这篇文章介绍多模态模型-YOLO World
多模态基础知识介绍可以看:多模态-1 基础理论
Grounding DINO介绍可以看:多模态-7 Grounding DINO
CLIP介绍可以看:多模态-2 CLIP
YOLO World原论文:《YOLO-World: Real-Time Open-Vocabulary Object Detection》
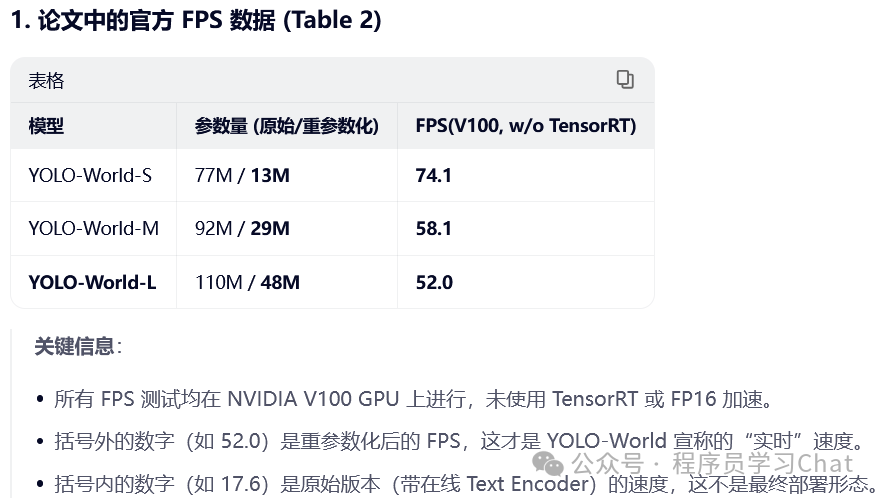
YOLO World类似Grounding DINO,也是解决开放集合目标检测的问题,但是使用的图像编码器是YOLO(具体是YOLO V8),相比于以往的开放集合目标检测模型更轻量,推理部署阶段可进一步配合重参数化的技巧提升推理速度,使YOLO World接近于原始YOLO的速度,消费级显卡上可达70+ FPS。
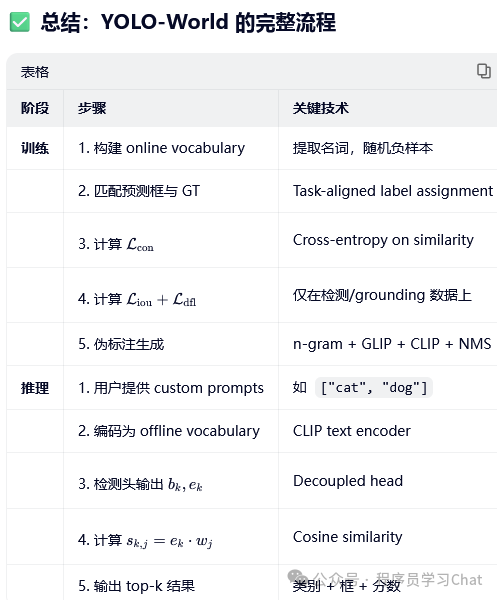
一 模型结构与训练
YOLO World整体结构如下:
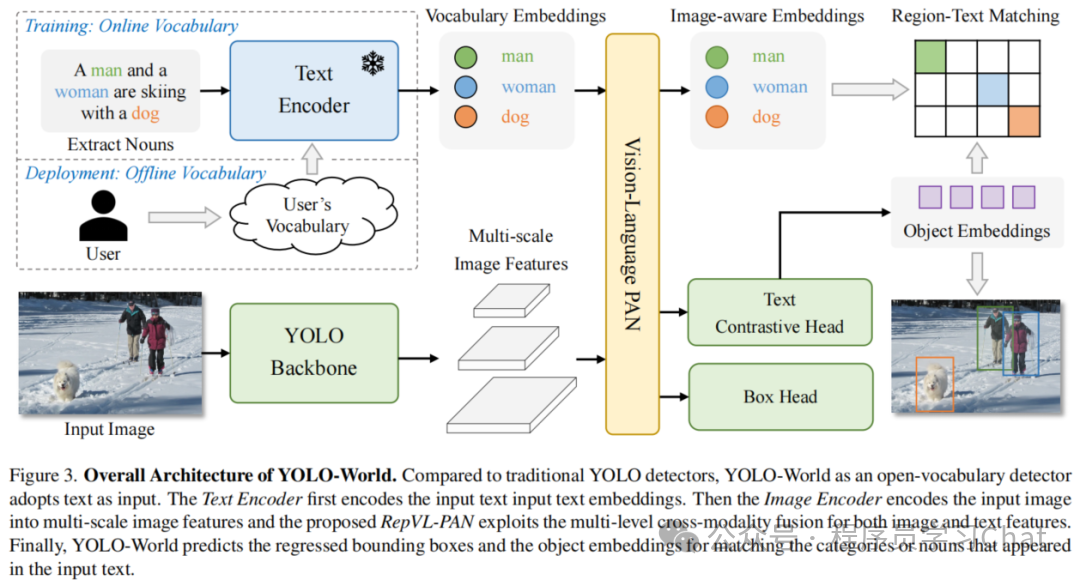
输入依旧是<图像,文本>,但是相比于Grounding DINO,YOLO World输入的文本是类别名称列表,而Grounding DINO是任意格式的文本。
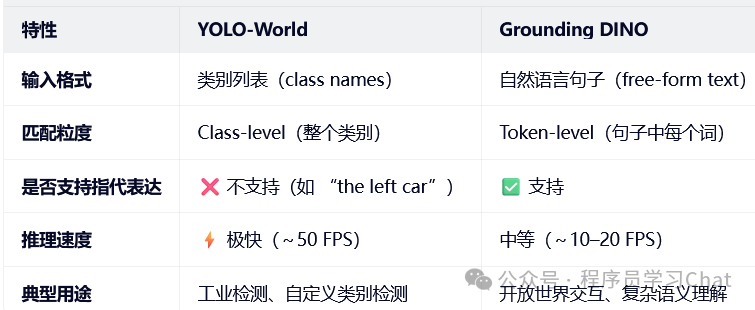
YOLO-World 更适合**"我知道要检测什么,只是模型没学过"的场景,而Grounding DINO 更适合"我用语言描述我想找的东西"**的场景。
将图片输入到YOLO的Backbone中进行图像特征提取,将类别文本输入到Text Encoder中进行文本编码特征提取(论文中使用的Text Encoder是CLIP),利用Vision-Language PAN进行图像特征、文本编码特征的语义对齐,将语义对齐后的特征输入到Text Contrastive Head、Box Head中得到预测类别和矩形框坐标输出,和真实标签计算损失反向梯度传播训练整个YOLO World。
1.1 Text Encoder

利用CLIP对输入的文本类别列表,如cat,dog,apple,进行特征编码表示,得到C,D大小的编码表示矩阵,其中C是类别的个数、D是文本特征编码表示的嵌入向量维度。如果输入的是一整段的文本,则利用n-gram方法从文本中提取出文本类别列表,再进行特征编码表示,比如输入的是"a cat and a dog eat apple",需要借助n-gram方法从这段文本中提取出来要检测的类别名词,然后形成类别名称列表再输入到CLIP中进行特征编码表示。
1.2 Vision-Language PAN
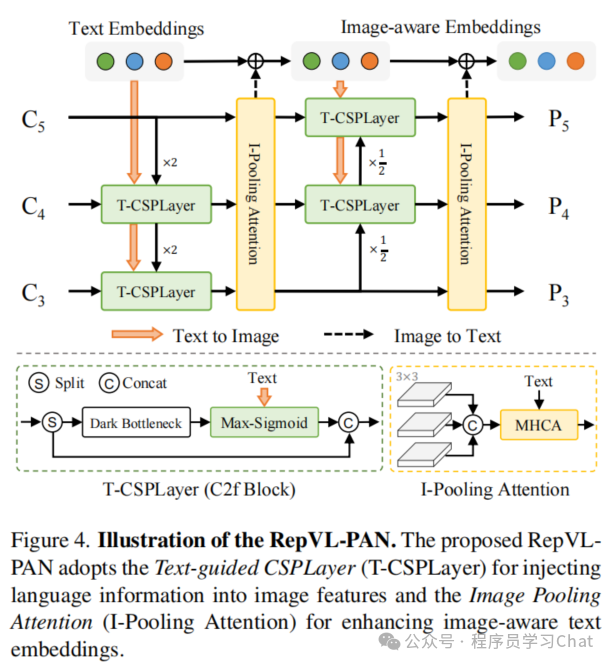



















1.3 训练














二 实验结果