目录
[第一部分:打破CNN统治------Vision Transformer (ViT)](#第一部分:打破CNN统治——Vision Transformer (ViT))
[1. 核心思想:An Image is Worth 16x16 Words](#1. 核心思想:An Image is Worth 16x16 Words)
[2. 关键细节解析(复试加分点)](#2. 关键细节解析(复试加分点))
[那个神秘的 0* Token (CLS)](#那个神秘的 0* Token ([CLS]))
[为什么必须要有 Position Embedding?](#为什么必须要有 Position Embedding?)
第二部分:跨界融合------多模态学习 (Multimodal Learning)
[1. 为什么需要多模态?](#1. 为什么需要多模态?)
[2. 经典架构演进:从"一锅炖"到"精细化"](#2. 经典架构演进:从“一锅炖”到“精细化”)
[🔹 阶段一:VisualBERT(早期探索)](#🔹 阶段一:VisualBERT(早期探索))
[🔹 阶段二:ViLT (Vision-and-Language Transformer Without Convolution)](#🔹 阶段二:ViLT (Vision-and-Language Transformer Without Convolution))
[🔹 阶段三:ALBEF(Align before Fuse)](#🔹 阶段三:ALBEF(Align before Fuse))
[1. 医学图像处理 (Medical Image Analysis)](#1. 医学图像处理 (Medical Image Analysis))
[2. 分布式训练与联邦学习 (Distributed & Federated Learning)](#2. 分布式训练与联邦学习 (Distributed & Federated Learning))
[🔹 单机多显卡 (Single Machine Multi-GPU)](#🔹 单机多显卡 (Single Machine Multi-GPU))
[🔹 参数服务器 (Parameter Server)](#🔹 参数服务器 (Parameter Server))
[🔹 联邦学习 (Federated Learning)](#🔹 联邦学习 (Federated Learning))
[第四部分: 简历与面试实战策略(重中之重)](#第四部分: 简历与面试实战策略(重中之重))
前言:复试中的"降维打击"
在准备考研复试的过程中,我深知导师看重的不仅仅是基础知识(如CNN卷积核大小),更看重考生对前沿技术(State of the Art)的理解 以及科研思维。
本文基于《深度学习扩展知识》第11章内容进行深度复盘。核心内容涵盖 Vision Transformer (ViT) 的原理、多模态学习(Multimodal) 的演进、分布式训练与联邦学习 ,以及最关键的------如何将这些高大上的技术点落地到我的简历和面试回答中。
第一部分:打破CNN统治------Vision Transformer (ViT)
面试高频问法:
-
"你知道Transformer怎么处理图像吗?"
-
"ViT和CNN在提取特征上有什么本质区别?"
-
"为什么ViT需要位置编码?"
1. 核心思想:An Image is Worth 16x16 Words
在很长一段时间里,CV领域是CNN的天下(局部感受野)。但 ViT (Vision Transformer) 的出现引入了全局注意力机制。
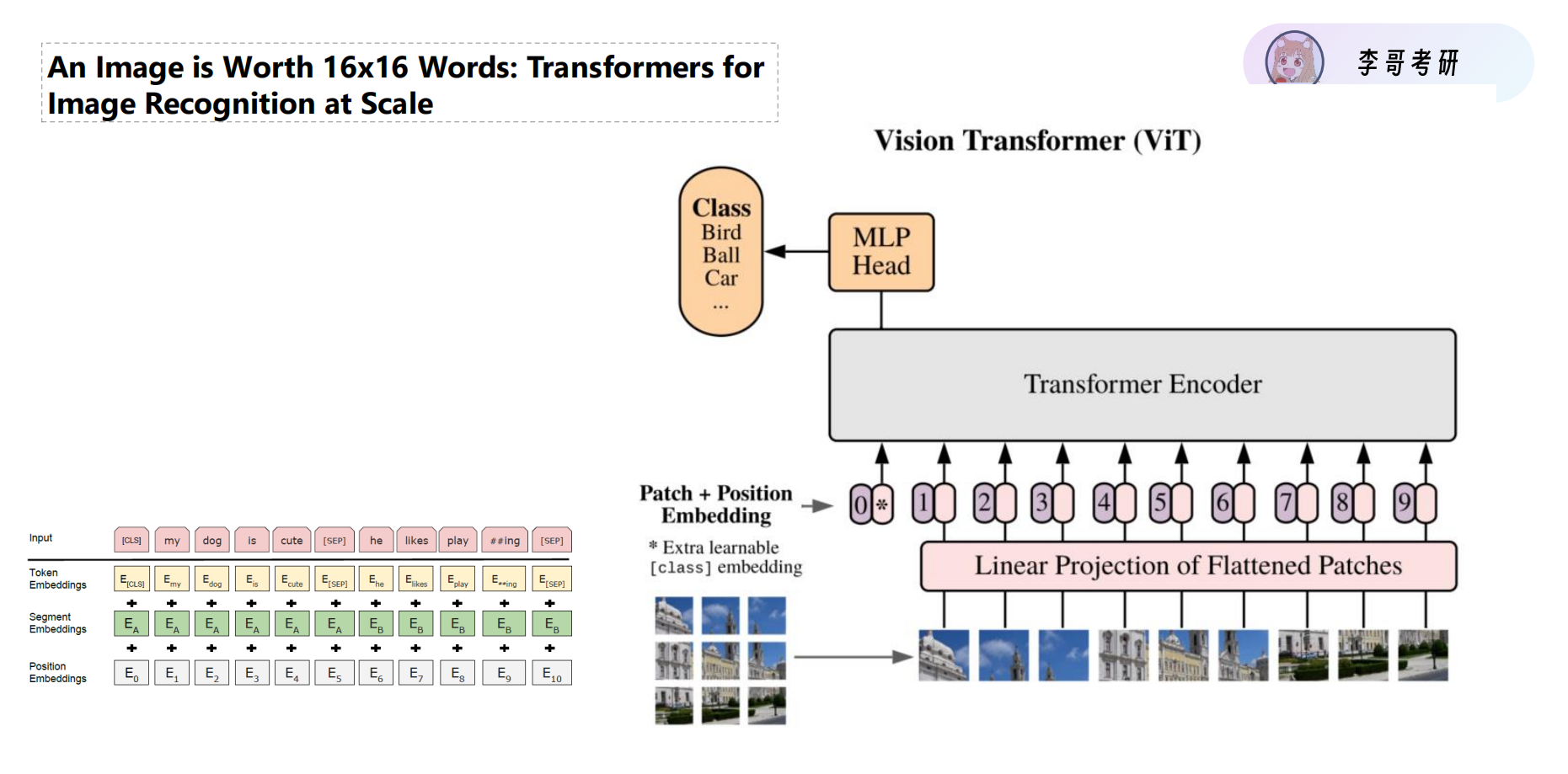
-
Patch Partition(切分) :将一张
的图片切分成
-
Linear Projection(线性映射) :把每个 Patch 拉平成一个向量,映射到
-
Transformer Encoder:利用 Self-Attention 机制,让每一个 Patch 都能"看到"整张图的其他部分(全局建模)。
2. 关键细节解析(复试加分点)
那个神秘的 0* Token (CLS)
在输入序列的最前面,ViT 增加了一个可学习的 class embedding (图中标记为)。
-
作用 :因为 Transformer 的**自注意力机制(Self-Attention)**允许全局信息交互,这个特殊的 Token 在层层传递中会"吸收"所有图片 Patch 的信息。
-
结果 :最后我们只需要取这个
为什么必须要有 Position Embedding?
这是 Transformer 的死穴------置换不变性(Permutation Invariance) 。 如果不加位置编码(0, 1, 2...),把输入的 Patch 顺序打乱,Transformer 根本不知道哪个块在左上角,哪个在右下角。位置编码是保留图像空间结构信息的关键。
第二部分:跨界融合------多模态学习 (Multimodal Learning)
面试高频问法:
-
"你了解哪些多模态任务?"
-
"VisualBERT 和 ViLT 有什么区别?"
-
"什么是'先对齐再融合'(ALBEF)?
1. 为什么需要多模态?
现实世界的信息是融合的。PPT中提到了很多具体任务:
-
VQA (视觉问答):看图回答"沙发是什么颜色的?"
-
Image Captioning:给图片写描述"一个男人和一个女人坐着聊天"。
-
Referring Expression:在图中定位"左边的白色椅子"。

2. 经典架构演进:从"一锅炖"到"精细化"
🔹 阶段一:VisualBERT(早期探索)
- 原理:简单粗暴。把图片的 R-CNN 特征和文字的 Token 向量串联在一起,直接丢进一个 Transformer 里。
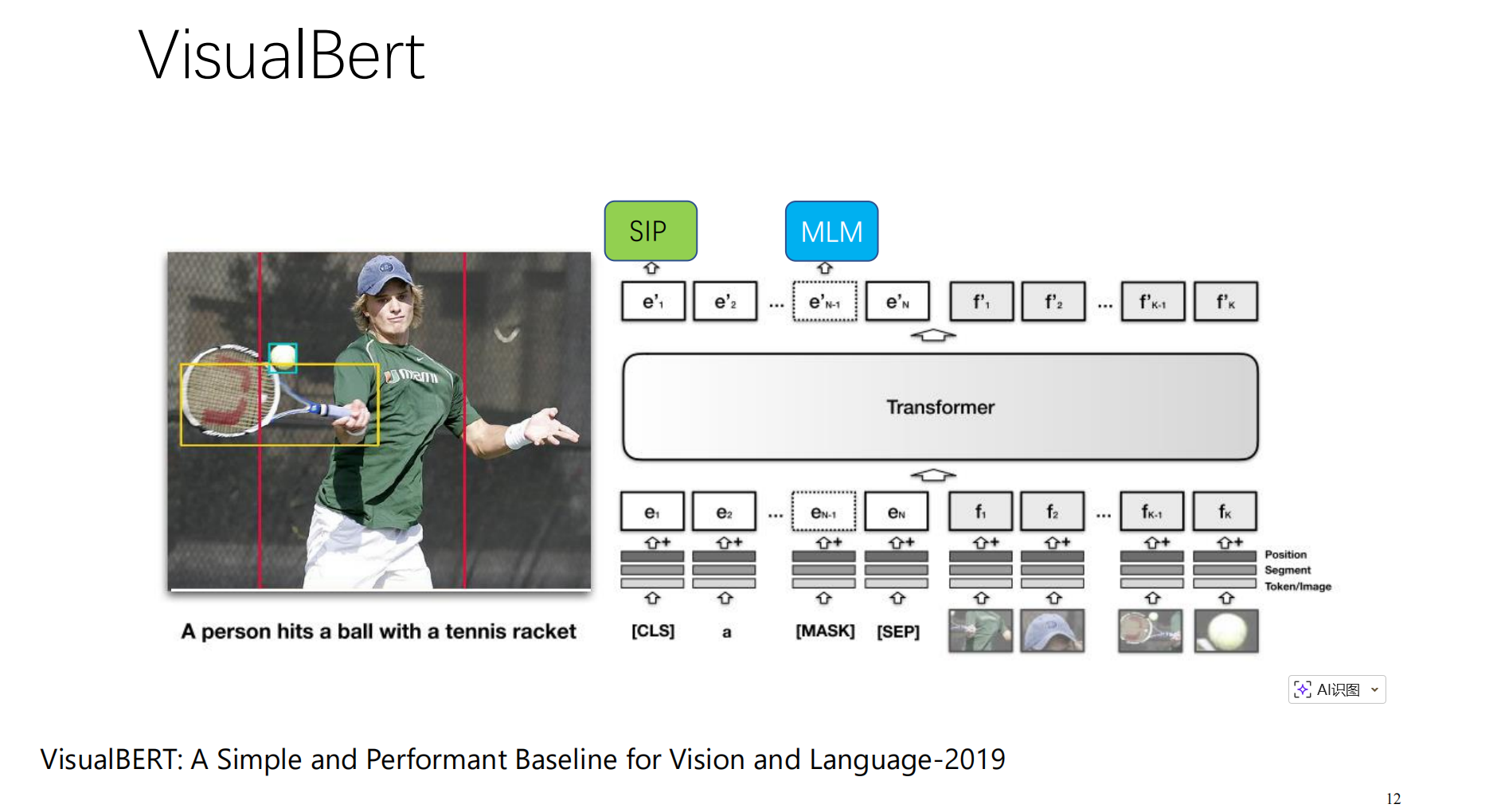
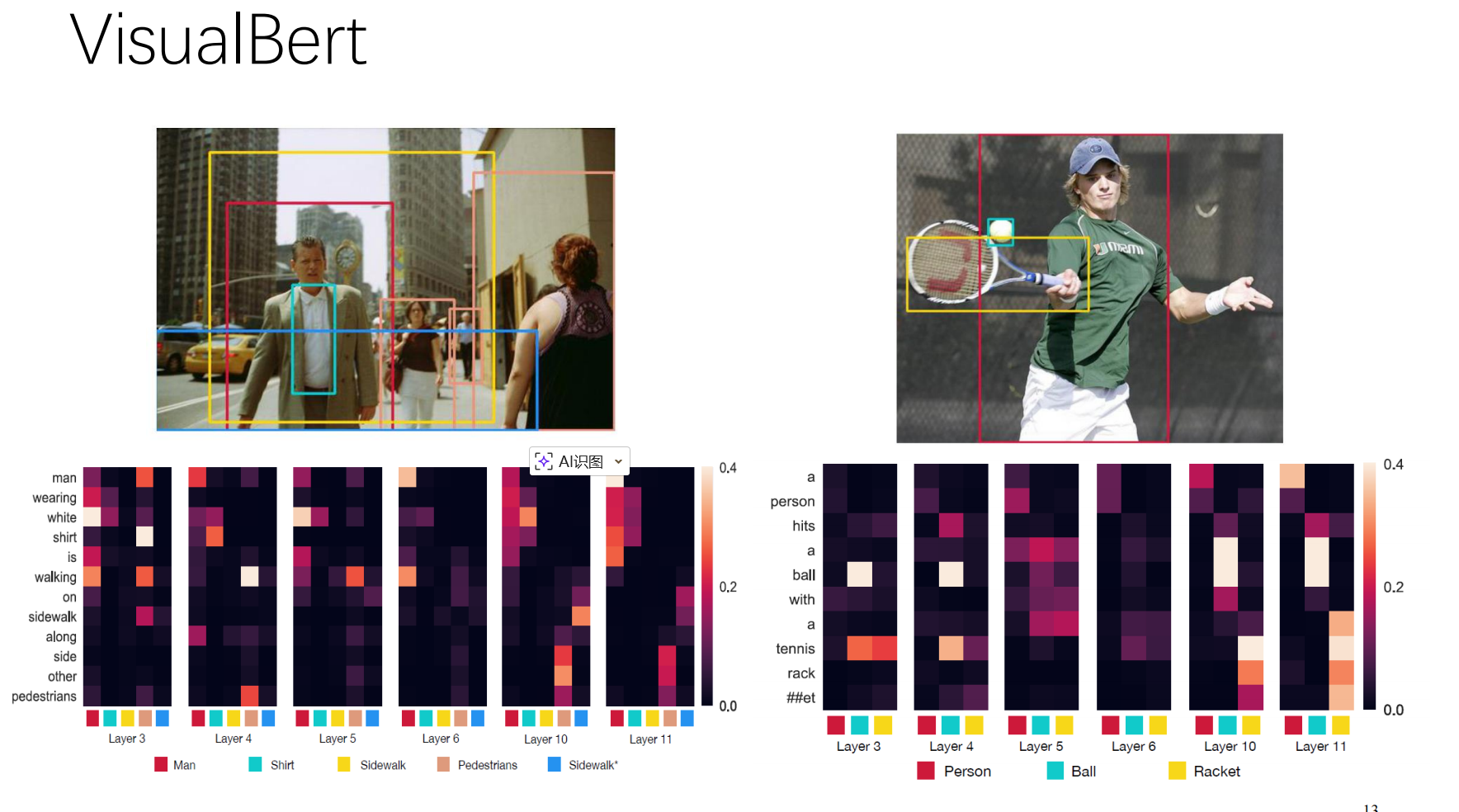
🔹 阶段二:ViLT (Vision-and-Language Transformer Without Convolution)
PPT第10页重点提到了这个模型。它的核心卖点是 "去掉了卷积"。
-
极简架构 :不像VisualBERT还需要一个很重的CNN提取特征,ViLT 直接把图片切 **Patch(像ViT那样)**然后和文字一起输入。
-
速度快:因为去掉了昂贵的CNN特征提取步骤,推理速度大幅提升。
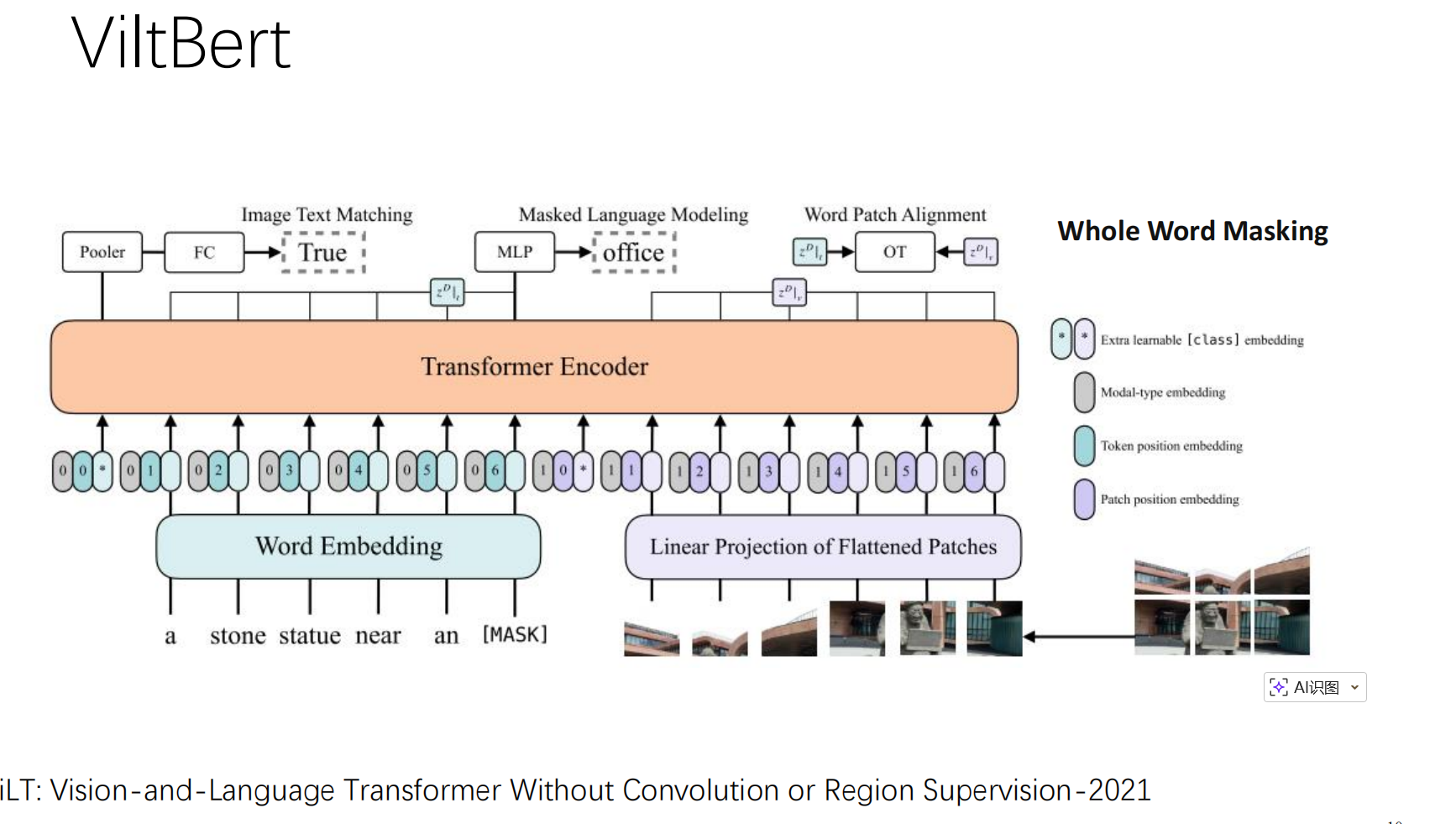
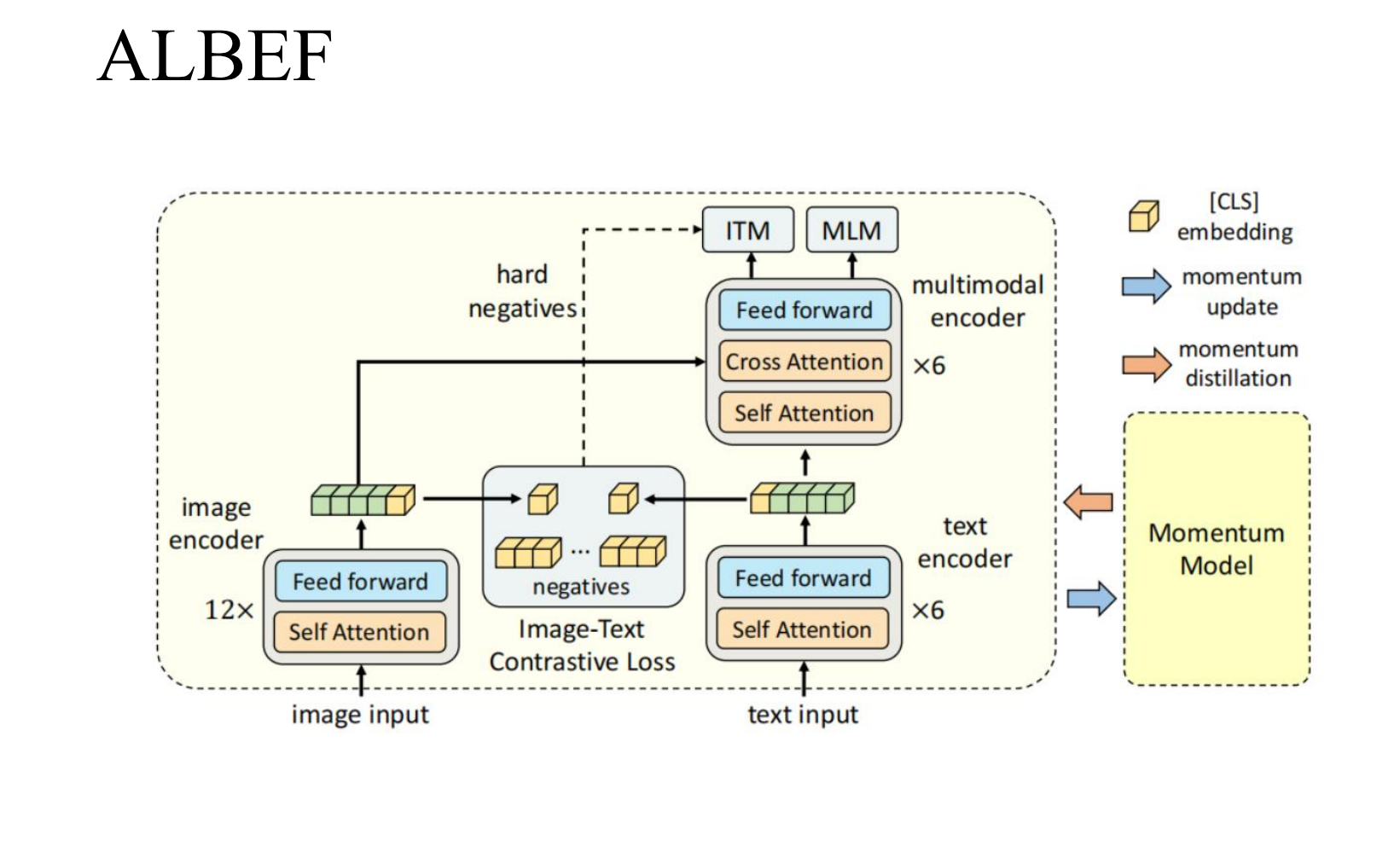
🔹 阶段三:ALBEF(Align before Fuse)
ALBEF 提出了更高级的 "先对齐,再融合"。
-
架构:图像和文本先经过各自独立的 Encoder。
-
对比学习(Contrastive Loss) :在融合之前,利用 Hard Negatives(困难负样本) 挖掘技术,强制模型区分细微差别(如区分"打网球"和"打羽毛球")。
第三部分:广阔天地------常见深度学习研究方向
在复试中,如果导师问"你对未来有什么规划?"或者"遇到算力瓶颈怎么办?",可以结合以下方向回答
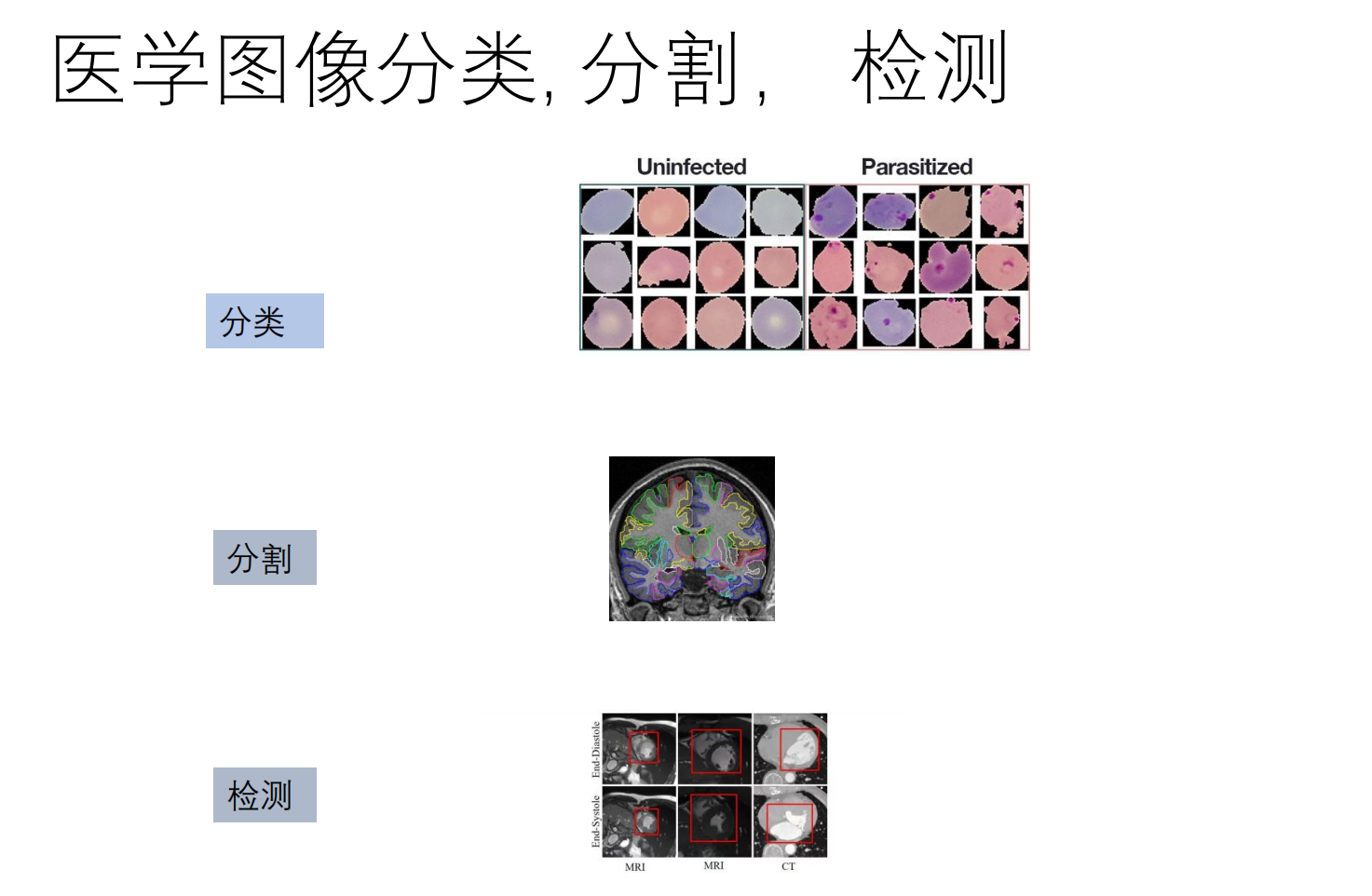
1. 医学图像处理 (Medical Image Analysis)
这是非常有应用前景的方向
-
任务:病灶分类、器官分割、病灶检测。
-
难点:数据标注极难(小样本),需要专业医生。
2. 分布式训练与联邦学习 (Distributed & Federated Learning)
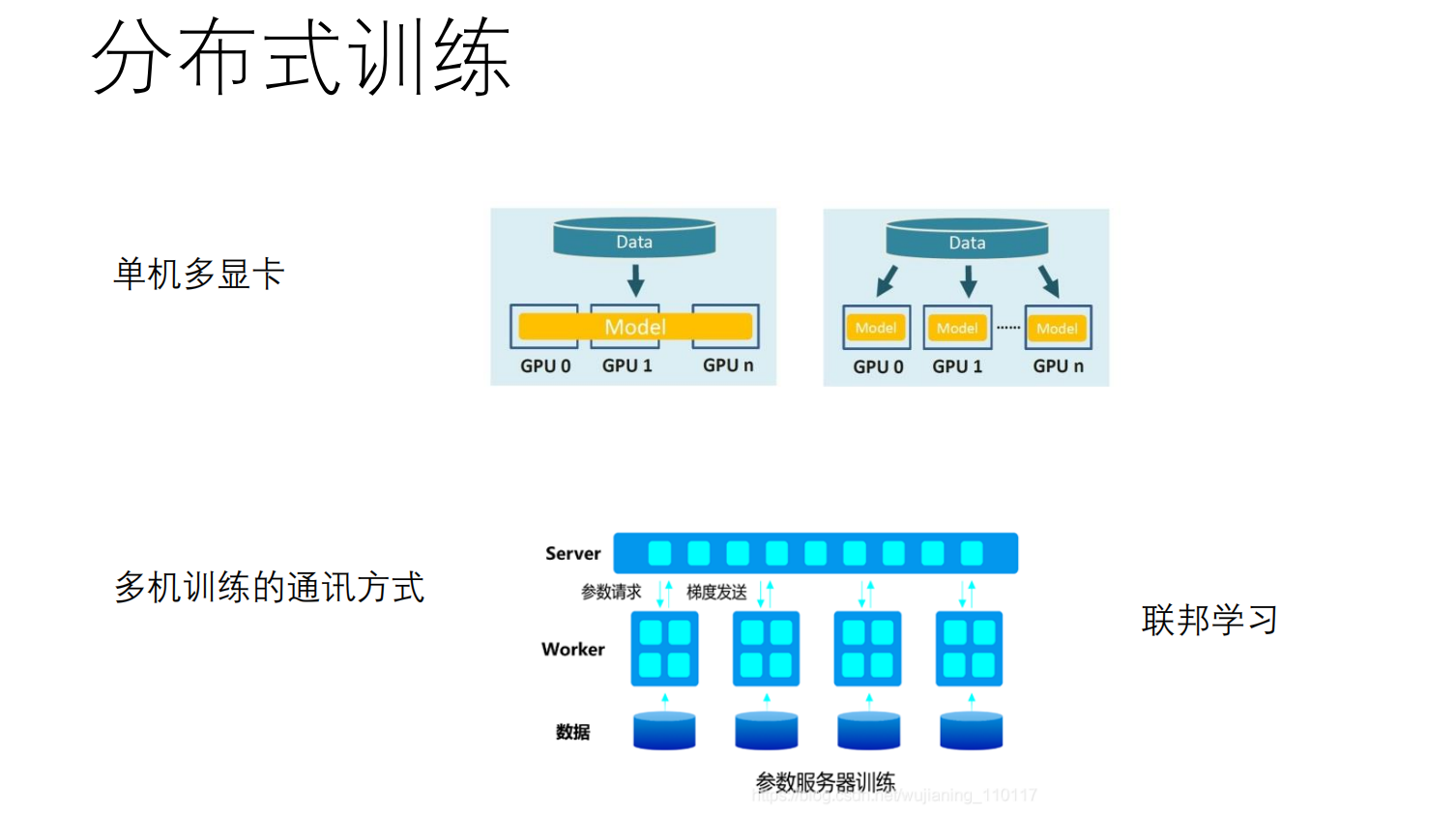
当模型参数量巨大(如大模型)或数据涉及隐私时,单机训练已无法满足需求。
🔹 单机多显卡 (Single Machine Multi-GPU)
-
场景:实验室服务器插了4张显卡。
-
原理(数据并行):将模型复制到每一张卡上,将数据 Batch 切分(Split)成多份并行计算梯度,最后梯度汇总更新。
🔹 参数服务器 (Parameter Server)
-
架构:Server-Worker 结构。
-
Worker(打工仔):负责计算梯度,发送给 Server。
-
Server(大管家):负责存储和更新参数,将新参数下发给 Worker。
🔹 联邦学习 (Federated Learning)
-
核心痛点 :数据隐私(如医院数据、手机输入法记录)。
-
口号 :"数据不动,模型动"。
-
流程 :数据不出本地(手机/医院),在本地训练后,只将加密后的梯度发送给服务器进行聚合。
第四部分: 简历与面试实战策略(重中之重)
如何把"平平无奇"的项目包装出"科研味"
策略一:针对不同任务的"话术设计"
如果你做的是"回归任务" (Regression)

-
误区:只谈模型层数。
-
正确姿势 :"重点在于数据处理"。
-
"针对该预测任务,我重点进行了特征工程。我分析了不同特征的相关性,处理了异常值。"
-
"在训练中,我使用了 Dropout 和 L2正则化 来防止过拟合,并对比了 MSE 和 MAE Loss 对离群点的敏感度。"
-
如果你做的是"分类任务" (Classification)

-
误区:只说准确率99%。
-
正确姿势 :"重点在于数据增广与模型设计"。
-
"针对数据量不足的问题,我设计了特定的数据增广策略。例如,对于MNIST数字分类,我没有使用翻转(Flip) ,因为数字6翻转变成9会改变语义,这体现了我对数据特性的思考。"
-
"对于无标签数据,我尝试了半监督学习 的方法,利用伪标签(Pseudo-labeling)扩充训练集。"
-
策略二:展示"自学与探究能力"
复试中,导师最看重潜力。
-
话术 :"这个项目是我在假期自学的。我对多模态很感兴趣,所以主动利用 CNKI 和 arXiv 查阅了 VisualBERT 和 ViLT 的论文。"
- 、
- 、
-
潜台词:我具备文献调研能力,不需要导师手把手教怎么查资料。
总结与心态
复试不仅是知识的考核,更是心态和逻辑的博弈。 通过这一章的学习,我不仅掌握了 ViT 和多模态的原理,更明白了"知其然,更要知其所以然。在接下来的复试中,我将自信地展示我对数据处理、模型选择背后的思考,而不仅仅是代码的搬运工。
祝我们一战成硕!💪