
🧠 一、研究背景
- 深度学习在序列建模中的融合趋势 :近年来,TCN(时序卷积网络)、Transformer(自注意力机制)和 GRU(门控循环单元)常被组合使用,以结合各自的优势:
- TCN:捕捉长期依赖,感受野大,适合时序建模。
- Transformer:通过自注意力机制捕捉全局依赖。
- GRU:处理序列数据,具有记忆门控机制,适合时序动态建模。
- 应用场景 :适用于时间序列预测、多变量回归、工业过程建模、能源预测等领域,尤其适合高维输入、多输出的复杂回归问题。
🛠 二、主要功能
- 数据预处理:读取数据、归一化、划分训练/测试集。
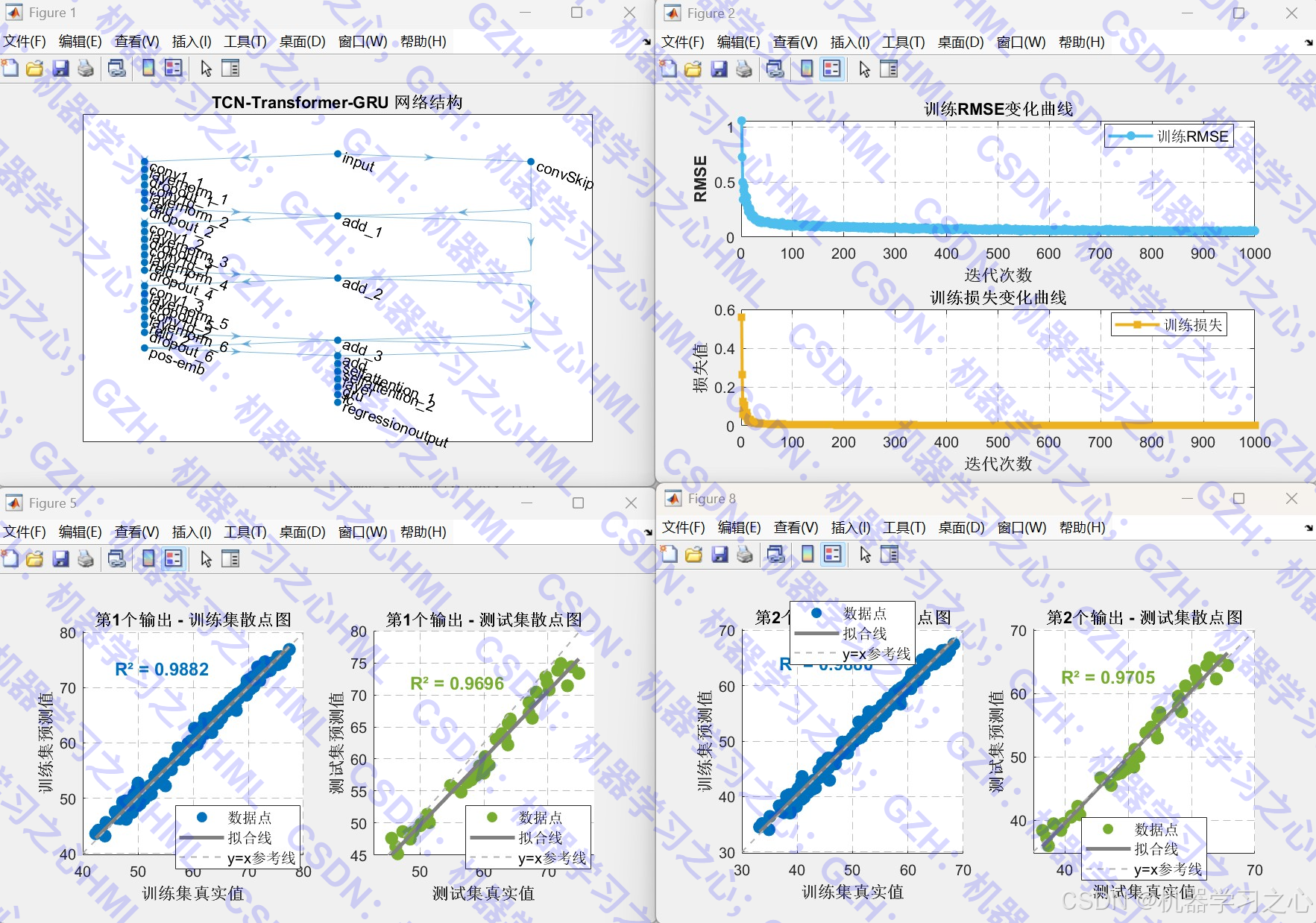
- 构建 TCN-Transformer-GRU 混合网络 :
- 输入 → TCN(多层残差扩张卷积)→ 位置编码 → Transformer(自注意力)→ GRU → 全连接 → 输出。
- 模型训练与评估 :
- 使用 Adam 优化器训练。
- 输出训练过程中的 RMSE 和 Loss 曲线。
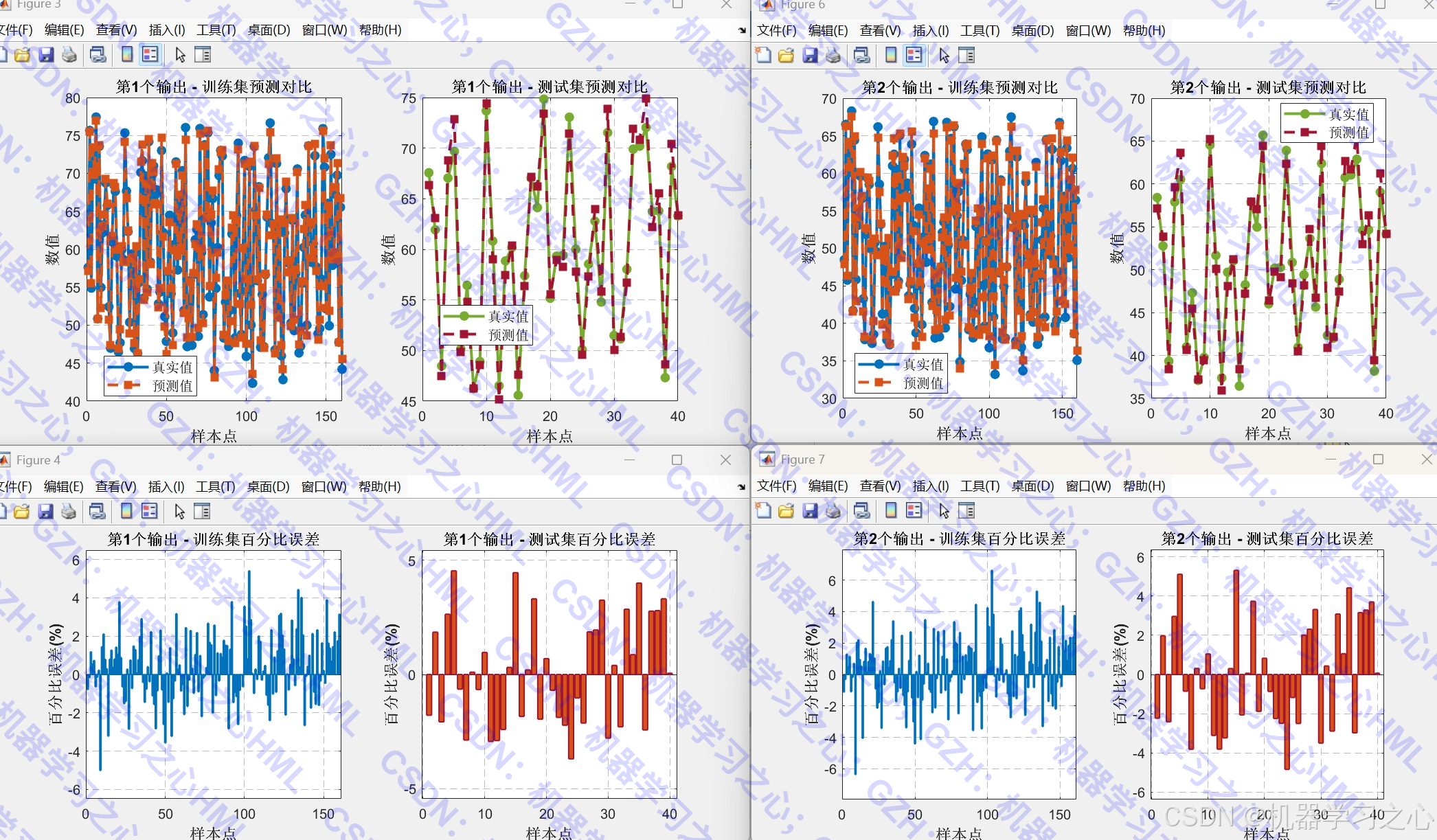
- 结果可视化 :
- 预测值与真实值对比图。
- 百分比误差图。
- 散点拟合图。
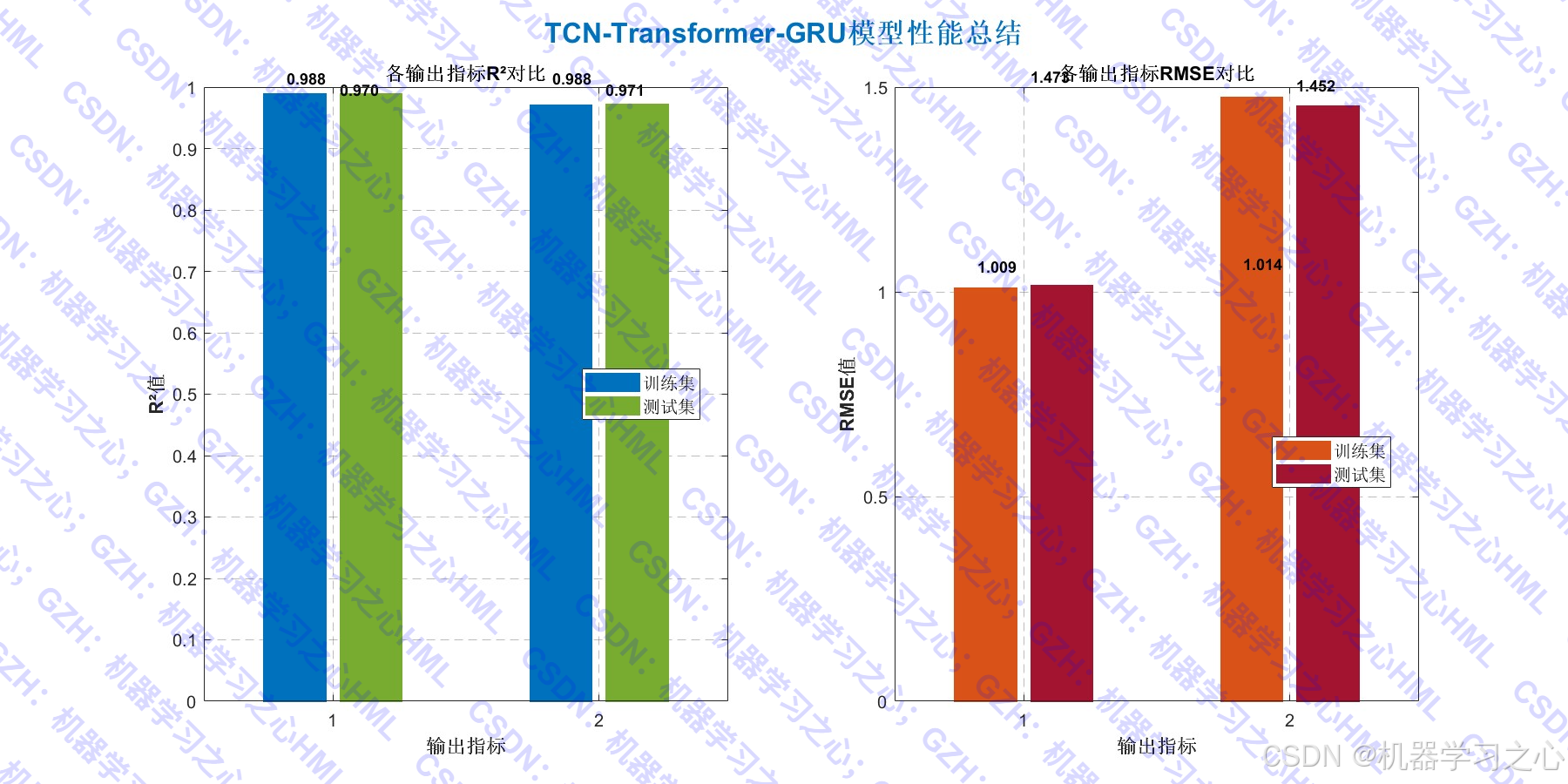
- 模型性能总结图(R²、RMSE)。
- 特征重要性分析 :
- 使用 SHAP 值(Shapley additive explanations)分析特征对输出的贡献。
- 新数据预测 :
- 加载新数据进行预测,并输出结果。
📦 三、算法步骤
- 数据准备 :
- 从 Excel 读取数据,前 5 列为输入,后 2 列为输出。
- 归一化到 0, 1。
- 按比例划分训练/测试集。
- 网络构建 :
- TCN 模块:多层残差扩张卷积,每层扩张因子递增(2^(i-1))。
- 位置编码层:为序列添加位置信息。
- Transformer 模块:两个自注意力层,支持因果掩码。
- GRU 层:提取序列特征。
- 回归输出层:全连接 + 回归层。
- 训练 :
- 使用 Adam 优化器,学习率分段下降。
- 记录训练过程中的 RMSE 和 Loss。
- 预测与反归一化 :
- 分别预测训练集和测试集。
- 反归一化得到实际值。
- 评估与可视化 :
- 计算 R²、MAE、RMSE。
- 绘制多种图表进行对比分析。
- 特征解释 :
- 调用
shapley_function计算 SHAP 值。
- 调用
- 新数据预测 :
- 调用
newpre函数对新数据进行预测。
- 调用
🧩 四、技术路线
数据 → 归一化 → TCN(残差扩张卷积)→ 位置编码 → Transformer(自注意力)→ GRU → 全连接 → 输出- TCN:通过扩张卷积扩大感受野,残差连接缓解梯度消失。
- Transformer:自注意力机制捕捉全局依赖。
- GRU:进一步提取时序动态特征。
📐 五、公式原理(简要)
- TCN 扩张卷积 :
yt=∑k=0K−1wk⋅xt−d⋅k y_t = \sum_{k=0}^{K-1} w_k \cdot x_{t - d \cdot k} yt=k=0∑K−1wk⋅xt−d⋅k
其中 (d) 为扩张因子。 - Transformer 自注意力 :
Attention(Q,K,V)=softmax(QKTdk)V \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dk QKT)V - GRU 更新门与重置门 :
zt=σ(Wz⋅ht−1,xt) z_t = \sigma(W_z \cdot h_{t-1}, x_t) zt=σ(Wz⋅ht−1,xt)
rt=σ(Wr⋅ht−1,xt) r_t = \sigma(W_r \cdot h_{t-1}, x_t) rt=σ(Wr⋅ht−1,xt)
h~t=tanh(W⋅rt⊙ht−1,xt) \tilde{h}t = \tanh(W \cdot r_t \\odot h_{t-1}, x_t) h~t=tanh(W⋅rt⊙ht−1,xt)
ht=(1−zt)⊙ht−1+zt⊙h~t h_t = (1-z_t) \odot h{t-1} + z_t \odot \tilde{h}_t ht=(1−zt)⊙ht−1+zt⊙h~t
⚙ 六、参数设定(代码中关键超参数)
| 参数 | 说明 |
|---|---|
maxPosition |
位置编码最大长度(128) |
numHeads |
自注意力头数(4) |
numKeyChannels |
键通道数(64) |
hiddens |
GRU 隐藏单元数(64) |
numFilters |
TCN 卷积核数量(32) |
filterSize |
卷积核大小(3) |
dropoutFactor |
Dropout 比率(0.1) |
numBlocks |
TCN 残差块数(3) |
MaxEpochs |
最大训练轮数(1000) |
InitialLearnRate |
初始学习率(1e-3) |
💻 七、运行环境
- 平台:MATLAB(建议 R2024b 及以上版本)
🏭 八、应用场景
- 工业过程预测:如化工过程、电力负荷预测。
- 能源与环境:如风速预测、污染物浓度预测。
- 金融时间序列:如股票价格、汇率预测。
- 健康医疗:如生理信号预测(多指标输出)。
- 交通流量预测:多路段流量同时预测。