前言:

hello大家好,欢迎来到我们MySQL数据库基础部分的第二篇文章:数据库基础概念,在本篇文章中,我会给大家介绍关于数据库的一些基本知识,帮助大家建立起数据库的架构记忆,希望对大家有所帮助。
什么是数据库?

当我们下载了MySQL数据库后,一般会存在两个应用,一个是mysql,一个是mysqld。
二者都属于数据库服务,只不过mysqld是数据库服务的服务端,mysql是数据库服务的客户端。如果我们后面说数据库服务,一般特指mysqld。
mysql的本质就是基于C(mysql)S(mysqld)模式的一种网络服务。
我们通常总称的MySQL,是一套给我提供数据存取的服务的网络程序。
我们说的数据库,一般是指:在磁盘或内存中存储的特定组织结构的数据------也就是将来在存储的一套数据库方案。
我们在没学数据库之前,数据都是存储在文件中的。数据库其实也能被看做是一种文件,但是为什么我们不直接使用文件存储呢?
这是因为普通文件的各种操作需要程序员自己手动来使用,在代码中读取内容随后进行管理,这样是十分不方便的。
文件保存数据有以下几个缺点:
- 文件的安全性问题
- 文件不利于数据查询和管理
- 文件不利于存储海量数据
- 文件在程序中控制不方便
所以,一般的文件确实提供了数据的存储功能,但是文件并没有提供非常好的数据管理能力(从用户角度)。
为了解决上述问题,专家们设计出更加利于管理数据的东西------数据库,它能更有效的管理数据。数据库的水平是衡量一个程序员水平的重要指标。
数据库的本质:对数据内容存储的一套解决方案,你给我字段或者要求,我会给你结果。
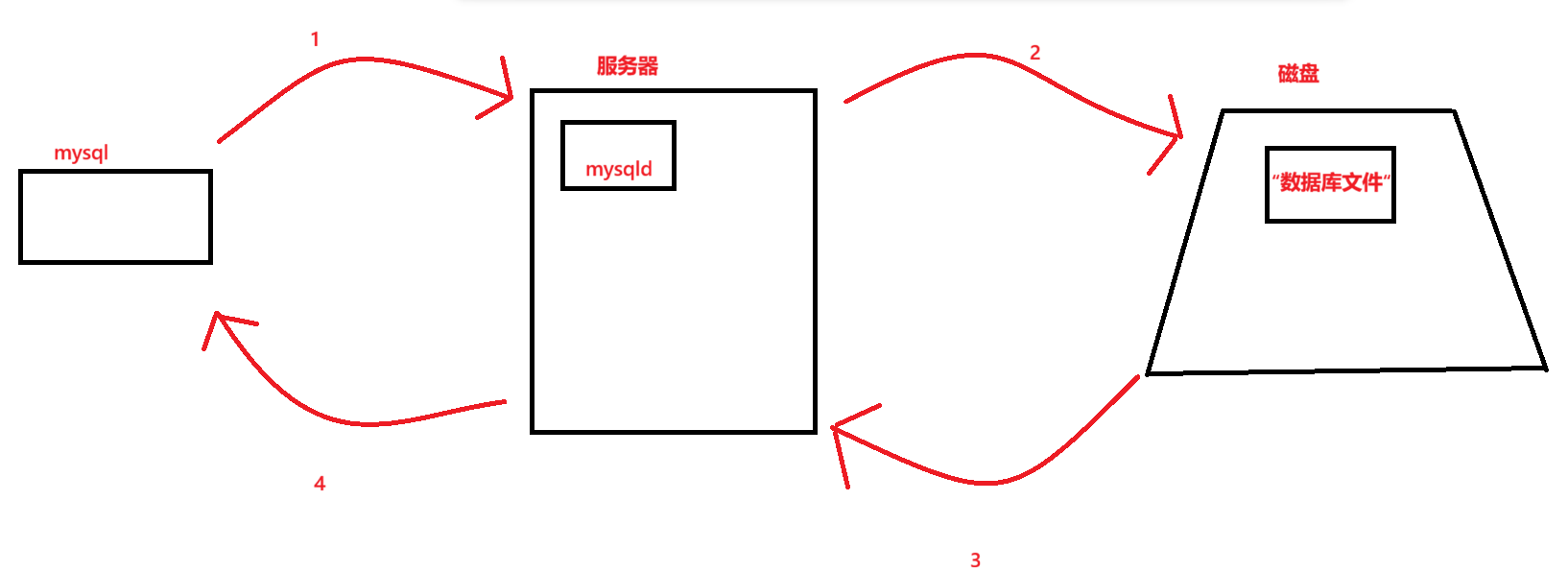
当一个mysql客户端提出某种需求,服务端会去数据库文件中进行处理,把结果交给mysqld,最后交给我们客户端。
所以什么是数据库呢?
一套结构化的数据或者整体的一套方案称为数据库。
以下是几种常见的主流数据库:
| 数据库 | 开发商 | 开源 | 典型场景 | 核心优势 | 常见误区澄清 |
|---|---|---|---|---|---|
| MySQL | Oracle | ✅(社区版) | Web 应用、电商、SaaS、中小型企业 | 高并发读写、生态成熟、部署简单、云原生支持好 | ❌"不适合复杂业务" → 错误! 阿里、腾讯、Uber 都用 MySQL 处理超复杂业务。8.0+ 支持 CTE、窗口函数、JSON、GIS 等高级功能 |
| PostgreSQL | 社区(源自 UC Berkeley) | ✅ | 金融、地理信息系统(GIS)、数据分析、高一致性要求系统 | 功能最全的开源 RDBMS:支持 JSONB、全文检索、自定义类型、逻辑复制、并行查询 | ✅ 不是"学术玩具" → 被 Apple、Instagram、Cisco、国家电网等大规模商用 |
| Microsoft SQL Server | Microsoft | ❌(有免费 Express 版) | Windows 生态、.NET 企业应用、BI 报表 | 与 Azure 深度集成、T-SQL 强大、SSIS/SSAS 工具链完善 | ⚠️ 跨平台能力已大幅提升(Linux/Docker 支持良好),不再仅限 .NET |
| Oracle Database | Oracle | ❌(有免费 XE 版) | 超大型企业核心系统(银行、电信、政府) | 极致稳定性、RAC 集群、高级安全/审计、向后兼容性极强 | ❌"并发不如 MySQL" → 严重过时! Oracle RAC 可横向扩展并发,OLTP 性能顶尖,只是成本高 |
| SQLite | D. Richard Hipp | ✅ | 移动 App(Android/iOS)、嵌入式设备、本地缓存、测试 | 零配置、单文件、ACID、C 语言库、资源占用极低(<500KB) | ✅ 定位清晰:不是为多用户高并发设计,而是"嵌入式首选" |
| H2 | Thomas Mueller | ✅ | Java 单元测试、内存数据库、小型应用原型 | 纯 Java、支持内存/文件模式、兼容 MySQL/PostgreSQL 语法 | ⚠️ 生产环境慎用 → 主要用于开发测试,非高可用场景 |
见一下数据库
那么接下来我们就来见一下数据库,使用mysql建立一个数据库与表结构,插入一些数据。
首先我们先在云服务器账号中登录root用户,前期使用我推荐用root方便一些,等大家接触一会后在使用各用户也不迟。
成为root后,我们默认下载的mysql是没有密码的,我们直接输入:
mysql
就可以直接进入mysql命令行:
我们输入:
show databases;
就可以看见我们当前的mysql的一个数据库信息:

注意,mysql里的命令语句通常要在末尾加一个;表示结尾。
那么这些数据库存放在哪里呢?
首先我们要知道,mysql他有自己的配置文件:
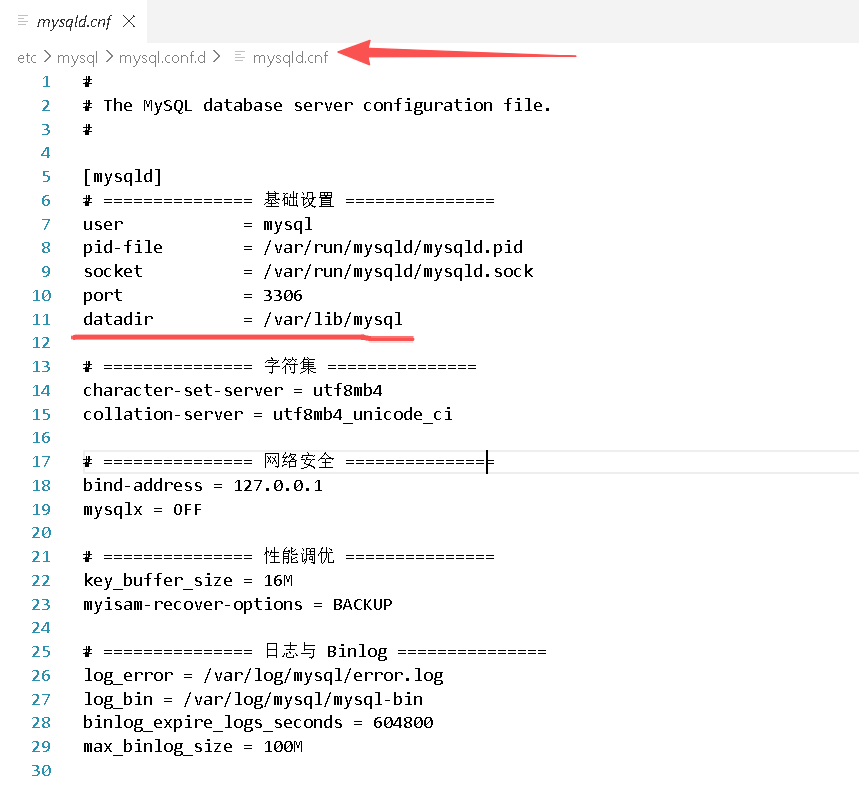
ubuntu在这个路径下,你可以看见这里有一个叫做datadir的属性,他指定的路径是/var/lib/mysql,那我们随后再去这个路径下查看:
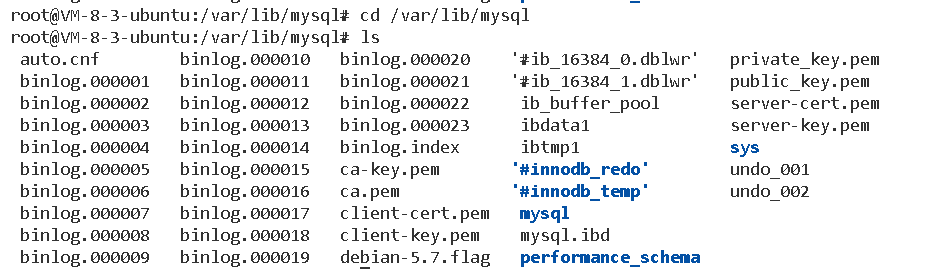
可以发现我们的mysql数据库文件就存储在这里,是一个一个的目录形式存在的。
我们在mysql中创建一个新的数据库,名字叫做helloworld,你会看见:

在mysql中创建新的数据库后,datadir路径下也创建了一个mysql目录。
我们进入这个helloworld目录看看:

里面目前什么都没有,这很正常,因为我们新建的这个数据库是空的。
倘若此时我们创建一个student表格呢?
我们先输入
use helloworld;
使用数据库,随后创建一个表结构:

之后再看mysql目录下,已经多了一个student.ibd文件(这些创建操作我们后面都会讲,现在只是给大家演示一遍看一下目录的前后区别)。
我们插入几个数据:

你可以选择查看表里的数据:

这里的* 代表每一个的意思,如果你想,也可以加一下限制语句来获得不同的输出结果,我们这里先不深入探究。
经过以上的各种操作,我们其实就已经可以在脑海中浮现出数据库的一个基本事实:
- 建立数据库,本质就是建立Linux下的一个目录
- 在数据库内建立表,本质就是在Linux下创建对应的文件即可!
这两个都是mysql的服务端帮我们做的事情。
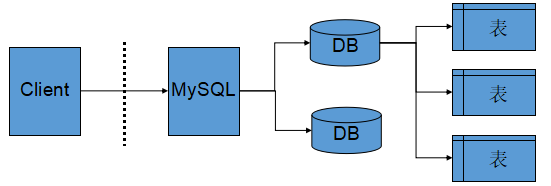
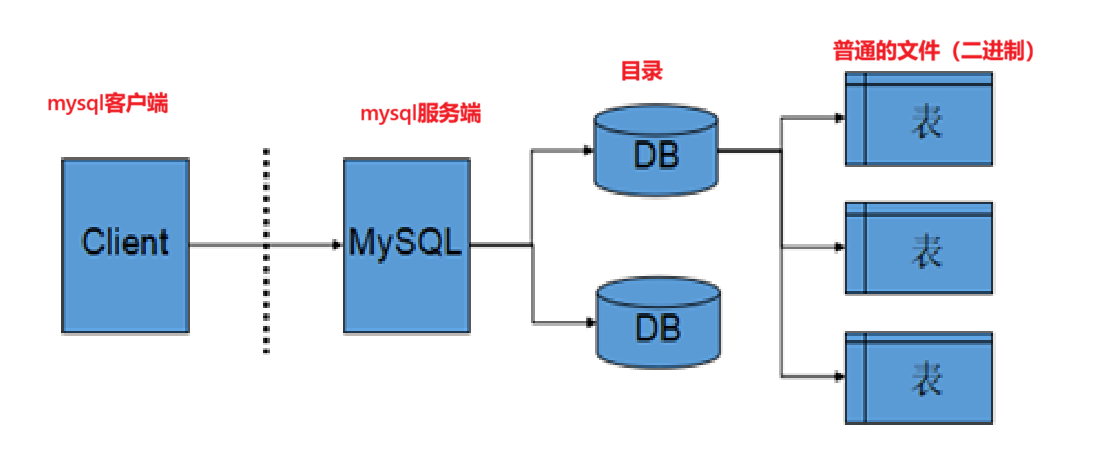
服务器,数据库与表关系
所谓安装数据库服务器,只是在机器上安装了一个数据库管理系统程序,这个管理程序可以管理多个数据库,一般开发人员会针对每一个应用创建一个数据库。
为保存应用中实体的数据,一般会在数据库中创建多个表,以保存程序中实体的数据。
数据库服务器、数据库和表的关系如下:
MySQL架构
MySQL 是一个可移植的数据库,几乎能在当前所有的操作系统上运行,如 Unix/Linux、Windows、Mac 和 Solaris。
各种系统在底层实现方面各有不同,但是 MySQL 基本上能保证在各个平台上的物理体系结构的一致性,这就是MySQL的架构。
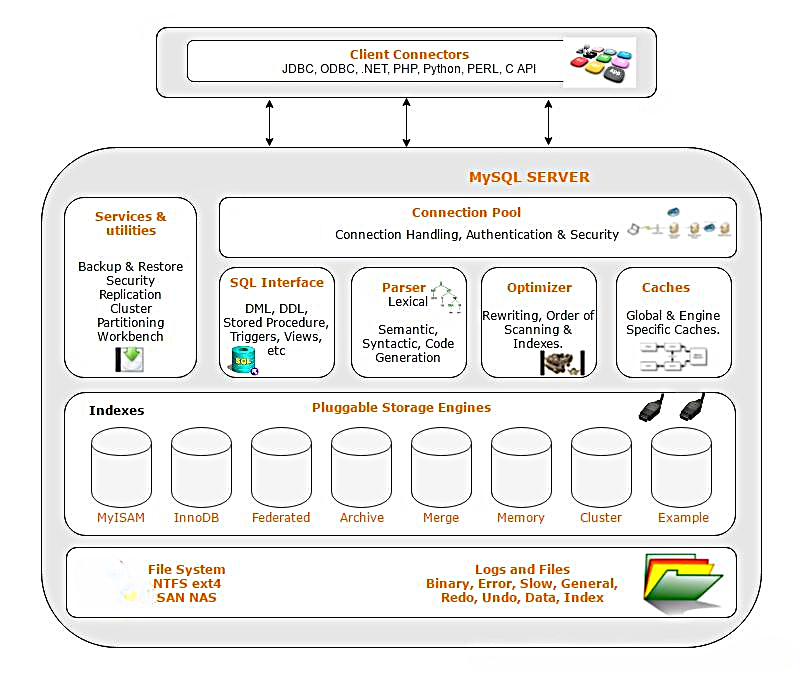
1️ 客户端连接器(Client Connectors)
- 是各种编程语言或工具与 MySQL 通信的接口
- 支持多种协议:
- JDBC(Java)
- ODBC(通用)
- .NET, PHP, Python, Perl, C API 等
- 所有客户端通过这些接口发送 SQL 请求,接收结果
说明 :你用
mysql命令行、PHP 连接数据库,都是走这个通道。
2️ MySQL Server 核心(MySQL SERVER)
这是整个系统的"大脑",分为多个子模块:
🔹 Connection Pool(连接池)
- 负责管理所有客户端连接
- 处理:
- 连接建立与断开
- 用户认证(用户名密码)
- 权限检查
- 会话状态维护
类比:像一个"门卫",先验证你是谁,再放你进大楼。
🔹 SQL Interface(SQL 接口)
- 接收并处理 SQL 语句
- 支持:
- DML(INSERT, UPDATE, DELETE)
- DDL(CREATE TABLE, ALTER TABLE)
- 存储过程、触发器、视图等高级功能
你的
SELECT * FROM users;就是这里接收的。
🔹 Parser(解析器)
- 对 SQL 语句进行语法和语义分析
- 分为三步:
- 词法分析(Lexical):把字符串拆成单词(token)
- 语法分析(Syntactic):判断是否符合 SQL 语法
- 语义分析(Semantic):检查表是否存在、字段名是否正确
- 最终生成抽象语法树(AST)
比如
SELECT name FROM users WHERE id=1;→ 解析成一棵树结构
🔹 Optimizer(优化器)
- 核心组件之一!决定"怎么执行"最高效
- 主要任务:
- 重写查询(如
WHERE a=1 AND b=2可能被重写) - 决定使用哪个索引(Index Selection)
- 确定扫描顺序(Join Order)
- 选择最佳执行计划(Execution Plan)
- 重写查询(如
例如:
SELECT * FROM t1,t2 WHERE t1.id=t2.id优化器可能决定先查小表,再关联大表 → 提升性能!
🔹 Caches(缓存)
- 缓存以下内容以提升性能:
- 全局缓存:查询结果、表定义
- 引擎级缓存:InnoDB 的 Buffer Pool(缓冲数据页)
- 减少磁盘 I/O,加快响应速度
比如你连续两次查
SELECT * FROM users,第二次直接从缓存返回
3️ Pluggable Storage Engines(可插拔存储引擎)
存储引擎(Storage Engine)是 MySQL 架构中最核心、最具特色的部分
MySQL 不直接存储数据,而是通过"存储引擎"来实现。
每个存储引擎都像一个独立的"数据存储模块",可以单独启用或禁用。
SQL 解析、优化等上层逻辑 与 底层数据存储 完全解耦。
这意味着:
- 你可以用同一套 SQL 语法操作不同类型的存储结构;
- 可以根据业务需求为不同表选择不同的存储引擎;
- 社区可以开发新的存储引擎(如 TokuDB、RocksDB),无缝集成到 MySQL
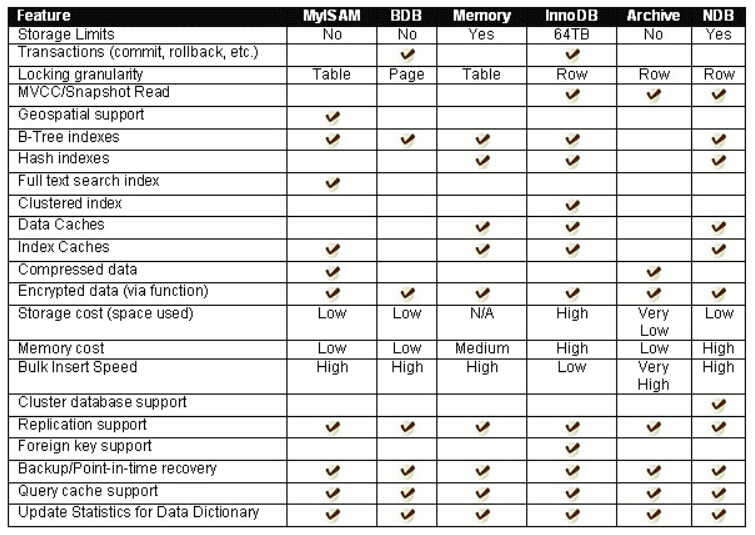
常见存储引擎:
| 引擎 | 特点 | 适用场景 |
|---|---|---|
| InnoDB | 支持事务(ACID)、行级锁、外键、MVCC | 主流选择,适合 OLTP(在线交易) |
| MyISAM | 不支持事务,但读取快,支持全文索引 | 旧版应用、只读报表(已逐渐淘汰) |
| Memory | 数据存在内存中,重启清空 | 临时表、高速缓存 |
| Archive | 压缩存储,只允许 INSERT/SELECT | 归档日志、历史数据 |
| Federated | 访问远程数据库 | 分布式系统 |
| Cluster | 高可用集群 | 企业级高并发 |
默认情况下,MySQL 使用 InnoDB 作为默认存储引擎(8.0+)
当你创建表时,如果不指定引擎,自动使用 InnoDB:
CREATE TABLE users (id INT PRIMARY KEY);
-- 实际就是 InnoDB你可以通过show engines;来看支持的存储引擎:

存储引擎对比:
4️ 底层存储层(File System & Logs)
这是数据最终落地的地方。
🔹 File System(文件系统)
- 数据存储在操作系统文件中
- 具体路径由
datadir指定(如/var/lib/mysql/) - 每个存储引擎有自己的文件格式:
- InnoDB:
.ibd(表空间文件) - MyISAM:
.MYD(数据)、.MYI(索引)
- InnoDB:
🔹 Logs and Files(日志文件)
- 关键日志类型:
- Binary Log(binlog):记录所有更改操作,用于主从复制和恢复
- Error Log:错误信息
- Slow Query Log:慢查询日志(调试性能)
- Redo Log / Undo Log:InnoDB 的事务日志,保证崩溃恢复
- Data & Index Files:实际的数据和索引文件
你之前看到的
binlog.000001、ibdata1都属于这一层!
SQL的分类
| 分类 | 全称 | 中文名 | 作用 | 核心命令 |
|---|---|---|---|---|
| DDL | Data Definition Language | 数据定义语言 | 定义/修改/删除数据库结构(库、表、索引等) | CREATE, DROP, ALTER, TRUNCATE |
| DML | Data Manipulation Language | 数据操纵语言 | 对表中的数据进行增删改 | INSERT, UPDATE, DELETE |
| DQL | Data Query Language | 数据查询语言 | 查询数据(常被归为 DML 子集) | SELECT |
| DCL | Data Control Language | 数据控制语言 | 控制权限 和事务 | GRANT, REVOKE, COMMIT, ROLLBACK |
有些资料会把 TCL(Transaction Control Language) 单独列出(如
COMMIT,ROLLBACK),但在 MySQL 中通常归入 DCL。
1. DDL:数据定义语言(结构管理)
作用:
- 创建、修改、删除数据库对象(database, table, index, view 等)
- 自动提交 :DDL 语句执行后立即生效,无法回滚(即使在事务中)
常见命令:
表格
| 命令 | 示例 | 说明 |
|---|---|---|
CREATE |
CREATE DATABASE mydb; CREATE TABLE users (id INT, name VARCHAR(50)); |
创建数据库或表 |
DROP |
DROP TABLE users; DROP DATABASE mydb; |
永久删除对象及所有数据 |
ALTER |
ALTER TABLE users ADD COLUMN email VARCHAR(100); ALTER TABLE users MODIFY name VARCHAR(100); |
修改表结构(加列、改类型、删列等) |
TRUNCATE |
TRUNCATE TABLE logs; |
快速清空整张表 (比 DELETE FROM 快,且重置自增 ID) |
注意:
DROP和TRUNCATE不可逆!ALTER TABLE在大表上可能锁表(MySQL 8.0+ 支持在线 DDL,减少影响)
2. DML:数据操纵语言(数据操作)
作用:
- 对已有表中的数据行进行操作
- 默认不自动提交(在事务中可回滚)
常见命令:
| 命令 | 示例 | 说明 |
|---|---|---|
INSERT |
INSERT INTO users (name) VALUES ('Alice'); |
插入新记录 |
UPDATE |
UPDATE users SET name='Bob' WHERE id=1; |
修改现有记录(务必带 WHERE!) |
DELETE |
DELETE FROM users WHERE id=1; |
删除记录(务必带 WHERE!) |
高危操作:
UPDATE users SET name='Hacker'; -- 没有 WHERE → 全表被改!
DELETE FROM users; -- 没有 WHERE → 全表被删!建议:开发时开启
sql_safe_updates=1(MySQL),禁止无 WHERE 的 UPDATE/DELETE。
3. DQL:数据查询语言(数据读取)
作用:
- 从数据库中检索数据
- 是使用最频繁的 SQL 类型
核心命令:
SELECT(唯一代表)
强大功能:
-- 基础查询
SELECT name, email FROM users WHERE age > 18;
-- 聚合
SELECT COUNT(*), AVG(age) FROM users;
-- 连接
SELECT u.name, o.amount
FROM users u JOIN orders o ON u.id = o.user_id;
-- 分组 + 排序
SELECT dept, COUNT(*)
FROM users
GROUP BY dept
ORDER BY COUNT(*) DESC;虽然
SELECT不修改数据,但复杂查询可能消耗大量 CPU/IO,需优化。
4. DCL:数据控制语言(权限 & 事务)
作用:
- 权限管理:控制谁可以访问哪些数据
- 事务控制:保证数据一致性
常见命令:
A. 权限管理:
| 命令 | 示例 | 说明 |
|---|---|---|
GRANT |
GRANT SELECT, INSERT ON mydb.* TO 'app_user'@'%'; |
授予权限 |
REVOKE |
REVOKE DELETE ON mydb.* FROM 'app_user'@'%'; |
撤销权限 |
B. 事务控制(TCL):
| 命令 | 说明 |
|---|---|
START TRANSACTION 或 BEGIN |
开启事务 |
COMMIT |
提交事务(永久保存更改) |
ROLLBACK |
回滚事务(撤销所有更改) |
SAVEPOINT |
设置保存点(部分回滚) |
事务示例:
START TRANSACTION;
UPDATE accounts SET balance = balance - 100 WHERE user_id = 1;
UPDATE accounts SET balance = balance + 100 WHERE user_id = 2;
COMMIT; -- 要么都成功,要么都失败结语
对于今天的内容,目标就是让大家有一个对MySQL的基本认识就可以了,至于MySQL的其他操作,我们会在后面的文章中一一为大家讲解。