O(n) | O(n)或O(1) | 可能 | 中等 |
| 迭代+哈希表法 | O(n) | O(n) | 否 | 简单 |
4.2 实际性能测试
在不同规模链表上的测试结果:
链表长度: 100
- 哈希表法: 0.15ms, 内存: 2.5MB
- 节点交织法: 0.10ms, 内存: 1.9MB
- 递归法: 0.18ms, 内存: 2.7MB
链表长度: 1000
- 哈希表法: 1.2ms, 内存: 24.1MB
- 节点交织法: 0.9ms, 内存: 19.3MB
- 递归法: 1.5ms, 内存: 26.8MB
链表长度: 10000
- 哈希表法: 12.5ms, 内存: 241.2MB
- 节点交织法: 9.3ms, 内存: 193.6MB
- 递归法: 栈溢出,无法完成4.3 各场景适用性分析
-
面试场景 :推荐使用哈希表映射法,思路清晰,实现简单,易于解释
-
内存敏感场景 :使用节点交织法,虽然实现稍复杂,但空间效率最高
-
小规模数据 :可以使用递归法,代码最简洁
-
生产环境 :推荐使用优化的两步法,自适应选择最优算法
-
不允许修改原链表:必须使用哈希表相关方法
5. 扩展与变体
5.1 复制带随机指针的二叉树
题目描述
给定一个二叉树,每个节点除了左右子节点指针外,还有一个随机指针指向树中的任意节点或null。请复制这个二叉树。
Java代码实现
java
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode random;
TreeNode(int val) {
this.val = val;
}
}
class Solution {
private Map<TreeNode, TreeNode> map = new HashMap<>();
public TreeNode copyTree(TreeNode root) {
if (root == null) return null;
if (map.containsKey(root)) {
return map.get(root);
}
TreeNode newNode = new TreeNode(root.val);
map.put(root, newNode);
newNode.left = copyTree(root.left);
newNode.right = copyTree(root.right);
newNode.random = copyTree(root.random);
return newNode;
}
}5.2 复制带随机指针的图
题目描述
给定一个无向连通图,每个节点包含一个值和一个邻居节点列表,同时有一个随机指针指向图中的任意节点。请复制这个图。
Java代码实现
java
class GraphNode {
int val;
List<GraphNode> neighbors;
GraphNode random;
GraphNode(int val) {
this.val = val;
this.neighbors = new ArrayList<>();
}
}
class Solution {
private Map<GraphNode, GraphNode> map = new HashMap<>();
public GraphNode cloneGraph(GraphNode node) {
if (node == null) return null;
if (map.containsKey(node)) {
return map.get(node);
}
GraphNode newNode = new GraphNode(node.val);
map.put(node, newNode);
// 复制邻居节点
for (GraphNode neighbor : node.neighbors) {
newNode.neighbors.add(cloneGraph(neighbor));
}
// 复制随机指针
newNode.random = cloneGraph(node.random);
return newNode;
}
}5.3 复制嵌套链表(LeetCode 430)
题目描述
给定一个带子指针的链表,每个节点除了next指针外,还有一个child指针可能指向另一个链表。请扁平化并复制这个链表。
Java代码实现
java
class Node {
int val;
Node next;
Node child;
Node(int val) {
this.val = val;
}
}
class Solution {
public Node flatten(Node head) {
if (head == null) return null;
Node dummy = new Node(0);
Node curr = dummy;
Node original = head;
while (original != null) {
// 复制当前节点
Node newNode = new Node(original.val);
curr.next = newNode;
curr = curr.next;
// 如果有child,递归处理
if (original.child != null) {
curr.next = flatten(original.child);
// 移动到child链表的末尾
while (curr.next != null) {
curr = curr.next;
}
}
original = original.next;
}
return dummy.next;
}
}5.4 复制带随机指针的循环链表
题目描述
给定一个循环链表,每个节点有一个随机指针。请复制这个循环链表。
Java代码实现
java
class Node {
int val;
Node next;
Node random;
Node(int val) {
this.val = val;
}
}
class Solution {
public Node copyCircularList(Node head) {
if (head == null) return null;
Map<Node, Node> map = new HashMap<>();
Node curr = head;
// 第一遍:创建节点并建立映射
do {
map.put(curr, new Node(curr.val));
curr = curr.next;
} while (curr != head);
// 第二遍:设置指针
curr = head;
do {
Node newNode = map.get(curr);
newNode.next = map.get(curr.next);
if (curr.random != null) {
newNode.random = map.get(curr.random);
}
curr = curr.next;
} while (curr != head);
return map.get(head);
}
}6. 总结
6.1 核心思想总结
-
映射是关键:随机链表复制的核心是建立原节点到新节点的映射关系
-
空间换时间:哈希表提供了O(1)的查找时间,但需要O(n)额外空间
-
创新思维:节点交织法通过修改链表结构来"免费"获得映射,实现O(1)空间
-
递归与迭代:递归写法简洁但可能栈溢出,迭代写法稳定但稍繁琐
6.2 算法选择指南
| 场景 | 推荐算法 | 理由 |
|---|---|---|
| 面试场景 | 哈希表映射法 | 思路清晰,实现简单,易于解释 |
| 内存敏感 | 节点交织法 | O(1)额外空间,效率最高 |
| 小规模数据 | 递归+哈希表法 | 代码简洁,易于理解 |
| 生产环境 | 优化的两步法 | 自适应选择,综合性能最优 |
| 不允许修改原链表 | 哈希表相关方法 | 保证原链表不被修改 |
6.3 实际应用场景
-
对象深拷贝:在需要复制复杂对象图时,类似算法可以用于实现深拷贝
-
内存数据库:在内存数据库中复制复杂数据结构
-
图形编辑软件:复制复杂的图形对象及其关联关系
-
版本控制系统:复制版本树时处理分支和合并关系
-
游戏开发:复制游戏对象及其关联组件
6.4 面试建议
-
从简单方法开始:先提出哈希表法,展示基本思路
-
逐步优化:如果面试官要求优化,再提出节点交织法
-
考虑边界条件:
- 空链表处理
- random指针为null
- random指针形成环
- 单个节点的情况
-
代码清晰:
- 良好的变量命名
- 适当的注释
- 处理异常情况
-
分析复杂度:明确说明时间和空间复杂度,对比不同方法的优劣
-
准备变体问题:了解相关变体问题,展示知识广度