作者:来自 Jeffrey Rengifo

Agent Builder 现已 GA 可用。开始使用 Elastic Cloud 试用版,并在此查看 Agent Builder 的文档。
在本文中,我们将探索如何结合 LangGraph 和 Elasticsearch 来构建 人机协同(human-in-the-loop - HITL )系统。这种方法允许 AI 系统直接让用户参与决策过程,使交互更加可靠且具备上下文感知能力。我们将通过一个以上下文驱动的场景实现一个实用示例,展示 LangGraph 工作流如何与 Elasticsearch 集成,以检索数据、处理用户输入,并生成经过优化的结果。
要求
- NodeJS 版本 18 或更新
- OpenAI API Key
- Elasticsearch 8.x+ 部署
为什么在生产级人机协同( HITL )系统中使用 LangGraph
在之前的一篇文章中,我们介绍了 LangGraph 以及它在使用 大语言模型( LLMs )和条件边来构建检索增强生成( RAG )系统方面的优势,从而自动做出决策并展示结果。有时我们并不希望系统从头到尾完全自主运行,而是希望用户能够在执行循环中选择选项并做出决策。这个概念被称为 人机协同。
人机协同
人机协同( HITL )是一种 AI 概念,允许真实的人与 AI 系统交互,以提供更多上下文、评估响应、编辑响应、请求更多信息,以及执行其他任务。这在低容错场景中非常有用,例如 合规、决策制定 和 内容生成,有助于提升 LLM 输出的可靠性。
需要注意的是,在 agentic 系统中,人机协同 的主要目的在于 验证,而不是对 agent 的方法进行盲目信任。人机协同 的介入应当是被动的,只在系统检测到信息缺失或存在歧义时才触发。这可以确保人工参与始终是有意义并且能创造价值的,而不是成为一个不必要地打断每个工作流的强制检查点。
一个常见的例子是,当你的编码助手在终端中请求你授权执行某个命令,或者在开始编码之前向你展示逐步的思考过程以供你确认。
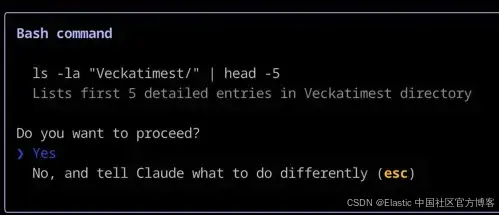 Claude Code 使用人机协同在执行 Bash 命令之前向你请求确认。
Claude Code 使用人机协同在执行 Bash 命令之前向你请求确认。
Elasticsearch 和 LangGraph:它们如何协同工作
LangChain 允许我们将 Elasticsearch 作为向量存储,并在 LangGraph 应用中执行查询,这对于执行全文搜索或语义搜索非常有用;而 LangGraph 用于定义具体的工作流、工具和交互。它还将 人机协同( HITL )作为与用户交互的额外一层。
实践实现:人机协同
让我们设想一个场景:一名律师对他最近接手的一个案件有疑问。如果没有合适的工具,他需要手动搜索法律文章和判例,完整阅读它们,然后再解读这些内容如何适用于他的情况。而通过 LangGraph 和 Elasticsearch,我们可以构建一个系统,搜索法律判例数据库,并生成一份案件分析,结合律师提供的具体细节和上下文。你可以在下面的仓库中找到该用例的完整实现。
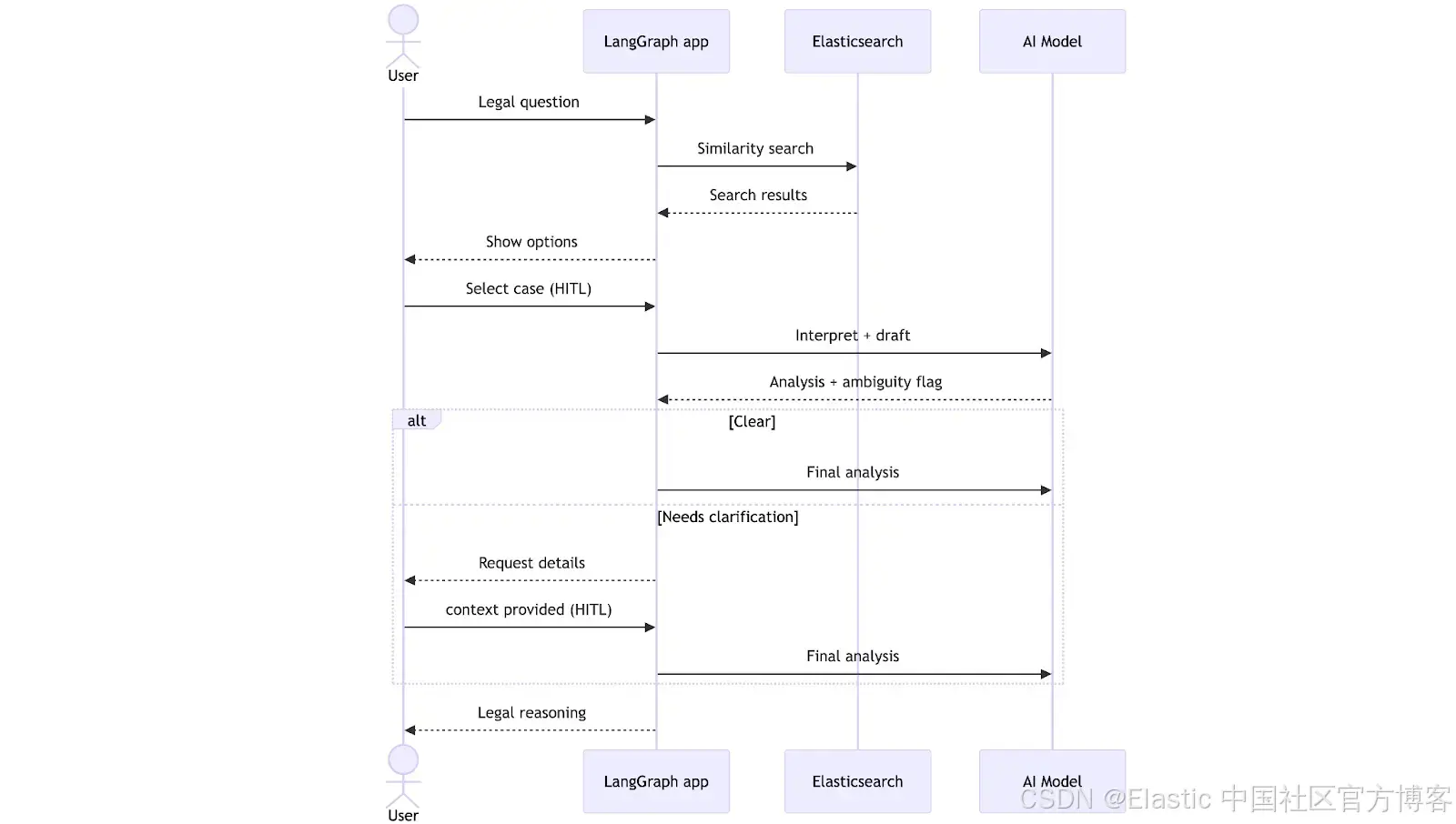
当律师提交一个法律问题时,工作流开始执行。系统会在 Elasticsearch 中执行向量搜索,检索最相关的判例,并使用自然语言将它们呈现给律师进行选择。完成选择后, LLM 会生成一份分析草稿,并检查信息是否完整。此时,工作流可以走两条路径之一:如果一切清晰,则直接生成最终分析;如果不清晰,则暂停并向律师请求澄清。在补充缺失的上下文之后,系统会结合这些澄清完成分析并返回结果。
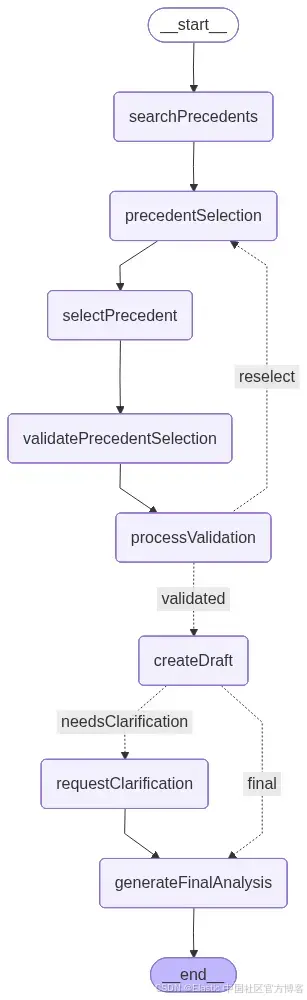
下面是由 LangGraph 绘制的一张图,展示了应用在开发完成后的整体结构。每个节点都代表一个工具或功能:
数据集
这是本示例将使用的数据集。该数据集包含一系列法律判例,每条记录描述了涉及服务延迟的案件、法院的推理过程以及最终判决结果。
[
{
"pageContent": "Legal precedent: Case B - Service delay not considered breach. A consulting contract used term 'timely delivery' without specific dates. A three-week delay occurred but contract lacked explicit schedule. Court ruled no breach as parties had not defined concrete timeline and delay did not cause demonstrable harm.",
"metadata": {
"caseId": "CASE-B-2022",
"contractType": "consulting agreement",
"delayPeriod": "three weeks",
"outcome": "no breach found",
"reasoning": "no explicit deadline defined, no demonstrable harm",
"keyTerms": "timely delivery, open terms, schedule definition",
"title": "Case B: Delay Without Explicit Schedule"
}
},
...
]数据导入与索引设置
索引设置和数据导入逻辑定义在 dataIngestion.ts 文件中,我们在其中声明了用于处理索引创建的函数。该设置与 Elasticsearch 的 LangChain 向量存储接口兼容。
注意:映射设置也包含在 dataIngestion.ts 文件中。
安装包并设置环境变量
让我们用默认设置初始化一个 Node.js 项目:
npm init -y现在让我们安装所有必需的依赖:
- @elastic/elasticsearch:Node.js 的 Elasticsearch 客户端,用于连接、创建索引和执行查询。
- @langchain/community:提供社区支持工具的集成,包括 ElasticVectorSearch 存储。
- @langchain/core:LangChain 的核心构建模块,如 chains、prompts 和工具函数。
- @langchain/langgraph:添加基于图的编排,允许使用节点、边和状态管理创建工作流。
- @langchain/openai :通过 LangChain 访问 OpenAI 模型(LLM 和 embeddings)。
- dotenv:从 .env 文件加载环境变量到 process.env。
- tsx:一个用于执行 TypeScript 代码的实用工具。
在控制台中运行以下命令以安装所有依赖:
npm install @elastic/elasticsearch @langchain/community @langchain/core @langchain/langgraph @langchain/openai dotenv --legacy-peer-deps && npm install --save-dev tsx创建一个 .env 文件来设置环境变量:
ELASTICSEARCH_ENDPOINT=
ELASTICSEARCH_API_KEY=
OPENAI_API_KEY=我们将使用 TypeScript 编写代码,因为它提供类型安全层和更好的开发体验。创建一个名为 main.ts 的 TypeScript 文件,并插入下一部分的代码。
包导入
在 main.ts 文件中,我们首先导入所需模块并初始化环境变量配置。这包括核心 LangGraph 组件、OpenAI 模型集成以及 Elasticsearch 客户端。
我们还从 dataIngestion.ts 文件中导入以下内容:
- ingestData:用于创建索引并导入数据的函数。
- Document 和 DocumentMetadata:定义数据集文档结构的接口。
Elasticsearch 向量存储客户端、embeddings 客户端和 OpenAI 客户端
这段代码将初始化向量存储、embeddings 客户端以及一个 OpenAI 客户端:
const VECTOR_INDEX = "legal-precedents";
const llm = new ChatOpenAI({ model: "gpt-4o-mini" });
const embeddings = new OpenAIEmbeddings({
model: "text-embedding-3-small",
});
const esClient = new Client({
node: process.env.ELASTICSEARCH_ENDPOINT,
auth: {
apiKey: process.env.ELASTICSEARCH_API_KEY ?? "",
},
});
const vectorStore = new ElasticVectorSearch(embeddings, {
client: esClient,
indexName: VECTOR_INDEX,
});应用工作流状态 schema 将有助于节点之间的通信:
const LegalResearchState = Annotation.Root({
query: Annotation<string>(),
precedents: Annotation<Document[]>(),
userChoice: Annotation<string>(),
selectedPrecedent: Annotation<Document | null>(),
validation: Annotation<string>(),
draftAnalysis: Annotation<string>(),
ambiguityDetected: Annotation<boolean>(),
userClarification: Annotation<string>(),
finalAnalysis: Annotation<string>(),
});在 state 对象中,我们将在各节点之间传递以下内容:用户的 query、从中提取的概念、检索到的法律 precedent,以及检测到的任何歧义。state 还会跟踪用户选择的 precedent、生成的 draft analysis,以及在所有澄清完成后的最终 analysis。
节点
async function searchPrecedents(state: typeof LegalResearchState.State) {
console.log(
"📚 Searching for relevant legal precedents with query:\n",
state.query
);
const results = await vectorStore.similaritySearch(state.query, 5);
const precedents = results.map((d) => d as Document);
console.log(`Found ${precedents.length} relevant precedents:\n`);
for (let i = 0; i < precedents.length; i++) {
const p = precedents[i];
const m = p.metadata;
console.log(
`${i + 1}. ${m.title} (${m.caseId})\n` +
` Type: ${m.contractType}\n` +
` Outcome: ${m.outcome}\n` +
` Key reasoning: ${m.reasoning}\n` +
` Delay period: ${m.delayPeriod}\n`
);
}
return { precedents };
}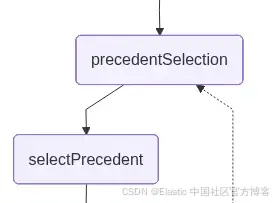
precedentSelection: 这个节点允许用户使用自然语言选择通过 proximity search 检索到的最符合问题的用例。此时,应用会中断工作流并等待用户输入:
function precedentSelection(state: typeof LegalResearchState.State) {
console.log("\n⚖️ HITL #1: Human input needed\n");
const result = interrupt({
question: "👨⚖️ Which precedent is most similar to your case? ",
});
return { userChoice: result as string };
}selectPrecedent: 这个节点将用户输入与检索到的文档一起发送,以便进行解析,从而选择其中一个。LLM 执行此任务,通过返回一个数字来表示它从用户的自然语言输入中推断出的文档:
async function selectPrecedent(state: typeof LegalResearchState.State) {
const precedents = state.precedents || [];
const userInput = state.userChoice || "";
const precedentsList = precedents
.map((p, i) => {
const m = p.metadata;
return `${i + 1}. ${m.caseId}: ${m.title} - ${m.outcome}`;
})
.join("\n");
const structuredLlm = llm.withStructuredOutput({
name: "precedent_selection",
schema: {
type: "object",
properties: {
selected_number: {
type: "number",
description:
"The precedent number selected by the lawyer (1-based index)",
minimum: 1,
maximum: precedents.length,
},
},
required: ["selected_number"],
},
});
const prompt = `
The lawyer said: "${userInput}"
Available precedents:
${precedentsList}
Which precedent number (1-${precedents.length}) matches their selection?
`;
const response = await structuredLlm.invoke([
{
role: "system",
content:
"You are an assistant that interprets lawyer's selection and returns the corresponding precedent number.",
},
{ role: "user", content: prompt },
]);
const selectedIndex = response.selected_number - 1;
const selectedPrecedent = precedents[selectedIndex] || precedents[0];
console.log(`✅ Selected: ${selectedPrecedent.metadata.title}\n`);
return { selectedPrecedent };
}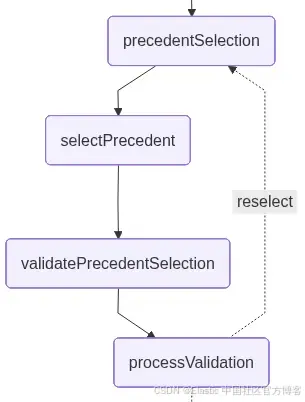
function validatePrecedentSelection(state: typeof LegalResearchState.State) {
const precedent = state.selectedPrecedent;
if (!precedent) return {};
const m = precedent.metadata;
console.log("\n⚖️ HITL #1.5: Validation needed\n");
console.log(
`Selected precedent: ${m.title} (${m.caseId})\n` +
`Type: ${m.contractType}\n` +
`Outcome: ${m.outcome}\n`
);
const result = interrupt({
question: "👨⚖️ Is this the correct precedent? (yes/no): ",
});
const validation =
typeof result === "string" ? result : (result as any)?.value || "";
return { validation };
}processValidation: 这个节点处理律师在上一个人机协同步骤中给出的确认响应(是/否),并决定工作流中的下一步路径。它将用户输入解释为对所选先例的明确批准或拒绝。
如果先例未被确认,该节点会清除当前选择,并将图返回到 precedentSelection 阶段,让用户重新选择。如果先例被确认,工作流将不作修改地继续执行:
function processValidation(state: typeof LegalResearchState.State) {
const userInput = (state.validation || "").toLowerCase().trim();
const isValid = userInput === "yes" || userInput === "y";
if (!isValid) {
console.log("❌ Precedent not confirmed. Returning to selection...\n");
return { selectedPrecedent: null, userChoice: "" };
}
console.log("✅ Precedent confirmed.\n");
return {};
}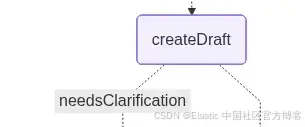
createDraft: 这个节点根据用户选择的先例生成初步法律分析。它使用 LLM 评估所选先例如何适用于律师的问题,并判断系统是否有足够信息继续执行。
如果先例可以直接应用,该节点会生成初稿分析,并沿正确路径跳转到最终节点。如果 LLM 检测到歧义,例如未定义的合同条款、缺失的时间线细节或不清晰的条件,它会返回一个标志,表示需要澄清,同时列出必须提供的具体信息。在这种情况下,歧义会触发图的左侧路径:
async function createDraft(state: typeof LegalResearchState.State) {
console.log("📝 Drafting initial legal analysis...\n");
const precedent = state.selectedPrecedent;
if (!precedent) return { draftAnalysis: "" };
const m = precedent.metadata;
const structuredLlm = llm.withStructuredOutput({
name: "draft_analysis",
schema: {
type: "object",
properties: {
needs_clarification: {
type: "boolean",
description:
"Whether the analysis requires clarification about contract terms or context",
},
analysis_text: {
type: "string",
description: "The draft legal analysis or the ambiguity explanation",
},
missing_information: {
type: "array",
items: { type: "string" },
description:
"List of specific information needed if clarification is required (empty if no clarification needed)",
},
},
required: ["needs_clarification", "analysis_text", "missing_information"],
},
});
const prompt = `
Based on this precedent:
Case: ${m.title}
Outcome: ${m.outcome}
Reasoning: ${m.reasoning}
Key terms: ${m.keyTerms}
And the lawyer's question: "${state.query}"
Draft a legal analysis applying this precedent to the question.
If you need more context about the specific contract terms, timeline details,
or other critical information to provide accurate analysis, set needs_clarification
to true and list what information is missing.
Otherwise, provide the legal analysis directly.
`;
const response = await structuredLlm.invoke([
{
role: "system",
content:
"You are a legal research assistant that analyzes cases and identifies when additional context is needed.",
},
{ role: "user", content: prompt },
]);
let displayText: string;
if (response.needs_clarification) {
const missingInfoList = response.missing_information
.map((info: string, i: number) => `${i + 1}. ${info}`)
.join("\n");
displayText = `AMBIGUITY DETECTED:\n${response.analysis_text}\n\nMissing information:\n${missingInfoList}`;
} else {
displayText = `ANALYSIS:\n${response.analysis_text}`;
}
console.log(displayText + "\n");
return {
draftAnalysis: displayText,
ambiguityDetected: response.needs_clarification,
};
}图中的两条路径如下所示:
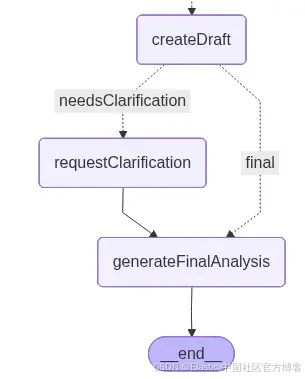
左侧路径包括一个额外节点,用于处理澄清。
requestClarification: 当系统发现初稿分析缺少必要上下文时,此节点触发第二个人机协同(HITL)步骤。工作流会被中断,并提示用户澄清前一个节点检测到的缺失合同细节:
function requestClarification(state: typeof LegalResearchState.State) {
console.log("\n⚖️ HITL #2: Additional context needed\n");
const userClarification = interrupt({
question: "👨⚖️ Please provide clarification about your contract terms:",
});
return { userClarification };
}这个干预展示了人机协同(HITL)以验证为驱动的特性:系统仅在发现可能影响分析质量的具体信息缺口时才会暂停请求人工输入。作为改进,在生产系统中,此节点可以增强验证逻辑,以确保在继续之前所有必要信息点都已被处理,从而保证分析建立在完整且准确的上下文之上。
generateFinalAnalysis: 这个节点生成最终法律分析,将所选案例与用户提供的额外上下文结合(如有需要)。利用前一个 HITL 步骤收集的澄清信息,LLM 综合案例推理、用户提供的合同细节以及决定是否存在违约的条件。
该节点输出一个整合了法律解释和实际建议的完整分析:
async function generateFinalAnalysis(state: typeof LegalResearchState.State) {
console.log("📋 Generating final legal analysis...\n");
const precedent = state.selectedPrecedent;
if (!precedent) return { finalAnalysis: "" };
const m = precedent.metadata;
const prompt = `
Original question: "${state.query}"
Selected precedent: ${m.title}
Outcome: ${m.outcome}
Reasoning: ${m.reasoning}
Lawyer's clarification: "${state.userClarification}"
Provide a comprehensive legal analysis integrating:
1. The selected precedent's reasoning
2. The lawyer's specific contract context
3. Conditions for breach vs. no breach
4. Practical recommendations
`;
const response = await llm.invoke([
{
role: "system",
content:
"You are a legal research assistant providing comprehensive analysis.",
},
{ role: "user", content: prompt },
]);
const finalAnalysis = response.content as string;
console.log(
"\n" +
"=".repeat(80) +
"\n" +
"⚖️ FINAL LEGAL ANALYSIS\n" +
"=".repeat(80) +
"\n\n" +
finalAnalysis +
"\n\n" +
"=".repeat(80) +
"\n"
);
return { finalAnalysis };
}构建图:
const workflow = new StateGraph(LegalResearchState)
.addNode("searchPrecedents", searchPrecedents)
.addNode("precedentSelection", precedentSelection)
.addNode("selectPrecedent", selectPrecedent)
.addNode("validatePrecedentSelection", validatePrecedentSelection)
.addNode("processValidation", processValidation)
.addNode("createDraft", createDraft)
.addNode("requestClarification", requestClarification)
.addNode("generateFinalAnalysis", generateFinalAnalysis)
.addEdge("__start__", "searchPrecedents")
.addEdge("searchPrecedents", "precedentSelection") // HITL #1
.addEdge("precedentSelection", "selectPrecedent")
.addEdge("selectPrecedent", "validatePrecedentSelection") // Selection validation
.addEdge("validatePrecedentSelection", "processValidation")
.addConditionalEdges(
"processValidation",
(state: typeof LegalResearchState.State) => {
const userInput = (state.validation || "").toLowerCase().trim();
const isValid = userInput === "yes" || userInput === "y";
return isValid ? "validated" : "reselect";
},
{
validated: "createDraft",
reselect: "precedentSelection",
}
)
.addConditionalEdges(
"createDraft",
(state: typeof LegalResearchState.State) => {
// If ambiguity detected, request clarification (HITL #2)
if (state.ambiguityDetected) return "needsClarification";
// Otherwise, generate final analysis
return "final";
},
{
needsClarification: "requestClarification",
final: "generateFinalAnalysis",
}
)
.addEdge("requestClarification", "generateFinalAnalysis") // HITL #2
.addEdge("generateFinalAnalysis", "__end__");在图中,我们可以看到 createDraft 条件边,它定义了选择"final"路径的条件。如图所示,决策现在取决于草稿分析是否检测到需要额外澄清的歧义。
整合在一起以执行:
await ingestData();
// Compile workflow
const app = workflow.compile({ checkpointer: new MemorySaver() });
const config = { configurable: { thread_id: "hitl-circular-thread" } };
await saveGraphImage(app);
// Execute workflow
const legalQuestion =
"Does a pattern of repeated delays constitute breach even if each individual delay is minor?";
console.log(`⚖️ LEGAL QUESTION: "${legalQuestion}"\n`);
let currentState = await app.invoke({ query: legalQuestion }, config);
// Handle all interruptions in a loop
while ((currentState as any).__interrupt__?.length > 0) {
console.log("\n💭 APPLICATION PAUSED WAITING FOR USER INPUT...");
const interruptQuestion = (currentState as any).__interrupt__[0]?.value
?.question;
// Handling empty responses
let userChoice = "";
while (!userChoice.trim()) {
userChoice = await getUserInput(interruptQuestion || "👤 YOUR CHOICE: ");
if (!userChoice.trim()) {
console.log("⚠️ Please provide a response.\n");
}
}
currentState = await app.invoke(
new Command({ resume: userChoice.trim() }),
config
);
}执行脚本
在分配好所有代码后,打开终端,运行以下命令执行 main.ts 文件:
tsx main.ts脚本执行后,问题 "Does a pattern of repeated delays constitute breach even if each individual delay is minor?" 将被发送到 Elasticsearch 进行相似度搜索,并显示从索引中检索到的结果。应用检测到多个相关判例匹配该查询,因此会暂停执行,并请求用户帮助确认哪个法律判例最适用:
📚 Searching for relevant legal precedents with query:
Does a pattern of repeated delays constitute breach even if each individual delay is minor?
Found 5 relevant precedents:
1. Case H: Pattern of Repeated Delays (CASE-H-2021)
Type: ongoing service agreement
Outcome: breach found
Key reasoning: pattern demonstrated failure to perform, cumulative effect
Delay period: multiple instances
2. Case E: Minor Delay Quality Maintained (CASE-E-2022)
Type: service agreement
Outcome: minor breach only
Key reasoning: delay minimal, quality maintained, termination unjustified
Delay period: five days
3. Case A: Delay Breach with Operational Impact (CASE-A-2023)
Type: service agreement
Outcome: breach found
Key reasoning: delay affected operations and caused financial harm
Delay period: two weeks
4. Case B: Delay Without Explicit Schedule (CASE-B-2022)
Type: consulting agreement
Outcome: no breach found
Key reasoning: no explicit deadline defined, no demonstrable harm
Delay period: three weeks
5. Case C: Justified Delay External Factors (CASE-C-2023)
Type: construction service
Outcome: no breach found
Key reasoning: external factors beyond control, force majeure applied
Delay period: one month
⚖️ HITL #1: Human input needed
💭 APPLICATION PAUSED WAITING FOR USER INPUT...
👨⚖️ Which precedent is most similar to your case? 这个应用的有趣之处在于,我们可以使用自然语言来选择一个选项,让 LLM 解释用户的输入以确定正确的选择。比如,如果我们输入文本 "Case H",会发生如下情况:
💭 APPLICATION PAUSED WAITING FOR USER INPUT...
👨⚖️ Which precedent is most similar to your case? Case H
✅ Selected: Case H: Pattern of Repeated Delays在选择案例后,应用会请求一次小的验证,以确认模型是否选择了正确的用例。如果你回答 "no",应用会返回到案例选择步骤:
Validation needed
Selected precedent: Case H: Pattern of Repeated Delays (CASE-H-2021)
Type: ongoing service agreement
Outcome: breach found
💭 APPLICATION PAUSED WAITING FOR USER INPUT...
👨⚖️ Is this the correct precedent? (yes/no): yes一旦确认,应用工作流将继续起草分析:
✅ Precedent confirmed.
📝 Drafting initial legal analysis...
AMBIGUITY DETECTED:
Based on Case H, a pattern of repeated delays can indeed constitute a breach of contract, even if each individual delay is minor. The outcome in Case H indicates that the cumulative effect of these minor delays led to a significant failure to perform the contractual obligations adequately. The reasoning emphasizes that consistent performance is critical in fulfilling the terms of a contract. Therefore, if the repeated delays create a situation where the overall performance is hindered, this pattern could be interpreted as a breach. However, the interpretation may depend on the specific terms of the contract at issue, as well as the expectations of performance set forth in that contract.
Missing information:
1. Specific contract terms regarding performance timelines
2. Details on the individual delays (duration, frequency)
3. Context on consequences of delays stated in the contract
4. Other parties' expectations or agreements related to performance
⚖️ HITL #2: Additional context needed
💭 APPLICATION PAUSED WAITING FOR USER INPUT...
👨⚖️ Please provide clarification about your contract terms:模型将用户选择的案例整合到工作流中,并在提供足够上下文后继续生成最终分析。在此步骤中,系统还利用了之前检测到的歧义:草稿分析指出合同中缺失的细节可能显著影响法律解释。这些"缺失信息"项指导模型确定在生成可靠最终意见前必须澄清的关键内容。
用户必须在下一次输入中提供所需澄清信息。让我们尝试输入:"Contract requires 'prompt delivery' without timelines. 8 delays of 2-4 days over 6 months. $50K in losses from 3 missed client deadlines. Vendor notified but pattern continued."
💭 APPLICATION PAUSED WAITING FOR USER INPUT...
👨⚖️ Please provide clarification about your contract terms: Contract requires "prompt delivery" without timelines. 8 delays of 2-4 days over 6 months. $50K in losses from 3 missed client deadlines. Vendor notified but pattern continued.
📋 Generating final legal analysis...
================================================================================
⚖️ FINAL LEGAL ANALYSIS
================================================================================
To analyze the question of whether a pattern of repeated minor delays constitutes a breach of contract, we need to combine insights from the selected precedent, the specifics of the lawyer's contract situation, conditions that typically govern breach versus non-breach, and practical recommendations for the lawyer moving forward.
### 1. Selected Precedent's Reasoning
The precedent case, referred to as Case H, found that a pattern of repeated delays amounted to a breach of contract. The court reasoned that even minor individual delays, when considered cumulatively, demonstrated a failure to perform as stipulated in the contract. The underlying rationale was that the cumulative effect of these minor delays could significantly undermine the purpose of the contract, which typically aims for timely performance and reliable delivery.
### 2. Lawyer's Specific Contract Context
In the lawyer's situation, the contract specified "prompt delivery" but did not provide a strict timeline. The vendor experienced 8 delays ranging from 2 to 4 days over a period of 6 months. These delays culminated in $50,000 in losses due to three missed client deadlines. The vendor was notified regarding these delays; however, the pattern of delays persisted.
Key considerations include:
- **Nature of the Obligations**: While "prompt delivery" does not define a strict timeline, it does imply an expectation for timely performance.
- **Material Impact**: The missed client deadlines indicate that these delays had a material adverse effect on the lawyer's ability to fulfill contractual obligations to third parties, likely triggering damages.
### 3. Conditions for Breach vs. No Breach
**Conditions for Breach**:
- **Pattern and Cumulative Effect**: Similar to the reasoning in Case H, evidence of a habitual pattern of delays can amount to a breach. Even if individual delays are minor, when combined, they may show a lack of diligence or reliability by the vendor.
- **Materiality**: The impact of these delays is crucial. If the cumulative delays adversely affect the contract's purpose or cause significant losses, this reinforces the case for a breach.
- **Notification and Opportunity to Cure**: The fact that the vendor was notified of the delays and failed to rectify the behavior can often be interpreted as a further indication of breach.
**Conditions for No Breach**:
- **Non-Material Delays**: If the delays did not affect the overall contractual performance or client obligations, this may lessen the likelihood of establishing a breach. However, given the risks and losses involved, this seems less relevant in this scenario.
- **Force Majeure or Justifiable Delays**: If the vendor could show that these delays were due to justify circumstances not within their control, it may potentially provide a defense against breach claims.
### 4. Practical Recommendations
1. **Assess Damages**: Document the exact nature of the financial losses incurred due to the missed deadlines to substantiate claims of damages.
2. **Gather Evidence**: Collect all communication regarding the delays, including any notifications sent to the vendor about the issues.
3. **Consider Breach of Contract Action**: Based on the precedent and accumulated delays, consider formalized communication to the vendor regarding a breach of contract claim, highlighting both the pattern and the impact of these repeated delays.
4. **Evaluate Remedies**: Depending upon the contract specifics, the lawyer may wish to pursue several remedies, including:
- **Compensatory Damages**: For the financial losses due to missed deadlines.
- **Specific Performance**: If timely delivery is critical and can still be enforced.
- **Contract Termination**: Depending on the severity, terminating the contract and seeking replacements may be warranted.
5. **Negotiate Terms**: If continuing to work with the current vendor is strategic, the lawyer should consider renegotiating terms for performance guarantees or penalties for further delays.
6. **Future Contracts**: In future contracts, consider including explicit timelines and conditions for prompt delivery, as well as specified damages for delays to better safeguard against this issue.
By integrating the legal principles from the precedent with the specific context and conditions outlined, the lawyer can formulate a solid plan to address the repeated delays by the vendor effectively.此输出展示了工作流的最终阶段,模型将所选案例(Case H)与律师的澄清信息整合,生成完整的法律分析。系统解释了为何延迟模式很可能构成违约,概述了支持该解释的因素,并提供了实用建议。总体来看,输出展示了人机协同(HITL)澄清如何消除歧义,使模型能够生成有依据、针对特定情境的法律意见。
其他真实场景
这种结合 Elasticsearch、LangGraph 和人机协同的应用,也适用于其他类型的应用,包括:
-
在执行前审查工具调用;例如在金融交易中,人类在下达买卖订单前进行审批。
-
在需要时提供额外参数;例如在客户支持分流中,当 AI 对客户问题可能的多种解释无法确定时,由人工选择正确的问题类别。
还有许多潜在的使用场景,人机协同将成为变革的关键。
结论
借助 LangGraph 和 Elasticsearch,我们可以构建能够自主决策的 agent,并作为线性工作流或根据上下文遵循条件路径执行。通过人机协同,agent 可以让实际用户参与决策过程,填补上下文空缺,并在容错关键的系统上请求确认。
这种方法的关键优势在于,你可以利用 Elasticsearch 能力筛选大规模数据集,然后使用 LLM 根据用户意图选择单一文档;这就是人机协同(HITL)。LLM 补充了 Elasticsearch,在处理用户表达意图的动态性方面提供支持。
这种方法保持了系统的快速和 token 高效性,因为我们只将 LLM 需要的部分发送以做最终决策,而不是整个数据集。同时,这也使系统在检测用户意图和迭代直到选择到期望选项时非常精准。
原文:https://www.elastic.co/search-labs/blog/human-in-the-loop-hitllanggraph-elasticsearch