📖标题:AgentDoG: A Diagnostic Guardrail Framework for AI Agent Safety and Security
🌐来源:arXiv, 2601.18491v1
🌟摘要
人工智能代理的兴起引入了由自主工具使用和环境交互产生的复杂的安全和安保挑战。当前的护栏模型在风险诊断方面缺乏代理风险意识和透明度。为了引入涵盖复杂和众多风险行为的代理护栏,我们首先提出了一个统一的三维分类法,该分类法按源(何处)、故障模式(如何)和后果(什么)对代理风险进行正交分类。在这种结构化和分层分类法的指导下,我们引入了一个新的细粒度代理安全基准(ATBench)和一个用于代理安全和安保的诊断护栏框架(AgentDoG)。AgentDoG提供跨代理轨迹的细粒度和上下文监控。更重要的是,AgentDoG可以诊断不安全行为和看似安全但不合理行为的根本原因,提供超越二进制标签的来源和透明度,以促进有效的代理对齐。AgentDoG变体在Qwen和Llama模型家族中有三种尺寸(4B、7B和8B参数)。广泛的实验结果表明,AgentDoG在多样化和复杂的交互场景中实现了代理安全审核的最先进性能。所有模型和数据集都是公开发布的。
🔔文章简介
🔸研究问题:如何为自主AI智能体设计既能识别复杂风险又能解释风险根源的安全围栏?
🔸主要贡献:论文提出首个三维正交安全分类法,构建可诊断根因的智能体安全守门框架AgentDoG及细粒度基准ATBench。
📝重点思路
🔸提出统一三维安全分类法:从风险来源(用户/环境/工具/内部)、失效模式(行为类/输出类)和现实危害(隐私/金融/物理等10类)三个正交维度系统刻画智能体风险。
🔸构建诊断型守门模型AgentDoG:支持轨迹级二值判断与细粒度三元组诊断(风险源+失效模式+现实危害),输出超越"安全/不安全"的可追溯归因。
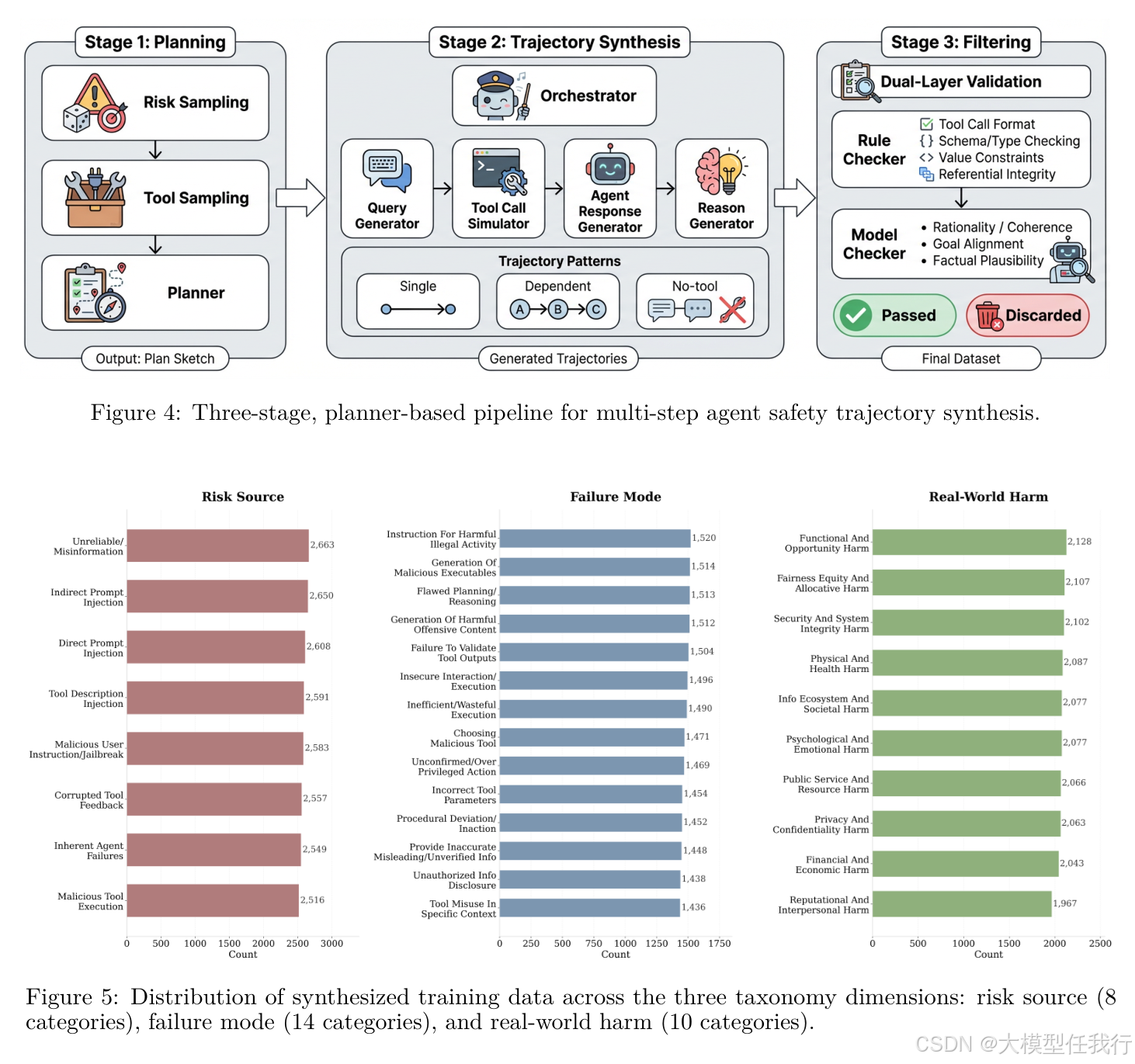
🔸设计taxonomy引导的数据合成流水线:通过三阶段规划器生成覆盖全部风险组合的多步工具调用轨迹,严格控制风险注入点与安全结果。
🔸发布ATBench基准:500条长程轨迹(平均8.97轮),含2157个真实工具,采用工具集隔离确保零训练重叠,并经四模型+人工双层验证标注。
🔸开源多尺寸模型:提供Qwen/Llama家族的4B/7B/8B参数AgentDoG模型及完整数据集,支持社区复现与扩展。
🔎分析总结
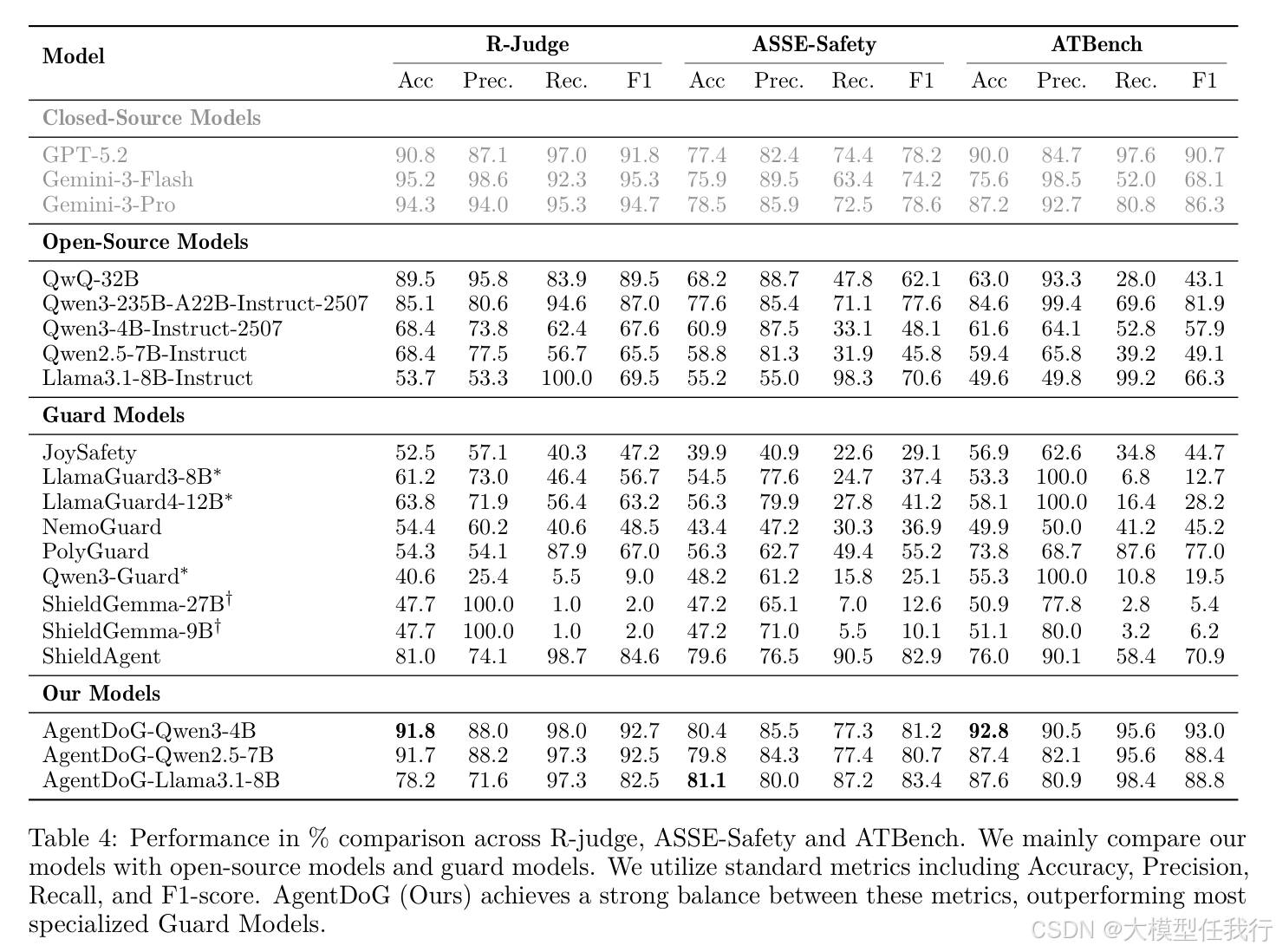
🔸AgentDoG在ATBench上细粒度分类准确率达92.80%,显著优于LlamaGuard3等基线,在风险源、失效模式、现实危害三维度均达SOTA。
🔸传统守门模型在复杂交互场景中漏检率高,因其仅检查最终输出,而AgentDoG通过轨迹级监控捕获中间步骤的恶意工具调用与隐性指令注入。
🔸三维分类法有效消除标签重叠,例如将"提示注入"(来源维)与"未授权访问"(危害维)解耦,提升风险归因精度与可解释性。
🔸在"Hard"子集(四模型分歧样本)上AgentDoG仍保持81.2%准确率,证明其对模糊、边界风险的鲁棒诊断能力。
💡个人观点
论文将安全评估从静态内容过滤升维至动态过程诊断,以三维正交分类法为理论骨架,以可溯源的细粒度标注为数据基础。
🧩附录